






第二章 多臂老虎机
- 两种反馈:纯估计性反馈(purely evaluative feedback)和纯指示性反馈(purely instructive feedback)
纯估计性反馈:估计某个动作好坏的程度,而不是该动作是否最好或者最坏。依赖于实际采取的动作。
纯指示性反馈:指示正确的动作,与实际采取的动作无关。这种反馈是监督学习的基础。 - 本章学习目标:研究这两种反馈的区别与联系。
2.1 k臂老虎机问题(k-armed Bandit Problem)
- 问题描述:在k个操作(options)或者动作(actions)中选择一个,并且重复选择。每一次选择之后将会收到一个数值的奖励,这个奖励采样于一个静概率分布,这个概率分布是基于所选择动作的。
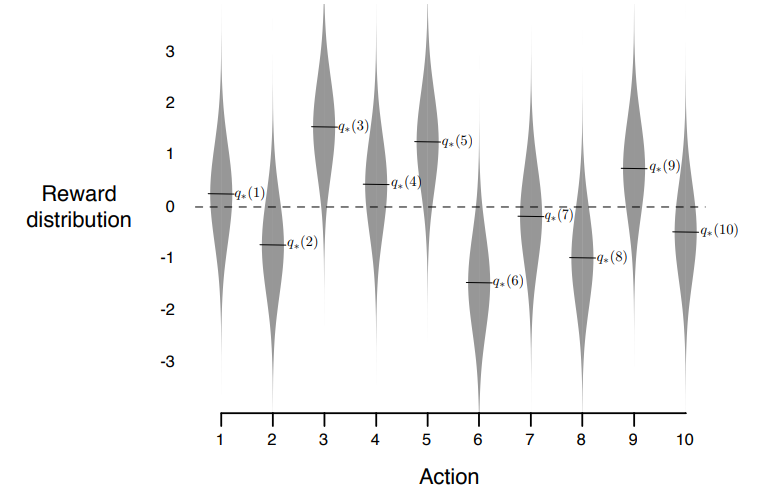
如下面图示,以高斯分布为例,二维情况下,a为动作a对应奖励的概率分布,*是我们的采样,是我们最后得到的实际奖励R。b、c是其他动作对应的奖励概率分布。类似的,我们可以在一维情况下采样。


- 目标:在一些时间步(time steps)后,比如1000步之后,最大化期望总奖励(expected total reward)。
- 在k臂老虎机问题中,每一次选择动作都有动作对应的期望(expected)或者平均(meaning)的奖励,称为动作值(the value of that action),时刻t选择的动作记为 A t A_{t} At,相关的奖励记为 R t R_{t} Rt。任给动作a,对应的期望奖励记为 q ∗ ( a ) q_{*}(a) q∗(a), q ∗ ( a ) ≐ E [ R t ∣ A t = a ] q_{*}(a) \doteq \mathbb{E}[R_{t}|A_{t}=a] q∗(a)≐E[Rt∣At=a]。若已知所有的动作值函数,k臂老虎机就很好解决了——我们只需要选择值最高的动作。但我们假设的情况是,动作值不可知,但可估计。称时刻t动作a对应的估计值为 Q t ( a ) Q_{t}(a) Qt(a),我们希望 Q t ( a ) Q_{t}(a) Qt(a)接近实际值 q ∗ ( a ) q_{*}(a) q∗(a)。
- 选择动作值 Q t ( a ) Q_{t}(a) Qt(a)最大的动作 a a a称为贪婪动作,当我们采取贪婪动作的时候,称我们在钻研/开发(exploiting) 动作值;当不采取贪婪动作时,称我们在调查/探索(exploring)。探索可以提升非贪婪动作的值。在单步中,开发可以最大化期望奖励;在多步中,探索有利于得到更高的总奖励。
- 在本章中,我们提出几个简单平衡探索-开发问题的方法,并且证明它们比纯开发的效果更好。
2.2 动作值方法
- 动作值方法:➀、估计动作值;➁、根据估计值选择动作。
- 抽样平均方法(sample-average) 用于估计动作值:
q ∗ ( a ) q_{*}(a) q∗(a)是我们的目标,即选择的动作的平均值。我们构造:
Q t ( a ) ≐ s u m o f r e w a r d s w h e n a t a k e n p r i o r t o t n u m b e r o f t i m e s a t a k e n p r i o r t o t = ∑ i = 1 t − 1 R i ⋅ 1 A i = a ∑ i = 1 t − 1 1 A i = a Q_{t}(a) \doteq \frac{sum\ of\ rewards\ when\ a\ taken\ prior\ to\ t}{number\ of\ times\ a\ taken\ prior\ to\ t}=\frac{\sum_{i=1}^{t-1}R_{i}\cdot \mathfrak{1}_{A_{i}=a}}{\sum_{i=1}^{t-1}\mathfrak{1}_{A_{i}=a}} Qt(a)≐number of times a taken prior to tsum of rewards when a taken prior to t=∑i=1t−11Ai=a∑i=1t−1Ri⋅1Ai=a
其中, 1 p r e d i c a t e \mathfrak{1}_{predicate} 1predicate是指示函数,若断言 p r e d i c a t e predicate predicate正确,值为1,否则为0。若分母为0,默认 Q t ( a ) = 0 Q_{t}(a)=0 Qt(a)=0。根据大数法则,当分母趋于无穷时,即无限多次选择之后, Q t ( a ) Q_{t}(a) Qt(a)将会收敛到 q ∗ ( a ) q_{*}(a) q∗(a)。当然,抽样平均方法并不是估计动作值最好的方法,但我们在这里不做展开。 - 纯贪心的动作选择方法(greedy action selection method)(根据估计值选择动作(一)):取估计值最大的动作,如下:
