








题目: Knowledge-Preserving Incremental Social Event Detection via Heterogeneous GNNs
中文题目: 基于异构gnn的知识保持增量社会事件检测
学习目标
学习怎么知识增强的?
学习怎么处理时间等多个因素的?
学习怎么构建子图的?
学习怎么对新类型有鲁棒性的?
ABSTRACT
Social events: 就是比较大型的新闻,引起了人们的关注! 检测和分析这些事件有助于提取有价值的洞见。 在危机管理、产品推荐和决策等领域有很多应用。
难点:
在增量学习环境中获取、保存和扩展知识是主要关注的问题。
过去的方法忽略了社交数据中丰富的语义信息! 而且不能保留住学习到的知识。
本文:
KPGNN利用了复杂的社会网络来促进数据的利用。
为了应用传入的数据,采用了contrastive loss terms处理数量不断变化的事件类。
它还利用gnn的归纳学习能力来有效地检测事件,并从之前未见过的数据扩展其知识。
KPGNN在处理大的社会流时,采用小批子图抽样策略进行训练,并定期剔除过时数据以保持动态
的嵌入空间。
KPGNN不需要特征工程,也很少有超参数需要调优。
NOTATIONS AND PROBLEM FORMULATION
我们首先在表1中总结了本文中使用的主要符号。然后我们将社会流、社会事件、社会事件检测和增量社会事件检测形式化如下:
社会流:从社会流(即社交媒体消息序列)中提取相关消息的聚类来表示事件,如Twitter流。

Definition 2.1. social stream
一个社会流
S
=
M
0
,
.
.
.
,
M
i
−
1
,
M
i
,
.
.
.
S = M_0,...,M_{i-1},M_i,...
S=M0,...,Mi−1,Mi,...是社会信息块的连续和时间序列,其中
M
i
M_i
Mi是一个消息块包含了在时间段内到达的所有消息
[
t
i
,
t
i
+
1
)
[t_i,t_{i+1})
[ti,ti+1)。
我们表示一个消息块 M i M_i Mi为 M i = { m j ∣ 1 ≤ j ≤ M i } M_i = \left \{{m_j|1\le j\le M_i} \right \} Mi={mj∣1≤j≤Mi},其中 m m m是单个消息! m j = { d j , u j , t j } m_j = \left \{ d_j,u_j,t_j \right \} mj={dj,uj,tj}表示为一种社会消息。 其中 d j d_j dj和 u j u_j uj和 t j t_j tj表示为关联的文本文档、用户(发送者和提到的用户)和时间戳
Definition 2.2. social event
social event:
e
=
{
m
i
∣
1
≤
i
≤
∣
e
∣
}
e=\left \{ m_i|1 \le i \le \left | e \right | \right \}
e={mi∣1≤i≤∣e∣}是一组相关的社会信息,讨论相同的现实世界发生的事情。注意,我们假设每个社交信息最多只属于一个事件。
Definition 2.3.
给定一个消息块
M
i
M_i
Mi,一个社会检测算法学习一个模型
f
(
M
i
;
θ
)
=
E
i
f(M_i; \theta) = E_i
f(Mi;θ)=Ei 。这样
E
i
=
{
e
k
∣
1
≤
k
≤
∣
E
i
∣
}
E_i = \left \{ e_k|1 \le k \le |E_i|\right \}
Ei={ek∣1≤k≤∣Ei∣}是包含在
M
i
M_i
Mi一组事件。
Definition 2.4.
给定社会流S,incremental social event detection算法学习一系列的事件检测模型
f
0
,
.
.
.
,
f
t
−
w
,
f
t
,
.
.
.
f_0,...,f_{t-w},f_t,...
f0,...,ft−w,ft,...,这样
f
t
(
M
i
;
θ
t
,
θ
t
−
w
)
=
E
i
f_t(M_i;\theta _t,\theta_{t-w})=E_i
ft(Mi;θt,θt−w)=Ei会为所有的在
{
M
i
∣
t
+
1
≤
i
≤
t
+
w
}
\left \{ M_i|t+1 \le i \le t+w \right \}
{Mi∣t+1≤i≤t+w}中的消息块。 这里,
E
i
=
{
e
k
∣
1
≤
k
≤
∣
E
i
∣
}
E_{i}=\left\{e_{k}|1 \leq k \leq| E_{i} \mid\right\}
Ei={ek∣1≤k≤∣Ei∣}是一系列的事件包含在消息块
M
i
M_i
Mi,
w
w
w是更新模型的window size,而
θ
t
\theta_t
θt和
θ
t
−
w
\theta_{t-w}
θt−w是两个模型
f
t
f_t
ft和
f
t
−
w
f_{t-w}
ft−w的参数。 注意
f
t
f_t
ft扩展了
f
t
−
w
f_{t-w}
ft−w的知识,通过根据
θ
t
−
w
\theta_{t-w}
θt−w。
f
0
f_0
f0就是啥也没有扩展。
3 METHODOLOGY
本节介绍我们提出的KPGNN模型。3.1节介绍了KPGNN的生命周期,给出了KPGNN如何增量运行的大图景。第3.2-3.5节对KPGNN的组件进行了放大,KPGNN的设计目标是增量获取和保存知识。第3.6节分析了KPGNN的时间复杂度。

