







 文章探讨了在数据有限的条件下如何进行有效表示学习,尤其是多模态数据的融合,包括基于简单操作的融合、注意力机制和双线性池化。重点介绍了双线性CNNs在细粒度识别中的应用,以及如何通过紧凑双线性池化减少计算复杂性。此外,提到了多模态Transformer的预训练方法,如BERT,以及如何通过缺失模态的提示学习来增强模型的鲁棒性。
文章探讨了在数据有限的条件下如何进行有效表示学习,尤其是多模态数据的融合,包括基于简单操作的融合、注意力机制和双线性池化。重点介绍了双线性CNNs在细粒度识别中的应用,以及如何通过紧凑双线性池化减少计算复杂性。此外,提到了多模态Transformer的预训练方法,如BERT,以及如何通过缺失模态的提示学习来增强模型的鲁棒性。
文章目录
- 1.Data and Label Efficient Representation Learning
- 2.On the Benefits of Early Fusion in Multimodal Representation Learning
- 3.Multimodal Intelligence: Representation Learning,Information Fusion, and Applications
- 4.Bilinear CNNs for Fine-grained Visual Recognition
- 5.Compact Bilinear Pooling
- 6.Multimodal Prompting with Missing Modalities for Visual Recognition
- 7.Multimodal Learning with Transformers: A Survey
- 8.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 池化部分
- 7.Multimodal Learning with Transformers: A Survey
- 池化部分
1.Data and Label Efficient Representation Learning
-
这篇文章有助于写未来发展方向
Data efficient representation learning focuses on learning useful representations with less data (labeled or unlabeled), which as discussed throughout this dissertation, can be particularly important for applications with limited data availability. Label efficient representation learning focuses on learning useful representations with little or no human annotations for the training data. As will be discussed, this is important for applications where it is often difficult or impossible to obtain accurately labeled data, such as in privacy sensitive fields or for applications with highly ambiguous label definitions.-
如何利用低质量的多模态数据进行融合也是一个未来的研究方向
-
数据高效表示学习关注于用较少的数据(标记或未标记)学习有用的表示,如贯穿本论文所讨论的,这对于具有有限数据可用性的应用可能特别重要;标记有效表示学习关注于学习对训练数据具有很少或没有人工注释的有用表示。
-
-
主要包括四部分
- 自增强(SelfAugment):用于自监督学习的自动增强策略,探索了如何使用很少/没有标记的训练数据和少量未标记的数据为无监督学习管道开发增强策略。
- 数据有效的自我监督的表征学习(Data Efficient Self-Supervised Representation Learning),探索如何利用一种形式的分层预训练的80倍以上的数据有效的预训练。
- 区域相似性表示学习(Region Similarity Representation Learning),其通过在区域(基于块)级执行对比学习来探索用于学习区域级表示的第一方法之一,并且当很少有标记数据可用时,使得下游任务(例如对象检测/分割)得到实质性改进。
- Scale-MAE:一个用于多尺度地理空间表示学习的尺度感知掩蔽自动编码器,探索利用已知尺度信息进行地理空间表示学习的方法。
2.On the Benefits of Early Fusion in Multimodal Representation Learning
-
为了便于早期多模融合的研究,这篇文章创建了一个卷积LSTM网络架构,该架构同时处理音频和视频输入,并允许选择音频和视频信息组合的层。该立即融合模型(C-LSTM体系结构)研究了融合深度对噪声鲁棒性的影响。
-
immediate fusion立即融合可以加入到第二章去
-
inductive bias归纳偏置
-