A t ≐ arg max a Q t ( a ) A_{t}\doteq\arg\max\limits_{a}Q_{t}(a) At≐argamaxQt(a),贪心动作选择方法只会钻研最好的动作值,使它们最大化,并不会调查那些看起来没那么好的动作值,但事实上,可能较次的实际拥有更高的动作值。 - ϵ \epsilon ϵ-贪心方法( ϵ \epsilon ϵ-greedy method)(根据估计值选择动作(二)):大多数时候遵照贪心法则,只有 ϵ \epsilon ϵ的概率会随机选择一个动作。好处是当步数增多时,每一个动作都将被采样无限多次,所以保证了所有的 Q t ( a ) Q_{t}(a) Qt(a)都收敛到 q ∗ ( a ) q_{*}(a) q∗(a)。
- 练习:在
ϵ
\epsilon
ϵ-贪心动作选择法中,假如有两个动作,以及
ϵ
=
0.5
\epsilon=0.5
ϵ=0.5,那么贪心动作被选择的概率是多少?
解:假设有动作a、b,且 Q ( a ) > Q ( b ) Q(a)>Q(b) Q(a)>Q(b),那么a是贪心动作。
P ( π = a ) = P ( π = a , π i s g r e e d y ) + P ( π = a , π i s n o t g r e e d y ) = 1 ∗ ( 1 − 0.5 ) + 1 2 ∗ 0.5 = 0.75 P(\pi=a)=P(\pi=a, \pi\ is\ greedy)+P(\pi=a, \pi\ is\ not\ greedy)\\=1*(1-0.5)+\frac{1}{2}*0.5\\=0.75 P(π=a)=P(π=a,π is greedy)+P(π=a,π is not greedy)=1∗(1−0.5)+21∗0.5=0.75
由公式可知,此时贪心动作被选择的概率是0.75。
2.3 10臂测试平台(10-armed testbed)
-
工作机制:每一次运行, 都依高斯分布(均值为0,方差为1的正态分布)随机选出10个值作为 q ∗ ( a ) q_{*}(a) q∗(a)(每个动作a对应的真实值)。在时间步t选择的动作 A t A_{t} At,对应的反馈是 R t R_{t} Rt,其中 R t R_{t} Rt采样于均值为 q ∗ ( a ) q_{*}(a) q∗(a),方差为1的正态分布。并且运行多次,例如2000次,注意每次都重新随机生成 q ∗ ( a ) q_{*}(a) q∗(a)。

-
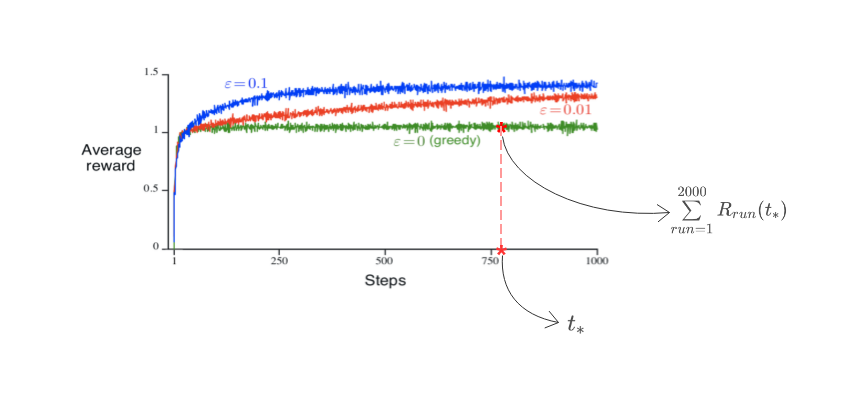
ϵ \epsilon ϵ-贪心算法与纯贪心算法的区别:下图是运行2000次得到的性状图,其中动作值估计和最有动作比都是使用了抽样平均方法。可以看出,纯贪心算法最初会提高很快,但逐渐收敛到较低的平均奖励上,约为1;而 ϵ \epsilon ϵ-贪心算法可收敛到1.55。所以,纯贪心算法在长时间运行的条件下相对劣势,经常收敛到局部最优动作上。


- ϵ \epsilon ϵ-贪心算法的优势取决于任务的设定,若方差高,则效果好;反之,则效果不佳。另外,如果我们弱化假设,那么 ϵ \epsilon ϵ-贪心算法将变得很重要。例如,我们假设k臂老虎机不稳定。不稳定性是强化学习最常见的问题。即使我们假设环境是稳定且确定的,我们的小实验中的 R t R_{t} Rt仍然每一次都不一样。因此探索/调查的模式必不可少。实际强化学习中我们需要平衡探索和开发。
- 练习:
2.2. 假设4-臂老虎机中,动作为1、2、3、4,使用 ϵ \epsilon ϵ-算法,和样本平均方法估计。初始值 Q 1 ( a ) = 0 , f o r a l l a Q_{1}(a)=0, for\ all\ a Q1(a)=0,for all a,初始动作及值分别是 A 1 = 1 , R 1 = − 1 , A 2 = 2 , R 2 = 1 , A 3 = 2 , R 3 = − 2 , A 4 = 2 , R 4 = 2 , A 5 = 3 , R 5 = 0 A_{1}=1, R_{1}=-1, A_{2}=2, R_{2}=1, A_{3}=2, R_{3}=-2, A_{4}=2, R_{4}=2, A_{5}=3, R_{5}=0 A1=1,R1=−1,A2=2,R2=1,A3=2,R3=−2,A4=2,R4=2,A5=3,R5=0。在其中一些步, ϵ \epsilon ϵ可能会发生,那么哪些步下,一定发生?哪些步下可能发生?
