







1 联邦图学习介绍
简介:
图数据通常分布在多个数据所有者中,由于隐私问题,无法在不同的地方收集图数据。联邦学习是一种分布式学习方案,它使参与者在不共享私人数据隐私的情况下联邦训练一个全局模型。因此将联邦学习与图学习相结合成为解决上述问题的一个很有前景的方案。
图的分类:
根据节点类型和边类型的数量,图可以分为同构图(只包含一种类型的节点和一种类型的边)和异构图(有多种类型的节点或多种类型的边)。

2 联邦图机器学习的类型
类型:

1、具有结构化数据的联邦学习:客户端基于其图数据协同训练机器学习模型,同时将图数据保存在本地。
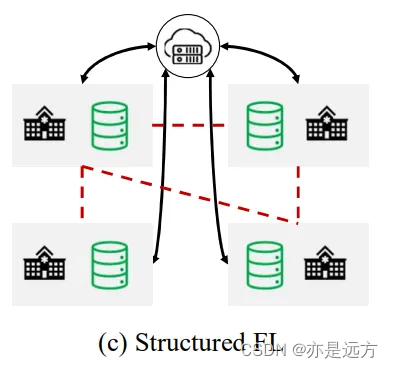
每个客户端可以具有一个(子)图或多个图。
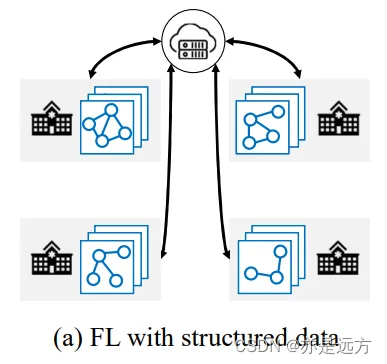
2、结构化联邦学习:客户端之间存在结构信息。
将每个客户端作为一个节点,结构化联邦学习的所有客户端形成一个客户端图。可以利用客户端图来设计更有效的联邦优化方法。
问题挑战:
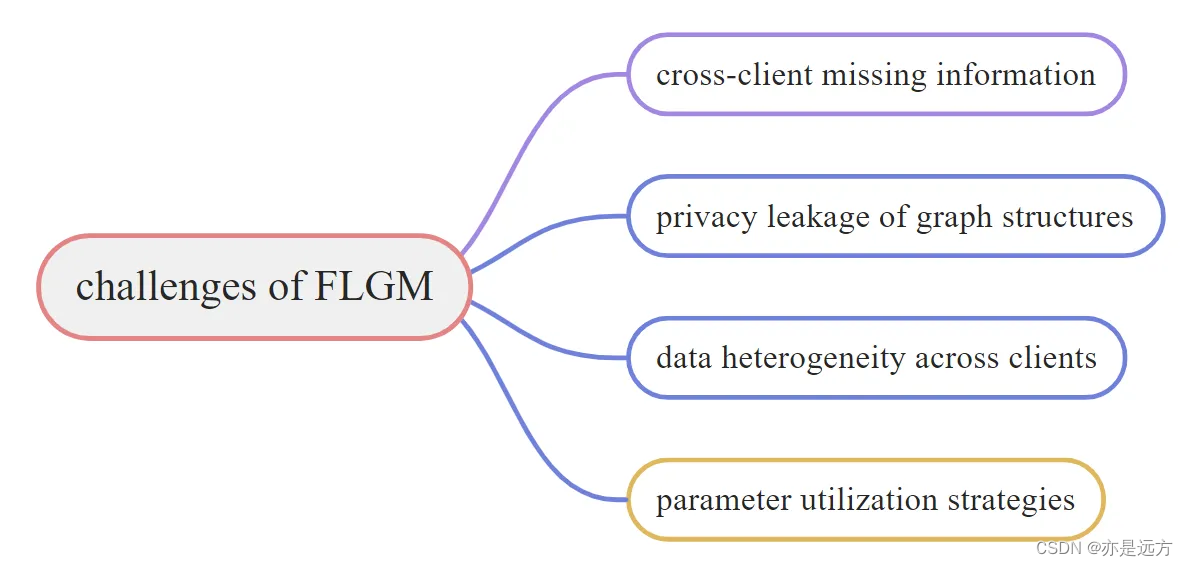
1、跨客户端信息缺失:具有结构化数据的联邦学习的常见场景中,每个客户端都拥有全局图的一个子图,并且一些节点可能具有属于其他客户端的邻居。由于隐私问题,节点只能聚合其客户端内的邻居特征,这导致了节点表示不足。
2、图结构的隐私泄露:具有结构化数据的联邦学习中,结构隐私会通过共享邻接矩阵或传输节点嵌入空间而暴露。
3、跨客户端的数据异构性:不同于传统联邦学习中来自Non-IID数据样本的异构性,联邦图学习数据包含的丰富结构信息也会导致数据异构性。客户端之间不同的图结构会影响图机器学习的性能。
4、参数利用策略:在结构化联邦学习中,客户端图使客户端能够从其邻居客户端获得信息,应设计好充分利用邻居信息的有效策略。
3 具有结构化数据的联邦学习(FL With Structured Data)
3.1 跨客户端信息重构(Cross-Client Information Reconstruction)
当一个图被拆分为多个子图,每个客户端拥有一个子图时,每个节点只能对来自其邻居子集(子图中的邻居)的信息进行聚合。丢失的跨客户端信息导致每个客户端上的节点嵌入有偏差。
根据原始的全局图是否已知,可分为以下两种:
3.1.1 中间结果传输(Intermediate Result Transmission)----中心服务器知道原始的图结构
H
l
=
σ
(
L
H
l
−
1
W
l
)
H^l = \sigma (LH^{l-1}W^l)
Hl=σ(LHl−1Wl)
注:
L
=
(
D
+
I
)
−
1
2
(
A
+
I
)
(
D
+
I
)
−
1
2
L = (D+I)^{-\frac{1}{2}}(A+I)(D+I)^{-\frac{1}{2}}
L=(D+I)−21(A+I)(D+I)−21、
W
l
W^l
Wl为权重矩阵,
H
0
=
X
H^0 = X
H0=X
在 FL 中,重写了上述朴素的 GCN 模型,定义为
H
(
k
)
l
=
σ
(
∑
s
=
1
M
L
(
k
s
)
H
s
l
−
1
W
(
s
)
l
)
H^{l}_{(k)} = \sigma(\sum_{s=1}^{M}L_{(ks)}H_s^{l-1}W^l_{(s)})
H(k)l=σ(s=1∑ML(ks)Hsl−1W(s)l)
k
k
k代表第 k 个客户端,
l
l
l代表第 l 层
3.1.2 缺失邻居生成(Missing Neighbor Generation)—不知道原始的图结构
设计一个缺失邻居生成器(missing neighbor generator),在其他客户端上重建节点的交叉子图邻居的特征。
