









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种解决小样本语义分割问题的方法。整个网络分成两个分支:条件分支(Conditioning Branch)和分割分支(Segmentation Branch),网络的结构如下图所示。

条件分支对应的是支持集图像,该图像包含一张目标物体的二元掩码图(一个通道)和一张原图(RGB三个通道),首先经过掩码操作,将原图中目标物体所在区域提取出来。然后经过VGG网络进行特征提取,再利用全连接层将其转化为长度为1000的特征向量。最后经过一个“权重哈希(Wight Hashing)”操作将其转化为长度是4097的一维向量(图中画了4个长条我并不太理解是什么含义)。所谓的权重哈希操作是利用一个固定权重的全连接层来实现的,权重计算方法如下式
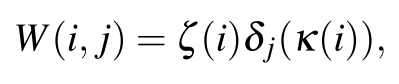
式中
ζ
(
i
)
→
{
−
1
,
+
1
}
\zeta(i)\rightarrow \left \{-1,+1\right \}
ζ(i)→{−1,+1}和
κ
(
i
)
→
{
1
,
.
.
.
,
m
}
\kappa(i)\rightarrow \left \{1,...,m\right \}
κ(i)→{1,...,m}是随机选择的,
m
m
m是输入向量的维度,本文取
m
=
1000
m=1000
m=1000,
δ
j
\delta_j
δj表示离散狄拉克函数。该权重不随着训练过程更新。
分割分支对应查询集图片,首先经过一个FCN-32s网络进行特征提取得到通道数为4096的特征图
F
q
m
n
F^{mn}_q
Fqmn,表示在坐标
(
m
,
n
)
(m,n)
(m,n)处的特征向量(长度为4096),然后利用条件分支得到的一维向量作为权重和偏置来对
F
q
m
n
F^{mn}_q
Fqmn做逻辑回归操作,公式如下

式中
w
w
w(长度为4096)和
b
b
b(长度为1)均来自条件分支输出的一维向量,
σ
\sigma
σ表示Sigmoid函数,
M
^
q
m
n
\hat{M}^{mn}_q
M^qmn表示在坐标
(
m
,
n
)
(m,n)
(m,n)处的预测掩码值。最后将预测掩码图
M
^
\hat{M}
M^通过双边线性插值的方式进行上采样,恢复到原图尺寸,然后以0.5为阈值对查询图片进行掩码操作得到分割图像。
对于支持集中一个类别包含多个图像的情况(few-shot),分别利用多张图片计算对应的分割图像,然后对多个分割结果采用“逻辑或”操作来解决预测准确率高但召回率低的问题,并得到最终的预测结果。
实现过程
网络结构
条件分支采用VGG,分割分支采用FCN-32s网络。
损失函数
本文的目标函数是最大化预测的对数似然
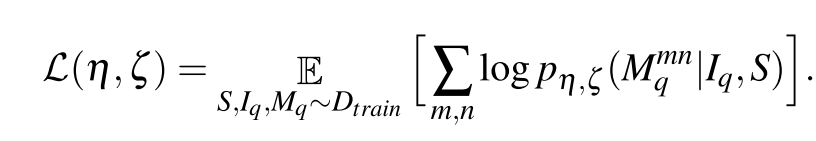
式中
η
,
ζ
\eta,\zeta
η,ζ分别表示分割分支和条件分支网络的参数。
训练策略
首先从训练集中采样得到查询集图像 I q I_q Iq和对应的语义分割图 Y q Y_q Yq,从中选择需要分割的目标类别 l l l,并得到对应的二元掩码图 M q = Y q ( l ) M_q=Y_q(l) Mq=Yq(l), Y q Y_q Yq中包含图中所有物体的分割结果(如汽车,公路,建筑等),但 M q M_q Mq中只包含目标类别的分割结果(如汽车)对应位置的像素点值为1,其他位置均为0。然后从训练集中包含目标类别 l l l的图片中,除去 I q I_q Iq剩下的部分里,采样得到支持集 S S S。
创新点
- 设计了一种双分支结构,实现了小样本语义分割任务
- 采用了权重哈希操作实现特征向量维度变换,并采用逻辑或操作解决预测结果召回率低的问题
算法评价
本文是较早地研究小样本语义分割任务的文章,采用的方式看起来也比较粗糙,每次只能分割一类物体(类似于显著性检测),只能得到二元的预测结果(是或不是),而且在预测时必须提供包含同类物体的支持集图像,以及对应的二元掩码图,这样就限制了实际应用效果。但作为一个早期的探索,本文还是向小样本语义分割任务这一难题迈出了坚实的一步,打下了一个良好的研究基础。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