解:
| run \ action | 1 | 2 | 3 | 4 | (selected action) | (reward) | ϵ \epsilon ϵ |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 1 | -1 | possible |
| 2 | -1 | 0 | 0 | 0 | 2 | 1 | possible |
| 3 | -1 | 1 | 0 | 0 | 2 | -2 | definitely no(若默认 ϵ \epsilon ϵ不选择最优动作,否则设为possible ) |
| 4 | -1 | -0.5 | 0 | 0 | 2 | 2 | definitely yes |
| 5 | -1 | 0.33 | 0 | 0 | 3 | 0 | definitely yes |
| 6 | -1 | 0.33 | 0 | 0 |
根据上面的表表格可知,
ϵ
\epsilon
ϵ在第4、5步一定发生,在第1、2、3步可能发生。
2.3. 在上面的性状图中,就积累奖励与选择最佳动作比而言,哪一个方法在长期运行中性状更优?优多少?请有质量的作答。
解:就积累奖励而言,
ϵ
\epsilon
ϵ-方法更优。在长期运行之后,
ϵ
\epsilon
ϵ可以得到非
ϵ
\epsilon
ϵ的1.5倍的奖励。就选择最佳动作比而言,在长期运行之后,
ϵ
\epsilon
ϵ方法能够达到91%,而非
ϵ
\epsilon
ϵ只有不到40%,
ϵ
\epsilon
ϵ大约是非
ϵ
\epsilon
ϵ的2.3倍。
2.4 递增实现(incremental implementation)
- 上一节介绍了使用样本平均的方法估计奖励,这一节将介绍如何更有效率地估计奖励的平均值,该方法有固定的记忆空间和固定的每步计算量。首先给一些定义:
称 R i R_{i} Ri为执行第i个动作得到的奖励。
称 Q n Q_{n} Qn为该动作执行完n-1次后的平均值,即 Q n ≐ R 1 + ⋯ + R n − 1 n − 1 Q_{n}\doteq\frac{R_{1}+\cdots+R_{n-1}}{n-1} Qn≐n−1R1+⋯+Rn−1。
我们每次算样本平均时,总会执行以上操作,随着步数的增加,我们需要存储的 记忆空间 { R 1 , R 2 , . . . , R n − 1 } \{R_{1},R_{2},...,R_{n-1}\} {R1,R2,...,Rn−1}会随之变大,而且计算量也会随之增大。事实上,这不是必要的,我们可以做等价替换,使其表达为递增的形式,称为递增实现。 - 只需给出
Q
n
Q_{n}
Qn与
R
n
R_{n}
Rn,新的n个奖励的平均值可计算如下:
(1) Q n + 1 = 1 n ∑ i = 1 n R i = 1 n ( R n + ∑ i = 1 n − 1 R i ) = 1 n ( R n + ( n − 1 ) 1 n − 1 ∑ i = 1 n − 1 R i ) = 1 n ( R n + ( n − 1 ) Q n ) = 1 n ( R n + n Q n − Q n ) = Q n + 1 n [ R n − Q n ] \begin{aligned} Q_{n+1}&=\frac{1}{n}\sum\limits_{i=1}^{n}R_{i}\\ &=\frac{1}{n}\left(R_{n}+\sum\limits_{i=1}^{n-1}R_{i}\right)\\ &=\frac{1}{n}\left(R_{n}+(n-1)\frac{1}{n-1}\sum\limits_{i=1}^{n-1}R_{i}\right)\\ &=\frac{1}{n}\left(R_{n}+(n-1)Q_{n}\right)\\ &=\frac{1}{n}\left(R_{n}+nQ_{n}-Q_{n}\right)\\ &=Q_{n}+\frac{1}{n}\left[R_{n}-Q_{n}\right]\tag{1} \end{aligned} Qn+1=n1i=1∑nRi=n1(Rn+i=1∑n−1Ri)=n1(Rn+(n−1)n−11i=1∑n−1Ri)=n1(Rn+(n−1)Qn)=n1(Rn+nQn−Qn)=Qn+n1[Rn−Qn](1)
特别的,当 n = 1 n=1 n=1时,对于任意的 Q 1 Q_{1} Q1, Q 2 = R 1 Q_{2}=R_{1} Q2=R1。对于(1)式,我们需要的只是两个变量的储存空间,和每一步十分简单的计算量。