一个密切相关的领域是多视图学习。虽然这两个领域有很大的重叠,但多视图学习强调从相同的输入模式获得不同的视图。一个典型的例子是从两个视角捕获相同的场景(两个视图都使用视觉模态)。
-
为了保持这些模态特异性归纳偏置的优点,同时也允许音频和视频输入的立即融合,这篇文章创建了一个多模态卷积长短时记忆网络,该网络生成具有适当归纳偏置的音频-视频融合表示。这个卷积长期短期记忆(简称C-LSTM)架构结合了传统卷积神经网络和传统长短期记忆网络中的卷积特性。
-

-
前两层为多模态卷积长短期记忆网络,以及用于计算门和更新值的方程。ft是遗忘门,it是输入门,gt是单元门,ot是输出门。W是对应的权重矩阵,b是对应的偏置值。σ()是S形函数。tanh()是双曲正切函数。
-
在卷积的每个点,第一层取:
- 输入图像的部分要乘以卷积核,记为v。
- 隐藏状态的部分要乘以卷积核,记为ht − 1。对于第一层中的第一个时间步长,其被初始化为零。
- 音频输入在给定时间步长的声谱值表示为at。
-
然后该模型使用上图“Initial LSTM Gate Values”公式计算LSTM门值:v、ht−1和at。初始的C-LSTM层产生一个单一的多模态张量,该张量组合了来自音频和视觉输入的信息。 与标准LSTM体系结构一样,前一层的隐藏状态ht被用作当前层的输入xt。 因此,在后续的LSTM层中,每个位置的门值都是从组合多模态输入xt的部分乘以卷积核来计算的。
-
在随后的 Subsequent LSTM Gate Values部分,通过在卷积的每个位置应用LSTM操作,该结构允许LSTM单元响应来自视觉域的空间信息以及音频域的时间信息。这种架构使我们能够研究初始层、第二层和完全连接层的信号融合,同时保持有利于处理图像和序列数据的相同归纳偏置。
-
3.Multimodal Intelligence: Representation Learning,Information Fusion, and Applications
- intelligent personal assistant(IPA)智能个人助理,这里可以写在论文里
- 《多模态智能:表示学习、信息融合及其应用》
- 这篇文章提供了多模态智能的可用模型和学习方法的技术综述。视觉与自然语言的结合是目前计算机视觉和自然语言处理领域的研究热点。这篇综述从三个新的角度—学习多模态表示、多模态信号在各个层面的融合和多模态应用,对多模态深度学习的最新工作进行了全面分析。
- 这篇文章回顾了基于深度学习的多模态建模和机器学习领域,特别是视觉和自然语言的结合。
- 多模态融合主要讨论了注意力机制和双线性池化等特殊架构
- 这篇论文Introduction部分首先讲了单模态的处理,然后讲了多模态的处理,最后一段介绍这篇文章的结构
数据融合章节
只看了数据融合部分
基于简单操作的融合
- 直接连接(concatenation)
- 加权和(weighted sum)
基于注意力机制
1.图片注意力机制
- 基于RNN的编码器-解码器模型
- 堆叠式注意力网络(SANs)
- 空间存储网络(SMem)
- 动态记忆网络(DMN)
- 自下而上和自上而下的注意力方法(Up-Down)
- 图像注意力机制的逆过程
2.图片和文本协同注意力机制
- 平行协同注意力机制和交替协同注意力机制
- 双重注意力网络(DAN)
- 堆叠潜在注意力机制(SLA)
- 双循环注意力单元(DRU)
3.双模态Transformer注意力机制
- BERT->
- OmniNet->
- LXMERT->
- ViLBERT
4.其他注意力机制
- 门控多模态单元
- 多模态残差网络(MRN)
- 动态参数预测网络(DPPnet)
基于双线性池化
双线性池化的因式分解
- 多模态紧致双线性池(MCB)
- 多模态低秩双线性池(MLB)
- 多模态分解双线性池(MFB)
- 多模态分解高阶池化(MFH)
- MUTAN,基于张量的多模态Tucker分解方法
- BLOCK,分块超对角融合框架。BLOCK也可以认为是MUTAN的改进版
双线性池化和注意力机制结合
双线性池可以与注意机制一起使用。
4.Bilinear CNNs for Fine-grained Visual Recognition
- 作者提出了Bilinear Convolutional Neural Networks(B-CNNs)用于细粒度的视觉识别问题,这个网络将一个图片表示为来自于两个CNN特征的池化外积,并且以平移不变的方式捕获局部化特征交互。
- 双线性特征的一个缺点是存储高维特征的内存开销。
介绍
- 细粒度识别即对隶属于同一类的目标进行分类,包括鸟的物种识别、汽车的型号识别和狗的品种识别。细粒度识别高度依赖目标的局部特征。例如,要将“加利福尼亚鸥”与“环嘴鸥”区分开来,需要识别其喙上的图案或它们羽毛的细微颜色差异。
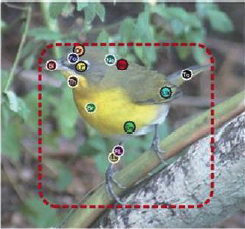
- 有两大类技术对这些任务是有效的:
- 一是局部模型,这些模型检测并提取局部的特征进行细粒度的类别区分
- 另一种方法是基于全局图像的整体模型。
- 之前方法的不足:
- 基于CNN的局部模型要求对训练图像局部标注,代价昂贵,并且某些类没有明确定义的局部特征,如纹理及场景。
- 虽然传统的SIFT纹理表示和最近的CNN特征表示在细粒度目标分类上也比较有效,但仍然达不到基于局部的方法的分类效果。其可能原因就是纹理表示的重要特征并没有通过端到端训练获得,因此在识别任务中没有达到最佳效果。
- 为了解决现有的深度纹理表示的几个缺点,文章提出了Bilinear CNNs.
