






输入为风机的三个位移surge,sway,heave;输出为导缆孔张力fairlead tension。
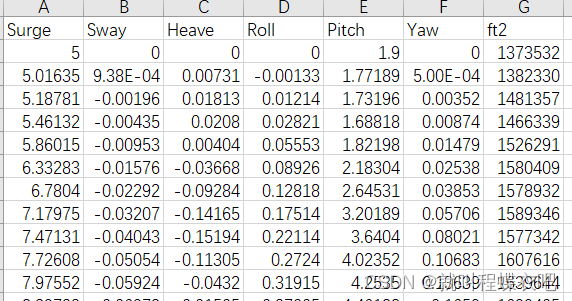
数据进行导入,由于进行MinMaxScaler需要转换为一维数组,所以先将向量reshape(-1,1)然后再squeeze成向量,fairlead不转会向量是因为后边维度对齐需要。heave,sway,surge,roll,pitch,yaw后三个数据这篇文章没有用到。
datasets = pd.read_excel("dataTur2200.xlsx", header=0)
datasets.columns = [
"surge",
"sway",
"heave",
"roll",
"pitch",
"yaw",
"fairlead",
]
heave = datasets.heave.to_numpy()
surge = datasets.surge.to_numpy()
sway = datasets.sway.to_numpy()
roll = datasets.roll.to_numpy()
pitch = datasets.pitch.to_numpy()
yaw = datasets.yaw.to_numpy()
fairlead = datasets.fairlead.to_numpy()
scaler_heave = MinMaxScaler()
scaler_surge = MinMaxScaler()
scaler_sway = MinMaxScaler()
scaler_fair = MinMaxScaler()
heave = np.squeeze(scaler_heave.fit_transform(heave.reshape(-1, 1)))
surge = np.squeeze(scaler_surge.fit_transform(surge.reshape(-1, 1)))
sway = np.squeeze(scaler_sway.fit_transform(sway.reshape(-1, 1)))
fairlead = scaler_fair.fit_transform(fairlead.reshape(-1, 1))然后是create_dataset,这里lookback代表考虑前面多少个时间步长的surge,sway,heave来预测
当前时间步长的fairlead tension,X, y = create_dataset(...)后,X.shape为[n-lookback,lookback,input_feature],n为数据总量,这里为2200(后边截取390到2190,去掉前边部分不稳定的数据),input_feature是输入数据特征数,这里是3(heave,surge,sway)。y.shape = [n-lookback,output_feature],output_feature = 1。
def create_dataset(heave, surge, sway, ft2, lookback):
X, y = [], []
temp = []
for i in range(len(heave)):
temp.append(np.array([heave[i], surge[i], sway[i]]))
for i in range(len(heave) - lookback):
X.append(temp[i:(i + lookback)])
y.append(ft2[i + lookback])
return torch.Tensor(np.array(X)).to(cuda), torch.Tensor(np.array(y)).to(cuda)
X, y = create_dataset(surge, sway, heave, fairlead, lookback)
X = X[390:2190, :]
y = y[390:2190]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
)然后是搭建Module,LSTM+Linear+Relu。
class Module_LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(input_size=3, hidden_size=hidden_size, num_layers=1)
self.linear = nn.Linear(hidden_size, 1)
self.relu = nn.ReLU()
def forward(self, input_seq):
input_seq, _ = self.lstm(input_seq)
input_seq = input_seq[:, -1, :]
input_seq = self.linear(input_seq)
input_seq = self.relu(input_seq)
return input_seq然后是模型的训练
model = Module_LSTM().to(cuda)
optimizer = optim.Adam(model.parameters())
loss_fn = nn.MSELoss()
loss_fn2 = nn.L1Loss()
loader = data.DataLoader(data.TensorDataset(X_train, y_train), shuffle=True, batch_size=10)
n_epochs = 200
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Validation
if epoch % 10 != 0:
continue
model.eval()
with torch.no_grad():
y_pred = model(X_train)
train_rmse = np.sqrt(loss_fn(y_pred.cpu(), y_train.cpu()))
train_mae = loss_fn2(y_pred.cpu(), y_train.cpu())
train_mape = (loss_fn2(y_pred.cpu(), y_train.cpu())) / y_pred.cpu().mean()
y_pred = model(X_test)
test_rmse = np.sqrt(loss_fn2(y_pred.cpu(), y_test.cpu()))
print(type(y_pred.cpu()), y_pred.cpu().mean())
print("Epoch %d: train RMSE %.4f, test RMSE %.4f train MAE %.4f train MAPE %.4f" %
(epoch, train_rmse, test_rmse, train_mae, train_mape))随后是后处理
with torch.no_grad():
train_plot = scaler_fair.inverse_transform(model(X_train).detach().cpu().numpy())
test_plot = scaler_fair.inverse_transform(model(X_test).detach().cpu().numpy())
origin_plot = scaler_fair.inverse_transform(fairlead.reshape(-1, 1))
print(train_plot.shape, test_plot.shape)
pred_plot = np.array(train_plot.tolist() + test_plot.tolist())
# print(pred_plot.shape,origin_plot.shape)
plt.ylim(500000, 2500000)
plt.plot(pred_plot[300:1500])
plt.plot(origin_plot[690:1890])
plt.show()
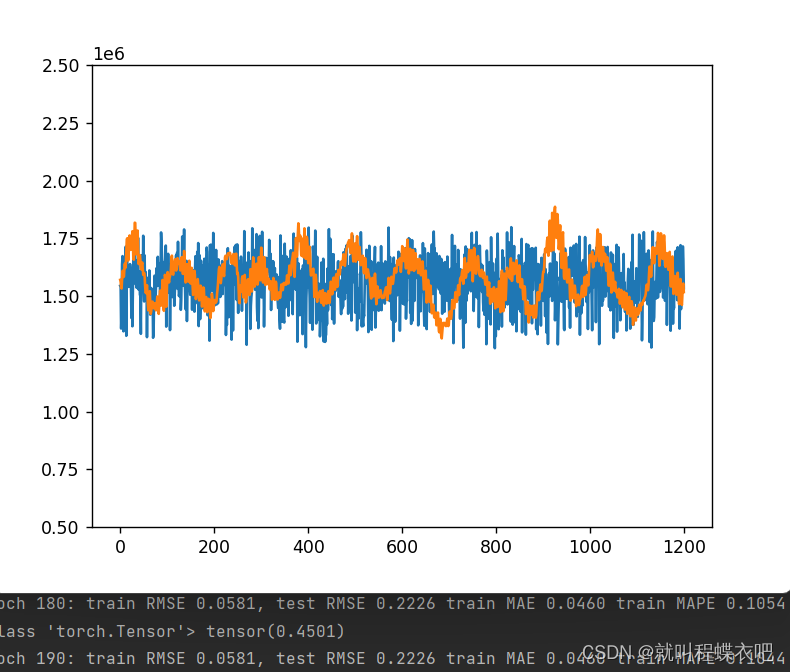
效果不太理想,lookback设置为一会好一点,但好不了太多















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