公式(1)将在书中频繁出现,一般形式为:
N e w E s t i m a t e ← O l d E s t i m a t e + S t e p S i z e [ T a r g e t − O l d E s t i m a t e ] NewEstimate\gets OldEstimate+StepSize[Target-OldEstimate] NewEstimate←OldEstimate+StepSize[Target−OldEstimate]
其中, [ T a r g e t − O l d E s t i m a t e ] [Target-OldEstimate] [Target−OldEstimate]称为估计的误差,其中 T a r g e t Target Target可以看作是理想方向,这里的 T a r g e t Target Target对应着第n个奖励。 S t e p S i z e StepSize StepSize称为步长因子,本书中我们常用 α \alpha α表示,或者 α t ( a ) \alpha_{t}(a) αt(a)。 - 伪代码:样本平均方法+
ϵ
\epsilon
ϵ-贪心算法

2.5 一个不稳定问题
- 由上一节可知,平均法适用于稳定性老虎机问题,即奖励的概率不随时间改变。但是现实中大多数强化学习具有强不稳定性。在这种情况下,我们的解决方案是权重上更偏向于最近的奖励,并且减少很早之前奖励的权重。
- 解决方案一:常数步长因子。
以公式(1)代表的递增实现为实例,即以 Q n Q_{n} Qn和 R n R_{n} Rn更新 Q n + 1 Q_{n+1} Qn+1。
下面的工作是:讨论在步长因子 α \alpha α为常数的情况下, Q n Q_{n} Qn与前n-1个奖励 { R i } i ∈ [ 1 , n − 1 ] ∩ Z \{R_{i}\}_{i\in [1,n-1]\cap\mathbb{Z}} {Ri}i∈[1,n−1]∩Z的关系。
Q n + 1 ≐ Q n + α [ R n − Q n ] Q_{n+1}\doteq Q_{n}+\alpha\left[R_{n}-Q_{n}\right] Qn+1≐Qn+α[Rn−Qn],其中 α ∈ ( 0 , 1 ] \alpha\in(0,1] α∈(0,1]是常数。可以一次推出, Q n Q_{n} Qn是前n-1个奖励和初始估计值 Q 1 Q_{1} Q1的加权平均:
(2)
Q
n
+
1
=
Q
n
+
α
[
R
n
−
Q
n
]
=
α
R
n
+
(
1
−
α
)
Q
n
=
α
R
n
+
(
1
−
α
)
[
α
R
n
−
1
+
(
1
−
α
)
Q
n
−
1
]
=
α
R
n
+
(
1
−
α
)
α
R
n
−
1
+
(
1
−
α
)
2
Q
n
−
1
=
α
R
n
+
(
1
−
α
)
α
R
n
−
1
+
(
1
−
α
)
2
α
R
n
−
2
+
⋯
+
(
1
−
α
)
n
−
1
α
R
1
+
(
1
−
α
)
n
Q
1
=
(
1
−
α
)
n
Q
1
+
∑
i
=
1
n
α
(
1
−
α
)
n
−
i
R
i
\begin{aligned} Q_{n+1} &= Q_{n}+\alpha\left[R_{n}-Q_{n}\right]\\ &=\alpha R_{n}+(1-\alpha)Q_{n}\\ &=\alpha R_{n}+(1-\alpha)\left[\alpha R_{n-1}+(1-\alpha)Q_{n-1}\right]\\ &=\alpha R_{n}+(1-\alpha)\alpha R_{n-1}+(1-\alpha)^{2}Q_{n-1}\\ &=\alpha R_{n}+(1-\alpha)\alpha R_{n-1}+(1-\alpha)^{2}\alpha R_{n-2}+\\&\cdots+(1-\alpha)^{n-1}\alpha R_{1}+(1-\alpha)^{n}Q_{1}\\ &=(1-\alpha)^{n}Q_{1}+\sum\limits_{i=1}^{n}\alpha(1-\alpha)^{n-i}R_{i}\tag{2} \end{aligned}
Qn+1=Qn+α[Rn−Qn]=αRn+(1−α)Qn=αRn+(1−α)[αRn−1+(1−α)Qn−1]=αRn+(1−α)αRn−1+(1−α)2Qn−1=αRn+(1−α)αRn−1+(1−α)2αRn−2+⋯+(1−α)n−1αR1+(1−α)nQ1=(1−α)nQ1+i=1∑nα(1−α)n−iRi(2)
