









 本文综述了几篇关于深度学习在立体匹配和语义分割领域的重要论文,包括GC-Net、PSMNet、SENet、BiSeNet、PSPNet等。这些工作展示了如何利用深度学习提升立体图像的视差图生成,以及如何实现实时的语义分割任务。创新点包括端到端学习、特征提取优化、注意力机制和双线网络结构。
本文综述了几篇关于深度学习在立体匹配和语义分割领域的重要论文,包括GC-Net、PSMNet、SENet、BiSeNet、PSPNet等。这些工作展示了如何利用深度学习提升立体图像的视差图生成,以及如何实现实时的语义分割任务。创新点包括端到端学习、特征提取优化、注意力机制和双线网络结构。
1.《End-to-End Learning of Geometry and Context for Deep Stereo Regression》
详细内容
发表时间:2017年3月13日
网络名称:GC-Net
主体思想
作者构建了一个全新的端到端的网络用于生成立体图像的视差图,首先利用二维的卷积神经网络提取出原始图像的特征图,将每个视差下的特征图组合起来,得到一个四维的匹配代价卷。然后利用3D卷积方法来提取特征,为了减少运算量,作者采用了编码解码的方式,先以2为步长对匹配代价卷进行下采样,降低维度,再用反卷积方法进行上采样,恢复维度。最后作者利用柔性argmin机制来回归视差,先对3D卷积得到的匹配代价值取负数,再用softmax将其正则化,得到视差可能性卷,然后将每个视差值和视差的可能性相乘求和,得到了每个像素点上的视差值。
创新点
- 利用卷积神经网络提取特征来构架匹配代价卷,而不是传统方法通过距离度量函数来计算匹配代价。作者认为这种特征提取方式可以提取的图像的绝对特征,在光照条件复杂的区域更具有鲁棒性并且能够结合上下文信息
- 在进行3D卷积时采用了编码解码结构,有效的减少了运算成本,并保留了空间精确性和细节信息
- 采用柔性argmin方式来回归视差,这一操作是完全可微的,因此可以得到亚像素精度的视差值
结论
该论文提出几个重要的概念:端到端网络,直接由立体匹配图像,生成视差图,并以预测视差与真实视差的绝对值差的平均值来训练网络,不再像之前的网络通过给图像贴上正确匹配和错误匹配的标签来训练网络;3D卷积中的编码解码结构,能够有效降低运算成本,同时保留高分辨率的细节信息;柔性argmin操作,通过回归的方式获得视差图,而不是采用分类的方式,这个操作是完全可微的,因此可以得到亚像素级别的视差图。
2.《Pyramid Stereo Matching Network》
详细内容
发表时间:2018年3月23日
网络名称:PSMNet
主体思想
作者搭建了一个端到端的网络,在特征提取的阶段,采用空洞卷积(dilated convolution)来扩大感受野,再利用SPP空间金字塔池化获取不同尺度感受野下的特征信息,将全局信息和局部信息结合起来构成匹配代价卷。然后采用了堆叠沙漏型的3D卷积操作,所谓沙漏型,就是先编码(卷积)下采样(特征图尺寸变小),再解码(反卷积)上采样(特征图尺寸变大),同时在反卷积的过程中还要加上未进行卷积操作的原始特征图,以期获得高分辨率的特征,完成一个由精到粗再由粗到精的变化过程,整个流程中特征图中间小两端大形似沙漏;所谓堆叠就是三个这样的结构串联起来。最后作者同样利用回归的方式来预测视差值,损失函数采用的是平滑的L1损失函数,相比于L2损失函数更具鲁棒性。
创新点
- 特征提取阶段先使用三层3 * 3的卷积层来代替7*7的卷积层,然后采用残差块的结构来避免梯度爆炸,最后采用了空洞卷积的方式,扩大感受野,且不会增加运算量
- 增加了空间金字塔池化结构,分别用64 * 64,32 * 32,16 * 16,8 * 8四个尺度的窗口进行平均池化,并紧跟一个1 * 1的卷积层来减少特征维度,在通过双线性插值的方式进行上采样以恢复到原始尺寸
- 将三个沙漏型3D卷积结构堆叠起来,每个沙漏结构都会产生一个视差图和一个损失值,训练时将三个损失值进行加权求和得到最终的损失值(权重是通过实验选择的最优方案)
结论
该论文引入了空洞卷积结构和空间金字塔池化结构这在一定程度上扩大了感受野,如作者所说,能够学习到物体(汽车)与次级区域(车窗,轮胎)之间的关系,以获得更多的环境信息,对于不适定区域有更强的鲁棒性;3D卷积过程中将三个沙漏型结构堆叠起来,以期获得更好的特征提取效果,根据作者实验结果,该结构生成的视差图是比单一的沙漏型结构的结果更加精确;损失函数采用来平滑的L1损失函数,在计算预测视差和真实视差的差值时,增加了平滑操作。
3.《Squeeze-and-Excitation Network》
详细内容
发表时间:2018年4月5日
网络名称:SENet
主体思想
该网络原本是用来解决图像分类问题的。它的核心在于为卷积得到的特征图赋予了权重,每个特征图之间不再是平等的关系,而是根据环境信息分配了不同的权重。这一过程分为两个步骤:压缩和激发。压缩,是将上一个卷积层输出的特征图进行全局平均池化,每个特征图的特征都压缩为一个数值。激发,利用压缩得到的聚合信息,获得通道维度上的依赖性,即各特征图上的权重。SEBlock结构可以总结为:全局平均池化层+1 * 1 * C/r的全链接层+ReLU激活层+1 * 1 * C的全链接层+Sigmoid激活层。输入维度是H * W * C,输出维度也是H * W * C,因此可以加到任何的卷积层之间,在残差网络中,可用于代替非恒等分支。
创新点
- 引入压缩和激发结构,激发函数要足够灵活,能够学习到多通道间的非线性相互作用,在较低层次中,可以学习直接的信息特征,提高可共享的低层级的表征能力;在较高的层次中,SE块变得更加专门化,并以较高具体化的方式响应输入
- 在SEBlock中引入了瓶颈结构,先用一个全链接层降低维度,再用一个全链接层上升维度,这一方面降低了模型复杂度,另一方面可以帮助模型泛化。
结论
该论文将SEBlock与ResNet网络结合起来取得了很好的训练效果,同时参数数量增长了10%,但根据实验参数主要来自于网络的最后一个阶段,去掉最后一个阶段,错误率只有轻微的上升,但参数数量下降了4%。
4.《Cascade Residual Learning A Two-stage Convolutional Neural Network for Stereo Matching》
详细内容
发表时间:2017年8月30日
网络名称:CRL
主体思想
该网络提出一个双级结构,第一级是沙漏型的残差结构,输入一对立体图像,输出的是全像素的初始视差图。第二级也是沙漏型的残差结构,分别对初始视差图进行1/16,1/8,1/4,1/2尺度的下采样,从不同尺度下学习残差信号,将左右图,从右图根据视差计算出的左图,视差图和预测视差与真实视差之间的误差图连接起来,输入第二级网络,网络只学习残差值,将第二级学习到的残差值加上第一级的初始化视差值得到最终的视差输出。同样采用的是端到端的训练,损失函数采用了 l 1 l_1 l1函数。
创新点
- 第一级网络在DispNetC上增加了上卷积层,原网络输出的是半分辨率的视差图,经过上卷积之后得到全分辨率的视差图,为第二级网络提供一个很好的初始视差图
- 第二级网络从不同的尺度下学习残差信号,而不是直接学习视差信号,将残差信号与第一级输出的初始视差相加得到最终的优化视差结果
结论
两级网络结构,第一级学习视差,第二级在此基础上学习残差,这一思想很新奇,根据实验结果来看,也有一定的效果。先下采样缩小尺寸,再上卷积恢复尺寸的处理方式也有一定的参考价值。
5.《Learning for Disparity Estimation through Feature Constancy》
详细内容
发表时间:2018年3月28日
网络名称:iResNet
主体思想
该网络将立体匹配的四个步骤整合到一个网络中,整个网络分为三个部分:提取多尺度的特征信息;第二部分利用特征来得到初始视差图;第三部分利用特征连续性对初始视差图进行优化,得到最终视差图。所谓特征连续性包含两个方面:一是特征相关性,是对左右提取得到的特征图做有平移的相关运算(correlation)(还没有完全弄明白计算方法,感觉是计算不同视差下的左右图之间的一致性);二是重构误差,根据初始视差图将右图提取出的特征图进行wrap操作,得到重构的特征图,再将重构的特征图与左图提取出的特征图做差,就得到了重构误差图(与CRL的wrap操作区分,CRL是根据视差对右图原图直接进行wrap,即所谓的颜色连续性,而该方法是对提取得到的特征图进行wrap,作者在实验中做了对比,证明特征连续性要比颜色连续性更具鲁棒性)。作者对优化视差步骤进行了迭代,即将优化得到视差图作为初始视差图,重新计算特征连续性,再次进行优化。
创新点
- 将立体匹配的全过程整合为一个网络,提高了准确率和效率
- 引入特征连续性的概念,利用特征连续性对初始视差图进行优化
- 对优化过程进行迭代,但随着迭代次数增加,增益效果迅速下降
结论
整体网络结构,利用特征连续性对视差进行优化的操作要优于利用颜色连续性的优化,优化迭代的策略可以加以利用,但需要注意计算成本的增加,特征连续性中特征相关性的计算方式尚不明确,仍需进一步研究。
6.《Left-Right Comparative Recurrent Model for Stereo Matching》
详细内容
发表时间:2018年4月3日
网络名称:LRCR
主体思想
该网络将左右一致性检测与视差值计算结合起来,首先利用一个高速网络生成匹配代价卷(此处仍使用传统的带有标签的图块比对方法),将得到的左右图的匹配代价卷分别输入到两个平行的堆叠四层ConvLSTM网络中,从中得到预测的视差图,将左右视差图进行坐标变换(把左视差图变换到右图坐标系下),将左视差图和由右图变换而来的视差图输入到一个简单的卷积神经网络中,输出误差图(右视差图也做相同处理)。再将误差图作为一种柔性的注意力引导图和匹配代价卷一起输入到下一级的ConvLSTM网络中,如此反复重复五次,最终输出视差结果,并做中值滤波和双边滤波处理。
创新点
- 将左右一致性检测和视差计算结合在一起,左右对比网络为视差计算提供了一种柔性的注意力引导图,使得网络更多的关注左右误匹配区域,提高了病态区域的匹配效果
- 引入了ConvLSTM网络,利用了网络的记忆效应,通过回归的方式计算视差图
- 基于RNN重复神经网络的结构搭建,重复结构有助于逐步改善视差预测结果
结论
该网络的结果并不是最优的,并且根据实验结果来看,处理速度特别慢,这主要是由于生成匹配代价卷的方式过于落后,但其引入的重复结构,堆叠的ConvLSTM结构和左右对比分支网络思想都是很新颖的,值得深入学习。同时对于LSTM(长短期记忆网络)和它对于视差图坐标转换的方法还要进一步学习。
7.《EdgeStereo:A Context Integrated Residual Pyramid Network for Stereo Matching》
详细内容
发表时间:2018年3月14日
网络名称:EdgeStereo
主体思想
作者搭建了一个单级的多任务网络,在特征提取阶段采用了VGG-16网络的主体部分,对于左右图中得到的特征图,进行Correlation操作,得到一个匹配代价卷。然后对特征提取过程中的特征图,进行一个1 * 1的卷积操作,得到更为精细化的一元特征图,将其与先前得到的匹配代价卷级联起来得到局部立体卷。构建多尺度的环境金字塔,思路也是从不同尺度下分别获取信息,最后再级联起来得到初始的立体信息。最后利用一个残差网络得到视差图,先将上述得到的立体信息进行下采样,最后得到尺寸为原图的1/64的Disp6,在此基础上学习视差图,然后再将其上采样,结合左图,右图,经Wrap操作的左图和误差图,来学习残差图,重复这样的操作,最终恢复到原始分辨率,整个过程中只有最小尺度下是学习视差图,其他尺度都只学习残差图。本文还结合了一个边缘检测网络,在特征提取过程中就同步进行边缘特征的提取,输出边缘概率图,将所有的边缘概率图利用1 * 1的卷积融合起来得到边缘图(Edge)。不仅如此,作者还将提取到的所有边缘特征图级联起来,再用1 * 1的卷积得到聚合边缘通道特征(aec),再与之前的局部立体卷结合起来,就得到了带有边缘特征的局部立体卷。在学习视差图和残差图的残差金字塔网络中,作者同样将聚合边缘通道特征(aec)和边缘图(Edge)进行下采样,将其与对应尺度下的立体信息(Disp)组成聚合图( A k A_k Ak),用聚合图代替之前单独的立体信息,逐层学习,最终得到完整的视差图。
创新点
- 采用单级网络,并且没有采用计算成本较高的3D卷积方式学习视差,而是利用残差网络在小尺度的视差图基础之上,逐层上采样学习残差,最终得到原分辨率的视差图
- 在特征提取过程中,增加边缘特征提取网络HED,利用边缘特征包含的中间信息,来改善最终得到的视差图效果
- 采用多任务训练方式,先利用ImageNet数据集训练边缘检测网络,并锁定参数;再锁定特征提取和边缘检测网络的权重,训练整个EdgeStereo网络(主要是环境金字塔和残差金字塔部分);最后再优化训练整个网络
####结论
该论文最大的突破在于引入了边缘检测网络,利用边缘特征来改善整个视差图的效果,就结果来看,在生成的视差图中物体的边缘位置的确更为清晰准确,并且视差估计和边缘检测两个任务之间能够相互帮助,使得两个任务的结果都有所改善。作者还对卷积金字塔,池化金字塔和空洞卷积金字塔进行了实验,实验结果表明池化金字塔的效果最好。多任务训练的方式也是很值得借鉴,能够有效的缩短训练时间。
8.《Improved Stereo Matching with Constant Highway Networks and Reflective Confidence Learning》
发表时间:2016年12月31日
网络名称:L-ResMatch
主体思想
本文的网络分为三个部分:匹配代价计算,视差计算,视差优化。在匹配代价计算部分也分成两级,第一级类似于特征提取,利用一个带有残差块的卷积网络分别从左右图中提取出特征图(文中称为描述符,Descriptor);第二级则是分为两个支路,一条支路是利用全连接网络,另一条支路则是直接对两幅图的特征图进行点乘,最后利用铰链损失函数和交叉熵损失函数组成的混合损失函数获得匹配代价。在视差计算部分,是将前一步得到的各个视差下的匹配代价,输入到一个卷积网络中,该卷积网络有两个阶段,第一阶段(FC3)由四个卷积层和三个全连接层组成,利用交叉熵损失函数,输出的结果是视差图。第二个阶段(FC5)在第一阶段的基础上,增加了两个全连接层,采用双边交叉熵损失函数,输出的是反射置信度(reflective confidence),将计算得到视差图的结果与真实值相比较,误差小于一个像素的标签置为正数,误差大于一个像素的标签置为负数。为两个损失函数计算得到的误差赋予权重并求和得到最终的误差,再进行反向传播。最后是视差优化部分,采用的还是传统方法,左右一致性检测,亚像素增强和中值滤波,双边滤波。
创新点
- 在特征提取部分采用了带有Inner-outer结构的残差块,即在两个普通残差块级联起来的基础上,再增加一个跳跃连接,并且这些跳跃连接都是带有权重的,还去掉了ReLU层和Batch Normalization层,据文章介绍这种做法有助于改善立体匹配的效果
- 在视差图生成部分,增加了反射置信度(reflective confidence)这一步骤,对每个位置的匹配情况给定一个二元化的标签(正确匹配为正数,错误匹配为负数)这有助于再迭代过程中不断优化视差计算结果
- 在匹配带价计算和视差计算部分都是分成了两个支路,并且都采用了不同类型的损失函数,一个采用混合损失函数的方式将两条支路融合在一起,另一个采用对损失函数进行加权求和的方式
