







1. Edge Assisted Real-time Object Detection (MobiCom’ 19)
问题&场景
增强现实(AR)通过执行CNN推断来达到对周围环境的准确理解,然而这需要大量计算能力,因而需要将该任务卸载至边缘服务器进行处理。这里以AR中的目标识别为例,显然AR需要将服务器的处理结果回传,而后进行渲染操作,端到端时延越长,最终准确度也越不准确。而上传AR视频本身是需要大量带宽的。本文旨在降低端到端时延,包括传输时延和服务器处理时延。
解决办法
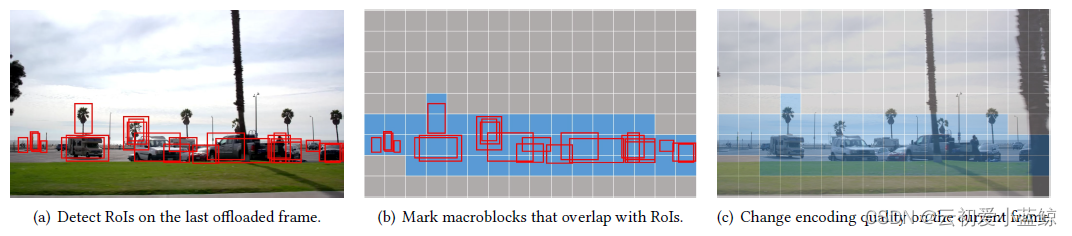
动态ROI编码
idea:从视频内容角度出发,并不是所有像素块都需要高质量编码,只需要将潜在的区域进行高质量编码,其他区域采用低码率编码。
method:采用上一帧的检测结果作为ROI的参照
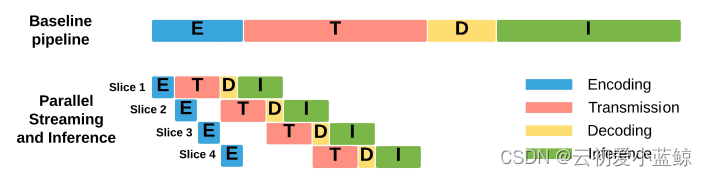
传输和推理的并行化
基于Motion Vector 的目标追踪

自适应卸载
基于两个原则:(1)只有在边缘云已完全接收到先前卸载的帧的情况下,帧才有资格被卸载;(2)如果帧与上次卸载的帧有显著差异,则将考虑卸载。第一个原则可防止网络拥塞,第二个可减少冗余,进而降低传输量。
相似度计算:(1)是否有大的motions出现;(2)是否有大量像素值改变。帧的运动由所有运动矢量的和来量化,并且新像素的数量由编码帧内的帧内预测宏块的数量来估计。
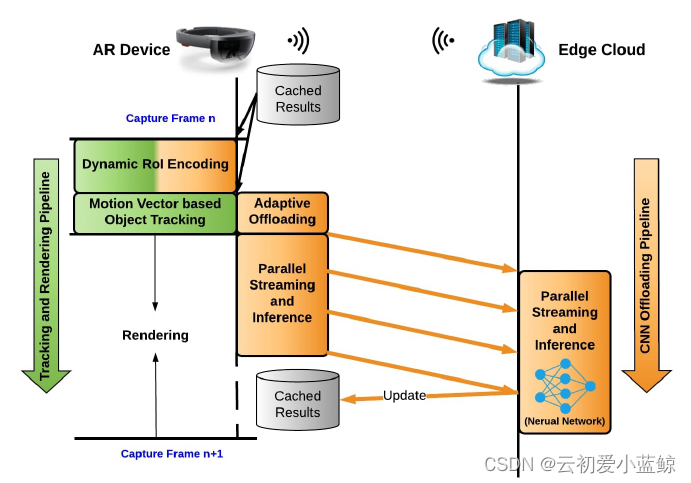
系统架构
2. Focus: Querying Large Video Datasets with Low Latency and Low Cost(OSDI’ 18)
场景
主要是在大规模数据集中找到符合请求的视频,一般来说,请求会附带视频特征,如包含的目标等。如找到过去一周交通视频里的卡车,找到昨天晚上公司摄像头拍下的公人;
问题
