








如果index是时间序列就不用转datetime;但是如果时间序列是表中的某一列,可以把这一列设为index
例如:

代码:
DF=df2.set_index(df1['time_slot1'])
DF.index=pd.to_datetime(DF.index,unit='ns')
ticket=DF.ix[:,['all_time']]
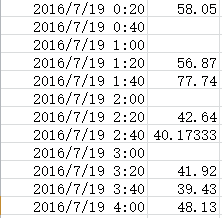
#以20分钟为一个时间间隔,求出所有间隔的平均时间
A_2analysisResult=ticket.all_time.resample('20min').mean()结果:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