结论
该论文发表时间较早,因此采用的匹配思路属于上一阶段的方式,并不是一个端到端的网络,但Inner-Outer残差块结构和Reflective confidence的计算都是很新颖的思路,可以尝试将其与自己的网络结构结合。
9.《End-to-End Training of Hybrid CNN-CRF Models for Stereo》
发表时间:2017年5月3日
网络名称:CNN-CRF
主体思想
作者构建了一个包含CNN和CRF(Conditional Random Fields)的网络,首先利用CNN从两幅图像中获取特征,然后经过一个correlation层,得到了不同视差下左右图中每个像素之间的相关性,correlation操作就是对左图(特征图)中的某个像素 ϕ i 0 \phi_i^0 ϕi0和右图(特征图)中视差为 k k k的像素点 ϕ i + k 1 \phi_{i+k}^1 ϕi+k1的点乘积,再经过一个softmax层归一化的过程。然后利用一个CRF去优化所有视差下的总代价,代价计算分为一元项(unary term)和成对项(pairwise term)。一元项很简单就是刚刚计算的相关性加一个负号(相关性越大,代价越低),成对项计算的是某个像素和他四连通区域(上下左右)内其他像素之间的关系,计算方法分成两种一种是固定权重计算方法,另一种是借助Pairwise-CNN网络来学习权重参数的方法,实验结果显示方法二的鲁棒性更好。但是要求出使得总代价值最小的视差很棘手,因此作者又引入了Dual-MM(基于 LP-relaxation算法)算法,使其容易利用GPU进行并行计算。最后计算得到使得总代价最小的视差图,并且不需要经过后处理过程依旧有很好的效果。
创新点
- 利用correlation层来计算左右特征图之间的相关性,并利用softmax层进行归一化
- 在CNN的基础上结合了CRF,借助其优化匹配代价,找出最优视差图
- 为了方便求解,提出了Dual-MM算法,优化了计算过程
结论
该论文将卷积神经网络与机器学习中的CRF方法结合在一起,提出一种新的寻找最优视差图的方法,其效果与最新的算法相比还是存在较大差距,但是不失为一种新的思路。其中提及了许多数学相关的计算方法还有CRF的概念,还需要进一步的学习。
10.《SGM-Nets:Semi-global matching with neural networks》
发表时间:2017年7月21日
网络名称:SGM-Nets
主体思想
作者将传统算法中的SGM(半全局匹配)和神经网络结合起来,利用神经网络学习SGM中的惩罚项,以代替人工设计。首先简单介绍了SGM算法思想,代价方程由匹配代价,倾斜惩罚项 P 1 P_1 P1和视差不连续惩罚项 P 2 P_2 P2组成,为了避免累加的结果过大,还减去上一个点的最小代价值。匹配代价可以利用传统方法(ZNCC等)计算出来,也可以利用卷积神经网络计算得到。作者构建的神经网络分为连两个过程——训练和测试。训练过程用于学习得到合适的惩罚项参数,而测试过程则是利用训练得到的参数,计算视差图。在训练过程中,作者设定了两个代价方程计算方法——路径代价和邻域代价。路径代价是指对于连续的像素点 x 0 , x 1 , x 2 , x 3 x_0,x_1,x_2,x_3 x0,x1,x2,x3,由 x 0 x_0 x0到 x 3 x_3 x3任意两点之间的代价值之和,对于真实视差值来说这一代价值无疑是最小的,该网络利用铰链损失函数不断修正参数使得代价值接近最小值。这一方法存在一个问题,虽然对于整个路径来说代价值是最小了,但对于路径中间,两个相邻点之间的路径不一定是最短的,为了消除这个问题,作者又引入了邻域代价。作者将相邻的两个点之间的关系分为三类:边缘,倾斜和平面,分别用不同的方法计算邻域代价值。使用这一方法有一个前提条件就是前一个点视差估计要是准确的,不然后面计算得到的代价值不可能是最小值,很难实现所有像素均满足这一要求,因此作者将路径代价和邻域代价按照一定比例相加,组成了一个整体的代价方程。上述过程作者称之为标准参数化,在此基础上作者又提出了新的参数化方法。考虑到在某些方向上视差变化有增有减,响应的惩罚项 P 1 P_1 P1, P 2 P_2 P2也是有正有负,作者对正负惩罚项分别计算,称之为有符号的参数化。最后作者介绍了SGM-Nets的网络结构,输入层是大小为55的图块和正则化后的图块位置,图块首先经过两个16通道的33的卷积层,特征图与正则化的图块位置级联起来输入两个全连接层,全连接层分别采用ReLU和ELU激活函数,输出的是四个方向上的惩罚项 P 1 P_1 P1, P 2 P_2 P2。
创新点
- 将SGM与卷积神经网络结合起来,利用神经网络学习惩罚项参数
- 构建了包含路径代价和邻域代价两部分的代价计算公式,并提出梯度计算公式,用于惩罚项的梯度反向传播计算
- 在原来工作的基础上又进一步提出有符号的参数化方法
结论
该论文是将SGM与神经网络结合在一起的,采取的计算思路与其他的方法均不相同,介于传统算法与深度学习方法之间,在代价计算公式和参数化方法上都提出了新的思路。就结果看来,效果优于传统算法和简单的神经网络算法(MC-CNN),但不如端到端网络效果好。
11.《Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains》
发表时间:2018年3月18日
网络名称:ZOLE
主体思想
作者发现现有的立体匹配网络在处理其他领域的图片时效果并不好,比如用手机采集的双目图像。作者观察到两个现象:1.训练好的模型在处理新的图片时会丢失很多细节信息,边缘模糊,作者称之为泛化缺陷;2.如果将图片上采样提高分辨率,处理后再将视差图下采样恢复分辨率,能够保留更多的细节信息,作者称之为尺度差异。基于这两个现象,作者提出了利用图拉普拉斯规则化对网络进行训练的方法。
对于真实值(ground truth)中的一个图块
s
s
s,它对于图
G
G
G应该是平滑的,具体来说就是拉普拉斯规则化算子
s
T
L
s
s^TLs
sTLs应该很小,其中
L
L
L是图G的拉普拉斯矩阵。对于某个模型生成的视差图,我们计算其中每一个图块的拉普拉斯规则化算子,将他们作为损失函数的一部分,用于引导网络的训练。实现这一过程的关键在于图
G
G
G的设定,这里引入一个样板图块(exemplar patches)的概念,它是一个图块的集合,这些图块是与真实值
s
s
s有统计学关系的(本文中选择了左图中的图块
f
l
e
f
t
f_{left}
fleft,当前视差图中的图块
f
c
u
r
r
f_{curr}
fcurr,优化后视差图中的图块
f
f
i
n
e
f_{fine}
ffine),确定了样板图块就能够计算出图
G
G
G的毗邻矩阵(adjacency matrix)
A
A
A和次数矩阵(degree matrix)
D
D
D,则拉普拉斯矩阵
L
=
D
−
A
L=D-A
L=D−A。如果在真实图块和样板图块中出现相同的边缘,则最小化拉普拉斯规则化算子能够使边缘更加突出;如果样板图块不连续,图拉普拉斯规则化能够产生平滑的图块。
作者采用的训练集包括两个部分:一是带有真实视差图的合成图片,另一个是其他领域中不带真实视差图的图片,作者利用尺度差异现象,将模型生成的视差图经过优化作为这一部分数据集的“真实视差图”。则损失函数由三部分构成,合成图片的真实视差图与模型生成的视差图之间的L1损失,其他领域图片的“真实视差图”与模型生成视差图之间的L1损失和拉普拉斯规则化算子。利用其对网络进行训练能够提高现有网络的泛化能力,保留更多的细节信息。
创新点
- 发现现有网络存在的两个现象:泛化缺陷和尺度差异,并利用其优化模型
- 没有从网络结构方面入手,而是针对现有的网络,在训练方法上进行优化,改善模型效果
- 引入拉普拉斯规则化算子用于网络模型训练
结论
该论文没有提出自己的网络结构,而是在现有网络的基础上,引入拉普拉斯规则化算子,对网络训练过程进行优化,得到了更具鲁棒性和泛化能力的网络模型。其提出的泛化缺陷和尺度差异现象,非常值得关注,也是进一步提高立体匹配网络效果的方向。
13.《Unsupervised Learning of Stereo Matching》
发表时间:2017年10月22日
网络名称:暂无
主体思想
作者提出了一种无监督的立体匹配网络,该网络无需输入真实视差图,就可以进行训练。其结构也可以分为三个部分:代价计算,代价聚合和视差生成。首先对输入的左右图进行卷积,提取特征,利用correlation层得到匹配代价卷;然后再从左右图中利用卷积提取特征图(与前面获得匹配代价卷的特征图不同,但个人感觉意义不大),将提取到的特征图级联到之前获得的匹配代价卷的每个通道上,再经过三层卷积之后获得最终的匹配代价卷,作者称之为连接滤波器(joint filter);最后利用soft argmax操作获得视差图。论文的关键在于无监督的学习方式,作者采用迭代方式,每次迭代都计算出视差图(左到右和右到左),从中选择出可信的匹配点,根据右图视差图,对左图视差图进行Wrap操作,再将重构的左图视差图与原本的左图视差图做差,差值的绝对值大于门限值的点,可信度为1,小于门限值的点,可信度为0。得到可信的视差值之后,可以根据点 P P P在左图中的坐标,加上视差值,找到对应右图中的点,组成新的训练数据,输入网络进行迭代训练。后处理步骤包括左右一致性检测和加权中值滤波。
创新点
- 提出一个无监督的立体匹配网络模型
- 在匹配代价聚合步骤中增加了连接滤波操作
- 在训练过程中采用迭代训练的方式,利用前一周期得到的视差图去寻找可信的匹配点,再进行训练,反复迭代准确率不断提高
结论
该论文针对现有网络对于训练数据集过度依赖的情况,提出了一种新型的无监督网络模型,其估算视差的网络结构并不复杂,但采用了反复迭代的训练方式,能够不断提高计算精度。在准确率方面,虽然是无监督学习,但仍可以和早期的有监督网络相媲美。
14.《Unsupervised Adaptation for Deep Stereo》
发表时间:2017年10月22日
网络名称:暂无
主体思想
作者在现有立体匹配网络的基础上,提出一种无监督的训练方式。作者首先构建了一个新的损失函数,该损失函数包括两个部分:置信度引导损失和平滑项。作者利用传统的立体匹配算法(AD-Census或SGM)得到参考视差图 D D D,再利用现有网络(DispNet)得到视差图 D ~ \tilde{D} D~,利用置信度测量算法(本文采用CCNN)求出两者之间每个像素的置信度 C ( p ) C_{(p)} C(p),如果 C ( p ) C_{(p)} C(p)大于门限值 τ \tau τ,则该像素处的置信度引导损失 ε ( p ) = C ( p ) ∣ D ( p ) − D ~ ( p ) ∣ \varepsilon_{(p)}=C_{(p)}\left |D_{(p)}-\tilde{D} _{(p)} \right | ε(p)=C(p) D(p)−D~(p) ,否则为0,整体的置信度损失 C L = 1 ∣ P ∣ ∑ p ∈ P ε ( p ) C_L=\frac{1}{\left | P \right |}\sum_{p\in P}\varepsilon _{\left ( p \right )} CL=∣P∣1∑p∈Pε(p)。该算法的思想是利用传统立体匹配算法和置信度算法从参考视差图中选出可靠的点,作为真实值,如果置信度太低,这样的点就不去计算损失,置信度满足要求的,才会计算损失值。因为上述方法得到的视差图是稀疏的(许多点处的置信度不满足要求),因此要利用平滑项去补偿这些损失,平滑项的计算也非常简单,对于一点 p p p, q q q是其邻域(该范围是根据两点之间得L1距离计算得,范围上限是个超参数,需要人为选定)内的任意一点,计算 ∣ D ~ ( q ) − D ~ ( p ) ∣ \left |\tilde{D}_{(q)}-\tilde{D} _{(p)} \right | D~(q)−D~(p) 并求平均值得到 p p p点处的平滑项 E ( p ) E_{(p)} E(p),最后对所有的 p p p点的 E ( p ) E_{(p)} E(p)求平均值得整张图得平滑项 S S S。最终的损失函数为 L = C L + λ ∗ S L=C_L+\lambda *S L=CL+λ∗S,其中 λ \lambda λ为权重系数,也需要人为选定。通过训练使得损失值不断缩小,则得到的视差图就不断优化。
创新点
- 提出一个无监督的立体匹配网络的训练方法
- 引入置信度损失函数,借助传统算法选择可信度高的点,用于训练
- 引入平滑项,减少稀疏视差图的影响
结论
无监督的学习方法核心问题在于如何在没有给定真实值的条件下,找到近似的真实值,这篇论文采用的方式是用传统算法得到的视差图和用深度学习方法得到的视差图相比对,计算出可信度,可信度高的点组成了近似的真实视差图。根据作者的实验,在参数选定合理的情况下,该方法得到的近似视差图是很接近真实视差图的,只不过是稀疏的,利用平滑项可以得到有效的补充。根据实验结果来看,该算法能够有效的提高深度学习算法的适应性和泛化能力,在缺少真实值的复杂环境下也有着更加优秀的表现。该算法中仍存在超参数过多,传统算法得到的参考视差图是否合理等问题,但在监督学习算法的精度已经很难有大幅度提高的情况下,寻找如何提高网络的泛化能力和减少网络的计算成本都是不错的思路。
15.《Learning from scratch a confidence measure》
发表时间:2016年9月22日
网络名称:CCNN
主体思想
该篇文章提出的并不是一个立体匹配的网络,而是一个计算视差图置信度的网络,就是上文中提到的CCNN。作者观察到视差图上存在很多重复的纹理,这些重复的图块能够用于评估视差分布的可靠性。作者构建了一个CNN网络,输入视差图,输出的是该视差图的置信度。对于视差图上的每个像素,作者都提取一个方形的图块作为样本(大小为99)将其输入四层通道数为64的33的卷积层,得到64个11的特征值,再经过两层100通道的全连接层(用11的卷积层代替),最终输出一个数字用于表示置信度。对于整个视差图上的所有样本图块,均采用相同权重的网络进行前向计算,而不是每个图块都分别训练,者能够有效的提高计算效率。在训练过程中,只对真实值可获得的像素提取样本(KITTI2012上大约只有1/3的像素是可获得真实视差值的),训练用的视差图是利用块匹配算法(Block Matching,BM)得到的,训练过程中对于卷积层部分,采用扇入比(fan-in)为1的随机链接表(random connection tables),即对于每一个卷积核,其输入都是从上一层的特征图中随机选取一个,这能够改善学习效果,提高学习速度。最终利用sigmoid函数计算标签值,采用BCE(双边交叉熵损失函数)和SGD算法。最后作者引入AUC(Area Under the Curve)的概念,用于评价视差图置信度测量算法的优劣,根据实验结果来看,该算法在KITTI2015和Middlebury2014数据集上的表现均优于其他算法,说明其具有较好的泛化能力。
创新点
- 提出一个视差图置信度计算网络
- 训练过程中采用了“随机链接表”
- 引入AUC概念用于评价置信度测量算法的优劣
结论
该网络的目标并不是得到一个视差图,而是对已得到的视差图的可信度做一个定量的评价,它可以给出一个置信度图,表示那些像素的视差是可靠的,而哪些是错误的,这可以为视差图的优化提供一个新的思路,获得了一个新的信息。前文介绍的无监督学习模型,均采用了相应的置信度测量函数用于网络的训练,可见该方法在提高网络的鲁棒性与泛化能力方面有一定的作用。