3.1 Continuous Detection Framework


如图2所示,KPGNN的生命周期包括三个阶段,即预培训、检测和维护。
在训练前阶段,我们构建一个初始消息图并训练一个初始模型。
在检测阶段,我们用输入消息块更新消息图,并检测事件。目前的KPGNN模型在进入维护阶段之前对一系列连续的区块进行工作。
在维护阶段,我们从消息图中删除过时的消息,并使用到达最后一个窗口的数据恢复模型训练。维护阶段允许模型忘记过时的知识,并为模型配备最新的知识。维护的模型可以在下一个窗口中用于检测。通过这种方式,KPGNN不断适应传入的数据,以检测新的事件并更新模型的知识。
3.2 Heterogeneous Social Message Modeling
在预处理过程中,我们的目标是:1)充分利用社交数据,从消息中提取不同类型的信息元素,2)对提取的元素进行统一组织,便于进一步处理。为此,我们利用了异构信息网络(HINs) 。HIN是一个包含不止一种类型的节点和边的图。图1 (a)是HIN的一个例子。

构建异构图:给定一个消息 m i m_i mi,我们从它的文档提取一组命名实体和文字(过滤掉非常常见和非常罕见的单词),提取的元素,以及一组和 m i m_i mi关联的用户和 m i m_i mi本身作为节点添加到HIN。我们在 m i m_i mi和它的边元素之间添加边。 例如,图1 (a),从 m 1 m_1 m1,我们可以提取tweet node m 1 m_1 m1,单词节点包含了fire和tears。 其中用户节点包含了user1和user2。 我们添加了 m 1 m_1 m1和其它节点之间边。我们对所有消息重复相同的过程,合并重复节点。最终,我们得到了一个包含所有信息及其不同类型元素的异构社交图谱。我们表示节点类型,即消息、单词、命名实体和用户分别表示为 m , o , e 和 u m,o,e和u m,o,e和u。
异构节点类型: 现有的异构gnn[18,37,40,43,44]通常在其模型中保留异构节点类型,以学习所有节点的表示。
消息同构图: 而KPGNN作为一个document-pivot模型,专注于学习消息之间的相关性,因此我们采用了不同的设计,将异构的社交图映射为同质的消息图,如图1 ©所示。同构消息图只包含消息节点,共享一些公共元素的消息之间有边。通过映射,同质消息图保留了异构社交图编码的消息相关性。具体来说,映射过程如下:
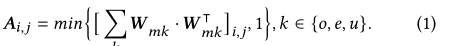
其中,A是同构信息图的邻接矩阵。N是图中的消息总数。 ⋅ i , j ·_{i,j} ⋅i,j表示的是i行j列,k表示的是节点类型。 W m k W_{mk} Wmk是异质社会图邻接矩阵的子矩阵,包含了类型m的行和类型k的列。如果消息 m i m_i mi和 m j m_j mj链接到一些常见类型k节点, [ W m k ⋅ W m k ⊤ ] i , j \left[\boldsymbol{W}_{m k} \cdot \boldsymbol{W}_{m k}^{\top}\right]_{i, j} [Wmk⋅Wmk⊤]i,j将大于或等于1,并且 A i , j A_{i,j} Ai,j将会等于1.
为了利用数据中的语义和时间信息,我们构造了消息的特征向量,如图1(b)所示。具体而言,文档特征计算为文档中所有单词预训练单词嵌入的平均值。通过对时间戳进行编码来计算时间特征:我们将每个时间戳转换为OLE date,OLE date的分数和整数分量构成一个二维向量。然后,我们执行这两个函数的消息连接。得到的初始特征向量,表示为 X = { x m i ∈ R d ∣ 1 ≤ i ≤ N } } , \left.\boldsymbol{X}=\left\{x_{m_{i}} \in \mathbb{R}^{d} \mid 1 \leq i \leq N\right\}\right\}, X={xmi∈Rd∣1≤i≤N}},其中 x m i x_{m_i} xmi是 m i m_i mi的初始特征向量,d是维度,是与相应的消息节点关联。我们将齐次消息图表示为 G = ( X , A ) \mathcal{G}=(X,A) G=(X,A)
注意 G \mathcal{G} G是静态的,当新消息块到达进行检测时(如图2第二阶段所示),我们通过插入新消息节点、它们与现有消息节点的链接和他们内部的链接到 G \mathcal{G} G来更新图。 类似地,我们定期从中删除过时的消息节点和与其相关联的边。在第4节中,我们对不同的更新维护策略进行了实证比较。















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









