






deepseek上传的文件中不包含音频文件,现在将语音识别和deepseek结合一下,
使用的是deepseek的离线api,离线api的配置链接:https://editor.csdn.net/md/?articleId=145481113
实现的功能是:可上传文件后,button1识别语音,button2将识别出的文字发送deepseek,并将回答显示出来
语音识别使用的Whisper,但是Whisper的中文输出默认的繁体字,所以还要使用 opencc 进行简繁转换
安装库
pip install openai-whisper
pip install opencc-python-reimplemented
绘制界面,安装库:
import tkinter as tk
from tkinter import filedialog
代码如下
import tkinter as tk
from tkinter import filedialog
import whisper
import opencc
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch # 导入 torch 模块
from openai import OpenAI
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用 4-bit 量化
bnb_4bit_use_double_quant=True, # 使用双重量化
bnb_4bit_quant_type="nf4", # 量化类型
bnb_4bit_compute_dtype=torch.float16 # 使用 torch.float16
)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
"./deepseek-coder-7b-instruct", # 本地路径
quantization_config=quantization_config,
device_map="auto"
)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("./deepseek-coder-7b-instruct")
file_path_var=""
simplified_text=""
end_text=""
def upload_file():
global file_path_var
file_path_var=filedialog.askopenfilename()
if file_path_var:
label_file.config(text=f"已选择文件: {file_path_var}")
def method_Audio():
global simplified_text
# 加载 Whisper 模型
models = whisper.load_model("medium")
# 识别音频
result = models.transcribe(file_path_var)
# 将繁体转换为简体
converter = opencc.OpenCC('t2s') # t2s: 繁体到简体
simplified_text = converter.convert(result["text"])
print(simplified_text)
def method_DeepSeek():
global end_text
prompt = simplified_text
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
end_text=tokenizer.decode(outputs[0])
method_ShowText(end_text)
def method_ShowText(text):
text_display.delete("1.0", tk.END) # 清空之前的内容
text_display.insert(tk.END, text) # 插入新的文本
# 创建主窗口
root = tk.Tk()
root.title("文件上传界面")
root.geometry("400x300")
# 上传文件按钮
btn_upload = tk.Button(root, text="上传文件", command=upload_file)
btn_upload.pack(pady=10)
# 显示文件路径
label_file = tk.Label(root, text="未选择文件")
label_file.pack()
# Button1 连接方法音频转文字
button1 = tk.Button(root, text="Button1", command=method_Audio)
button1.pack(pady=5)
# Button2 连接方法文字发送给deepseek
button2 = tk.Button(root, text="Button2", command=method_DeepSeek)
button2.pack(pady=5)
# 文本显示框
text_display = tk.Text(root, height=40, width=40)
text_display.pack(pady=10)
# 运行主循环
root.mainloop()
第一次运行会下载模型,会比较慢,其中whisper的模型 tiny, base, small, medium, large几种选择(体量从小到大排列),我使用的是medium,1.4G左右,whisper对于语音中中英文混合识别不行,但是单一语音识别准确率还是可以的
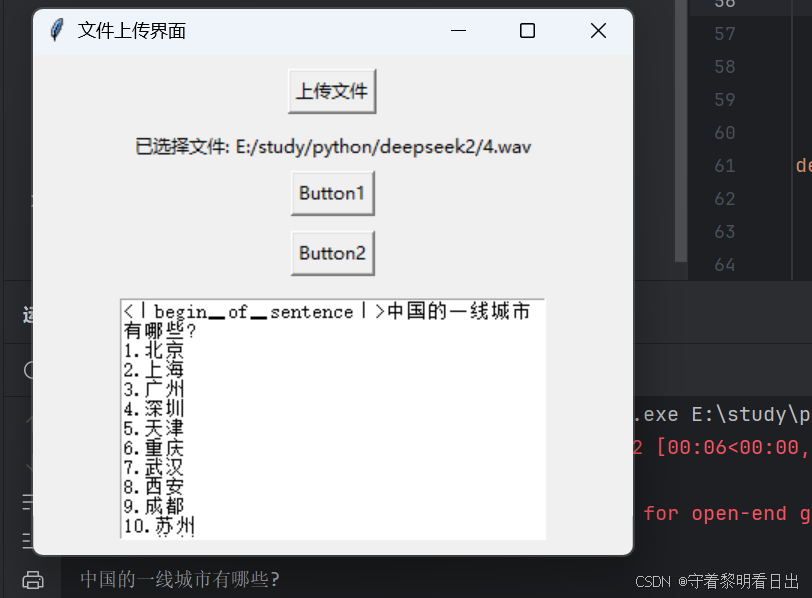
选择上传文件,选择对应音频,点击按钮1识别音频,按钮2deepseek执行,运行结果如下:
传入结果如下:
但是中英文混合识别结果就不行,输入音频:请用python写一个快速排序算法,
先用的文字转音频,所以普通话肯定是标准的,识别出的是:其用Typen写一个快速排序算法

















 1148
1148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