16.《Deep Material-aware Cross-spectral Stereo Matching》
发表时间:2018年6月22日
网络名称:DPN+STN
主体思想
该篇文章不再单纯研究RGB双目摄像头的立体匹配问题,而是借助RGB-NIR(近红外摄像头)来解决立体匹配的问题。作者的基础网络结构分为两个部分视差预测网络(DPN)和光谱转换网络(STN)。其中DPN是参考Godard 等人提出的网络结构,其作用是输入一对立体图像,输出视差图,唯一的区别在于此时输入的是RGB-NIR立体图像(左图是RGB图像
I
C
l
I^l_C
ICl,右图是NIR图像
I
N
r
I^r_N
INr);而STN网络的作用是输入一幅RGB图像,输出一个伪NIR图像
I
p
N
l
I^l_{pN}
IpNl。该网络是一个无监督网络,DPN网络得到左右视差图(
d
l
,
d
r
d^l,d^r
dl,dr),对NIR图像
I
N
r
I^r_N
INr和左视差图
d
l
d^l
dl做Wrap操作可得到重构的左NIR图像
I
~
N
l
\tilde{I}^l_N
I~Nl,同样的对伪NIR图像
I
p
N
l
I^l_{pN}
IpNl和右视差图
d
r
d^r
dr做Wrap操作可得到重构的右伪NIR图像
I
~
p
N
r
\tilde{I}^r_{pN}
I~pNr,通过比较
I
~
N
l
\tilde{I}^l_N
I~Nl和
I
p
N
l
I^l_{pN}
IpNl,
I
~
p
N
r
\tilde{I}^r_{pN}
I~pNr和
I
N
r
I^r_N
INr之间的误差,对网络进行训练。DPN的损失函数分为三个部分:视野连续性项(
L
v
L_v
Lv,描述左右视差图之间的连续性);校准项(
L
a
L_a
La,比较NIR图像与伪NIR图像之间的亮度和结构差异);平滑项(
L
s
L_s
Ls,平滑图像边缘视差不连续的区域);STN的损失函数直接比较NIR图像和伪NIR图像之间的亮度差异。
作者观察到立体匹配在许多不可靠的表面表现很差,如反光表面,透明玻璃和发光物体,因此作者在原网络的基础上引入了材料感知置信度(Material-aware Confidence),主要作用在两个方面:一、使用新型的置信度加权平滑技术将可靠区域的视差传播到不可靠的区域;二、通过重写与材料相关的校准项和平滑项损失函数,来拓展DPN网络的损失函数。置信度加权视差平滑,对于某个点处的平滑项损失,其数值与上下左右像素的视差置信度有关,置信度是根据该像素所属的材料类别计算的;材料感知损失函数,利用Deep Lab提出的网络可以计算出图像中各个物体所属材料的概率(包含反光表面,透明玻璃和发光物体等共8个类别),材料感知损失函数就是在原损失函数的基础上,利用所属材料的概率进行加权求和,例如对于一个像素点
p
(
x
,
y
)
p(x,y)
p(x,y),其校准损失和平滑损失都是原损失值乘以属于各个材料的概率,再相加求和。其中对于反光表面,透明玻璃和发光物体这三种不可靠的材料,其平滑项计算是利用上文提到的置信度加权平滑损失计算的,其他材料均采用正常的计算方法。
创新点
- 提出一个基于RGB-NIR相机的无监督立体匹配网络
- 在原有的DPN+STN网络基础上引入了材料感知置信度损失函数,对于不可靠区域专门处理
- 在STN网络中为了避免视差的影响,采用对称的结构,对左右图做相同的处理
结论
该网络有两个大的突破,首先把目光转向了其他结构光图像上,而不仅仅是关注RGB图像,其次是关注到物体的材料这个属性对于视差生成的影响,对于某些特殊的材料需要单独进行处理。其同样采用无监督训练网络,这看起来是一个重要的趋势,处理速度较快,基本满足实时性要求。但对于材料感知损失函数的设定和置信度的计算方法,人为设计内容较多,可能会影响算法的鲁棒性。
17.《Efficient Deep Learning for Stereo Matching》
发表时间:2016年6月27日
网络名称:Content-CNN
主体思想
该篇文章是立体匹配与深度学习结合的早期的文章,作者基本沿用了Siamese的网络结构,将最后级联层和后处理部分用一个简单的内积层代替,将计算效率大大提高。作者的网络是由两个共享参数的平行的4层卷积层构成,分别输入左右图块,左图的尺寸与网络的感受野大小相同(9*9),右图尺寸要更大(不是很理解这样做的目的)。两幅图分别经过卷积层后,左图输出64幅特征图,右图输出所有视差情况下的64幅视差图,左侧输出分别在不同的视差下与对应的右侧特征图进行点乘积运算,对点乘运算结果经过softmax层,就得到了某个像素属于不同视差的可能性,选择可能性最大的作为该点的视差。利用交叉熵损失函数训练网络,该网络本质上是一个分类网络,类别就是所有的视差值,通过比较相似性来确定某个像素点属于哪一个视差类别。作者还研究了不同的平滑处理步骤对于视差估计的改善效果,包括成本聚合,半全局块匹配,倾斜平面匹配和精细的后处理步骤。
创新点
- 在Siamese网络的基础上将最后一层改为点乘积层,提高了计算效率
- 研究了不同的平滑处理步骤对视差估计的作用
结论
该网络是早期以分类思想为主导的网络结构,在Siamese网络的基础上,不仅大幅度提高了运算效率,降低了运行时间,同时视差图的效果也达到当时先进水平,是一篇比较重要的基础论文,其对平滑处理工作的呀研究,对于后来者选择处理方式也有着很重要的参考价值。
18.《Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches》
发表时间:2016年1月1日
网络名称:MC-CNN-art/fast
主体思想
该篇文章Zbontar和LeCun是在深度学习应用在立体匹配领域的第二篇文章,是之前工作的一个拓展,其利用CNN从左右图块中提取特征,并计算相似度,进而得到匹配代价。该篇论文介绍了两个网络,一个是快速网络,计算速度快,但精度稍差;一个是精准网络,精度高,但速度慢。对于两个网络的初级部分是相同的,都是两个共享权重的卷积层叠加,分别从左右图块中获得抽象的特征信息,区别在于最终计算相似度的方法,快速网络直接使用cosine相似度测量函数计算两个特征图的相似度;而精准网络则是训练了一个由全连接层构成的神经网络输出两个特征图的相似度。在训练过程中,作者将首先对每幅图片的每个视差可知的像素点都提取了两个图块对,一个是正图块对(左图中的一个图块和右图中对应视差正确邻域内的一个图块),一个是负图块对(左图中的一个图块和右图中对应视差错误邻域内的一个图块)。对于快速网络来说,训练采用的是铰链损失函数,输入正图块对,输出的相似度为
S
+
S^+
S+,输入负图块对,输出的相似度为
S
−
S^-
S−,则损失函数为
L
o
s
s
=
m
a
x
(
0
,
m
+
S
−
−
S
+
)
Loss=max(0,m+S^--S^+)
Loss=max(0,m+S−−S+)其中
m
m
m是一个边界值,用作参数调整的。如果输出的
S
+
S^+
S+比
m
+
S
−
m+S^-
m+S−还大,那么损失值就为0,否则为
m
+
S
−
−
S
+
m+S^--S^+
m+S−−S+(一个正数)。
对于精准网络,其损失函数是二元交叉熵损失函数,输出的相似度为
s
s
s,正图块对的标签
t
=
1
t=1
t=1,负图块对的标签
t
=
0
t=0
t=0,则损失函数为
L
o
s
s
=
t
l
o
g
(
s
)
+
(
1
−
t
)
l
o
g
(
1
−
s
)
Loss=tlog(s)+(1-t)log(1-s)
Loss=tlog(s)+(1−t)log(1−s)
最终的匹配代价即输出相似度加负号,相似度越高,匹配代价越低。后面又采用了十字交叉代价聚合,半全局匹配算法,WTA计算视差。在后处理步骤中,首先采用插值法来补充左右视差不一致的点,再利用亚像素增强来提高算法的分辨率,最后采用精细化处理,包括中值滤波和双边滤波,来平滑视差图。
创新点
- 提出了快速网络和精准网络两个立体匹配模型,为后面的研究者提供了重要的学习和参考对象
- 制作正负图块对用于网络训练,并根据相似度测量算法,选择适当的损失函数
结论
该网络是立体匹配领域中的里程碑式的作品,后来的许多算法都是在其研究的基础上进行优化和改善,其快速网络和精准网络的计算结果也是许多算法评价的参考标准。早期的网络只局限于使用CNN来计算匹配代价,后续仍需要传统的算法来计算视差和优化视差。而且其训练过程比较复杂,计算速度也较慢,且不能进行端到端的训练,因此逐渐被新型的算法所取代。
19.《Computing the Stereo Matching Cost with a Convolutional Neural Network》
发表时间:2014年9月15日
网络名称:MC-CNN
主体思想
该篇文章首次将深度学习引入立体匹配领域,利用卷积神经网络从左右图中提取特征并计算匹配代价,其结构由一个8层的网络构成,输入99的左右图块,L1是一个32通道的55的卷积层,L2和L3是由200个神经元组成的全连接层,L1、L2、L3是两个权值共享的平行支路,然后将左右支路得到的200个神经元级联起来,组成一个400*1的特征向量,L4-L7是4层300维的全连接层,最后L8利用soft max函数输出两个数值,分别代表匹配的可能性和不匹配的可能性。该网络在训练过程中也需要先制作正负图块对,损失函数采用的是交叉熵损失函数。
图像匹配代价的计算是选择网络输出的不匹配的可能性,后面又采用了十字交叉代价聚合,半全局匹配算法,WTA计算视差。在后处理步骤中,首先采用插值法来补充左右视差不一致的点,再利用亚像素增强来提高算法的分辨率,最后采用精细化处理,包括中值滤波和双边滤波,来平滑视差图。
创新点
- 首次将神经网络引入立体匹配流程中,用于匹配代价的计算
结论
该网络Zbontar和LeCun在深度学习应用于立体匹配的开山之作,也是后面众多研究工作的基石,它摆脱了传统算法需要手动设计匹配算法的思路,利用神经网络提取更加抽象,更加鲁棒的特征来计算匹配代价,取得了划时代的进步。至此之后,立体匹配的主流算法都是结合深度学习方法了,尽管现在看来这个网络是一个很简单且低效的结构,但他的影响却是巨大的。
20.《Stereo Matching Using Conditional Adversarial Networks》
详细内容
发表时间:2017年10月
网络名称:暂无
主体思想
该篇文章首次将条件对抗生成网络(cGANs)应用到立体匹配领域中。对抗生成网络(GANs)分为生成器和区分器,生成器根据输入的信息生成一幅图像,将生成的图像和真实图像随机输入到区分器中,区分器用于区分输入的图像是真实图像还是生成的图像,两个网络相互对抗,直至生成的图片十分接近真实图片,使得区分器无法分辨。本文提出的网络结构同样包含这两个部分,首先将左右图像输入到生成器中,生成器是由Siamese网络和U-net网络构成,利用Siamese分别从左右图像中提取特征,在级联后送入U-net网络,U-net网络是一个带有跳跃连接的编码解码结构,这种结构在扩大感受野的同时还能保留高频的细节信息,输出视差图。区分器的输入包含左右图像和视差图,此处随机输入真实视差图和生成的视差图,左右图像同样经过Siamese网络来提取特征和卷积层来融合特征,视差图经过卷积层后,与融合特征级联起来,再进行卷积和Sigmoid操作,输出一个数值,表示此次输入的视差图是真实视差图还是生成的视差图,引导生成器不断优化生成的结果。
创新点
- 首次将条件对抗生成网络引入立体匹配过程中,用于引导生成器不断生成更加接近真实值的结果
- 采用混合损失函数,L1损失项用于捕捉低层次信息,对抗损失项用于捕捉高层次的环境信息
结论
该网络本质上是利用对抗生成网络的思想来训练视差生成网络,是一次大胆的尝试,但不知道在缺少真实视差图的情况下,该网络的泛化能力如何(例如用Scene Flow数据集进行训练,而用KITTI数据集测试)。其引入对抗损失函数的思路仍值得借鉴。
21.《End-to-End Disparity Estimation with Multi-granularity Fully Convolutional Network》
详细内容
发表时间:2017年10月28日
网络名称:MG-FCN
主体思想
该篇文章提出了在不同粒度条件下分别进行correlation操作,从而能够得到不同粒度下的多种匹配信息。其网络结构分为三个部分:多粒度特征表示,correlation层和级联的反卷积层。首先,将左右图输入一个预训练好的ResNet-50网络,然后分别提取它在conv1,pool1和res4a层处输出的特征图,这就代表不同粒度下的特征。对这些特征图分别做最大位移为96,48,24的correlation操作,得到不同粒度下的左右图匹配信息。然后将其分别送入三个残差网络,进一步编码匹配信息,并且使图像尺寸统一为原图的1/8,再将三个网络的输出结果级联起来,输入到一个级联的反卷积结构中,进行3次放大比例为2的反卷积,最后经过一个1*1的卷积层输出视差图。损失函数为L1损失。
创新点
- 利用ResNet-50网络获得不同粒度下的特征信息
- 对不同粒度下的特征信息进行correlation以获得多种匹配信息,增强视差预测效果
结论
该网络提出的不同粒度的概念,其实与不同尺度的概念相似,所谓不同粒度就是对应ResNet网络中尺寸为分别为原图的1/2,1/4,1/8的特征图,区别在于本文分别对三个粒度下的特征图做correlation操作,分别进行编码后,再将其级联起来。如作者所言,这样能够获得高层次的类别信息用于补充低层次的匹配信息。
22.《MC-DCNN: Dilated Convolutional Neural Network for Computing Stereo Matching Cost》
发表时间:2017年10月28日
网络名称:MC-DCNN
主体思想
该篇文章将空洞卷积应用到了MC-CNN网络中,来代替原本的卷积层。其网络结构与MC-CNN大体相同,左右图分别输入两个平行的Siamese网络,网络分为五层,对应的空洞值分别为1,1,2,4,8。每个卷积层后面是批规范化(BN)层和ReLU层,略有不同的是每个分支,分别将第3、4、5层的输出级联起来,作为最终的输出,而不是只输出第五层的输出,作者指出这既能保持较好的不变性,又能保留低层次的细节信息。空洞卷积,当空洞值为1时,就是普通的卷积层,卷积核为为紧密相邻的矩阵(33或者其他);而当空洞值为2时,卷积核每两个点之间都有一个空格,不再是紧密相邻的了,空洞值为n时,每两个点之间的间距为(n-1)。在保证参数没有变多的前提下,扩大了感受野,三层空洞值为1,2,4,卷积核为33的卷积层,对应的感受野分别为33,77,15*15。左右两个分支网络的输出级联起来再进入三个卷积层和一个Sigmoid层输出相似度。仍需要十字交叉代价聚合,半全局匹配,亚像素增强,中值滤波和双边滤波等后处理步骤,最终输出视差图。
创新点
- 利用空洞卷积扩大感受野,获得更多环境信息
- 级联多个层次的特征图,保留更多的低层次细节信息
结论
该网络是MC-CNN网络众多衍生版本中的一个,在原网络的基础上引入了空洞卷积,在没有增加参数的情况下,提高了匹配的准确性。
23.《Disparity Estimation Using Convolutional Neural Networks with Multi-scale Correlation》
发表时间:2017年10月28日
网络名称:暂无