● 首先每个客户端
c
k
c_k
ck在其局部子图
G
k
G_k
Gk中隐藏节点和相关边的子集,以形成受损子图
G
~
k
\widetilde G_k
G
k。
● 然后每个客户端训练一个由
θ
d
\theta_d
θd参数化的预测器(predictor)和一个由
θ
f
\theta_f
θf参数化的编码器(encoder)(例如GCN)
● 前者用于预测
G
~
k
\widetilde G_k
G
k中每个节点的隐藏邻居数量
n
~
i
\widetilde n_i
n
i,后者用于通过最小化损失来预测隐藏邻居的特征。
KaTeX parse error: Undefined control sequence: \label at position 1: \̲l̲a̲b̲e̲l̲{eqn-3} L^n = \…
其中
L
d
L^d
Ld和
L
f
L^f
Lf分别是隐藏邻居的预测数量及其预测特征的损失函数。
3.2 重叠实例对齐(Overlapping Instance Alignment)
一个实例(instance)可能属于多个客户端。来自不同客户端的重叠实例的嵌入可能来自协同训练期间的不同嵌入空间。重叠实例对齐的关键思想是通过在客户端本地实例嵌入的基础上学习全局嵌入。
3.2.1 基于齐次图的对齐(Homogeneous Graph-Based Alignment)
现有工作主要是在纵向联邦学习(vertical FL)下进行的。有以下两种场景,可以通过在联邦优化过程中同时保护结构信息和原始节点特征来处理这个问题。
场景 1(scenario 1):一组节点位于所有的客户端,但他们的特征和关系在客户端之间不同
VFGNN 算法:
H
←
C
O
M
B
I
N
E
(
{
H
(
k
)
}
k
=
1
M
)
H\leftarrow COMBINE(\{H_{(k)}\}^M_{k=1})
H←COMBINE({H(k)}k=1M)
注:
C
O
M
B
I
N
E
(
⋅
)
COMBINE(·)
COMBINE(⋅)是一个组合操作,如平均(mean)和回归(regression)
场景 1(scenario 1):某客户端只有节点特征,另外的客户端只有图的结构数据
SGNN 算法:用结构化相似矩阵(structural similarity matrix)
A
s
A^s
As 代替原邻接矩阵
A
A
A。
A
i
j
s
A^s_{ij}
Aijs表示节点
v
i
v_i
vi和
v
j
v_j
vj之间的相似度。使用下面的公式定义
A
i
j
s
=
e
x
p
(
−
d
i
s
t
(
O
D
(
N
(
v
i
)
)
,
O
D
(
N
(
v
j
)
)
)
)
A^s_{ij} = exp(-dist(OD(N(v_i)), OD(N(v_j))))
Aijs=exp(−dist(OD(N(vi)),OD(N(vj))))
注:
O
D
(
⋅
)
OD(·)
OD(⋅)返回一组节点的度的有序列表
3.2.2 基于知识图谱的对齐(KG-Based Alignment)
每个客户端拥有一个知识图谱(Knowledge Graph, KG),并且每个KG可能具有也存在于其他客户端上的重叠实体。在每一轮通信之后,服务器从每个客户端收集每个局部嵌入矩阵以更新全局嵌入矩阵。然后,服务器将全局嵌入分发给相应的客户端,用于随后的本地训练。
FedE 算法:使得服务器使用全局实体表(overall entity table)来记录所有来自客户端的唯一实体。
E
t
=
I
⊘
∑
k
=
1
M
v
k
⊗
∑
k
=
1
M
P
(
k
)
E
(
k
)
t