- 洞察点:某些广泛使用的纹理表征模型都可以写作将两个合适的特征提取器的输出,外积之后,经池化得到。
- 首先,(图像)先经过CNNs单元提取特征,之后经过双线性层及池化层,其输出是固定长度的高维特征表示,其可以结合全连接层预测类标签。最简单的双线性层就是将两个独立的特征用外积结合。这与图像语义分割中的二阶池化类似。
- 实验结果:作者在鸟类、飞机、汽车等细粒度识别数据集上对模型性能进行测试。表明B-CNN性能在大多细粒度识别的数据集上,都优于当前模型,甚至是基于局部监督学习的模型,并且相当高效。
用于图像分类的B-CNN
B-CNN 架构
-
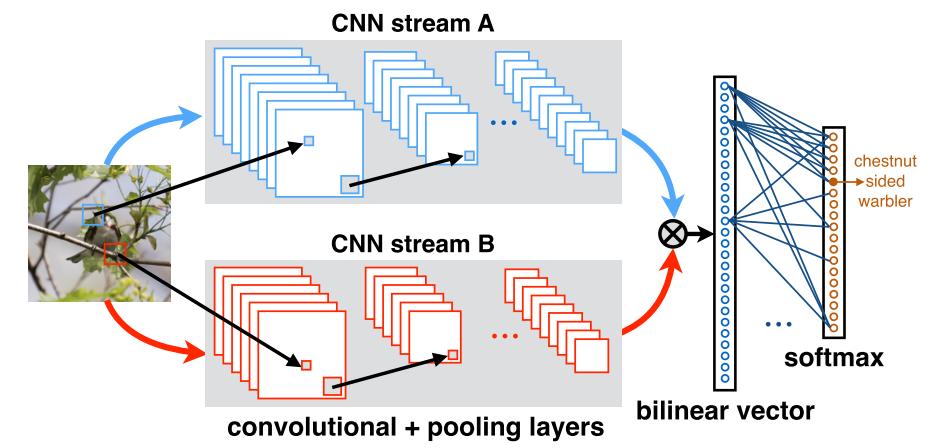
基于 B-CNN 的图像分类。将图像分别通过神经网络 A 和 B,利用矩阵外积和平均池化相结合的方法得到图像的双线性特征表示。这将通过一个线性和 softmax 层来获得类预测。
-
两个不同的stream代表着通过CNN得到的不同特征,然后将两个特征进行bilinear 操作。用于图像分类的 B-CNN 包含四部分:
B = ( f A , f B , P , C ) \mathcal{B}=\left(f_A, f_B, \mathcal{P}, \mathcal{C}\right) B=(fA,fB,P,C)
其中 f A \ f_A fA和 f B \ f_B fB分别表示基于CNN的特征提取函数,P是池化函数, C \mathcal{C} C是分类函数。 f : L × I → R K × D \ f: \mathcal{L} \times \mathcal{I} \rightarrow \mathbb{R}^{K \times D} f:L×I→RK×D,输入图像I和位置L,得到大小为K × D的输出特征。位置通常是可以包含位置和尺度。通过矩阵外积得到每个位置的输出特征,即位置 l \ l l处的特征 f A \ f_A fA和 f B \ f_B fB的双线性结合为:
bilinear ( l , I , f A , f B ) = f A ( l , I ) T f B ( l , I ) \text { bilinear }\left(l, I, f_A, f_B\right)=f_A(l, I)^T f_B(l, I) bilinear (l,I,fA,fB)=fA(l,I)TfB(l,I)
注意 f A \ f_A fA和 f B \ f_B fB必须具有相同的特征维数 K 才能兼容。池化函数 P \ P P的作用是在不同的位置L处的特征进行整合,来得到图片的全局信息 Φ ( I ) \Phi(I) Φ(I)。作者使用的是sum池化,即:
Φ ( I ) = ∑ l ∈ L bilinear ( l , I , f A , f B ) = ∑ l ∈ L f A ( l , I ) T f B ( l , I ) \Phi(I)=\sum_{l \in \mathcal{L}} \text { bilinear }\left(l, I, f_A, f_B\right)=\sum_{l \in \mathcal{L}} f_A(l, I)^T f_B(l, I) Φ(I)=l∈L∑ bilinear (l,I,fA,fB)=l∈L∑fA(l,I)TfB(l,I)
由于在进行池化处理的过程中忽略了特征的位置,因此bilinear特征 Φ ( I ) \Phi(I) Φ(I)是一个无序表示。如果 f A \ f_A fA和 f B \ f_B fB分别提取尺寸为 K × M 和 K × N 的特征,则 Φ ( I ) \Phi(I) Φ(I)的尺寸为 M × N。- 通俗一点讲,就是对图像上的每个位置上的特征进行矩阵相乘,然后进行sum pooling 或者进行max-pooling。
-
特征函数
特征函数 f 的一个候选是由卷积层和池层的层次结构组成的 CNN。B-CNN中的特征函数 f A \ f_A fA和 f B \ f_B fB可以不共享/部分共享/完全共享

-
归一化和分类函数