主体思想
该篇文章是在Mayer等人的网络基础上,提出了采用多尺度的correlation操作来代替原有的单一尺度的correlation操作。他们发现小尺度的correlation核适用于尺寸较小,细节信息丰富的物体,而大尺度的correlation核适用于尺寸较大,但纹理一致的物体。首先,左右图输入两个卷积网络分支提取特征图,特征图在做correlation操作时,不再是单独的每两个像素之间相乘,而是水平相邻的3个或7个像素分别对应相乘再求和,作为第一个像素的相关性度量值(是否往两侧延伸,计算中间像素的相关性更合适?)。像素点
(
x
,
y
)
(x,y)
(x,y)处,位移值为
d
d
d的相关性计算方法如下:
F
m
(
x
,
y
)
=
∑
n
=
1
K
∑
j
=
0
N
∑
i
=
0
M
F
n
l
(
x
+
i
,
y
+
j
)
×
F
n
r
(
x
+
i
+
d
,
y
+
j
)
F_m(x,y)=\sum_{n=1}^{K}\sum_{j=0}^{N}\sum_{i=0}^{M}F_{n}^{l}(x+i,y+j)\times F_{n}^{r}(x+i+d,y+j)
Fm(x,y)=n=1∑Kj=0∑Ni=0∑MFnl(x+i,y+j)×Fnr(x+i+d,y+j)式中
F
n
l
,
F
n
r
F_{n}^{l},F_{n}^{r}
Fnl,Fnr表示第
n
n
n个通道的左右特征图,
K
K
K是通道数,
[
N
×
M
]
[N\times M]
[N×M]表示correlation核的尺寸,本文取
[
1
×
1
]
,
[
1
×
3
]
,
[
1
×
7
]
[1\times 1],[1\times 3],[1\times 7]
[1×1],[1×3],[1×7]
分别在三个尺度下做correlation操作之后,再将输出的correlation图级联起来输入压缩层(由8个卷积层构成),再进入上采样层,最后获得视差图。在训练过程中,为了提高训练速度,作者还提出里水平样条训练方法,将768384的原始图片分割为3个768128的图块,再进行训练,总的参数量不会变化,且训练损失收敛更快,且更稳定。
创新点
- 采用多尺度的correlation操作,对于大尺寸弱纹理的物体和小尺寸细节丰富的物体都有很好的处理效果
- 训练过程中把图片分割成图块,增加批尺寸(batch size),使训练速度更快,效果更加稳定
结论
该网络是一个端到端的网络,其结构是优于同时期的其他网络的。在corelation操作中采用多尺度的方法,这也反映出从不同尺度下获取更多信息,是改善立体匹配网络的关键因素。其采用的水平样条训练的方法,在内存和计算速度有限的情况下,可以改善网络的训练效果,提高网络的训练速度。
24.《Fundamental Principles on Learning New Features for Effective Dense Matching》
发表时间:2017年9月14日
网络名称:CNNF+SGM
主体思想
该篇文章总结了现有特征描述算子的存在的问题,并提出了评价一个特征是否合理的两条原则——一致性和辨别性。一致性是指特征点应该与其他视图中的对应点相同或者相似;辨别性是指特征点与他邻域内的点有足够的差别。作者基于这两条原则提出了两个特征描述算子,但不可能同时满足两条原则,因此作者将其归化为一个多目标的优化问题,试图寻找他的Pareto解。为此,作者设计了一个卷积神经网络,利用反向传播算法来优化两个特征算子,作者提出了相应的损失函数,为了利用梯度反向传播,还对特征描述算子进行调整,使其可微分。将提取到的特征与其他的算法结合起来就可以得到视差图,根据实验可知本文提取的特征在光滑表面的表现更好,并且对于光照变化和噪声更具鲁棒性,最重要的是他的通用性很强,可以与很多的算法结合,来优化结果。
创新点
- 提出了特征描述算子的两个原则:一致性和辨别性,并据此提出更具鲁棒性和通用性的特征描述算子
- 将匹配问题归化为一个多目标优化问题,并利用卷积神经网络进行求解,得到更好的特征用于计算匹配代价
- 将提取到的特征与现有算法结合起来,得到了优于原算法的结果,并探究了网络结构复杂度和输入图像尺寸对结果的影响
结论
该网络是是作者在实验之后,结果最好的一种组合,用本文提出的方法获得特征,并计算匹配代价,再结合SGM算法得到视差图。本文提出的特征描述算子的两条准则对于后来的算法具有指导性的意义,但后来的算法大多利用CNN提取抽象的特征,因此该思想并没有广泛应用。
25.《A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation》
发表时间:2015年12月7日
网络名称:DispNets
主体思想
该篇文章首先提出了一个大规模的数据集Scene Flow,为后面的网络训练提供了充足的资源。其次将在光流(optical flow)领域取得很好效果的FlowNet推广到了立体匹配领域中,用于端到端训练,估算视差值。与FlowNet相同,本文提出了两种网络形式:DispNetS和DispNetC。DispNetS是一个较为简单的结构(S表示Simple),左右图级联起来输入一个6层的压缩网络,由步长为2的卷积层构成,用于提取特征。然后再进入扩展网络,由反卷积层组成,由粗到细逐步还原分辨率,最终输出视差图。整个过程中是全程监督的,就是每反卷积一次就会计算对应分辨率下的损失值,用于监督网络训练。DispNetC是引入correlation操作的结构,左右图分别进入一个压缩网络进行特征提取,对提取到的特征图做x方向上的correlation操作,因为是一维的corelation,因此可以选择较大的位移值(最大位移值为40),将correlation之后的特征图进一步压缩,再反卷积还原分辨率,得到最终的视差图。
创新点
- 提供了一个开放的大规模合成数据集,方便深度网络的训练
- 首次在立体匹配领域提出了端到端训练的网络
- 对左右特征图进行correlation操作来寻找左右特征图之间的对应关系
结论
该网络引入了一个全新的思路,完全摒弃了代价聚合,视差计算,视差优化等传统算法的步骤,利用卷积神经网络实现了端到端的训练过程,尤其是DispNetC网络中采用的先压缩再拓展的结构和Corelation结构,为后来的算法提供了一个参考模型。
26.《Patch Based Confidence Prediction for Dense Disparity Map》
发表时间:2016年9月22日
网络名称:PBCP
论文来源:
主体思想
该篇文章主要做了两方面的工作,第一,首次提出了利用卷积神经网络对视差图置信度进行评判的方法;第二,将置信度与SGM算法结合起来,作为一个额外的惩罚项,用于优化视差图。首先作者设计了一个双通道的视差图块,用于置信度计算,第一个通道利用了中心像素与邻域内其他像素的关系,如果邻域内其他像素的视差是连续的,则表示该中心像素更有可能是正确匹配的;第二个通道借助了左右一致性原则,由左图得到的视差与由右图得到的视差应该相近或相同。将这个双通道的图块输入一个由4层卷积层和1层全连接层构成的网络,卷积层中,第一层有6个通道的33卷积核,其他三层有4个33的卷积核,全连接层合并为两个神经元,并经过softmax函数输出正确匹配的置信度和错误匹配的置信度。为了提高计算效率,作者还在此基础上对双通道的视差图块计算方法做了改进,提出了混合型网络,实现了最优效果。
为了获得稠密的视差图,作者将计算得到置信度与SGM的惩罚项结合起来,如果置信度小于设定的值,则会作为惩罚项加到能量方程中,置信度高的点则不会有额外的惩罚。
创新点
- 首次利用卷积神经网络来计算视差图的置信度
- 提出一种双通道的视差图块计算方法,用于计算视差置信度
- 将置信度作为一种惩罚项引入了SGM算法中,得到了效果更好的视差图结果
结论
该文是较早的利用卷积神经网络去对传统算法进行优化的文章,也是首次利用CNN来计算视差图的置信度,也证明了神经网络在这项任务中具有巨大的潜力。这为后面的无监督学习提供了一个训练网络的基本思路——利用置信度去评价视差图的优劣。其只是在SGM算法中引入了一点点改进,但是一种全新的尝试,为后续更加深入全面的结合打下了基础。
27.《Semi-supervised learning of deep metrics for stereo reconstruction》
发表时间:2016年12月3日
网络名称:MC-CNN-WS
论文来源:
主体思想
该篇文章提出一种半监督的学习方式,与传统算法输入为左右对应的图块对不同,本文将图块分为三类,左图中某条水平线上的图块作为参考图块 e r = ( p 1 r , p 2 r , . . . p W r ) e^r=(p_1^r,p_2^r,...p_W^r) er=(p1r,p2r,...pWr);右图中对应水平线上的图块称为正图块 e + = ( p 1 + , p 2 + , . . . p W + ) e^+=(p_1^+,p_2^+,...p_W^+) e+=(p1+,p2+,...pW+);右图中其他水平线上的图块称为负图块 e − = ( p 1 − , p 2 − . . . p W − ) e^-=(p_1^-,p_2^-...p_W^-) e−=(p1−,p2−...pW−), W W W是一条水平线上的图块数量。首先,对于某一条水平线上的 W W W个图块构建一个相似度矩阵 S i j r + S_{ij}^{r+} Sijr+,表示参考图块 p i r p_i^r pir和正图块 p j + p_j^+ pj+之间的相似度, i , j ∈ { 1 , 2... W } i,j\in \left\{1,2...W\right\} i,j∈{1,2...W}。然后,作者依据立体匹配中的假设条件设计了三种半监督的学习方式,MIL方式是根据极线约束和视差范围约束制定的,核心思想为正图块之间的相似度应该大于负图块之间的相似度;CONTRASTIVE 方式是根据极线约束、视差范围约束和独特性约束制定的,核心思想为匹配点之间的相似度应该大于同一条极线上其他任意两点之间的相似度;MIL-CONTRASTIVE没有仔细介绍,大体上是把两种方法按比例结合起来;CONTRASTIVE-DP是基于极线约束、视差范围约束、独特性约束、连续性约束和顺序约束指定的,DP是指动态规划,对同一条极线上的所有像素找到一条平均相似度最高的路径,对于路径上的点其对应的相似度应该大于其邻域之外的其他点之间的相似度。在铰链损失函数的基础上结合三种方法的思想,设计出对应的损失函数。最后,将MC-CNN-fast网络做一定的改造,运用本文提出的方法进行无监督训练,后续的处理步骤相同,得到视差图。
创新点
- 根据立体匹配中的约束条件设计了一种半监督的训练方式
- 融合了动态规划的思想,在相似度矩阵中寻找平均相似度最大的路径
- 与MC-CNN-fast网络结合起来,得到一个半监督网络模型
结论
该文章根据立体匹配中常用的约束条件设计了一种半监督的训练方式,并在过程中巧妙地结合了动态规划地思想,在MC-CNN-fast网络的基础上修改得到了一个半监督的网络模型。根据作者地实验结果,利用地约束条件越多,得到地匹配效果越好。
28.《Self-Supervised Learning for Stereo Matching with Self-Improving Ability》
发表时间:2017年9月4日
网络名称:SsSMnet
论文来源:
主体思想
该篇文章提出一种自监督的学习方式,其核心思想在于利用左右图得到的视差图,对左右图进行Wrap操作之后得到对应的重构图,将重构图与原图比较得到重构误差,以此作为损失训练网络。其网络分为五个部分:1.特征提取,与GC-Net相似分别对左右图做权值共享的卷积操作;2.特征卷组合,此处并没有将左右两个通道的特征图直接级联起来,而是将左右图混合起来,以左特征图 a a a为例,对应的右特征图 b b b相对于 a a a视差为0,将 b b b中像素向右平移一个像素,则得到视差为1的特征图 b 1 b_1 b1,将 a a a分别与 b , b 1 , . . . b D m a x b,b_1,...b_{Dmax} b,b1,...bDmax级联起来组成 D m a x + 1 Dmax+1 Dmax+1个图片对,再将这些图片对级联起来组成了一个特征图卷,对于右图做同样的操作;3.利用3D卷积做特征匹配,同样采用了编码解码结构,先压缩至原尺寸的1/16,再反卷积恢复原分辨率,得到匹配代价卷;4.Soft-argmin操作得到视差图;5.利用得到的视差图,对左右图分别做Wrap操作,得到重构的左右图用于训练网络。损失函数包含了四个部分:一元特征项,规则化项,一致性项和最大深度约束。因为不需要真实视差图进行监督,该网络还具有自适应学习的能力,可以在测试过程中不断学习,使网络更加适应新的环境。
创新点
- 在特征卷构建过程中采取新的方式
- 设计了一个适用于自监督学习的损失函数
- 网络具备自适应学习的能力,提高网络的泛化能力
结论
该文章提出的自监督学习网络思路非常清晰,充分利用wrap操作得到的重构图像对网络进行训练。尤其是损失函数中的一致性项和最大深度约束两个部分是之前没有见过的方式,很值得的进一步的探究。该网络首次赋予了模型自适应学习的能力,这对于将网络应用于实际场景具有重要意义。
29.《On the Importance of Stereo for Accurate Depth Estimation:An Efficient Semi-Supervised Deep Neural Network Approach》
发表时间:2018年4月20日
网络名称:NVStereoNet
论文来源:CVPR2018
主体思想
该篇文章首先比较了单目深度估计和双目立体匹配之间的区别,证明在准确率上单目视觉与双目视觉还存在较大差距。然后提出一个半监督的网络模型,其网络结构是基于GC-Net的,首先是特征提取,然后构建特征卷(参见上篇笔记28),利用3D卷积计算匹配代价,在计算视差部分提出一种新型的计算方法ML-argmax用于代替softmax方法,ML-argmax是由4个3*3的卷积层和一个sigmoid层构成的,整个过程中激活函数用ELU代替ReLU+BN。损失函数也包含四个部分图像损失,激光雷达损失,一致性损失,平滑性损失。图像损失即左图与重构的左图之间的差别,利用SSIM方法计算;激光雷达损失即与真实视差图之间的L1损失;一致性损失是将左视差图进行Wrap操作与右视差图做比较;平滑性损失是鼓励视差图各像素之间尽量平滑。如果令激光雷达损失的权重为0,即为无监督学习,如果图像损失和激光雷达损失各占一定比例则为半监督学习(KITTI2012的真实视差图是稀疏的)。
创新点
- 视差计算部分提出ML-argmax方法用于代替Softmax
- 设计了一个损失函数,通过调整系数来实现半监督或无监督学习
- 将模型应用到嵌入式的平台Jetson-TX2中
结论
该文章首先证明了在深度估计领域双目视觉的精确度是由于单目视觉的,这为后来的研究指明了方向。然后提出了ML-argmax方法用于计算视差,实验证明该方法由优于softmax方法。最后,设计了一个新的损失函数,将图像损失(自监督)和激光雷达损失(半监督)结合起来,实验证明单独的激光雷达损失(半监督)效果<单独的图像损失(自监督)<两者结合算法。
30.《SegStereo: Exploiting Semantic Information for Disparity Estimation》
发表时间:2018年7月31日