- 视频请求任务的执行通常需要运行detector&classifier CNNs,显然用昂贵的CNN会显著增加处理时延和计算开销;
- 在视频收集过程中使用CNN推理,能提高视频请求速度,但代价昂贵,同时也会造成潜在的资源浪费(因为大部分摄像头收集的视频和要求的视频并没有直接联系);
- 在视频请求时进行CNN推理,通过帧下采样、CNN模型优化等手段可降低推理代价,但处理速度依然十分缓慢(处理一个月的视频需要5小时)。
目标
在大规模历史视频数据中,实现低延时和低代价的视频请求
解决方案
基于索引的快速查询
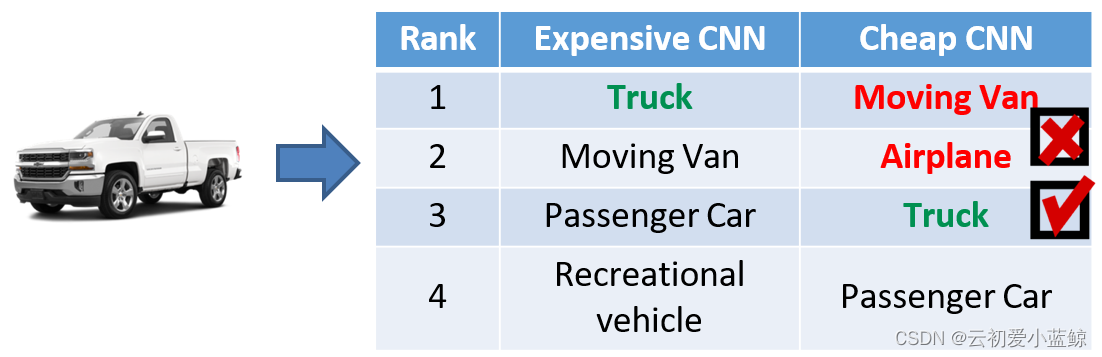
idea:简单CNN虽然有更低的准确度,但是复杂CNN的最好结果也在简单CNN的top-K结果内。如下图所示
 Recall: Fraction of relevant objects that are selected (其实可以理解为与目标类别中被选中的比例)
Recall: Fraction of relevant objects that are selected (其实可以理解为与目标类别中被选中的比例)
Precision: Fraction of selected objects that are relevant(选中的类别中为目标类别的比例)
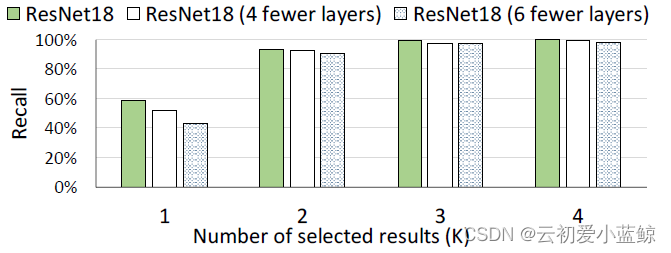
从上图可以看到,随着K的增大,目标类别中,越来越多的类被包括在top-K内。这也意味着,当我们用简单模型初筛时,虽然不能保证百分比检测出目标物体,但是能保证top-K内有目标物体。
工作流程:
 分为两个阶段:(1)Ingest-time:通过简单模型得到top-K物体(按概率排序),每个物体对应当前frame的ID,该步骤可实现高Recall;(2)Query-time:用户发出一个请求(包含目标物体),系统只需要根据目标物体对应的帧ID寻找,并将其送入昂贵的CNN加以确认,该步骤可实现高Precision。
