









文章目录
一、新闻分类任务
1.1 中文数据集
从THUCNews中抽取了20万条新闻标题,已上传至github,文本长度在20到30之间。一共10个类别,每类2万条。数据以字为单位输入模型。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集划分:
| 数据集 | 数据量 |
|---|---|
| 训练集 | 18万 |
| 验证集 | 1万 |
| 测试集 | 1万 |
注意:更换自己的数据集:按照我数据集的格式来格式化你的中文数据集。
1.2 数据特点
训练集有18w条,测试集和验证集均为1w条,每条样本都是20-30个中文汉字。词表直接使用huggingface上的中文词表即可。划分训练测试验证集用如下函数,返回train列表有18w条样本数据,每条样本数据为一个tuple元组,比如train[0]元组大小为4。
def build_dataset(config):
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, test
为了模型后面的训练,先要做文本数据预处理:
- 获取数据后去除非文本部分
- 分词(英文文本则不需要分词)
- 去除停用词
- 对英文单词进行词干提取(stemming)和词型还原(lemmatization),我们这里是中文,不需要做这个
- 构建词表
- 根据词表将文本转为数字
1.3 跑起代码
bert模型放在 bert_pretain目录下,ERNIE模型放在ERNIE_pretrain目录下,每个目录下都是三个文件:
- pytorch_model.bin
- bert_config.json
- vocab.txt
下载地址:
- 预训练模型下载地址:
- bert_Chinese: 模型 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz
- 词表 https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt
来自这里
备用:模型的网盘地址:https://pan.baidu.com/s/1qSAD5gwClq7xlgzl_4W3Pw
- ERNIE_Chinese: http://image.nghuyong.top/ERNIE.zip
来自这里
备用:网盘地址:https://pan.baidu.com/s/1lEPdDN1-YQJmKEd_g9rLgw
解压后,按照上面说的放在对应目录下,文件名称确认无误即可。
【使用说明】下载好预训练模型就可以跑了。
# 训练并测试:
# bert
python run.py --model bert
# bert + 其它
python run.py --model bert_CNN
# ERNIE
python run.py --model ERNIE
参数:模型都在models目录下,超参定义和模型定义在同一文件中。
二、 预训练语言模型ERNIE
2.1 ERNIE模型结构
大模型的痛点:
- 仅考虑单一粒度语义建模,缺乏多粒度知识引入,语义理解能力受限;
- 受限于 Transformer 结构的建模长度瓶颈,无法处理超长文本;
- 聚焦语言等单一模态,缺乏工业真实应用场景针对多个模态如语言、视觉、听觉信息的联合建模能力。
Ernie 2.0是百度在Ernie 1.0基础之上的第二代预训练结构。
模型结构与Ernie 1.0还有 Bert保持一致,12层的transformer的encoder层。
具体可以参考:一文读懂最强中文NLP预训练模型ERNIE
ERNIE:Enhanced Representation through Knowledge Integration