对bilinear特征 x = Φ ( I ) x = \Phi(I) x=Φ(I)求带符号的平方根操作,即
y ← sign ( x ) ∣ x ∣ \mathbf{y} \leftarrow \operatorname{sign}(\mathbf{x}) \sqrt{|\mathbf{x}|}\ y←sign(x)∣x∣
然后再进行L2正则化操作
z ← y / ∥ y ∥ 2 \mathbf{z} \leftarrow \mathbf{y} /\|\mathbf{y}\|_2 z←y/∥y∥2
这样做可以提升模型性能。分类函数使用logistic regression 或 linear SVM,作者发现线性分类模型SVM对于bilinear特征的分类效果较好。
-
端到端训练
B-CNN可以端到端的方式进行训练。因为整个结构是一个有向无环图,参数可以通过分类损失梯度的反向传播来训练(例如,交叉熵)。双线性形式简化了梯度计算。假设 dl/dx 是损失函数l相对于 x 的梯度,那么根据梯度的链式法则可以得到:
d ℓ d A = B ( d ℓ d x ) T , d ℓ d B = A ( d ℓ d x ) \frac{d \ell}{d A}=B\left(\frac{d \ell}{d \mathbf{x}}\right)^T, \quad \frac{d \ell}{d B}=A\left(\frac{d \ell}{d \mathbf{x}}\right) dAdℓ=B(dxdℓ)T,dBdℓ=A(dxdℓ)
只要能够有效地计算特征 A 和特征 B 的梯度,整个模型就能够以端到端的方式进行训练。该方案如下图所示。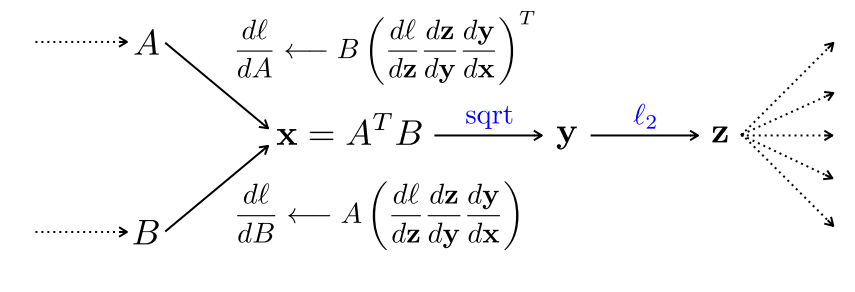
-
Bilinear model 可以看做是其他特征算子(BOW,FV,VLAD)的通用形式。
降维
B-CNN计算了特征的外积,这样原始输出为512维特征的模型经过外积之后的特征变成了512 × 512 ≈ 262 k,特征是高度冗余的。对于 B-CNN,考虑在特征 x 和 y 之间计算外积的情况。为了减小计算量,可以采取下述几种降维方法:
- 先外积后降维,即 Φ ( x , y ) = vec ( x T y ) P \Phi(\mathrm{x}, \mathrm{y})=\operatorname{vec}\left(\mathrm{x}^{\mathrm{T}} \mathrm{y}\right) \mathrm{P} Φ(x,y)=vec(xTy)P,vec操作将外积矩阵变换成向量,P表示降维的映射矩阵;
- 先降维后外积,即 Φ ( x , y ) = ( x A ) T ( x B ) \Phi(\mathrm{x}, \mathrm{y})=(\mathrm{xA})^{\mathrm{T}}(\mathrm{xB}) Φ(x,y)=(xA)T(xB),A,B均表示降维映射矩阵;
- 对其中一个特征降维再计算外积,假如对x进行降维处理,则设置B为单位矩阵。
上述三种方法中,降维映射矩阵都可以使用PCA得到。第一种方法比较直观,但是PCA的计算量很大,因为外积的维度为d2,4。第二种方法计算量小,但是准确率损失的太大。多实验中发现第三种方法效果最好。降维矩阵使用PCA进行初始化,但是可以与分类层联合地训练它们。
作者还比较了PCA方法与最近提出的紧凑双线性池(Compact Bilinear Pooling,CBP)技术,PCA方法略差于CBP。CBP使用特征稀疏线性投影与张量草图(Tensor Sketch)的乘积来近似外积。然而,PCA的一个优点是可以实现为密集矩阵乘法,经验上比CBP快1.5倍,CBP涉及计算傅里叶变换及其逆运算。
5.Compact Bilinear Pooling
摘要
双线性模型在语义分割、细粒度识别和人脸识别等视觉任务中表现出了令人印象深刻的性能。然而,双线性特征是高维的,通常在几十万到几百万的数量级,这使得它们对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