网络名称:SegStereo
论文来源:
详细内容
主体思想
该篇文章将语义分割与视差估计结合起来,利用语义信息来解决视差估计中模糊区域的问题。语义信息是通过两种方式结合到视差估计流程中的:嵌入语义特征和语义softmax损失。首先利用PSPNet网络的浅层部分进行特征提取,对得到的特征图 F l F^l Fl和 F r F^r Fr做correlation操作得到匹配代价卷 F c F_c Fc,并将特征图送入语义特征提取网络得到语义特征图 F s l F_s^l Fsl和 F s r F_s^r Fsr,除此之外还对左特征图 F l F^l Fl做转换操作(就是做一个256通道的1*1的卷积操作)得到转换的特征图 F t l F_t^l Ftl。将 F c F_c Fc, F s l F_s^l Fsl和 F t l F_t^l Ftl级联起来即得到了嵌入语义的特征图,送入一个编码解码结构,再经视差回归得到视差图。根据视差图对右语义特征图 F s r F_s^r Fsr做Warp操作可以得到重构的左语义特征图 F s l ~ \tilde{F_s^l} Fsl~,将其与真实的语义分割图相比较,计算L1范式得到分割损失项 L s e g L_{seg} Lseg。对于无监督学习模式,根据视差图和右图原图可计算光度损失 L p L_p Lp,即经Warp操作得到重构的左图与左图原图之间的L1损失,对于有监督学习模式,则直接计算预测视差图与真实视差图之间的L1损失作为视差回归损失 L r L_r Lr。为了保证视差图平滑,作者还引入了平滑损失项 L s L_s Ls,对三种损失赋予相应的权重并相加得到最终的损失函数。
创新点
- 提出了对特征图进行转换操作
- 将语义特征信息整合到视差计算流程中
- 设计了带有平滑项的损失函数,利用光度损失进行无监督学习,利用视差回归损失进行有监督学习,并结合了语义分割损失
结论
该文章将语义分割与视差估计结合在一起,利用语义信息来改善视差估计效果,实验结果表明该方法很有效。但该网络需要用带有语义分割真实标签的数据集对语义分割网络进行训练。模型中提出的对特征图进行转换的思想和视差平滑损失的思想都是很新颖的做法,可以尝试应用。
31.《Learning to Refine Object Segments》
发表时间:2016年3月29日
网络名称:SharpMask
论文来源:ECCV2016
主体思想
该篇文章是关于语义分割和目标检测的,过程中采用一种Refine结构来恢复图像分辨率,并将高层次的语义特征与低层次的形状特征结合起来。在分割领域中一个重要的网络结构DeepMask,采用了常见的编码解码结构,通过不断的卷积,特征图的尺寸(分辨率)越来越低,但特征图的数量不断增加,特征表征也更加抽象,然后利用反卷积或上采样,逐层恢复图像尺寸。这种做法在恢复分辨率的过程中会丢失掉低层次的形状和位置信息,为了解决这个问题,作者提出一种Refine结构并将其堆叠起来,直至恢复到原图像尺寸。对于第 i i i级特征图集合 F i F^i Fi,其特征图数量为 f f f,首先利用33的卷积层将其压缩为特征图数目为 s s s的 S i S^i Si,再将他与上一级Refine结构生成的 M i M^i Mi级联起来,再经过33的卷积层和上采样层(放大两倍)得到该层的输出 M i + 1 M^{i+1} Mi+1,若干个Refine模块串联起来组成了一个由顶到底的结构,图像尺寸不断放大,特征图数目不断缩小,这与编码过程正好相反。对于第一层, M 1 M^1 M1是直接对 F 1 F^1 F1做1*1的卷积得到的。
创新点
- 设计了Refine结构对图像信息进行整合和补充
- 对网络中的不同结构进行了实验
结论
该文章是较早对解码过程进行研究的,对于常见的编码解码结构,在解码过程中如果简单的采用上采样或反卷积的方式无疑会丢失很多信息,ResNet采用skip连接在一定程度上改善了这个问题,但还不足够。该文章提出的方法启发我们将低层次信息和高层次信息融合在一起,以获得信息补充。
32.《Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation》
发表时间:2018年6月4日
网络名称:
论文来源:CVPR2018
主体思想
该篇文章是关于语义分割的,在ResNeXt网络的基础上进一步完善得到。与PSPNet网络利用金字塔结构从不同尺度下提取信息,再融合起来的思路不同。本文提出一种单一尺度下的,利用跳跃连接获得不同分辨率下的环境和语义信息。模型同样包括编码器和解码器,编码器参考了ResNeXt网络的结构,采用堆叠的残差块的方式来整合信息。解码器则采用新型的结构,用于获取环境信息,生成语义特征并融合不同分辨率下的信息。编码器同样由4个解码块构成,解码块包含三个部分:编码调整部分,融合部分和语义特征生成部分。编码调整部分用于将对应编码器得到的特征进行维度调整,使其适用于融合部分于语义特征生成部分。融合部分是将来自上一级解码器的信息和来自编码器的信息融合起来,与众不同的是本文提出的结构还将前面几级解码器的输出通过上采样提高分辨率之后融合在一起,比如第二级的解码器,不只融合了第三级解码器输出的特征图和第二级编码器输出的特征图,还利用跳跃连接融合了来自第四级解码器的输出。语义特征生成部分,首先有5个卷积池化块(33卷积层和55的最大池化层)串联起来,每一层输出的特征图经过一个卷积层降低维度后再级联在一起构成一个特征卷,然后经过四个堆叠的残差块结构输出语义特征图。本文提出的网络包含短跳跃连接和长跳跃连接,其中短跳跃连接是指在残差块中,将输入信号和输出信号连接起来,长跳跃连接则是将来自更深层但更粗糙的语义信息和来自浅层但精细的外观信息结合起来。
创新点
- 重新设计了编码解码结构,利用跳跃连接融合不同分辨率下的语义信息,使得解码器能够通过来自前面几级的解码器的信息来修正潜在的误差
- 设计了语义特征生成结构
结论
该文章进一步的对ResNet网络进行完善,指出金字塔结构使得预算量大幅增加,而本文是在单一尺度下,通过融合不同分辨率下的信息来获得更好的语义分割效果。该文章提到批规范化(BN)能够为网络引入额外的非线性信息,较大的批尺寸配合适当的训练策略可以提高网络的准确性,但对于批尺寸较小的训练方法,BN作用有限。
33.《MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features》
发表时间:2018年6月4日
网络名称:MaskLab
论文来源:CVPR2018
主体思想
该篇文章是关于实例分割的,与语义分割不同,实例分割其实是将目标识别与语义分割结合起来,不仅需要将不同的物体划分出来,还要识别出他是属于什么物体。本文提出的网络是在Fast-RCNN的目标识别网络基础上,结合了语义分割和方向预测两部分构成的。首先利用目标识别网络,框选出感兴趣的区域,然后语义分割网络将属于不同语义类别的物体划分出来,方向预测则是估算出每个像素点相对于中心点的方向。不仅如此作者还探究了空洞卷积和超级柱(hypercolumn)等技术影响。
创新点
- 将目标识别,语义分割和方向预测融合起来构成一个全新的实例分割网络
- 引入了超级柱技术
结论
该文章将多个视觉任务有机的结合在一起,实现了较好的分割效果。其中提到的方向预测网络和超级柱技术都是之前未曾接触的全新概念,但暂时没有找到很好的与立体匹配任务的结合点。对于这两个技术的介绍也不太详细,需要进一步的了解。
34.《Deep Residual Learning for Image Recognition》
发表时间:2015年12月10日
网络名称:ResNet
论文来源:CVPR2016
主体思想
该篇文章首先提出一个奇怪的现象,在图像识别领域中,随着网络层数的增加,识别准确率并没有上升,反而出现了下降,这并不是由于过拟合导致的,也没有出现梯度消散现象。为了解决这个问题,本文提出了残差学习的概念,如果普通的处理过程定义为 H ( x ) H(x) H(x),输入为 x x x,则残差学习则是对 F ( x ) = H ( x ) − x F(x)=H(x)-x F(x)=H(x)−x进行学习,再用跳跃连接将输入 x x x和输出 F ( x ) F(x) F(x)相加则得到 H ( x ) H(x) H(x)。训练残差特征的过程要比直接训练原始特征要更加容易。对于一般的残差学习输入 x x x和输出 F ( x ) F(x) F(x)的维度是相同的,因此可以直接对应通道相加。作者还提出如果维度发生改变,可在跳跃连接过程中增加一个线性映射过程 W s W_s Ws,使得 W s ( x ) W_s(x) Ws(x)与 F ( x ) F(x) F(x)具有相同的维度,后经实验发现该方法对准确率提升效果有限,且会增加参数和计算量,因此并未采用。作者提出两种残差块结构,对于层数较少的网络,可以采用第一种结构,其包括两个33卷积层,两个卷积层之间有ReLU层,跳跃连接将输入与输出相加在一起。如果网络层数较大,为了减少参数数量,采用了瓶颈结构,输入首先经过一个11的卷积层降低维数,再经过33的卷积,最后经过11的卷积恢复维度,输出结果,每两个卷积层之间都包含一个ReLu层增加网络的非线性,同样的跳跃连接也将输入与输出相加起来作为最终的结果。若干个残差块堆叠起来构成了ResNet网络,每隔几个残差块就会利用步长为2的卷积层对特征图进行下采样,同时将通道数增加一倍。最后经过一个全局最大池化层和softmax层得到分类结果。
创新点
- 首次提出了残差学习的概念,并设计了相应的残差块结构
- 解决了深层网络学习能力下降的问题,对不同的残差结构进行试验
结论
该篇文章是图像识别领域的里程碑式的作品,并且在机器视觉其他领域中都产生了深远的影响。随着网络层数的增加,参数数目没有增长,学习效果却不断改善,因此是十分重要的一种网络结构。现在许多网络都在ResNet结构上进行优化和改善,得到很好的结果。
35.《Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation 》
发表时间:2018年9月14日
网络名称:TRL
论文来源:ECCV2018
主体思想
该文章将单目深度估计与语义分割任务结合,两个任务相互促进。该网络的主体架构也是基于ResNet的,首先对于一幅RGB图像,经过一个卷积层后,进入由四个残差块构成的ResNet的编码器,然后进入解码器,解码器采用了任务递归的学习方式(Task-recursive Learning,TRL),简单来讲就是深度估计任务和语义分割任务交替进行,两者相互作用,共同改善效果。解码器由上采样块和任务注意力模块(Task Attention Module,TAM)构成,编码器输出的特征图经过上采样块扩大一倍尺寸,进入带有瓶颈结构的残差块Res-d1中,进行深度估计的学习,将输出与输入级联起来,再输入到相同的残差块Res-d2中,进行语义分割的学习。将Res-d1的输出和Res-d2的输出经上采样块后,送入TAM。在TAM中,两组输入的特征图首先进入平衡单元,将两种特征信息按比例结合起来,然后进入一系列卷积层和反卷积层,这一机制是为了获得不同空间尺度下的注意力,最后经过Sigmoid层得到注意力图M,深度估计的特征图 f d f_d fd和语义分割的特征图 f s f_s fs分别乘以 ( 1 + M ) (1+M) (1+M)得到带有门限的深度估计的特征图 f d g f_d^g fdg和语义分割的特征图 f s g f_s^g fsg,两者级联起来再送入Res-d3中,按照由粗到精的方式,不断重复这个过程,直至恢复到原始尺寸的1/2。过程当中为了获得高分辨率的细节信息,将对应尺寸编码器的输出一同输入到解码器中,算是一种跳跃连接。上采样块并不是简单的双边上采样,而是先用不同大小的卷积核分别对输入进行卷积,级联起来后,再采用亚像素操作(sub-pixel operation)得到上采样的结果。损失函数,深度估计采用Huber损失,该损失函数可以在深度区别很小的地方获得比较明显的梯度,有助于网络的训练;语义分割采用交叉熵损失函数。最后将两者按照一定比例结合起来,其比例系数也是需要学习的参数。用该损失函数,对整个流程进行监督,每个Res-dx块输出的特征图经过一个卷积层后,即得到该尺寸下的深度估计图或语义分割图。
创新点
- 采用了任务递归的学习方式,将深度估计和语义分割任务结合起来,两者之间相互作用,相互促进
- 设计了TAM结构,有效的将两个任务得到的特征图结合起来,对于两者共有的特征(如边缘,布局等)会给予更多的关注,这也能够用于其他的多任务结合的网络中
- 采用了新的上采样块,比传统的反卷积或双边上采样的方法效果更好
- 引入了Huber损失函数对深度估计进行监督,并利用可学习的参数将两个损失函数结合起来
总结
该网络有效的将深度估计和语义分割任务结合起来,两者相互作用,共同提高,使得两个任务的结果都有很明显的改善,多任务之间的结合,或许将成为未来研究的热点问题。其中提出的TAM结构,上采样块结构和Huber损失函数都是新的方法,并且很容易可以运用到自己的网络中。
36.《Depth Estimation via Affinity Learned with Convolutional Spatial Propagation Network》
发表时间:2018年9月14日
网络名称:CSPN
论文来源:ECCV2018
主体思想
该文章是有关单目视觉深度估计的,有两个核心点:一是利用输入的图像特征改善深度图的效果,保留边缘信息和图像结构;二是利用稀疏的深度采样点改善稠密深度图的效果,因为利用激光雷达可以获得离散的深度信息与摄像头结合可以获得稠密深度图,这一研究具有实际应用意义。如何改善深度图的效果呢?作者提出了卷积空间传播网络的思路(Convolutional Spatial Propagation Network,CSPN),这是受到SPN的启发,根据相似性矩阵对深度图进行精细化处理。SPN是按照从左到右,从上到下的方式对整张图片进行全局更新,这样做无疑会增加很多的计算量,而对于深度图的精细化只需要局部的环境信息,因此本文是对局部区域内,一个点周围的八个方向进行多次迭代更新,这样可以大大提高计算速度。首先,利用现有的网络得到初始的深度图,本文采用的是UNet,本质上也是带有跳跃连接的ResNet,在解码器恢复图像尺寸的过程中,利用跳跃连接补充细节信息,根据试验跳跃连接到Relu层之后的效果最好。然后,利用原始图片计算得到八个方向上的相似性矩阵,SPN中是使用一个深度卷积网络得到的,本文中直接利用现有的UNet网络输出8个相似性矩阵,这可以简化网络结构。最后将初始深度图,稀疏的深度信息图和相似性矩阵一起输入到CSPN网络中,输出得到精细化的深度图。
创新点
- 将SPN中按照行列进行全局传播的方式优化为八个方向的局部传播,降低了计算复杂度,使得计算时间与图像的大小无关,只与卷积核的尺寸和迭代次数有关;
- 引入稀疏深度信息,利用离散的精确的深度点提高深度图的准确性;
- 利用同一个网络,即得到初始深度图又得到相似性矩阵;
- 探索了跳跃连接位置对深度估计效果的影响
总结
空间传播网络是改善众多视觉任务效果的重要技术,在图像分割,目标检测和深度估计方面都有应用,KITTI中排名最高的算法可能也采用了这个技术,因此十分具有开发潜力。它能够利用相似性矩阵,改善所得图像中物体的边缘,结构等细节信息,其思想与置信传播的概念有点接近,不过借助卷积操作可以大大提高计算速度,因此得到广泛关注。
37.《StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction 》