文心 ERNIE 开源版地址:https://github.com/PaddlePaddle/ERNIE
文心 ERNIE 官网地址:https://wenxin.baidu.com/
论文地址:https://arxiv.org/pdf/1904.09223v1.pdf
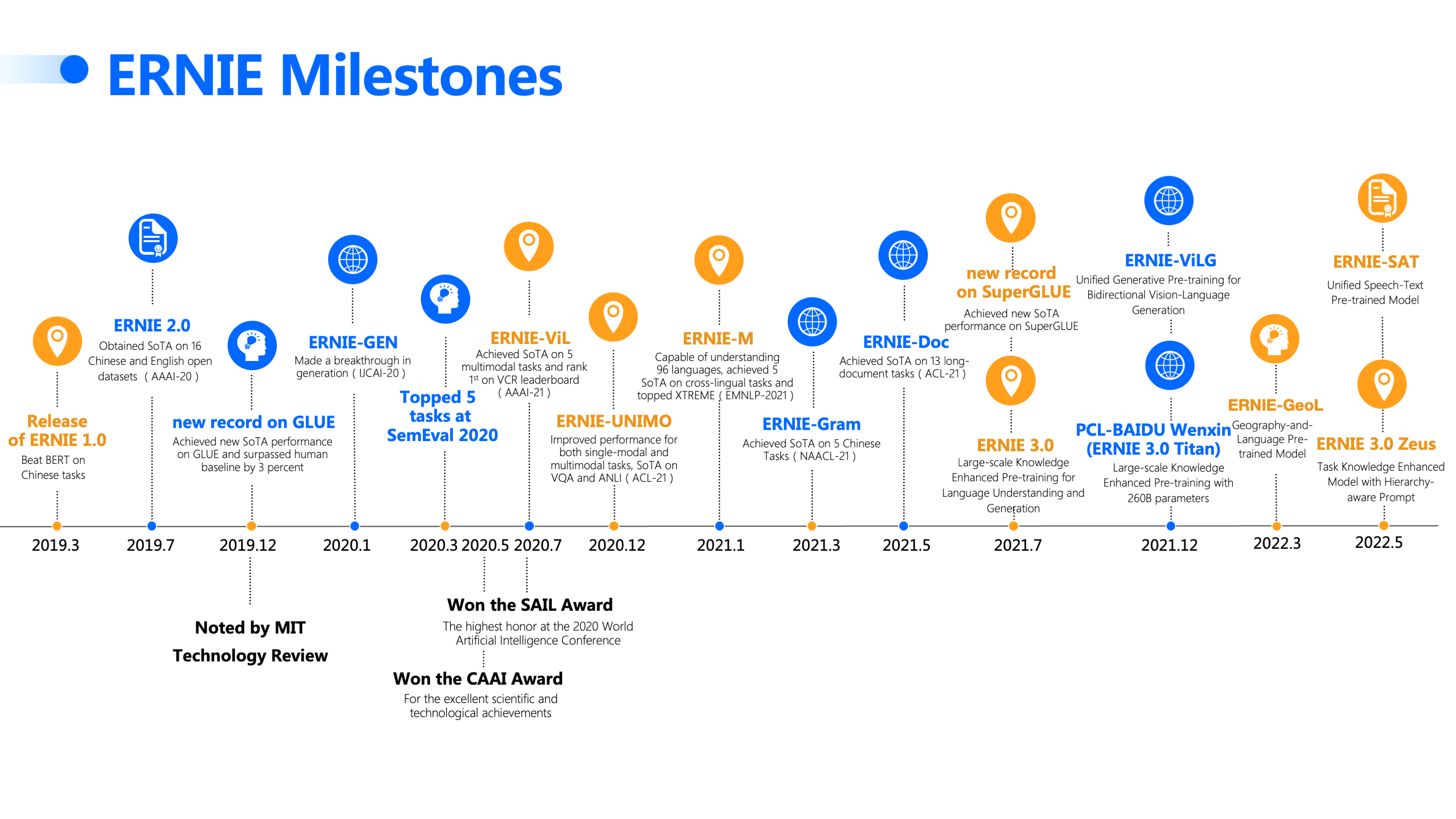
- 受Bert mask策略的启发,提出一种新的语言表示模型,称为ERNIE(Enhanced Representation through Knowledge Integration).ERNIE旨在学习到通过知识屏蔽策略增强的语言表示,其中屏蔽策略包括实体级屏蔽(Entity-level strategy)和短语级屏蔽(Phrase-level strategy)。
- entity-level 策略通常会掩盖由多个单词组成的实体;
- Phrase-level 策略会掩盖由几个词共同作为概念单元的整体短语。
- 实验结果表明,ERNIE优于其他基准方法,在包括自然语言推理、语义相似性、命名实体识别、情感分析、问答系统在内的五个自然语言处理任务上取得了好结果 。作者还证明了ERNIE在完形填空测试中具有更强大的知识推理能力。
- 在绝大多数的研究中,仅仅通过上下文来预测丢失的单词并对其进行建模。 这些模型没有考虑句子中的先验知识。 例如,在句子“哈利·波特是由罗琳(J. K. Rowling)创作的一系列幻想小说”中。 哈利·波特(Harry Potter)是小说的名字,而罗琳(J. K. Rowling)是作家。
- 模型很容易通过实体内部的单词搭配来预测实体Harry Potter的缺失单词,而无需借助较长的上下文。如果模型学习更多有关先验知识的信息,则该模型可以获得更可靠的语言表示。ERNIE不是直接添加知识嵌入(knowledge embedding),而是隐式地学习有关知识和较长语义依赖性的信息,例如实体之间的关系,实体的属性和事件的类型,以指导单词嵌入学习。
2.2 bert模型结构
- 常用的BERT模型其实就是transformer模型的编码器部分,用户为下游任务生成一段话的文本表示。BERT是一个无监督学习的过程,可通过MLM和NSP两种预训练任务实现无监督训练的过程。
- MLM预训练任务:首先随机遮盖或替换一句话中的某个单词,然后让下游模型通过上下文预测被遮盖或替换的单词,最后构建只针对预测部分的损失函数用以训练BERT模型。
- 为防止过拟合并提高模型对文本本身的理解能力,MLM在遮盖或替换单词时,采用混合方式:大部分(80%)单词被遮盖为
[mask],小部分(10%)单词被随机替换为其他单词,另外小部分(10%)单词保持不变。 - ex:比如对于文本”我喜欢打篮球“,在10%概率下MLM会改为如:”我喜欢打咖啡“
- 为防止过拟合并提高模型对文本本身的理解能力,MLM在遮盖或替换单词时,采用混合方式:大部分(80%)单词被遮盖为
- NSP预训练任务:MLM倾向于抽取单词层次的表征,当任务需要句子层级的表征时,则需要NSP任务预训练的模型。NSP目标是预测两个句子之间是否相连:NSP以50%的相连概率从语料库中抽取N对句子,加入
[cls]预测标记和[sep]分句标记后输入BERT模型,使用[cls]预测标记收集到的全局表征进行二分类预测,并使用分类损失优化BERT模型。- ex:比如句子”我喜欢打篮球,尤其是3v3篮球“,NSP任务将其转为:
[cls]我喜欢打篮球[sep]尤其是3v3篮球[sep]。
- ex:比如句子”我喜欢打篮球,尤其是3v3篮球“,NSP任务将其转为:
- MLM和NSP两种预训练任务可以同时进行,都从无标签文本数据中进行构建(即都是自监督学习self-supervision训练),降低数据成本。transformer可并行训练,故BERT可在超大规模语料库上进行训练, 为下游任务提高高质量、可迁移的预训练文本表征支持。
