






本文原创笔记,禁止转载。有问题可私信付费找我咨询。

直接插入法的基本步骤
步骤1:计算初始估计(Pilot Estimate)
- 选择一个初始的带宽矩阵 G \mathbf{G} G 和核函数 L L L 。
- 计算初始密度估计:
f ~ ( x , G ) = 1 n ∑ i = 1 n L G ( x − X i ) \tilde{f}(x, \mathbf{G}) = \frac{1}{n} \sum_{i=1}^{n} L_{\mathbf{G}}(x - X_i) f~(x,G)=n1i=1∑nLG(x−Xi)
这里 L G ( x − X i ) L_{\mathbf{G}}(x - X_i) LG(x−Xi) 表示使用带宽矩阵 G \mathbf{G} G 的核函数 L L L 。
步骤2:估计未知量 ∥ Δ f ∥ L 2 2 \|\Delta f\|_{L_2}^2 ∥Δf∥L22
- 计算初始估计的拉普拉斯量
Δ
f
~
(
x
,
G
)
\Delta \tilde{f}(x, \mathbf{G})
Δf~(x,G)
具体计算方式依赖于你的核函数和数据分布,可以使用数值微分或其他方法。 - 计算初始估计的
L
2
L_2
L2 范数的平方:
∥ Δ f ~ ( ⋅ ; G ) ∥ L 2 2 = ∫ R d ( Δ f ~ ( x , G ) ) 2 d x \|\Delta \tilde{f}(\cdot; \mathbf{G})\|_{L_2}^2 = \int_{\mathbb{R}^d} (\Delta \tilde{f}(x, \mathbf{G}))^2 dx ∥Δf~(⋅;G)∥L22=∫Rd(Δf~(x,G))2dx
这个步骤通常需要使用数值积分来计算。
步骤3:带入公式计算带宽矩阵 h A M I S E \mathbf{h}_{AMISE} hAMISE
- 使用估计的
∥
Δ
f
~
(
⋅
;
G
)
∥
L
2
2
\|\Delta \tilde{f}(\cdot; \mathbf{G})\|_{L_2}^2
∥Δf~(⋅;G)∥L22 ,带入带宽选择公式:
h A M I S E = ( d ∥ K ∥ L 2 2 n μ 2 ( κ ) 2 ∥ Δ f ~ ( ⋅ ; G ) ∥ L 2 2 ) 1 d + 4 h_{AMISE} = \left( \frac{d \|K\|_{L_2}^2}{n \mu_2(\kappa)^2 \|\Delta \tilde{f}(\cdot; \mathbf{G})\|_{L_2}^2} \right)^{\frac{1}{d+4}} hAMISE=(nμ2(κ)2∥Δf~(⋅;G)∥L22d∥K∥L22)d+41
这里:
- d d d :数据的维度。
- ∥ K ∥ L 2 2 \|K\|_{L_2}^2 ∥K∥L22 :核函数 K K K 的 L 2 L_2 L2 范数的平方,可以通过先验知识或数值计算得到。
- n n n :样本数量。
- μ 2 ( κ ) \mu_2(\kappa) μ2(κ) :二阶矩,这也是先验知识或数值计算得到。
总结
- 初始带宽矩阵选择:选择一个初始的带宽矩阵 G \mathbf{G} G ,比如可以使用Silverman’s规则或Scott’s规则。
- 初始密度估计:计算初始密度估计 f ~ ( x , G ) \tilde{f}(x, \mathbf{G}) f~(x,G) 。
- 估计拉普拉斯量:计算初始密度估计的拉普拉斯量,并计算其 L 2 L_2 L2 范数的平方。
- 计算最终带宽矩阵:将上一步得到的估计值带入带宽选择公式,得到最终的带宽矩阵 h A M I S E \mathbf{h}_{AMISE} hAMISE
计算
∥
Δ
f
^
(
⋅
,
G
)
∥
L
2
2
\lVert \Delta \hat{f}(\cdot, G) \rVert^2_{L_2}
∥Δf^(⋅,G)∥L22 可能涉及复杂的数值计算,尤其是在多维数据的情况下。
选择合适的
G
G
G 和
L
L
L 对最终带宽选择的精度和核密度估计的质量有显著影响。

核密度图的区别
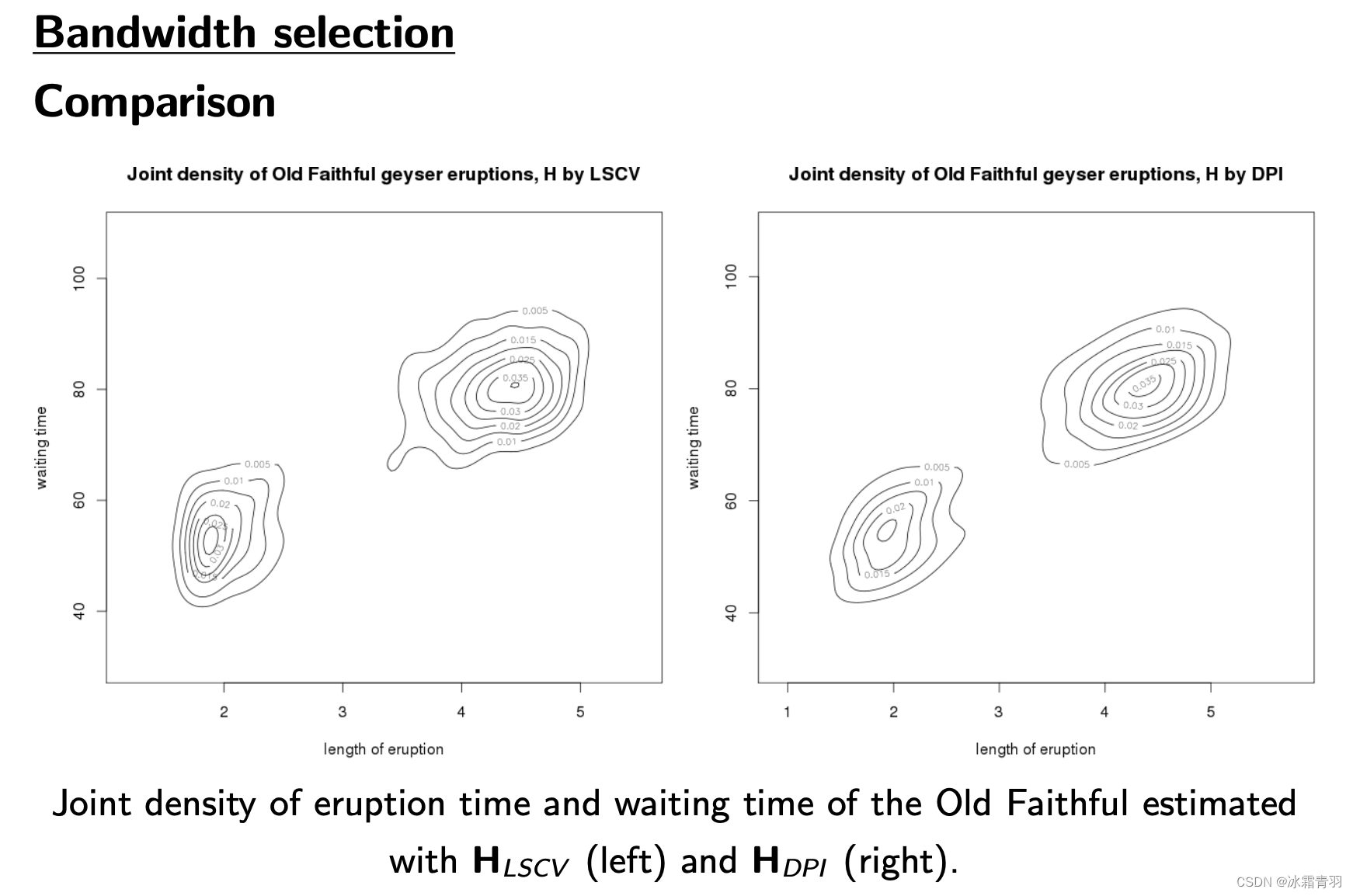
- 等高线的密集程度:
在使用 LSCV 方法的图中,等高线在某些区域更为密集,尤其是中心区域,表明数据点在这些区域集中度更高。
使用 DPI 方法的图中,等高线相对更分散,尤其是在较大等待时间的区域,显示了更宽的密度分布。 - 细节的捕捉:
LSCV 方法得到的图形显示了更多的细节变化,尤其是在等待时间较短的区域。
DPI 方法则在等待时间较长的区域展现了更平滑的过渡,可能更适合揭示大尺度的数据分布特征。
带宽矩阵的影响
LSCV 带宽矩阵 H L S C V = ( 0.014 0.111 0.111 11.922 ) H_{LSCV} = \begin{pmatrix} 0.014 & 0.111 \\ 0.111 & 11.922 \end{pmatrix} HLSCV=(0.0140.1110.11111.922) 提示了在喷发时间维度上使用了较小的带宽,使得喷发时间的变化更加精细地被捕捉。
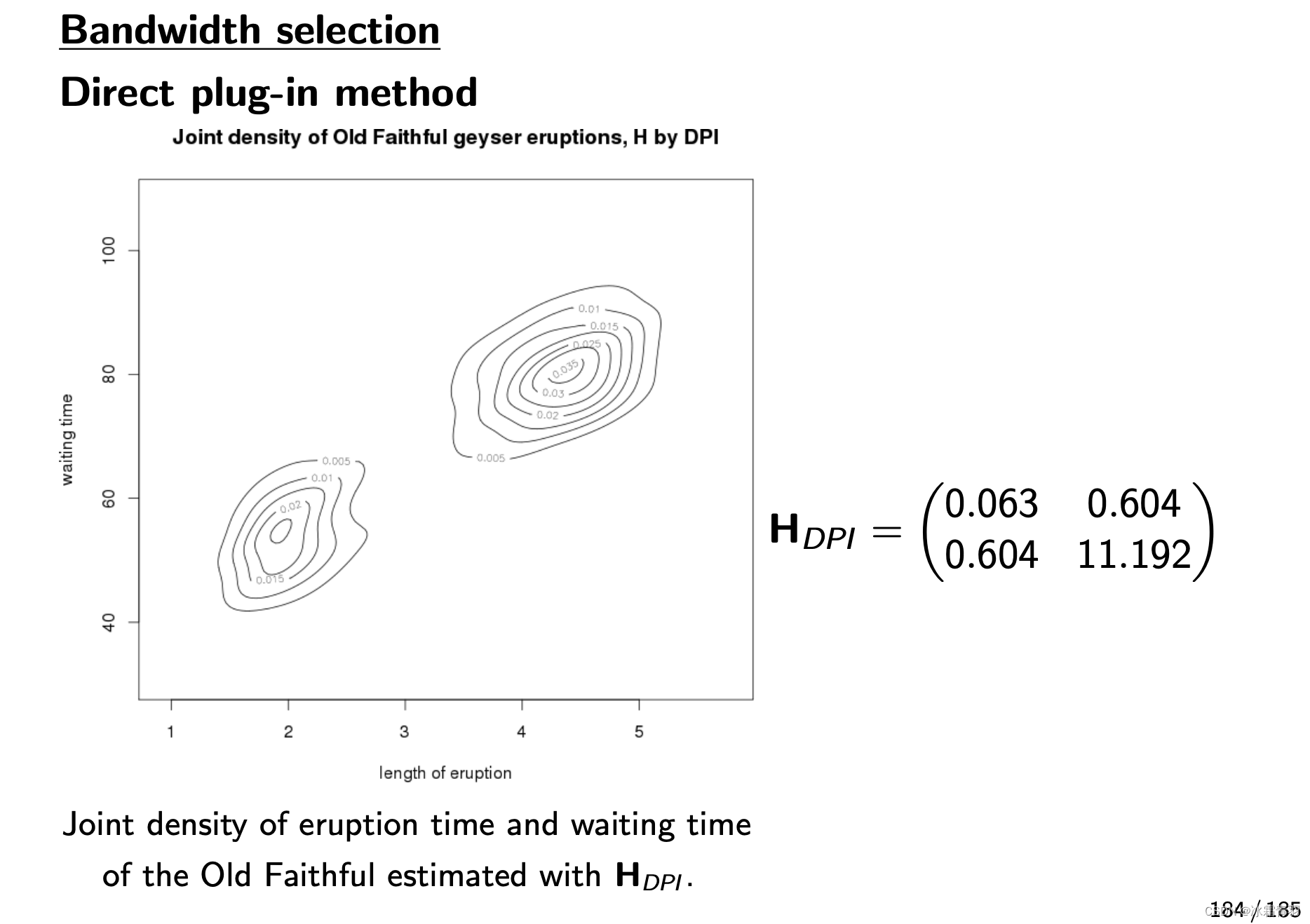
DPI 带宽矩阵 H D P I = ( 0.063 0.604 0.604 11.192 ) H_{DPI} = \begin{pmatrix} 0.063 & 0.604 \\ 0.604 & 11.192 \end{pmatrix} HDPI=(0.0630.6040.60411.192) 在两个维度上都使用了相对较大的带宽,特别是在喷发时间上,从而导致了更宽泛的密度估计。
结论
LSCV 方法 通过较小的带宽在喷发时间上提供了较高的灵敏度,适用于分析需要突出局部特征的场景。
DPI 方法 通过较大的带宽提供了一个平滑且广泛的视角,适合于观察整体趋势和较为广泛的数据分布。
总体来说,选择哪种方法取决于具体的分析需求和数据特性。如果需要详细捕捉局部变化,LSCV 方法可能更为适宜;如果关注于大规模的趋势和模式,DPI 方法可能提供更好的视图。在实际应用中,理解每种方法的特点和适用场景是选择合适带宽方法的关键。如果你需要进一步了解这些方法或有其他数据分析问题,欢迎继续咨询。
在选择带宽方法时,需要考虑数据分析的目标:
-
如果目的是详细分析数据的微观结构,如确定不同类型的喷发模式及其变异,LSCV 方法更为合适。
-
如果分析的重点是观察整体趋势和模式,或者数据在某些区域较为稀疏,DPI 方法提供了一种更加平滑的视图,有助于避免过拟合。















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









