









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种通过优化基础类别选择的方式改善小样本学习的算法。许多小样本分类算法都是基于迁移学习的方式,首先在基础数据集上进行预训练,然后在新的小样本数据集上做微调训练。本文并没有研究如何改善特征提取网络或分类器的结构,而是另辟蹊径的考虑如何选择最佳的基础数据集,更具体地说就是选择哪些类别的基础数据集用于预训练。解决这一问题存在两大困难:1.如果对基础数据集中的所有类别组合都进行尝试,那么时间复杂度将相当高;2.没有一种可以直接描述基础数据集的类别选择和在新数据集上分类效果之间关系的方法。为了解决上述困难,作者首先提出了相似比(Similarity Ratio,SR)的概念,并且证明了SR与小样本分类性能之间的联系;然后将基础类别选择的问题归结为一个次模优化问题(submodular optimization);最后通过贪婪算法在有限时间复杂度条件下寻找到该问题的次优解。
首先作者定义了什么是相似比SR,如下所示

式中,分子表示新类别中与基础类别最相似的K个类别的平均相似程度,分母表示新类别与所有基础类别的平均相似程度,相似程度可用余弦距离表示。如果想提高SR的值,那么一方面要保证基础类别中有一些类别与新类别是高度相关的,非常接近的,以提高分子的值;另一方面要保证基础类别具备一定的多样性,也就是说其他无关的类别与新类别之间的差异很大,以降低分母的值。这一要求与小样本学习对于基础类别的要求不谋而合,因此SR可以用于表示小样本分类的性能(SR越大,则小样本分类效果越好),作者还通过一系列实验证明这一关系,此处不再详述,只介绍其中最为重要的一个结论。作者将与新类别的最高相似性表示如下
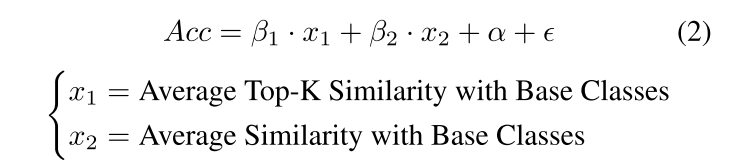
x
1
x_1
x1和
x
2
x_2
x2分别表示SR的分子和分母,
β
1
\beta_1
β1和
β
2
\beta_2
β2分别表示对应的权重,
α
\alpha
α表示残差项,
ε
\varepsilon
ε表示噪声项,随着基础类别数目
K
K
K的增长,
β
1
\beta_1
β1和
β
2
\beta_2
β2平均值的比率
β
ˉ
2
/
β
ˉ
1
\bar{\beta}_2/\bar{\beta}_1
βˉ2/βˉ1变化如下图所示

由图可知,当基础类别数目比较少
K
<
5
K<5
K<5时,
β
ˉ
2
/
β
ˉ
1
>
0
\bar{\beta}_2/\bar{\beta}_1>0
βˉ2/βˉ1>0,也就是说此时
x
1
x_1
x1和
x
2
x_2
x2都是越大越好,因为类别太少,需要尽可能多的相似的类别。而当基础类别数目逐渐增长
K
>
5
K>5
K>5时,
β
ˉ
2
/
β
ˉ
1
<
0
\bar{\beta}_2/\bar{\beta}_1<0
βˉ2/βˉ1<0,也就是说
β
2
<
0
\beta_2<0
β2<0,此时我们希望
x
2
x_2
x2越小越好,因为有5个与新类别非常相似的类别就足够了,其他的类别应该尽量增加多样性,而不是一味的追求与新类别相似。这再一次印证了作者的观点:提高SR的值等价于提高小样本分类的效果,下面的工作就是如何选择合适的基础类别来提高SR的值了,作者认为该问题可以归结为一个次模优化问题,并可以利用贪婪算法求解,下面简单介绍一下什么是次模函数。

上图是从其他人的博客里找到的,他描述了一个利用贪婪算法解决雷达覆盖范围的问题。该问题满足两个性质:单调性(Monotone)和次模性(Submodularity)。单调性是指如果我在
S
1
S_1
S1和
S
2
S_2
S2覆盖范围的基础上,增加一个新的
S
′
S'
S′则总的覆盖范围的变化肯定是非负的(可能增长,也可能不变,但至少不会变小)。次模性是指相对于在
S
1
S_1
S1和
S
2
S_2
S2覆盖范围的基础上,增加一个新的
S
′
S'
S′(图a所示),在
S
1
.
.
.
S
4
S_1...S_4
S1...S4的基础上增加一个新的
S
′
S'
S′(图b所示),带来的覆盖范围增益更小。具体的介绍和证明过程可以参看这篇博客https://blog.csdn.net/a358463121/article/details/85037552。
作者将SR的优化问题归结为

式中
B
u
B_u
Bu表示未被选中的基础类别,
B
s
B_s
Bs表示被选中的基础类别,
N
N
N表示新类别;
c
A
c_A
cA表示类别集合
A
A
A中各个类别的质心(特征值的平均值);
λ
\lambda
λ是一个超参数,等价于上文提到的
−
β
ˉ
2
/
β
ˉ
1
-\bar{\beta}_2/\bar{\beta}_1
−βˉ2/βˉ1,为了简化问题,本文假设
λ
≥
0
\lambda\geq 0
λ≥0;
K
K
K也是一个超参数,表示基础类别的数目;
f
f
f表示相似性度量函数(如余弦距离);
M
K
(
)
M^K()
MK()表示最相似的
K
K
K个值之和,计算过程如下
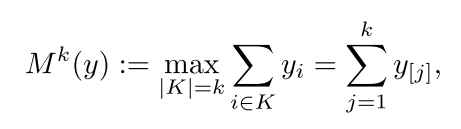
y
[
j
]
y_{[j]}
y[j]表示将
y
y
y的值按照由大到下排列。
当
λ
=
0
\lambda=0
λ=0时上述优化问题就可以看作一个标准的单调非减次模优化问题,因此可以直接使用贪心算法求解,过程如下

其中
h
(
)
h()
h()表示上述的优化目标函数。
当
λ
>
0
\lambda>0
λ>0时,上述优化问题可以看作一个非单调的次模优化问题,本文结合随机贪婪算法(Random Greedy Algorithm)和连续双贪婪算法(Continuous Double Greedy Algorithm)进行求解,过程如下


具体的求解过程建议参看原文,此处不再详述。
创新点
- 从基础类别选择的角度出发,通过改善基础训练集来提高小样本分类的效果
- 引入SR的概念,并证明其与小样本分类效果之间的关系
- 利用贪婪算法求解了最大化SR的优化目标函数
算法评价
尽管已经阅读了数十篇小样本学习的文章,这篇文章的思路还是让我觉得眼前一亮。通过优化基础类别的选择,来提高基于迁移学习的小样本分类算法的效果,这一想法算得上独树一帜了,虽然在我看来基于迁移学习的小样本学习算法并不能算是该领域的主流方向。整篇文章的数学性很强,阅读起来有一定的障碍,如果需要完全理解并推导整个过程,还是要求有很好的数学基础的。本文的解读也只是围绕着作者核心思想来展开,对于证明和推导的细节并没有介绍,感兴趣的读者可以去阅读原文。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 2764
2764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