我们称(2)式为加权平均,因为权重
(
1
−
α
)
n
+
∑
i
=
1
n
α
(
1
−
α
)
n
−
i
=
1
(1-\alpha)^{n}+\sum\limits_{i=1}^{n}\alpha(1-\alpha)^{n-i}=1
(1−α)n+i=1∑nα(1−α)n−i=1,其中权重
α
(
1
−
α
)
n
−
i
\alpha(1-\alpha)^{n-i}
α(1−α)n−i说明
R
i
R_{i}
Ri的权重取决于它已经过去了多少个,即n-i(how many rewards ago)。若
α
<
1
\alpha<1
α<1,那么当不断有新的
R
n
R_{n}
Rn进来时,
R
i
R_{i}
Ri的权重式不断减小的,具体来说,以
1
−
α
1-\alpha
1−α为基数呈指数级变化。如果
1
−
α
=
0
1-\alpha=0
1−α=0,那么所有权重都聚集到最新的奖励上,其他奖励的权重为0。因此,我们称(2)式代表的学习法则为指数型近期加权平均(exponential recency-weighted average)。
- 很多时候,步长因子 α n ( a ) \alpha_{n}(a) αn(a)会随着时间步变化。例如在样本平均方法中, α n ( a ) = 1 n \alpha_{n}(a)=\frac{1}{n} αn(a)=n1,并且根据大数法则,估计值会收敛到正确值。对于其他变化的 { α n ( a ) } \{\alpha_{n}(a)\} {αn(a)}收敛性并没有保证。因此我们引入随机逼近理论(stochastic approximation theory) 作为条件来保证估计值以概率 1 1 1收敛:
(3)
∑
n
−
1
∞
α
n
(
a
)
a
n
d
∑
n
=
1
∞
α
n
2
(
a
)
<
∞
\sum\limits_{n-1}^{\infty}\alpha_{n}(a)\ \ \ and\ \ \ \ \sum\limits_{n=1}^{\infty}\alpha_{n}^{2}(a)<\infty\tag{3}
n−1∑∞αn(a) and n=1∑∞αn2(a)<∞(3)
第一个条件保证了步长因子足够大,来克服初始值和震荡;第二个条件保证了步长因子足够小以至于收敛。例如,
α
n
(
a
)
=
1
n
\alpha_{n}(a)=\frac{1}{n}
αn(a)=n1是满足收敛条件的,但
α
n
(
a
)
=
α
\alpha_{n}(a)=\alpha
αn(a)=α不满足条件二,因此估计值会随着新得到的
R
n
R_{n}
Rn不断变化。实际操作中,满足公式(3)条件的步长因子往往使收敛变得缓慢,所以需要调整,因此,理论分析中,随机逼近理论使用很多,但实际操作中,却不怎么遵守。
- 练习:
Ex.2.4. 如果步长因子 α n \alpha_{n} αn不是常数,而是随时间步不断变化,那么估计值 Q n Q_{n} Qn是过去 { R i } \{R_{i}\} {Ri}集合的加权平均,它类似于公式(2),请推出用 { R i } \{R_{i}\} {Ri}表示估计值 Q n Q_{n} Qn的具体表达式。
解:
Q n + 1 = Q n + α n [ R n − Q n ] = α n R n + ( 1 − α n ) Q n = α n R n + ( 1 − α n ) [ α n − 1 R n − 1 + ( 1 − α n − 1 ) Q n − 1 ] = α n R n + ( 1 − α n ) α n − 1 R n − 1 + ( 1 − α n ) ( 1 − α n − 1 ) Q n − 1 = α n R n + ( 1 − α n ) α n − 1 R n − 1 + ( 1 − α n ) ( 1 − α n − 1 ) α n − 2 R n − 2 + ⋯ + ( 1 − α n ) ( 1 − α n − 1 ) ⋯ ( 1 − α 2 ) α 1 R 1 + ( 1 − α n ) ( 1 − α n − 1 ) ⋯ ( 1 − α 1 ) Q 1 = ∏ i = 1 n ( 1 − α i ) Q 1 + ∑ i = 1 n ( α i ∏ j = i + 1 n ( 1 − α j ) R i ) \begin{aligned} Q_{n+1} &= Q_{n}+\alpha_{n}\left[R_{n}-Q_{n}\right]\\ &=\alpha_{n} R_{n}+(1-\alpha_{n})Q_{n}\\ &=\alpha_{n} R_{n}+(1-\alpha_{n})\left[\alpha_{n-1} R_{n-1}+(1-\alpha_{n-1})Q_{n-1}\right]\\ &=\alpha_{n} R_{n}+(1-\alpha_{n})\alpha_{n-1} R_{n-1}+(1-\alpha_{n})(1-\alpha_{n-1})Q_{n-1}\\ &=\alpha_{n} R_{n}+(1-\alpha_{n})\alpha_{n-1} R_{n-1}+(1-\alpha_{n})(1-\alpha_{n-1})\alpha_{n-2} R_{n-2}+\\ &\cdots+(1-\alpha_{n})(1-\alpha_{n-1})\cdots(1-\alpha_{2})\alpha_{1}R_{1}\\ &+(1-\alpha_{n})(1-\alpha_{n-1})\cdots(1-\alpha_{1})Q_{1}\\ &=\prod_{i=1}^{n}(1-\alpha_{i})Q_{1}+\sum\limits_{i=1}^{n}\left(\alpha_{i}\prod_{j=i+1}^{n}(1-\alpha_{j})R_{i}\right) \end{aligned} Qn+1=Qn+αn[Rn−Qn]=αnRn+(1−αn)Qn=αnRn+(1−αn)[αn−1Rn−1+(1−αn−1)Qn−1]=αnRn+(1−αn)αn−1Rn−1+(1−αn)(1−αn−1)Qn−1=αnRn+(1−αn)αn−1Rn−1+(1−αn)(1−αn−1)αn−2Rn−2+⋯+(1−αn)(1−αn−1)⋯(1−α2)α1R1+(1−αn)(1−αn−1)⋯(1−α1)Q1=i=1∏n(1−αi)Q1+i=1∑n(αij=i+1∏n(1−αj)Ri)
Ex.2.5. 设计并执行一个实验来说明,样本平均方法对不稳定问题的劣势。其中不稳定问题改为增版10臂老虎机问题,即所有真实值 q ∗ ( a ) q_{*}(a) q∗(a)开始时一致,之后每一个 q ∗ ( a ) q_{*}(a) q∗(a)在每一步都进行独立地随机游走(每加一个正态增量,均值为0,标准差为0.01)。画出对应的动作值形状图,同时考虑另一个常步长因子的估计值方法,其中 α = 0.1 \alpha=0.1 α=0.1。使用 ϵ = 0.1 \epsilon=0.1 ϵ=0.1,步数为10000步。
解:这道题一共有两个要求:
一、要求设计一个实验,来表明不稳定性问题对样本平均方法的影响。
二、比较常步长因子(也叫recency-weighted average)和样本平均方法的性状。
要求一:
首先在原来的10-臂老虎机的机制中,已经包含了不稳定性的设计。其中,不稳定性的定义是在每一时间步,真实值
q
∗
(
t
)
q_{*}(t)
q∗(t)是随时间变化的。 如下图所示,问题中叙述的机制是,每次运行会确定
q
∗
′
q_{*'}
q∗′,这个值不随时间变化。每个时间步都加一个随机采样的值
x
x
x,
x
∼
N
(
0
,
0.0
1
2
)
x\sim N(0, 0.01^{2})
x∼N(0,0.012),得到
q
∗
(
t
)
q_{*}(t)
q∗(t)作为均值,当前步的奖励
R
(
t
)
R(t)
R(t)采样于
N
(
q
∗
(
t
)
,
1
)
N(q_{*}(t),1)
N(q∗(t),1)。不可否认这样做增加的不稳定性,但实际上改变的是
R
(
t
)
R(t)
R(t)对应概率分布的标准差,即散度。

下面,我们给一个证明,具体说明这一效果:
命题:上述不稳定机制本质上是加大R(t)分布的标准差,即散度。
证明:
假设
x
∼
N
(
0
,
c
2
)
x\sim N(0,c^{2})
x∼N(0,c2),则
p
(
x
)
=
N
(
0
,
c
2
)
=
1
2
π
c
e
x
p
(
−
1
2
c
2
x
2
)
d
x
p(x)=N(0,c^{2})=\frac{1}{\sqrt{2\pi}c}exp(-\frac{1}{ 2c^{2} }x^{2})\mathrm{d}x
p(x)=N(0,c2)=2πc1exp(−2c21x2)dx
同理,记
R
(
t
)
R(t)
R(t)为
r
r
r,则对于给定
x
x
x,
r
r
r采样于一个条件分布,其概率密度函数为
p
(
r
∣
x
)
=
N
(
x
,
1
2
)
=
1
2
π
e
x
p
(
−
1
2
x
2
)
d
x
p(r|x)=N(x,1^{2})=\frac{1}{\sqrt{2\pi}}exp(-\frac{1}{2}x^{2} )\mathrm{d}x
p(r∣x)=N(x,12)=2π1exp(−21x2)dx
我们希望求
r
r