分为两个阶段:(1)Ingest-time:通过简单模型得到top-K物体(按概率排序),每个物体对应当前frame的ID,该步骤可实现高Recall;(2)Query-time:用户发出一个请求(包含目标物体),系统只需要根据目标物体对应的帧ID寻找,并将其送入昂贵的CNN加以确认,该步骤可实现高Precision。
消除索引冗余
挑战:对每一帧都建立一个索引,开销十分巨大,同时查询也很繁琐,耗时高。一个更大的K也会加大增加后续请求的时间
动机:相似图片产生的特征向量也十分相似,如图所示:

方法:通过将相似的目标聚类,从而减小查询时间
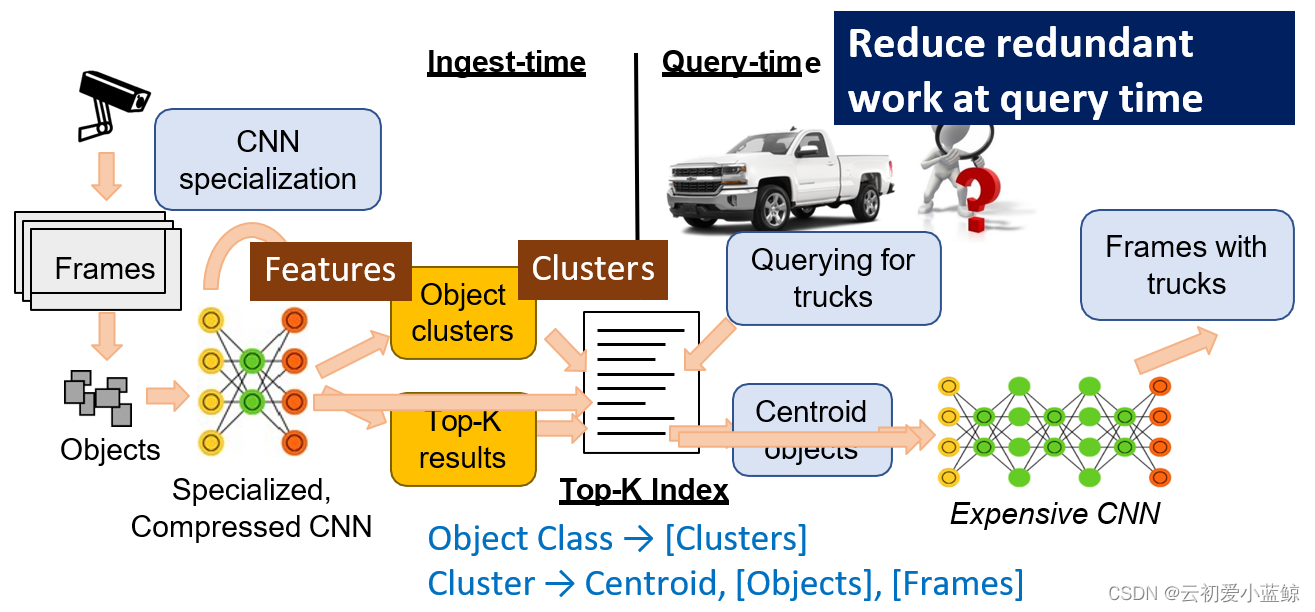 如上图所示,便宜CNN得到所有图片中目标的特征图,并通过聚类算法将相似目标放在一个类别中,每次用户端发出请求,只需在相应的类别中,取出对应的额frame ID进行深度CNN推理,即可得到相应的视频或者图片。
如上图所示,便宜CNN得到所有图片中目标的特征图,并通过聚类算法将相似目标放在一个类别中,每次用户端发出请求,只需在相应的类别中,取出对应的额frame ID进行深度CNN推理,即可得到相应的视频或者图片。
权衡建索引的代价和请求的时延
调整系统中的一些参数:
- Ingest阶段,选择多便宜的CNN?
- 如何选择近似索引top-K中的K?
- 聚类算法中,聚类的距离阈值如何选择?
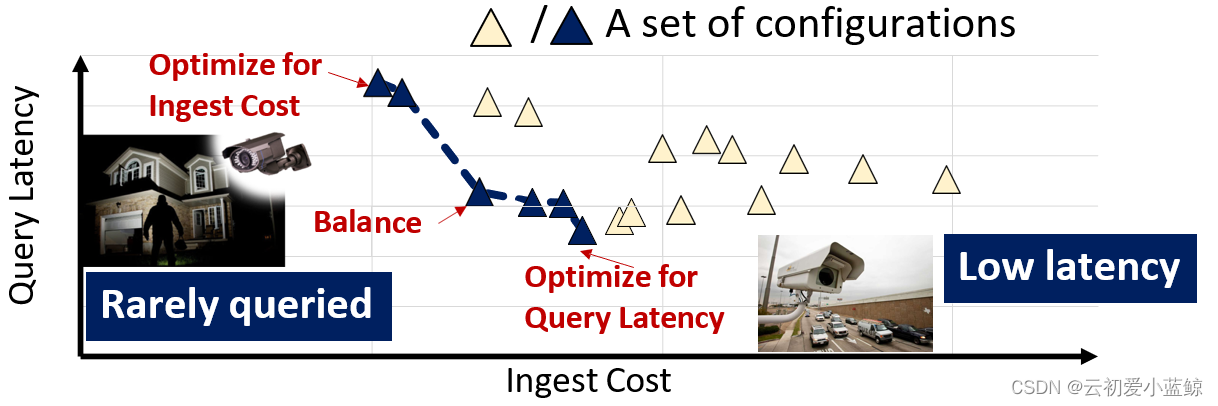 通过计算 Pareto Boundary,即帕累托边界,选择最优配置
通过计算 Pareto Boundary,即帕累托边界,选择最优配置
系统流图
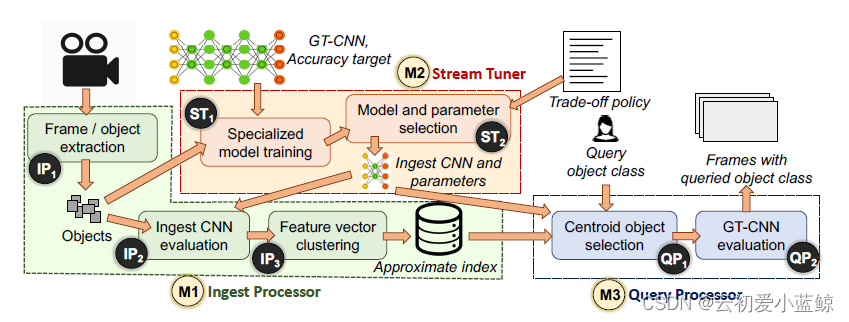
Focus在查询前,都会使用一个简易的CNN建立一个物体到帧ID的索引,在后续阶段,只需将相应的帧送入昂贵CNN进行检验即可。















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









