






“ 近期由于工作需要,研究了一下使用springAI实现RAG,网上查找资料要么配置不全,要么没有讲到环境搭建的内容,所以写一篇记录一下完整过程,希望能够帮到其他开发者。文末附完整代码。”
一、安装 Postgres PGVector数据库
PGVector:PGVector是基于PostgreSQL的向量化的扩展插件。PGVector为PostgreSQL添加了一个新的数据类型:vector用于高纬向量的存储,并支持检索和计算。PGVector特别适用于推荐系统、图像检索、自然语言处理等需要向量相似度计算和向量检索的场景。
1、相关环境及工具:
操作系统:Windows 10
PostgreSQL版本:16(pg的安装非常简单,网上一搜一大把,此处略过)
PGVector版本:vector-0.7.3(安装包从官网下载即可)
工具:安装PgVector需要用到VScode相关工具(vcvars64.bat、nmake)
vcvars64.bat位置:D:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Auxiliary\Build\vcvars64.bat
nmake.exe位置:D:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.40.33807\bin\Hostx64\x64\nmake.exe
2、安装步骤:
1、以管理员身份运行cmd.exe(最好使用管理员身份运行,否则可能出现文件夹无权限访问的情况,导致安装失败)。
2、执行命令:call "D:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Auxiliary\Build\vcvars64.bat" 。
3、进入PGVector解压所在目录:cd G:\PostgreSQL\vector-0.7.3 。
4、设置环境变量:set "PGROOT=G:\PostgreSQL\16"(PostgreSQL根目录)
5、执行编译命令:nmake /F Makefile.win;(nmake命令如果执行失败,需要将命令所在位置配置到系统环境变量PATH中;D:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.40.33807\bin\Hostx64\x64)
6、执行安装命令:nmake /F Makefile.win install
安装完成后可以看到vector安装包中相关sql脚本已经复制到PG的extension目录下:
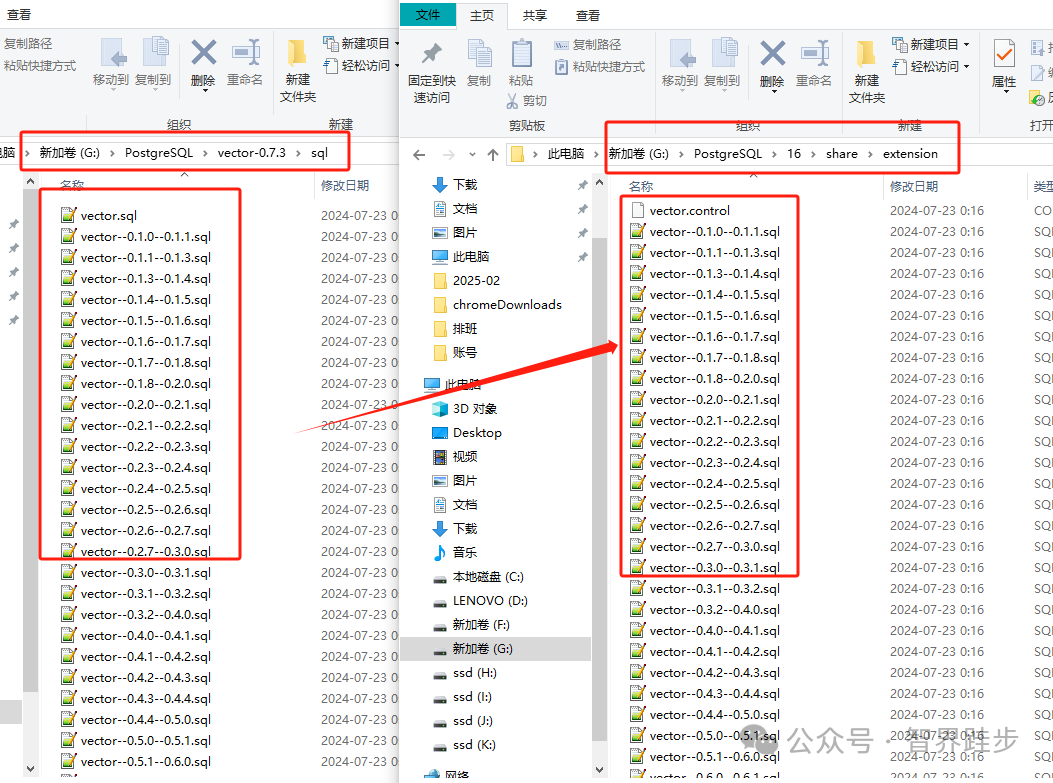
7、创建数据库:打开psql客户端创建测试库vcs