r的概率分布,则
p
(
r
)
=
∫
p
(
r
∣
x
)
p
(
x
)
d
x
p(r)=\int p(r|x)p(x)\mathrm{d}x
p(r)=∫p(r∣x)p(x)dx为其分布的概率密度函数。
我们的目标是,得到
p
(
r
)
p(r)
p(r)与
x
x
x无关的精确表达式。
p
(
r
)
=
∫
p
(
r
∣
x
)
p
(
x
)
d
x
=
∫
1
2
π
c
e
x
p
(
−
1
2
c
2
(
r
−
x
)
2
)
1
2
π
e
x
p
(
−
1
2
x
2
)
d
x
=
1
2
π
c
∫
e
x
p
(
−
1
2
[
(
r
−
x
)
2
+
x
2
c
2
]
)
d
x
=
1
2
π
c
∫
e
x
p
(
−
1
2
c
2
+
1
c
2
(
x
2
−
2
r
c
2
c
2
+
1
x
)
−
r
2
2
)
d
x
=
1
2
π
c
e
x
p
(
−
r
2
2
)
∫
e
x
p
(
−
1
2
c
2
+
1
c
2
[
(
x
−
r
c
2
c
2
+
1
)
2
−
(
r
c
2
c
2
+
1
)
2
]
)
d
x
=
1
2
π
c
e
x
p
(
−
r
2
2
)
e
x
p
(
c
2
+
1
2
c
2
r
2
c
4
(
c
2
+
1
)
2
)
∫
e
x
p
(
−
c
2
+
1
2
c
2
(
x
−
r
c
2
c
2
+
1
)
2
)
d
x
=
1
2
π
c
e
x
p
(
−
r
2
2
(
c
2
+
1
)
)
∫
e
x
p
(
−
c
2
+
1
2
c
2
x
2
)
d
x
=
1
2
π
c
2
c
c
2
+
1
e
x
p
(
−
r
2
2
(
c
2
+
1
)
)
∫
e
x
p
(
−
y
2
)
d
y
=
1
2
π
c
2
c
c
2
+
1
π
e
x
p
(
−
r
2
2
(
c
2
+
1
)
)
=
1
2
π
c
2
+
1
e
x
p
(
−
r
2
2
(
c
2
+
1
)
)
=
N
(
0
,
(
c
2
+
1
)
2
)
\begin{aligned} p(r)&=\int p(r|x)p(x)\mathrm{d}x\\ &=\int\frac{1}{\sqrt{2\pi}c}exp\left(-\frac{1}{ 2c^{2} }(r-x)^{2}\right)\frac{1}{\sqrt{2\pi}}exp\left(-\frac{1}{2}x^{2} \right)\mathrm{d}x \\ &=\frac{1}{2\pi c}\int exp\left(-\frac{1}{ 2 }\left[(r-x)^{2}+\frac{x^{2}}{c^{2}} \right]\right)\mathrm{d}x\\ &=\frac{1}{2\pi c}\int exp\left(-\frac{1}{2} \frac{c^{2}+1}{c^{2}} \left(x^{2}-\frac{2rc^{2}}{c^{2}+1}x \right) -\frac{r^{2}}{2} \right)\mathrm{d}x\\ &= \frac{1}{2\pi c} exp \left(-\frac{r^{2}}{2} \right) \int exp\left(-\frac{1}{2} \frac{c^{2}+1}{c^{2}} \left[\left(x-\frac{rc^{2}}{c^{2}+1} \right)^{2}-\left(\frac{rc^{2}}{c^{2}+1} \right)^{2} \right] \right)\mathrm{d}x\\ &= \frac{1}{2\pi c} exp\left(-\frac{r^{2}}{2}\right) exp\left(\frac{c^{2}+1}{2c^{2}} \frac{r^{2}c^{4}}{(c^{2}+1)^{2}} \right)\int exp\left(-\frac{c^{2}+1}{2c^{2}}\left(x-\frac{rc^{2}}{c^{2}+1} \right)^{2} \right)\mathrm{d}x\\ &= \frac{1}{2\pi c} exp\left(-\frac{r^{2}}{2(c^{2}+1)}\right)\int exp\left(-\frac{c^{2}+1}{2c^{2}} x^{2}\right) \mathrm{d}x\\ &=\frac{1}{2\pi c} \frac{\sqrt{2}c}{\sqrt{c^{2}+1}} exp\left(-\frac{r^{2}}{2(c^{2}+1)}\right)\int exp\left( -y^{2} \right)\mathrm{d}y\\ &= \frac{1}{2\pi c} \frac{\sqrt{2}c}{\sqrt{c^{2}+1}} \sqrt{\pi}\ exp\left(-\frac{r^{2}}{2(c^{2}+1)}\right)\\ &= \frac{1}{\sqrt{2\pi}\sqrt{c^{2}+1}}exp\left(-\frac{r^{2}}{2(c^{2}+1)}\right)\\ &=N(0,(\sqrt{c^{2}+1})^{2}) \end{aligned}