E^t = \mathbb{I} \oslash\sum_{k = 1}^{M}v_k\otimes\sum_{k=1}^{M}P_{(k)}E^t_{(k)}
Et=I⊘k=1∑Mvk⊗k=1∑MP(k)E(k)t
注:
E
t
E^t
Et全局实体嵌入表,
I
\mathbb{I}
I全 1 向量
(3)基于用户项目图的对齐(User-Item Graph-Based Alignment)
伪交互物品采样和局部差分隐私(LDP)技术是两种常见的策略。
3.3 非独立同分布数据适应(Non-IID Data Adaptation)
每个客户端上的数据分布可能在节点特征和图结构方面存在很大差异。这种数据异构性会导致严重的模型差异,从而降低全局模型的性能。现有技术分为基于全局模型的单一方法和基于个性化模型的方法。
(1) 基于单一全局模型的方法( Single Global Model-Based Methods)
基于单一全局模型的方法的目标是在来自客户端的图数据上训练全局图机器学习模型。
设计损失函数:
1、为局部损失函数添加正则化项。
2、实例重加权(最小化局部模型和全局模型之间的损失差异)
联邦学习模型聚合重新加权:在联邦学习的聚合过程中重新加权局部模型,例如在模型聚合阶段为每个客户端的模型参数分配自适应权重。
模型插值:客户端的局部模型是由其上一轮的局部模型和当前轮次全局模型组合得到的。
(2)基于个性化模型的方法(Personalized Model-Based Methods)
与训练单个全局图机器学习模型不同,该方法旨在为每个客户端训练一个个性化的图机器学习模型。
客户端聚类:将具有相似数据分布的客户端放在一个组中,组中的客户端共享相同的模型参数。
4 结构化联邦学习(Structured FL)
4.1 集中式聚合(Centralized Aggregation)
4.2 全分散传输(Fully Decentralized Transmission)
5 一些应用(Appliactions)
6 研究局限性和未来发展方向(Open Challenges And Future Directions)
当前在联邦图机器学习(FGML)的研究中存在一些局限性,并提出了未来进步的有希望的方向:
- 图结构的数据异质性:图结构的非独立同分布(non-IID)特性也是一个关键挑战。尽管少数论文分析了跨客户端的非独立同分布图结构,但很少有完全解决这个问题的。
- 实例嵌入的安全聚合:现有研究主要应用局部差分隐私技术和伪实例采样来减轻因嵌入传输而导致的隐私泄露。然而,这些算法可能因为引入噪声而导致性能下降。因此,在FGML中设计一个既有效又安全的聚合方案仍然是一个开放问题。
- FGML中的通信减少策略:大量的通信开销使得训练FL模型变得困难。进一步的应用研究应更好地考虑通信减少策略,如数据压缩和本地更新。
- FGML中的公平性:公平性是FL中的一个重要话题。在不访问不同客户端中的敏感信息(例如性别和种族)的情况下,FL模型可能对某些数据组表现出明显的偏见。
- FGML中的投毒攻击和防御。对图结构的投毒攻击会影响FGML中的协作训练。设计针对FGML中图结构的有效攻击并防御此类攻击可能是安全性方面一个有前景的话题。
- 基准和平台。与FGML中的适用基准和平台仍处于起步阶段。图被分割为跨越多个客户端的多个子图时。需要来自现实世界的实际分布式图数据,以便进行更实用的图划分。
7 问题
node embeddings 和各种 embeddings 是什么意思?
8 计划
继续看三篇论文















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