发表时间:2018年9月14日
网络名称:StereoNet
论文来源:ECCV2018
主体思想
本文是利用深度卷积神经网络实现立体匹配,其特点是处理速度快,能实现60fps的实时处理,并且准确率也差强人意。其网络结构也十分简单,首先是特征提取网络,由3到4个通道数为32,卷积核大小为55,步长为2的下采样层和6个残差块构成,左右网络共享权重,输出32幅下采样到1/16或1/8的特征图,这样做的好处有:扩大了感受野的范围,对于弱纹理区域有帮助;使得特征向量更紧密,减少计算量。然后,得到匹配代价卷,利用三个堆叠的3D卷积和视差回归得到初始视差图,此时视差图尺寸为原图的1/16或1/8。最后,利用分层的精细化处理对初始视差图进行上采样,对原始视差图进行双边上采样恢复到原始尺寸,再和原图级联起来,经过一个32通道,33的卷积层,再送入6个卷积核大小为33 的残差块,残差块采用空洞卷积,空洞参数分别是1,2,4,8,1,1;在经过33的卷积输出一个残差图,将残差图与原始视差图(恢复尺寸后)相叠加,对叠加结果用ReLU进行激活,去除负数部分。重复该精细化过程,可以逐步恢复图像的细节信息,提高准确率。损失函数采用改进的L1损失函数。
创新点
- 对原图进行大幅度的下采样,再进行特征提取和3D卷积,可在保留关键信息的同时,大幅度减少计算量,提高处理速度,以实现在移动平台的应用
- 采用分层迭代的精细化处理,以原图作为向导图,逐步提高精度。
总结
该篇文章在准确率上的表现并不佳,KITTI2015仅排名87,但其目标是实现在移动端的实时应用,因此重点在于如何减少计算量,提高处理时间。其提出大部分的时间和计算量都花费在了高分辨率的匹配过程中,但大部分的效果却来自于低分辨率的匹配过程,因此采用低分辨率的匹配方法,再利用分层精细化的方式优化视差图,取得了不错的实验效果,其处理速度为60fps,基本满足实时要求。
38.《Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation 》
发表时间:2018年9月14日
网络名称:DispNet-CSS-ft
论文来源:ECCV2018
主体思想
本文是遮挡检测,动作和深度边缘检测与视差估计,光流估计和场景流估计结合起来。作者是在FlowNet2.0的基础上,增加了对于遮挡区域和动作与深度边缘的学习,这能够提高视差估计和光流估计的效果。作者设计了三种网络,第一个网络:左右(对于光流估计则是连续的两帧图像)图像首先经过correlation层,进入FlowNetC网络,输出视差图和遮挡区域图,再将其和左图、右图和经Wrap操作得到的左图级联起来,输入到FlowNetS网络,进行残差学习,将输出结果与输入相加,再次输入一个FlowNetS网络,这次输出的是视差图,遮挡区域图和边缘分布图,最后将其级联后输入到精细化网络中,得到最终的结果。第二种网络则是考虑了左右图(1、2帧)之间在遮挡区域的不连续性,因此对左右图(1、2帧)的视差和遮挡区域都进行学习,再级联起来送入下级网络,后面同样经历两个FlowNetS网络和一个精细化网络。第三种网络,则是将左右图(1、2帧)学习分开,分成两个平行的网络去学习,然后利用Wrap操作,由左图得到合成的右图,从右图得到合成的左图,再分别级联起来送入后面的网络。最后作者将光流估计网络和视差估计网络结合起来构成场景流估计网络。训练过程中是对逐级进行训练的,先训练第一级,然后固定参数,再训练下一级,因为需要对视差(光流)估计,遮挡区域检测和动作与深度边缘检测同时学习,因此要求数据集包含三个真实值(GroundTruth)。视差(光流)估计损失函数采用EPE损失,遮挡区域检测和动作与深度边缘检测采用交叉熵损失函数,将不同的学习任务的损失乘以平衡系数再相加得到最终的损失函数。
创新点
- 将视差估计(光流估计)与遮挡区域检测和动作与深度边缘检测相结合,其可以相互促进提高学习效果
- 设计了三种网络,探究了左右图(1、2帧)之间的相关性对于遮挡区域检测的影响
总结
本文采用堆叠的FlowNet网络,对残差进行学习;将其与遮挡区域检测和动作与深度边缘检测相结合,改善了学习的效果。根据作者的实验结果,第一种网络的效果最好,挡区域检测和动作与深度边缘检测的学习对于视差估计有帮助作用,但左右图
(1、2帧)之间的相关性对于遮挡区域的检测作用不明显。该网络有效的改善了遮挡区域检测和动作与深度边缘检测的效果,甚至将其应用到动作分割任务中,仍取得了优异的表现。
39.《DenseASPP for Semantic Segmentation in Street Scenes》
发表时间:2018年6月21日
网络名称:DenseASPP
论文来源:CVPR2018
主体思想
本文采用级联的空洞卷积来解决接到场景中尺寸变化较大的物体的语义分割问题。空洞卷积可以在不增加参数数量的条件下,扩大感受野的范围,而将不同扩张率(空洞率)的空洞卷积层级联起来能够进一步的获得更大的感受野,并且能够获得更多像素点信息。首先对于输入的图像进行初步卷积,提取特征图,缩小图像尺寸;然后进入DenseASPP模块,空洞卷积层按照级联的方式组合,层级越低,扩张率越小(例如第一个空洞卷积层,扩张率为3,最后一个空洞卷积层,扩张率为24),经过一个空洞卷积之后,将输出和输入的原始特征图和之前其它空洞卷积层的输出级联起来,送入下一个空洞卷积层;为了防止通道数过多,在每个空洞卷积层之前,都有一个1*1的卷积层,将通道数减少到输入的1/2;最后将各个空洞卷积层的输出和原始输入的特征图级联起来,再经过若干卷积层输出分割结果。采用交叉熵损失函数。
创新点
- 利用级联不同扩张率的空洞卷积,获得了更加稠密的不同尺度下的特征信息
- 在参数数目没有较大增长的条件下,获得更大的感受野和更加密集的图像信息
总结
本文是在DenseNet的基础上,增加了级联的空洞卷积结构,与ASPP利用不同扩张率的空洞卷积按照平行的方式分别对特征图进行卷积的方法不同,本文利用跳跃连接的方式,将不同扩张率的空洞卷积连接起来,这样能够获得更加稠密的特征金字塔和更加广阔的感受野。
40.《Parallel Feature Pyramid Network for Object Detection》
发表时间:2018年9月14日
网络名称:DenseASPP
论文来源:ECCV2018
主体思想
本文利用一种平行特征金字塔结构实现目标检测任务,与其他网络增加深度的方式不同,该网络选择增加网络的宽度,来改善检测效果。首先,图像经过一个基础网络(VGG-16)提取特征,利用空间金字塔池化将特征图下采样到不同的尺寸;然后利用带有bottleneck结构卷积层对各个尺寸的特征图进一步提取特征,并压缩通道数;将不同尺寸下的特征图送入多尺度环境信息聚合模块(MSCA),聚合不同尺度下的特征信息并输出对应尺度的特征图,将不同尺度下的特征图送入SubNetwork得到最终的目标检测结果。与其他利用SPP结构的网络,直接将不同尺度的特征图上采样的到统一尺寸并级联起来的方式略有不同,该网络利用MSCA结构聚合了不同尺度下的特征图,例如对于尺寸为1/2H1/2W的特征图,将其未经bottleneck结构压缩的特征图和经过压缩的尺寸为HW、1/4H1/4W一起输入到MSCA结构中,将HW尺寸的特征图利用自适应池化下采样到1/2H1/2W,将1/4H1/4W尺寸的特诊图利用双边上采样器放大到1/2H1/2W,再将其与未经压缩的尺寸为1/2H1/2W的特征图级联起来,在经过一系列的卷积层,进一步精细化和聚合不同尺度下的特征信息得到1/2H*1/2W尺寸下的特征图。其他尺度的特征图也做类似的操作,最终得到不同尺度下的特征图。
创新点
- 利用SPP结构生成金字塔形状的特征图,用于增加网络的宽度,而不是增加网络的深度,这有利于提高网络的计算速度
- 利用MSCA模块聚合了不同尺度下的环境特征信息
总结
本文利用了空间金字塔池化结构,但却不是直接的将不同尺寸下的特征图级联起来,而是利用MSCA模块将特征信息聚合起来,当前尺寸的特征图提供基础信息,而其他尺寸下的特征图则提供补充信息,通过增加网络的宽度,而代替增加网络深度提高了网络的计算速度。
41.《Densely Connected Convolutional Networks》
网络名称:DenseNet
论文来源:CVPR2017
主体思想
本文提出一种稠密连接的卷积网络,将每个卷积层的输出和在此之前其它卷积层的输出都级联起来输入到下一个卷积层中,若干卷积层构成一个稠密卷积块,若干稠密卷积块构成一个稠密卷积网络DenseNet。该网络消除了梯度消散问题,增强了特征传播,鼓励特征复用,从根本上减少了参数数目。首先,与ResNet网络一样,图像经过一个77的步长为2的卷积层和33的步长为2的最大池化层,将尺寸压缩到原尺寸的1/4;然后进入第一个稠密卷积块中,稠密卷积块是由若干个卷积组构成的,此处的卷积组包含一个BN层,一个ReLU层和一个33的卷积层,每个卷积组的输出有 k k k个通道,对于第 l l l个卷积组,其输入是由前 ( l − 1 ) (l-1) (l−1)个卷积组的输出和最初的输入级联起来构成的,由于在过程中输入通道数会逐步增加,为了防止通道数过多,在每个卷积组之间增加了瓶颈层(bottleneck layer),瓶颈层是由BN层,ReLU层和11的卷积层构成的,其输出通道固定为 4 k 4k 4k。整个网络是由3-4个稠密卷积块构成的,为了控制参数数目,压缩图像尺寸,在各个稠密卷积块之间增加了过渡层(transition layer),过渡层是由BN层,11的卷积层和22,步长为2的平均池化层构成,完成了对图像的下采样,过渡层还需要压缩特征图的通道数,压缩比例通常为0.5,即输出的通道数为输入的1/2。最后经过7*7的全局平均池化和softmax层输出分类结果。
创新点
- 通过稠密连接将最终的输出和前面各级输出联系起来,使得梯度可以直接传播到输入层,消除了梯度消散问题,有利于网络的训练
- 利用瓶颈层和过渡层,即减少了参数数目,又压缩了特征
结论
本文是在ResNet之后又一个突破性的网络结构,其在ResNet的基础上引入了稠密连接的方法,并且将ResNet将输入和输出相加的方式改为级联起来,实现了特征图的复用。根据实验结果,其比较ResNet又有较大的突破,在同等分类效果下,参数数目仅为ResNet的1/3,通过调整网络参数,最佳网络效果在各个数据集上均超过了ResNet和其对应的变种。
42.《RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation》
网络名称:RefineNet
论文来源:CVPR2017
主体思想
该文章解决了高分辨率的语义分割问题。当前众多的网络都是基于ResNet结构的,但ResNet结构随着卷积层加深,图像的尺寸也不断缩小,通常每经过一个残差块,尺寸缩小一倍,通道数增加一倍,这对于目标识别这种分类任务是没问题的,但是对于语义分割,深度估计这类视觉任务,需要原尺寸的输出,需要恢复图像的分辨率。现在有两种解决方案,一种是利用反卷积或双边上采样恢复图像尺寸,但由低分辨率图像恢复得到高分辨率图像时,已经丢失的细节信息不能得到补充;另一种方法是利用空洞卷积代替ResNet中的卷积层,过程中无需进行下采样,也可以得到更大感受野,利用这种方法图像经过ResNet并不会缩小尺寸,但导致计算量过大。本文采用的第一种方案,但在恢复尺寸的过程中,利用RefineNet模块,获取不同尺度下的信息,以补充丢失的细节信息。网络的主体部分是预训练的ResNet,经过四个残差块得到原尺寸1/32的特征图,然后经过四个RefineNet模块由下至上逐级恢复分辨率,最后得到原尺寸1/4的特征图。除了最下层的RefineNet4模块只有一个输入,即来自残差块ResNet4的输出,其他的RefineNet模块均有两个输入,一个是来自上一个RefineNet模块的输出,一个是对应层级ResNet模块的输出,例如RefineNet3模块,其输入为RefineNet4的输出和ResNet3的输出。
下面简述RefineNet的结构,其由三部分构成自适应卷积层(Adaptive Conv)、多分辨率融合(Mutli-resolution Fusion)和链式残差池化(Chained Residual Pooling)。自适应卷积层是由两个RCU(Residual Convolution Unit)模块构成的,RCU即是一种简化的残差块,与普通的残差块相比,去除了BN层。其结构为一个ReLU层和一个33的卷积层,再一个ReLU层和一个33的卷积层,最后利用跳跃连接将输入和输出相加。其作用是将预训练的ResNet的权重微调到符合我们的任务需要。输入的不同尺寸的图像(一般为两种尺寸)经过自适应卷积层输出通道数为256的特征图,进入多分辨率融合模块,现经过一个33的卷积层,然后上采样到同一尺寸,其尺寸即为输入图像的最大尺寸,例如输入是1/32和1/16的两种尺寸的图像,则均上采样到1/16,再将两组图像相加起来。其作用是将不同分辨率的输入融合为高分辨率的输出。最后进入链式残差池化层,用于获得大尺寸的背景环境信息。由多分辨率融合层得到的特征图首先经过一个ReLU激活层,以增加特征图的非线性,然后进入一个池化块,池化块由55的最大池化层和一个3*3的卷积层构成,输出分成两个方向,一个是与输入相加,为了一种跳跃连接,另一个输入到下一个池化块中,将每个池化块(通常为两个)的输出都相加起来,再经过一个RCU模块即得到了RefineNet的输出。池化层的步长为1,因此在池化过程中不会改变图像尺寸。经过四个RefineNet模块得到原尺寸1/4的特征图,再经过softmax层得到最终的预测结果,可再进行上采样恢复到原始尺寸。
创新点
- 提出了RefineNet结构,在恢复图像分辨率的过程中,融合了低分辨率下的语义信息和高分辨率下的细节信息
- 在RefineNet结构中充分利用跳跃连接,使得误差在反向传播过程中可以很直接地作用在较低的层级中,这有利于深层网络的训练
总结
该网络还是利用了ResNet强大的特征提取能力,为了能够还原得到高质量的高分辨率图像,在恢复分辨率的过程中融合了多分辨率的信息。作者在文章中多次强调了残差连接,或者说跳跃连接的作用,将残差连接分为长范围残差连接(指ResNet和RefineNet之间的连接)和短范围残差连接(指RefineNet内部RCU模块和链式残差池化模块中的残差连接),在前向运算过程中,残差连接用带有细节信息的低层级特征图去优化低分辨率的高层级特征图;在反向传播过程中,残差连接使得梯度可以直接传播到低层级特征图上,消除了梯度消散问题,有助于网络的高效训练。
43.《Learning Depth with Convolutional Spatial Propagation Network》
发表时间:2018年10月4日
网络名称:M2S_CSPN
论文来源:
主体思想