p(r)=∫p(r∣x)p(x)dx=∫2πc1exp(−2c21(r−x)2)2π1exp(−21x2)dx=2πc1∫exp(−21[(r−x)2+c2x2])dx=2πc1∫exp(−21c2c2+1(x2−c2+12rc2x)−2r2)dx=2πc1exp(−2r2)∫exp(−21c2c2+1[(x−c2+1rc2)2−(c2+1rc2)2])dx=2πc1exp(−2r2)exp(2c2c2+1(c2+1)2r2c4)∫exp(−2c2c2+1(x−c2+1rc2)2)dx=2πc1exp(−2(c2+1)r2)∫exp(−2c2c2+1x2)dx=2πc1c2+12cexp(−2(c2+1)r2)∫exp(−y2)dy=2πc1c2+12cπ exp(−2(c2+1)r2)=2πc2+11exp(−2(c2+1)r2)=N(0,(c2+1)2)
其中
∫
e
x
p
(
−
y
2
)
d
y
=
π
\boxed{\int exp\left(-y^{2} \right)\mathrm{d}y=\sqrt{\pi} }
∫exp(−y2)dy=π
∫
e
x
p
(
−
a
y
2
)
d
y
=
1
a
∫
e
x
p
(
−
y
2
)
d
y
∵
l
e
t
t
≐
a
y
\boxed{\int exp\left( -ay^{2} \right)\mathrm{d}y=\frac{1}{\sqrt{a}} \int exp\left(-y^{2} \right)\mathrm{d}y\ \ \ \because let\ t\doteq \sqrt{a}y}
∫exp(−ay2)dy=a1∫exp(−y2)dy ∵let t≐ay
由上可知,对于要求一,原来10-臂老虎机R(t)的标准差为1,已经是不稳定情况了。所以我们的设计应该变化不稳定的剧烈程度,使R(t)的标准差从0,逐步增加到1.5,即[0, 0.5,1,1.5],观察它对性状图的影响即可。
另外,我们可以从不那么严谨的角去理解:
∵
x
∼
N
(
0
,
c
2
)
∵
y
∼
N
(
0
,
1
2
)
∴
r
∼
N
(
x
,
1
2
)
=
x
+
N
(
0
,
1
)
∼
N
(
0
,
c
2
)
+
N
(
0
,
1
)
=
N
(
0
,
c
2
+
1
)
\because x\sim N(0,c^{2})\\ \because y\sim N(0,1^{2})\\ \therefore r\sim N(x,1^{2})=x+N(0,1)\\ \sim N(0,c^{2})+N(0,1)=N(0,c^{2}+1)
∵x∼N(0,c2)∵y∼N(0,12)∴r∼N(x,12)=x+N(0,1)∼N(0,c2)+N(0,1)=N(0,c2+1)
值得注意,虽然r与x不独立,但正态分布对均值有可加性,可将x分离开,使得到的y与x独立,因此最后的等号成立。
明白机制的本质之后,我们不妨考虑R(t)分布的总标准差 σ = c 2 + 1 \sigma=\sqrt{c^{2}+1} σ=c2+1。记为不稳定因子(nonstationary)。下图是样本平均方法的性状图:


可以看出,面对越不稳定的环境,样本平均方法对于平均值估计的震荡越大;而且找到最佳动作的百分比越低。
要求二、可以看出,对于高度不稳定的10-臂老虎机而言,样本平均的方法比常步长因子的方法效果更好。

 具体的代码见我的github博客
具体的代码见我的github博客
疑问: 教材里说,对于不稳定问题,样本平均方法比不上常步长因子方法?为什么我的实验结果不是这样呢?
原因: 因为我的代码里,设的是
ϵ
=
0.1
\epsilon=0.1
ϵ=0.1,它影响了最终的结果。下面放上
ϵ
=
0
\epsilon=0
ϵ=0的效果图:


这样看来,确实教材中的话是正确的。















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