- ex:如还是刚才的句子”我喜欢打篮球,尤其是3v3篮球“,MLM和NSP任务同时进就是
[cls]我喜欢打[mask][sep]尤其是3v3篮球[sep]。
- ex:如还是刚才的句子”我喜欢打篮球,尤其是3v3篮球“,MLM和NSP任务同时进就是

三、项目代码
1. bert模型
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
进入上面forward函数的x列表有3个元素,x[0]是输入的句子,x[2]是mask_tensor,即如果当前句子位置存在元素则为1,否则为0(这0为padding元素)。比如第一个句子有19个中文汉字,first_lst = x[2][0].cpu().numpy(),通过sum([x for x in first_lst])统计到确实是有19个1,剩下全为0。
通过torchinfo.summary看model对象结构如下:
================================================================================
Layer (type:depth-idx) Param #
================================================================================
Model --
├─BertModel: 1-1 --
│ └─BertEmbeddings: 2-1 --
│ │ └─Embedding: 3-1 16,226,304
│ │ └─Embedding: 3-2 393,216
│ │ └─Embedding: 3-3 1,536
│ │ └─BertLayerNorm: 3-4 1,536
│ │ └─Dropout: 3-5 --
│ └─BertEncoder: 2-2 --
│ │ └─ModuleList: 3-6 85,054,464
│ └─BertPooler: 2-3 --
│ │ └─Linear: 3-7 590,592
│ │ └─Tanh: 3-8 --
├─Linear: 1-2 7,690
================================================================================
Total params: 102,275,338
Trainable params: 102,275,338
Non-trainable params: 0
================================================================================
2. ERNIE预训练模型
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
对应的模型结构:
Model(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(18000, 768, padding_idx=0)
(position_embeddings): Embedding(513, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(fc): Linear(in_features=768, out_features=10, bias=True)
)
跑Ernie的文本分类效果是比Bert效果好的:
No optimization for a long time, auto-stopping...