该文章与《Depth Estimation via Affinity Learned with Convolutional Spatial Propagation Network》是同一个作者,其将CSPN从单目深度估计扩展到了双目的立体匹配领域。其网络是基于PSMNet的,主要做了以下几个方面的改进:一、构建了3DCSPN,在CSPN的基础上,增加了一个维度,使其能够对三维的张量进行处理。在PSMNet中,对构建的四维的匹配代价卷(DHWC)进行3D卷积,得到各个视差下的匹配代价,再利用回归的方法得到最终的视差图。本文利用3D卷积结构获得了对应的相似性矩阵,将相似性矩阵和原本的卷积结果进行3DCSPN,得到各个视差下的匹配代价,再经过回归得到视差图。二、PSMNet利用三个沙漏型结构分别得到视差图,并通过实验手工为三个视差图分配权重,求和得到最终的输出。本文则是对三个经上采样的各个视差下的匹配代价卷分别进行卷积,得到对应的相似性矩阵,三个相似性矩阵构成三维的相似性矩阵(3HW),三个视差图构成四维的视差图矩阵(3HW1),经过3DCSPN将各个视差图融合起来,再利用Padding操作消除第一个维度,得到HW1的视差图。三、对于金字塔池化的部分利用CSPN进行改造。PSMNet中,对提取得到的特征图,直接进行池化得到多尺度的特征图,经卷积压缩维度后,再将各个尺度下的特征图经上采样后级联起来。本文在此基础上,首先对提取到的特征图,进行卷积,得到相似性矩阵,用相似性矩阵和特征图进行CSPN操作,通过修改卷积核尺寸和步长得到不同尺度下的特征图,取代了池化操作,作者称之为加权空间金字塔池化(WSPP)。在PSMNet中,是将不同尺度下的特征图上采样到统一尺寸后直接级联起来,经过卷积压缩维度后,输出特征图。与此不同的是,作者又分别用四个独立的卷积层得到四个相似性矩阵,将相似性矩阵级联起来,与级联在一起的特征图进行3DCSPN,得到最终的特征图,作者称之为加权金字塔空间融合策略(WSPF)。除此以外,作者还利用ASPP代替SPP,利用空洞卷积获取更大的感受野,取得了更好的效果。
创新点
- 在2DCSPN的基础上,提出了3DCSPN,对3D卷积得到的结果进行优化
- 用3DCSPN对视差图进行融合,取代了之前的加权求和方式
- 利用CSPN方法获得不同尺度下的特征图,取代了金字塔池化方法
- 对不同尺度下得到的特征图,利用3DCSPN 进行融合,取代了直接级联的方式
总结
该算法在KITTI排行榜上排名第一,相较于PSMNet有明显的效果提升。核心思想在于卷积空间传播网络(CSPN)的应用,作者将其嵌入到PSMNet网络的各个层级中,使得网络效果有了极大改善,这说明CSPN方法拥有很大的开发潜力,其具有很强通用性,可用于其他网络的改进,甚至是应用于其他的视觉任务中。
44.《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》
发表时间:2018年2月7日
网络名称:DeepLabv3+
核心思想
本文是在DeepLabv3网络的基础上进行改进,用于解决语义分割问题。作者指出空间金字塔池化能够获取多尺度下的环境信息,而编码解码结构能够通过逐渐还原空间信息获得更明确的物体边缘结构,因此作者将两者的优势结合起来,以DeepLabv3网络作为编码器,在此基础上增加一个简单却有效的解码器来优化语义分割结果。DeepLabv3中利用ASPP结构通过修改空洞卷积的扩张比率来得到不同尺度的特征图,再将其级联起来通过1*1的卷积层得到编码结果。解码器部分,首先对编码结果进行双边上采样放大4倍,再与编码器中对应尺寸的低层级特征图级联起来,在级联之前,低层级的特征图要先经过1 * 1的卷积层,这是因为低层级的特征图通道数较多,超过了编码器的输出结果,使得训练更加困难,级联的特征图经过3 * 3的卷积之后,再进行上采样恢复原尺寸。上述编码器是基于ResNet-101结构的,作者又对Xception网络进行改进作为编码器,改进有三点:1.加深网络层数;2.所有的最大池化操作均由带有特定步长的深度分离卷积操作代替;3.在卷积操作之后,增加BN和ReLU层。
深度分离卷积,是将一个标准的卷积分解成一个depthwise卷积和pointwise卷积,例如一个16通道的特征图经过一个输出通道为32的卷积层,参数个数为16 * 32 * 3 * 3 = 4608,若是深度分离卷积,则分解为先经过一个3 * 3的16通道卷积层提取深度信息,再用32个1 * 1的卷积核遍历16个特征图得到32个输出特征图,参数个数为16 * 3 * 3 + 32 * 16 * 1 * 1 = 656个参数,这大大减少了参数数量。
创新点
- 采用编码解码结构,以DeepLabv3作为编码器,利用空洞卷积获得不同分辨率的特征图,再采用简单却有效解码器,恢复空间信息。
- 改进Xception网络,将深度分离卷积应用到ASPP模块和解码器中,获得速度更快,表征能力更强的编码解码网络
- 深度分离卷积与ASPP的结合可以通过调整扩散率得到各种分辨率的特征图
总结
该网络是Google团队在DeepLabv3的基础上做了进一步的改进,利用一个简单却有效的解码器,恢复图像尺寸的同时保留了物体边缘信息。作者还引入了深度分离卷积,将其应用于ASPP结构和编码解码器中,提高计算速度,减少参数数目。应用改进的Xception网络作为编码器,取得更好的分割效果。
45.《Xception: Deep Learning with Depthwise Separable Convolutions》
发表时间:2017年4月4日
网络名称:Xception
核心思想
本文提出一种新型的网络结构,是将Inception V3网络中的Inception模块替换成深度分离卷积模块。作者指出传统的卷积操作是将空间维度和通道维度混合在一起的,用一个卷积核融合了空间上的联系(一张特征图上不同像素点的信息,通过卷积操作聚集在一起)和通道上的联系(各个特征图之间的信息,通过累加求和聚集在一起)。Inception则是将其分解为一系列操作,分别独立的聚集空间信息和通道信息,使得该过程更加简单有效。具体来说Inception是利用1 * 1的卷积将输入的通道分成3~4个较小的通道,再用3 * 3的卷积层分别获取各个通道上的空间信息,最后将其级联在一起。而Xception则是一种极端的Inception结构,对输入的每一个通道都做独立的空间卷积(例如输入通道数为16,则用16个3 * 3的卷积核分别对其卷积,输出通道也为16,各通道之间相互独立,没有累加求和的过程),再用1 * 1的卷积核分别对16个通道特征图做卷积,将各通道信息映射到一个新的通道空间中(例如输出通道为32,对于每一个通道都有维度为16 * 1 * 1的卷积核对输入的16个通道卷积,并将16个通道的卷积结果累加求和得到一个输出,32个卷积核则得到32个通道的输出)。Xception结构与Inception结构存在以下不同点:1.Inception是先对输入通道做1 * 1的卷积,而Xception是后做1 * 1的卷积;2.Inception在卷积操作之后都跟随有ReLU的非线性激活层,而Xception的卷积操作后并没有。 Xception的网络结构分为三个部分,输入部分,中间部分和输出部分。输入部分,先经过初步卷积得到64个通道的特征图,然后进入3个级联的Xception模块,每个Xception模块均由两个深度分离卷积层和一个最大池化层构成,深度分离卷积层之间有ReLU激活层,最大池化层的步长为2,因此图像尺寸会缩小一倍,带有类似残差块的跳跃连接,将输入经过1 * 1的步长为2的卷积层后与输出累加起来。中间部分,则是由8个Xception模块构成,与输入部分的Xception模块不同,最大池化层由一个深度分离卷积层代替。输出部分则是由一个Xception模块和两个深度分离卷积层和一个全局平均池化层构成,得到2048个输出向量,由于该网络用于分类任务,因此后面还有全连接层和逻辑回归层,得到各个分类的概率情况。根据实验结果,Xception网络与Inception网络相比,网络参数相同但分类效果有一定提高,尤其在JFT数据集上效果提升明显。
创新点
- 将深度分离卷积代替Inception结构,独立地获得空间维度和通道维度信息
- 提出新型的Xception网络,有效的提升了图像分类任务的结果
总结
该网络是Google团队在InceptionV3的基础上引入深度分离卷积结构的改进,其核心在于将卷积过程中的空间信息和通道信息分解成两个步骤,使其能够更快更有效的获取信息。无论是Inception还是Xception,其都是基于将通道联系和空间联系解耦开效果要比结合起来更好这一假设。由试验结果来看,其效果是优于同等深度的ResNet网络的,但论文中提到该网络在60块K80GPU上训练时间超过了1个月,说明该深度网络训练难度较大。
46.《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》
发表时间:2017年5月12日
网络名称:DeepLab v2
核心思想
本文介绍了用于语义分割的DeepLab v2网络,该网络针对普通DCNN网络存在的三个问题,分别进行改善,进而提高了分割效果。问题一:卷积操作和池化操作会降低特征图的分辨率;对此作者引入了空洞卷积来代替普通的卷积+池化的组合,空洞卷积能够有效的扩大感受野以聚合更多的环境信息,且不会增加参数数量和计算复杂度。问题二:物体的尺寸众多;对此作者受金字塔池化思想的启发,提出了深色金字塔池化(ASPP),用不同扩张率的空洞卷积来代替不同尺寸的池化操作,以获取不同尺度下的目标信息(扩张率越大对应的感受野越大),最后将各个特征图求和。问题三:图像分类为了保持一定空间不变性使得物体边缘的准确率受限;对此,作者采用一种全连接的条件随机场(CRF)结构,对输出的分类结果进行优化,通过迭代的方式逐步精细化物体的边缘。整个网络的结构:首先图像经过一个DCNN(VGG-16或ResNet-101),其中用空洞卷积代替卷积+池化结构,过程中图像分辨率不会降低;经过卷积提取特征后,进入ASPP结构,用四个不同扩张率的空洞卷积核分别对特征图进行卷积,在经过两层1 * 1的卷积之后,将特征图相加起来;将得到的特征图输入到CRF网络中,进一步优化。
创新点
- 提出了空洞卷积的方法,有效扩大感受野范围,且不增加参数数目;
- 提出了ASPP结构,能够获取不同尺度的物体信息,并将其融合起来
- 提出全连接的CRF结构,提高分类结果的边缘定位准确率
总结
该文其率先提出了空洞卷积和ASPP的结构,对后来的网络产生极其深远的影响,两种结构在深度学习领域均得到广泛的应用。空洞卷积和ASPP结构对于扩大感受野,获取不同尺度的特征信息具有重要作用,这一点已被众多网络验证过。其团队在此基础上陆续提出多个衍生网络,效果也在逐步提升。
47.《Attention to Scale: Scale-aware Semantic Image Segmentation》
发表时间:2015年11月10日
网络名称:
核心思想
该网络提输入不同尺度的图片可以改善分割的效果,这是基于输入尺度大的图片,注意力会集中在小的物体上,输入尺度小的图片,注意力集中在大的物体上这一假设的。融合多尺度图片的方法主要有两种:一个是Skip-net的形式,将不同层级的特征图级联起来;另一个是share-net的形式,输入不同尺寸的图片,分别进行卷积操作,各个分支间权重共享,最后再将不同尺度的特征图融合起来(不同尺度的特征图在融合之前先上采样到同一尺寸),融合的方式有求平均值和求最大值。本文基于Share-net的形式,提出一种新的融合形式——注意力模型(Attention model),即加权求和。不同尺寸的图像分别经过由DeepLab构成的主体网络进行特征提取,特征图经过softmax层得到各个分类下的得分图(Score map),得分图均上采样到原图的尺寸;不同尺度的图像,分别经过一个卷积化(即把全连接层改为1 * 1的卷积层)的VGG-16模型提取特征,再共同输入到一个注意力模型得到各个尺度下的权重,注意力模型是由两层卷积构成,第一层是512个通道的3 * 3的卷积,第二层则是有S个(S表示尺度的个数,比如有三种不同的尺度,S=3)通道的1 * 1 的卷积层,然后再经过一个softmax层就得到了每个像素点上,不同尺度所占有的权重,再进入注意力模型之前,应该对各个特征图进行上采样,恢复到原图尺寸,这一点文章里没有说明。将前面得到不同尺度下的得分图和对应的权重相乘再求和即得到了最终的得分图。权重值 w i s w_i^s wis反映了在尺度 s s s的条件下,位置 i i i处的重要性。除此之外,作者还提出了对不同尺度下得到的得分图进行额外的监督,就是说最终的损失函数不仅仅计算融合后的得分图,还会对融合之前各个尺度下的得分图进行计算,作者提出这样可以得到更有区分度的特征图进行融合。
创新点
- 输入不同尺度的图像分别计算各个分类的得分图并融合起来
- 提出一种基于注意力模型的多尺度得分图融合的方法
- 对不同尺度下的得分图进行额外监督,提高各个尺度特征图的区分度
总结
该网络是较早的进行语义分割的网络,但是其提出融合多尺度信息的思想依旧是很有价值的想法,其网络直接输入了不同尺寸的图像,多个分支并行处理,这会增加运算成本,而起提出的基于注意力模型的融合方式,可以与空间金字塔池化结合起来,用于多尺度信息的融合。作者同样也注意到了额外监督的重要意义,对于过程中各个层级的结果,各个尺度的结果进行监督,能够有效的提高模型的输出准确率,这一点格外重要。
48.《ParseNet: Looking Wider To See Better》
发表时间:2015年11月19日
网络名称:ParseNet
核心思想
本文提出将全局环境信息融入到语义分割网络之中,作者认为全局环境信息对于语义分割目标识别等任务非常重要,对于语义分割来说,仅凭局部的信息对每个像素进行分类是非常模糊的,但如果能够得到来自整幅图片的全局信息,该任务就更容易了。虽然理论上随着卷积层数增加,感受野的尺寸也在不断增长,但根据作者的试验,感受野的尺寸比想象中的小很多,这也就更加说明增加全局环境信息的重要性。作者提出两种融合方式一种是提前融合(Early fusion),另一种是滞后融合(Later fusion)。提前融合的方式十分简单,首先利用全局平均池化将特征图提取为一个特征向量(每幅特征图得到一个特征值,特征向量的长度等于特征图的通道数),然后将该向量进行反池化(即重复,例如特征图的大小为256*256,而特征向量中的某个数为0.1,反池化得到三幅大小为256 * 256的全局信息图,每个像素点的数值均为0.1),再将反池化得到的全局信息图与特征图级联起来,送入卷积层或分类器中。滞后融合则是将特征图和全局信息图先分别送入分类器中,再将分类得分图融合起来,作者提到有时候单凭特征图不能识别某样东西的种类而将两者结合起来就能够识别了。除此之外,作者还发现,不同层级的特征图,其特征值的范围差别很大(低层级的特征值在120左右,而高层级的特征值小于1),如果采用简单的级联方式融合特征图则会使效果恶化,因此作者提出先对特征向量和特征图进行L2-Norm的规则化处理,并且增加一个可以进行学习的权重系数,这使得训练更加稳定,并且改善了最终的效果(其思想我感觉与Batch Normalization很相似)。其网络采用DeepLab作为主体,融合全局环境信息和多个卷积层的特征图信息,提高了分割的准确率。
创新点
- 提出利用全局平均池化的方式,从整幅图片中提取出全局环境信息,作为一组特征向量
- 提出两种融合全局环境信息的方式
- 对特征图和特征向量进行L2-Norm规则化,将特征值规范到一个范围之内
总结
该网络考虑到融合全局环境信息的重要性,其通过全局平均池化的方式得到特征向量,再通过反池化恢复到原图尺寸,再将全局环境信息和特征图级联起来,而在SENet中,是将特征向量作为权重,对特征图做加权操作,两者有着异曲同工之妙。根据作者的实验可以看出,在大部分情况下融合全局环境信息和其他层级特征图信息是对结果有一定作用的,其中L2-Norm规则化十分关键。
49.《BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation》
网络名称:BiSeNet
论文来源:ECCV 2018
核心思想
