







文献阅读:Incremental Event Detection via Knowledge Consolidation Networks
Abstract
- 传统的事件检测方法通常需要一组固定的预定义事件类型。每次新事件到达时,存储所有先前数据并用所有先前数据和新数据重新训练模型是不可行的。
- 然而,现有的增量学习方法无法处理增量事件检测任务中新旧类之间的语义模糊和训练数据不平衡问题。
- 在本文中,提出了一个知识整合网络(KCN)来解决上述问题。具体来说,设计了两个组件,prototype增强的回溯和分层蒸馏。
- 实验结果证明了所提出的方法的有效性,在ACE基准和TAC KBP基准上, F1分数分别比最先进的模型高出19%和13.4%。
Introduction
一个实用的ED系统应该能够逐步学习新的类,而不是需要一组固定的预定义事件类。因此,考虑一种更现实的增量学习设置,其中学习系统从类增量数据流中学习,其中不同事件类的示例在不同时间到达。

增量事件检测的自然方法是简单地根据新数据微调预先训练的模型。然而,这种方法面临着严重的挑战——灾难性遗忘。更具体地说,当一个学习系统适应新的类时,它通常会在旧类上遭受显著的性能下降。例如,在图2中,在对新类(即攻击)的训练数据进行微调之后,更新的模型可以重新记录-初始化攻击事件,但未能检测到死亡事件,这是它最初能够检测到的。

灾难性遗忘解决的方法,这主要可以分为基于参数的方法,这些方法试图识别和保存原始模型(即,在旧类上学习的模型)的重要参数,以及基于重放的方法,它们从每个旧类中保留少量数据。当新的类到达时,存储的数据和新的数据被组合以重新训练模型。由于基于回放的方法非常简单和有效,因此此类方法一直主导着研究。
将基于重放的方法应用于增量事件检测时,我们发现了两个挑战:
- 语义歧义问题
- 类不平衡问题。
语义歧义:
在句子“他离开了公司”中,“离开”一词不仅可以触发结束位置事件,还可以触发运输事件。相比之下,“他辞去了经理的职务”这一例子可以更准确地表达“结束职位”事件,更能代表“结束职位类别”。
Method
Trigger Extractor
KCN模型: Prototype Enhanced Retrospection
Hierarchical Distillation
当出现新的类时,所提出的KCN模型使用保留的旧类数据和新到达类的训练数据的组合来更新参数。prototype增强回溯通过保留最具代表性的示例来保留先前的知识。分层蒸馏将先前的知识从原始模型转移到当前模型。
Trigger Extractor:
Trigger Extractor基于Transformer架构,使用最先进的文本编码器BERT对输入句子进行编码。当新的类到达时,将存储的旧数据和新类数据的训练数据组合起来,以训练当前模型。首先利用BERT来获得每个token的上下文表示,然后在BERT上添加softmax以预测事件类型。通常,采用交叉熵作为损失函数来训练事件检测模型:
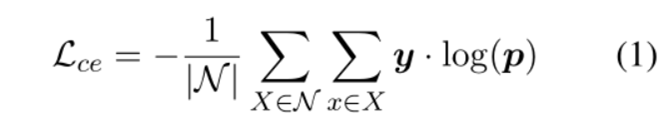
Prototype Enhanced Retrospection:
在模型中,当到目前为止已经学习了m个类,并且B是可以保留在内存中的示例总数时,模型将为每个类存储n=B/m个示例。
由于内存的大小是有限的,当新类到达时,内存单元执行两个操作:
一个是选择代表性示例以保留新类,另一个是删除一些存储的旧类示例以为新类分配空间。
一:将µc作为c类的prototype:
设计了一种基于prototype的选择算法,该工作将prototype称为特征空间中的类代表点。对于每个类,该算法计算每个训练示例与对应prototype之间的距离,然后基于到该类prototype的距离生成一个类的样本的排序列表,选择列表的前n个示例作为示例存储在有界存储器中。
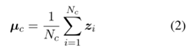
- 直观地说,示例与prototype越接近,示例对类的代表性就越强。
二:假设旧类和新类的数量分别为m和t(t=|𝐶^((𝑘) )|)。内存需要删除B/m−B/(m+t)存储了每个旧类的示例。采用独立于数据的删除策略。对于每个旧类,根据排序的示例列表删除远离prototype的示例。这样,旧类最具代表性的例子仍然保留。
内存的存储大小是恒定的,当新类到达时,内存需要删除旧类的一些保留示例,以便为新类中的示例分配空间。
Hierarchical Distillation:
尽管存储少量旧数据对提高性能非常有用,但新旧类之间的训练样本数量非常不平衡,这使得模型偏向于新类,导致严重遗忘以前的知识。
提出了一种分层蒸馏,以从原始模型中学习先前的知识。核心思想如下:对于相同的输入,如果当前模型能够提取相似的特征,并在先前的类上给出与原始模型相似的预测分布,则可以假设当前模型能够有效地保存先前的知识。
-
Features-level Distillation:使用BERT作为特征提取器,表示为f(·)。对于输入x,原始模型和当前模型的提取特征为
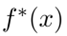 以及
以及 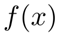 提出了一个特征级蒸馏损失函数:
提出了一个特征级蒸馏损失函数:
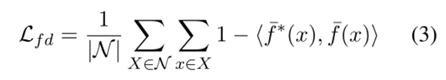
-
Predictions-level Distillation:鼓励旧类上的当前预测与原始模型的软标签匹配来保留分类器的先前知识。预测水平蒸馏损失为:
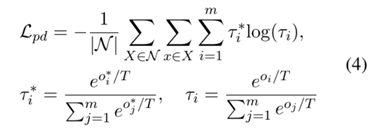
通过为每个类存储最具代表性的示例并减少类不平衡的影响来解决灾难性遗忘问题。结合上述损失,总损失如下所示:
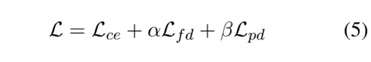


Experiments
与最先进的EMR模型相比,KCN方法在ACE基准和TAC KBP基准上分别实现了19%和13.4%的F1整体得分改进。这表明KCN对于增量事件检测任务非常有效。

保留的样本越多,EMR和KCN的性能越好。尽管在每种情况下,KCN方法的结果都优于EMR。
即使保留了更少的样本,KCN方法仍然获得了比EMR更好的性能,这表明prototype增强的回溯可以选择最具代表性的示例,分级蒸馏可以减少类不平衡的影响。
















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