Test Loss: 0.24, Test Acc: 92.54%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9465 0.8840 0.9142 1000
realty 0.9171 0.9510 0.9337 1000
stocks 0.8738 0.8520 0.8628 1000
education 0.9658 0.9590 0.9624 1000
science 0.8395 0.9100 0.8733 1000
society 0.9348 0.9170 0.9258 1000
politics 0.9232 0.9010 0.9119 1000
sports 0.9649 0.9890 0.9768 1000
game 0.9630 0.9360 0.9493 1000
entertainment 0.9335 0.9550 0.9441 1000
accuracy 0.9254 10000
macro avg 0.9262 0.9254 0.9254 10000
weighted avg 0.9262 0.9254 0.9254 10000
Confusion Matrix...
[[884 13 68 3 10 7 10 4 0 1]
[ 9 951 3 0 8 5 5 4 2 13]
[ 31 43 852 1 37 1 25 6 2 2]
[ 1 2 1 959 10 16 3 0 0 8]
[ 3 1 20 4 910 14 8 1 29 10]
[ 2 16 0 10 14 917 22 2 1 16]
[ 2 4 29 10 36 11 901 1 0 6]
[ 0 2 0 1 2 1 1 989 0 4]
[ 1 1 2 1 42 5 1 3 936 8]
[ 1 4 0 4 15 4 0 15 2 955]]
Time usage: 0:00:09
项目完整代码链接稍等放上。
Reference
[1] 百度搜索首届技术创新挑战赛:赛道一
[2] 超详细中文预训练模型ERNIE使用指南
[3] BERT与知识图谱的结合——ERNIE模型浅析
[4] 赛题baseline:使用RocketQA进行篇章检索判定是否存在答案 + 使用 ERNIE 3.0进行阅读理解答案抽取
搜索问答赛道,包含答案抽取和答案检验两大任务。
Coggle阿水:https://aistudio.baidu.com/aistudio/projectdetail/5013840
致Great:https://aistudio.baidu.com/aistudio/projectdetail/5043272
洪荒流1st:https://aistudio.baidu.com/aistudio/projectdetail/4960090
[5] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[6] ERNIE: Enhanced Representation through Knowledge Integration
[6] 百度文心大模型ERNIE:https://github.com/PaddlePaddle/ERNIE
[7] https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
[8] 一文读懂最强中文NLP预训练模型ERNIE.飞桨
[9] 超详细的 Bert 文本分类源码解读 | 附源码
[10] pytorch的bert预训练模型名称及下载路径
[11] 记一次工业界文本分类任务的尝试(文本分类+序列标注+文本抽取)
[12] NLP学习之使用pytorch搭建textCNN模型进行中文文本分类
[13] Pytorch实现中文文本分类任务(Bert,ERNIE,TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention, DPCNN, Transformer)
[14] 领域自适应之继续预训练demo.预训练模型加载
[15] 百度飞桨项目:基于BERT的中文分词
[16] https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert
[17] NLP&深度学习:PyTorch文本分类
[18] 自然语言处理 — Bert开发实战 (Transformers)
[19] BERT模型实战之多文本分类(附源码)
[20] 使用chatGPT看论文:https://www.humata.ai/
[21] 四大模型」革新NLP技术应用,百度文心ERNIE最新开源预训练模型
[22] 论文解读 | 百度 ERNIE: Enhanced Representation through Knowledge Integration
[23] 预训练模型之Ernie2.0. 某乎
[24] 预训练模型(四)—Ernie
[25] https://wenxin.baidu.com/















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











