







Pytorch学习
学习pytorch辅导书:Pytorch手册
常用函数查询:Pytorch文档
后续学习更新。
针对语音处理的pytorch常用函数
一般用到如下:
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader #训练数据组织
from hparams import hparams #预处理及网络需要的参数
import librosa #特征提取
import soundfile as sf #读音频
import random
语音增强–数据预处理
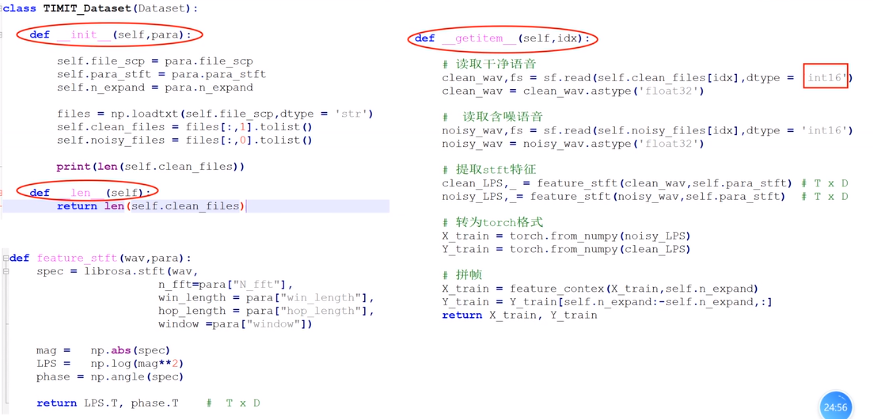
预处理得到(D维,T帧)数据,而网络输入需要(T,D)
其中每次输入网络的不是一帧,而是多帧,所以需要拼帧:

比如每5帧拼一起,作为一个整体,来预测中间一帧:
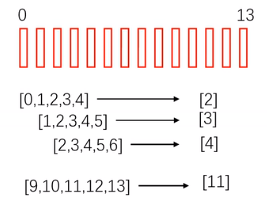
想象一下,每一帧数据D维,每5帧放一起,假设共13帧,即得到(9帧D维5)的数据。
根据这一部分,主要的pytorch的函数就是:
torch.from_numpy
用来将数组array转换为张量Tensor。
X_train = torch.from_numpy(noisy_LPS)
具体用法:
a=np.array([1,2,3,4])
print(a)
#[1 2 3 4]
print(torch.from_numpy(a))
#tensor([1, 2, 3, 4], dtype=torch.int32)
torch.unfold
torch.unfold(dimension,size,step)
按照指定维度dimension,以一定的间隔step将原始张量按size 大小进行分片,然后返回重整后的张量。
示例:
>>> a = torch.arange(16).view(4, 4)
>>> a
tensor([[ 0, 1, 2, 3],#[]里逗号隔开的就是列
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
>>> b = a.unfold(0, 3, 1) #0行1列
# 按照行,以每3个元素,跨步为1进行展开
>>> b
tensor([[[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]],
[[ 4, 8, 12],
[ 5, 9, 13],
[ 6, 10, 14],
[ 7, 11, 15]]])
>>> b.shape
torch.transpose
torch.transpose(tensor,dim_0,dim_1)
转置操作,交换两个维度。
示例:
a=torch.tensor([[[1,2,3],[4,5,6]],
[[7,8,9],[10,11,12]]])
b=torch.transpose(a,1,2) #置换1,2维,0维不变
#输出b:
#tensor([[[ 1, 4],
[ 2, 5],
[ 3, 6]],
[[ 7, 10],
[ 8, 11],
[ 9, 12]]])
#a的shape: torch.Size([2, 2, 3])
#b的shape: torch.Size([2, 3, 2])
torch.view
用于改变tensor的形状。
示例:
a = torch.tensor([1, 2, 3, 4, 5, 6])
b = a.view(2, 3)
#输出:
>>a : tensor([1, 2, 3, 4, 5, 6])
>>b : tensor([[1, 2, 3],
[4, 5, 6]])
-1表示一个不确定的数,就是如果你确定想要reshape成什么维度,把不确定,或懒得算的那个维度置为-1,其他的需要写上
示例:
c = a.view(-1,3)
#输出:
tensor([[1, 2, 3],
[4, 5, 6]])
c = a.view(3,-1)
#输出
tensor([[1, 2],
[3, 4],
[5, 6]])
深入学习:tensor.view()、tensor.reshape()、tensor.resize_() 三者的区别
torch.cat
outputs = torch.cat(inputs, dim)
把多个tensor进行拼接。
inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列
dim : 选择哪一维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。
示例:
# x1
x1 = torch.tensor([[11,21,31],[21,31,41]],dtype=torch.int)
x1.shape # torch.Size([2, 3])
# x2
x2 = torch.tensor([[12,22,32],[22,32,42]],dtype=torch.int)
x2.shape # torch.Size([2, 3])
'合并,得到inputs为2个形状为[2 , 3]的矩阵 '
inputs = [x1, x2]
print(inputs)
'打印查看'
[tensor([[11, 21, 31],
[21, 31, 41]], dtype=torch.int32),
tensor([[12, 22, 32],
[22, 32, 42]], dtype=torch.int32)]
torch.cat(inputs, dim=0).shape# 按第0维拼接
Out[1]: torch.Size([4, 3])
torch.cat(inputs, dim=1).shape# 按第一维拼接
Out[2]: torch.Size([2, 6])
torch.cat(inputs, dim=2).shape #报错
IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