二、编写测试代码
下面演示使用spingAI框架,将一个markdown文档向量存储到PGVector后,结合文档内容,调用智谱API进行RAG问答的代码示例。springboot版本:3.4.2;Java版本:17。
1、maven依赖配置:
maven依赖配置:
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-zhipuai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<id>spring-snapshot</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>2、代码示例
application.yml配置:
server:
port: 8180
spring:
application:
name: springAI
ai:
zhipuai:
# https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys 智谱开放平台
api-key: 填写自己的
base-url: https://open.bigmodel.cn/api/paas/
vectorstore:
pgvector:
initialize-schema: true
index-type: hnsw
datasource:
username: postgres
password: 123456
url: jdbc:postgresql://localhost:5432/vcs
注意:一定要将spring.ai.vectorstore.pgvector.initialize-schema配置为true
这样的话,springAI在启动期间会执行以下命令自动启用vector所需的扩展。通过以下命令可以看到,创建了vector相关的extension、一个名为vector_store的表,并创建了表的索引,向量化后的数据就存储在vector_store表中。
其中embedding的字段类型是vector(1536),就是上面我们提到的新的字段类型。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE IF NOT EXISTS vector_store (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
content text,
metadata json,
embedding vector(1536) // 1536 is the default embedding dimension
);
CREATE INDEX ON vector_store USING HNSW (embedding vector_cosine_ops);上传markdown文档接口,进行向量化
FileController 文件上传接口
@Autowired
private FileService fileService;
@RequestMapping("/upload/md")
public void uploadMd(MultipartFile file) throws IOException {
fileService.saveResourceMarkDown(file);
}FileService 将文档内容存储到vector中
public void saveResourceMarkDown(MultipartFile file) throws IOException {
String fileName= file.getOriginalFilename();
Path tempFile = Files.createTempFile("temp-", fileName);
Files.write(tempFile, file.getBytes());
Resource fileResource = new FileSystemResource(tempFile.toFile());
MarkdownDocumentReaderConfig loadConfig = MarkdownDocumentReaderConfig.builder().build();
MarkdownDocumentReader markdownDocumentReader=new MarkdownDocumentReader(fileResource, loadConfig);
vectorStore.accept(tokenTextSplitter.apply(markdownDocumentReader.get()));
}RAG问答示例
ZhipuRagController
@Autowired
private RagService ragService;
@RequestMapping("/chat")
public String chat(String message) {
return ragService.chatByVectorStore(message);
}RagService
private final static String SYSTEM_PROMPT = """
你需要使用文档内容对用户提出的问题进行回复,同时你需要表现得天生就知道这些内容,
不能在回复中体现出你是根据给出的文档内容进行回复的,这点非常重要。
当用户提出的问题无法根据文档内容进行回复或者你也不清楚时,回复不知道即可。
文档内容如下:
{documents}
""";
@Autowired
private ChatModel chatModel;
@Autowired
private VectorStore vectorStore;
public String chatByVectorStore(String message) {
List<Document> listOfSimilarDocuments = vectorStore.similaritySearch(message);
assert listOfSimilarDocuments != null;
String documents = listOfSimilarDocuments.stream().map(Document::getText).collect(Collectors.joining());
Message systemMessage = new SystemPromptTemplate(SYSTEM_PROMPT).createMessage(Map.of("documents", documents));
UserMessage userMessage = new UserMessage(message);
ChatResponse rsp = chatModel.call(new Prompt(List.of(systemMessage, userMessage)));
return rsp.getResult().getOutput().getText();
}三、运行效果
项目启动:启动后去数据库中查询表,可以看到vcs库下有一张vector_store的表,且表结构如前面提到的创建命令一致。


文件上传:
调用文件上传接口:http://localhost:8180/file/upload/md
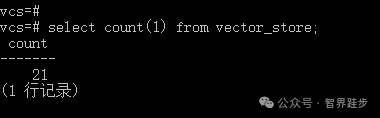
文件上传完成后,可以看到vector_store表中已经有数据了

问答验证:
调用问答接口:http://localhost:8180/file/upload/md
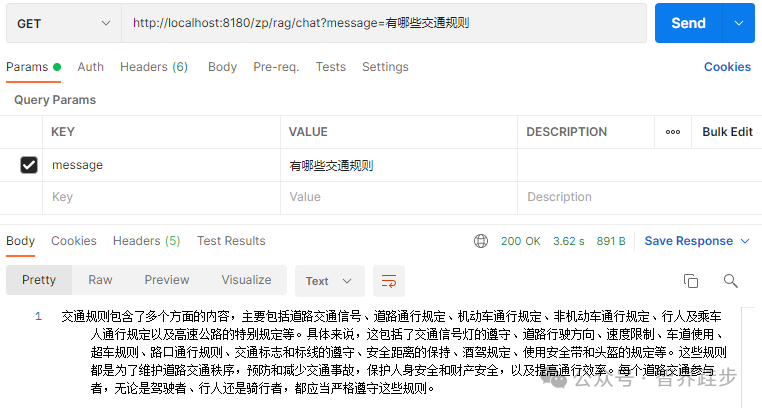
当我们问有哪些交通规则时,可以看到从文档中找到了答案。
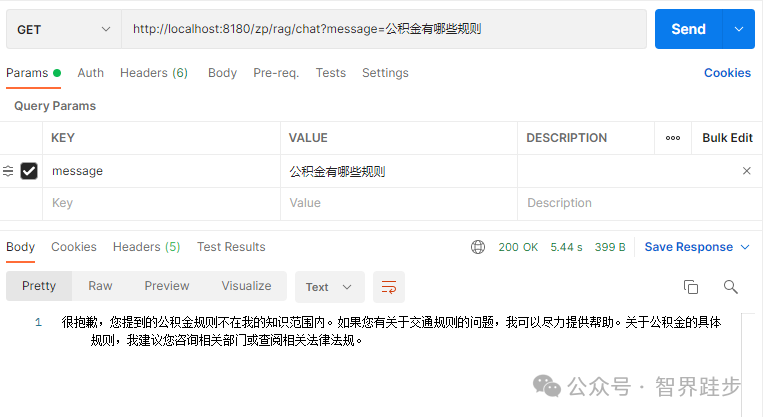
当我们问公积金有哪些规则时,可以看到没有找到答案。
四、结语
到此,从环境搭建到效果演示全部完成,如需获取完整代码,关注公众号【智界跬步】,回复消息:RAGDEMO。


















 3736
3736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