本文目标是实现实时的语义分割任务,作者提出一个层级浅但视野宽的网络,一方面提高了网络处理速度,另一方面还改善了语义分割的效果。作者指出现有的语义分割网络为了提取高层级的语义特征,需要增加网络的深度,但网络深度增加,参数数目也会急剧增加,计算量也增长,因此通常会利用卷积和池化来缩小图像的尺寸,但在下采样的过程中,损失较多的空间信息。U-Net结构虽然在一定程度上能够恢复空间细节信息,但会降低网络的计算速度,而且许多损失的信息并不能够有效的恢复。因此,U-Net只能作为一种补充,但不是一种治本的解决方式。作者提出一种双线网络,一条路线是空间路线,另一条路线是环境路线,空间路线采用三个步长为2的卷积层,保留空间信息并且得到高分辨率的特征图,环境路线则是采用一种快速的的下采样策略来获得充足的感受野,再利用一个特征融合模块,将两条路线得到的特征图融合起来,得到最终的分割结果。在环境路线中,作者采用的是Xception结构作为主体,对输入图像进行下采样,并获得较大的感受野,得到高层级的语义环境信息。环境路线共有四层,每经过一层特征图的尺寸都缩小4倍,在路线的最后是一个全局池化层,以最大感受野来获取全局的环境信息。之后类似U-Net结构,对全局池化层的输出进行上采样,恢复到原图尺寸的1/32和1/16,再与下采样过程中对应尺寸特征图融合起来,融合不是采用简单的级联,而是使用一种注意力优化模型,该模型利用全局池化得到的特征向量来引导特征的学习。最终的特征融合模块,与SENet类似,首先将两条路线得到的特征图级联起来,然后利用一个BN层来平衡特征值的范围(空间路线得到的是低层级的空间信息,环境路线得到的是高层级的语义信息),然后利用全局平均池化,得到特征图对应的特征向量,特征向量经过1 * 1的卷积和池化之后,利用sigmoid层激活,作为每个特征图的权重,最后将特征图加权求和得到输出特征图。损失函数在最终输出损失的基础上,增加了两个补充项,分别是环境路线最后两层的输出对应的损失,作为一种深度监督损失计算方法均为Softmax函数。
创新点
- 提出一种双线网络结构,一条线用于保留空间细节信息,一条线利用较大的感受野获取高层级的语义信息
- 引入了注意力优化模型,利用全局环境信息来引导特征学习
- 引入了特征融合模型,有效的将两条路线的特征图融合在一起
- 在保证分割精度的前提下,大幅度提高了网络的处理速度,实现了实时分割的要求
总结
该网络的目标是在不损失精度的前提下,尽力提高网络的计算速度,因此其并没有采用效果更好,但速度更慢的ResNet101结构,而是选择了一种“轻权重”结构Xception。另一方面其创新性的采用两条路线的方式,一方面保留丰富的空间细节信息,一方面提取充足的语义特征信息,最后利用特征融合结构将二者有机的结合起来,互为补充,保证了语义分割的效果,且网络参数少,速度快,实时性强,为实际产品级的应用奠定了基础。
50.《Pyramid Scene Parsing Network Hengshuang》
发表时间:2017年4月27日
网络名称:PSPNet
核心思想
该网络首先将SPP结构运用到语义分割领域,也是PSMNet的思想来源。与何凯明利用SPP网络来解决全连接层对于输入图像的尺寸限制问题不同,本文利用SPP结构获得不同子区域(sub-region)的全局信息。作者发现在语义分割领域存在三个主要问题:关系误匹配,类别混淆和不显著的类别。这些问题都与环境关系和不同感受野的全局信息有关,其实利用全局信息的优势,早有人做了相应的尝试,并取得了不错效果,但是通过全局平均池化,将一幅特征图压缩成一个特征值,作者指出这种方法在处理场景比较复杂的情况时,不足以覆盖必要信息。因此本文利用不同尺寸的池化窗口,分别对特征图进行池化,得到了不同感受野下的全局信息。首先,图像经过初步的卷积层提取特征图,初步卷积采用是带有空洞卷积的ResNet结构,得到特征图分别池化为1 * 1,2 * 2 , 3 *3 和6 * 6大小的特征图,再经过1 * 1的卷积压缩通道数,最后利用双边线性插值上采样到原尺寸,与初步卷积得到的特征图级联起来,经过卷积得到最终的结果。在训练过程中也采用了深度监督策略,将ResNet中某个层的结果输出出来,作为补充损失,权重为0.4。
创新点
- 利用空间金字塔结构提取不同尺度下的全局环境信息
- 采用深度监督策略
总结
该网络最早将SPP结构引入到语义分割领域,与SPPNet将得到的特征图展平为一维向量的方法不同,该网络是将不同尺度的特征图,经过上采样恢复成原尺寸,再与初始的特征图级联起来,作为不同尺度下全局环境信息的补充。该方法取得了非常好的效果,当时在众多数据集上都排名第一。
51.《SegFlow: Joint Learning for Video Object Segmentation and Optical Flow》
发表时间:2017年9月20日
网络名称:SegFlow
核心思想
该文章将视频的语义分割与光流估计结合在一起,此处的语义分割属于二元分割,即只区分前景区域和背景区域。作者提出了一种双分支网络,一个分支用于语义分割任务,另一个分支用于光流估计任务,语义分割分支采用了ResNet-101结构,光流估计分支则采用了FlowNetS结构。为了让两个任务能够互为补充,在上采样阶段,将两个分支上对应尺寸的特征图级联起来,再利用卷积层平衡特征图。因为没有一种数据集既包含语义分割的真实值,又包含光流估计的真实值,所以为了解决这一问题,作者提出了迭代训练的思路,分别在对应的数据集上依次训练两个分支,在训练语义分割时,固定光流估计分支的参数,同理,在训练光流估计分支时,也会固定语义分割分支的参数。光流估计分支采用EPE损失,语义分割分支采用加权的交叉熵损失函数。
创新点
- 提出了一种语义分割与光流估计多任务融合的网络
- 设计了一种迭代训练方法
- 证明了语义分割与光流估计两个任务可以互为补充,相互促进
总结
该文章提出了一种语义分割与光流估计相结合的网络,其思路是比较简单清晰的,将各自分支得到的特征图分别级联起来,作为一种信息的补充。网络结构也是比较传统的双分支结构,训练过程采用了迭代训练的思路,这也是目前多任务网络普遍采用的方案。在损失函数部分,他将两个任务的损失函数乘以对应的系数相加起来,但存在一个疑问,在训练过程中,对于一幅图片只能得到一种损失(或语义分割,或光流估计),并不能得到两个损失,不明白二者加权相加的目的何在。代码已经开源。
52.《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》
发表时间:2018年4月24日
网络名称:Multi-Task Learning
核心思想
该网络将语义分割,实例分割与单目深度估计结合在一起。其网络结构非常简单,整体属于编码解码结构。三个任务共用一个编码器,编码器部分是改编自DeepLabV3网络,主体为ResNet-101结构,后面增加一个ASPP模块。ResNet-101结构中的卷积层使用空洞卷积代替,ASPP模块是由4个扩张率分别为1,12,24,36的卷积分支构成的,卷积核大小分别为1 * 1,3 * 3,3 * 3,3 * 3,通道数均为256。此外,利用全局平均池化将ResNet-101输出的特征图压缩为长度为256的特征向量。最后将ASPP模块4个分支的输出和特征向量(通过复制放大到相同尺寸)级联起来得到通道数为1280的特征图。
解码器部分分成三个分支,分别对应三个任务,其结构是相似的,但参数各自独立。解码器一共只有两层,第一层是卷积核为1*1,通道数为256的卷积层,后面带有批规则化层(BN)和激活层;第二层则是将通道数压缩到对应任务所需数目,对于语义分割任务,通道数与物体类别数相同,对于深度估计任务,通道数为1,对于实例分割任务,通道数为2。最后,利用双边上采样,恢复图像尺寸,即得到对应的输出结果
该网络采用了共用的编码器部分,该编码器能够为三个任务学习到有效的特征表征。但网络的核心在于设计了一个多任务的损失函数,利用该损失函数能够对多个任务同时进行训练。与普通的多任务网络采用线性方式聚合多任务损失的方法不同,该文提出了根据方差不确定性(Homoscedastic Uncertainty)来计算不同损失权重的思路。总的损失函数计算方法如下:
L
(
W
,
σ
1
,
σ
2
)
=
1
2
σ
1
2
L
1
(
W
)
+
1
σ
2
2
L
2
(
W
)
+
l
o
g
(
σ
1
)
+
l
o
g
(
σ
2
)
L(W,σ_1,σ_2 )=\frac{1}{2σ_1^2 } L_1 (W)+\frac{1}{σ_2^2 } L_2 (W)+log(σ_1)+log(σ_2)
L(W,σ1,σ2)=2σ121L1(W)+σ221L2(W)+log(σ1)+log(σ2)
L
1
L_1
L1表示连续型输出的损失函数,
L
2
L_2
L2表示离散型输出的损失函数,
σ
1
,
σ
2
σ_1,σ_2
σ1,σ2则作为一个权重参数,当
σ
1
,
σ
2
σ_1,σ_2
σ1,σ2越大,则对应损失
L
1
,
L
2
L_1,L_2
L1,L2权重越小,为了防止
σ
1
,
σ
2
σ_1,σ_2
σ1,σ2过大,增加了一个平衡项
(
l
o
g
(
σ
1
)
+
l
o
g
(
σ
2
)
)
(log(σ_1)+log(σ_2))
(log(σ1)+log(σ2))。该损失函数的权重系数是会随着网络学习不断更新的,因此能够寻找到最优的参数组合。
创新点
- 首次提出三个任务同时训练网络
- 提出一种基于方差不确定性的损失函数计算方法
总结
该网络首次实现了三种视觉任务的同时训练,其网络最大的特点在于编码器部分三个任务共用,这证明了多个任务所需要的特征图是可以共享的,这极大的降低了多任务网络的复杂度和计算量,另一方面该网络的解码器部分非常简单,但我也认为这是他网络效果不够优秀的原因所在,如果对每个任务的解码器部分都做一个更加精细的设计,可能整体效果会更好。论文的核心在于损失函数的设计,提出了基于方差不确定性的损失函数计算方法,取代了简单的加权求和方法,权重参数能够随着网络训练不断更新,寻找到最优的组合方案,并且根据实验能发现,该方法对于权重系数的初始化是具有很强鲁棒性的,无论参数初始值如何选择,在大约100次迭代之后都会趋近与相同的组合。
53.《End to End Learning for Self-Driving Cars》
发表时间:2016年4月25日
网络名称:
核心思想
该网络采取一种非常大胆方案,不再利用CNN作为一种环境感知的手段,而是直接利用CNN端到端的控制汽车转向,输入视频,输出转角。该网络结构十分简单,一共有9层,第一层是规则化层,不参与网络的优化过程,后面是5个卷积层,前三层的卷积核为5 * 5,步长为2,后两层卷积核为3 * 3 ,步长为1;最后是三个全连接层,输出为一个数值,即转角度数。训练损失就是转角与正确角度之间的均方差。作者采集了72小时的真实驾驶录像,包含各种路况,各种天气,作为训练集,对网络进行训练。在测试过程中分成两个阶段,第一个阶段是在模拟驾驶环境下,测试网络是否能够输出正确转向角度,当车辆偏离车道线超过1米时,则会有人工介入,修正车辆方向。第二阶段是实车测试,利用DRIVE PX平台进行神经网络的计算,并通过线控系统,控制车辆转向。评价指标是自动驾驶时间占总行驶时间的比例,经试验该比例达到了98%,证明该方案能够有效控制车辆的转向。
创新点
- 打破了无人驾驶中感知层与决策层之间的壁垒,实现了端到端的控制车辆转向,直接利用摄像头捕捉图像,输出转向角度
总结
本文是NVIDIA团队提出的无人驾驶方案,其摒弃了典型的感知-决策方案,而是利用CNN直接从图像中学习如何控制车辆。但其控制策略比较简单,只能控制车辆转向,而不能控制车辆的纵向运动。其试验效果证明,CNN能够直接从图像中学习到足够的特征信息,并做出正确的判断。但另一方面,其训练时间较短,数据集仅有72个小时,且覆盖的条件有限,因此在面对突发情况,或特殊情况时,不确定网络决策是否及时准确。
54.《Learning Monocular Depth by Distilling Cross-domain Stereo Networks》
论文来源:ECCV 2018
核心思想
该论文提出了一种很新颖的想法,利用双目视觉得到深度图作为真实值用于训练单目视觉估计网络。这是因为单目视觉深度估计存在一些缺陷,对于有监督训练,单目深度估计网络需要大规模的数据集,尽管有SceneFlow这样的大规模合成数据集,但单目视觉深度估计网络的泛化能力很差,在合成数据集上训练的网络,应用到真实场景中表现很差,而且不同的场景之间都不具备通用性,如室内环境和街道场景。对于无监督训练,估计的准确性很差。并且在训练过程中,不能利用旋转,放缩,扭曲等操作扩充数据集,因为单目深度估计对于视角的变化十分敏感。而双目深度估计在场景迁移和视角变化方面鲁棒性更强,泛化能力更强。因此作者提出一种新的训练流程,分为三步,首先,利用合成数据集训练立体匹配网络,本文采用的立体匹配网络是DispNetC的一个变种,与普通的立体匹配网络仅仅得到视差图不同,该变种还要利用分类的方式,将所有的像素点分成遮挡区域和非遮挡区域两种,得到遮挡区域图;然后,利用有监督或无监督方式,在真实数据集如KITTI上优化训练立体匹配网络,对于有监督训练,损失函数为L1损失函数。对于无监督训练,损失函数分为三项,第一项 L p h o t o L_{photo} Lphoto计算非遮挡区域的光度损失,第二项 L a b s L_{abs} Labs计算遮挡区域的损失,原则是尽量接近未经优化训练的预测结果;第三项 L r e l L_{rel} Lrel是光滑项,使视差梯度尽量小。最后,利用立体匹配网络得到的视差图训练单目深度估计网络,单目深度估计网络整体采用编码解码结构,编码器部分为VGG-16网络,解码器部分带有跳跃连接,带有不同尺度下的深度监督。要注意与其他单目深度估计网络直接输出深度图不同,此处得到的结果为视差图,需要利用转换公式,计算得到深度图。
创新点
- 提出一种新颖的单目视觉深度估计网络训练思路,在不增加数据集的前提下,改善了训练效果
- 提出一种新型的无监督网络训练方法,将图像分为遮挡区域和非遮挡区域,避免了光度损失在非遮挡区域的错误估计问题
总结
该论文提供了一种很好的将单目深度估计与双目立体匹配结合起来思路,利用双目立体匹配解决了单目深度估计的训练问题,根据作者的试验,立体匹配网络的效果越好,单目深度估计的结果也更加准确。该文章提出的在无监督训练过程中,将图像分为遮挡区域和非遮挡区域的想法,也非常值得借鉴。在无监督训练过程中,如何提供一个可靠地虚拟真实值,是研究的重点,本文减少了在遮挡区域的错误估计,并提出利用置信度能够更好提高无监督训练的效果。
55.《Single View Stereo Matching》
论文来源:CVPR 2018
网络名称:SVS
核心思想
该论文提出一种新颖的单目视觉深度估计思路,首先利用一个视角合成网络,从一副图像合成得到对应的立体图像,即根据左图,合成右图,然后再利用立体匹配网络得到视差图。现有的单目深度估计网络基本是根据高层级的语义信息,将其与深度信息关联起来,由于缺乏先验知识,因此直接学习语义与深度之间的关系十分困难,并且需要大规模带有详细标签数据集进行训练。而双目视觉立体匹配的精度更高,泛化能力更强。因此,作者提出由单目图像,合成立体图像,再利用立体匹配得到深度图像。网络分为两个部分,第一部分是视角合成网络,是在Deep3D网络基础上修改得到的,首先对输入图像进行卷积,得到一个三维的视差值概率卷(H * W * D),每个点代表该像素的视差为d的可能性
(
d
∈
D
)
(d \in D)
(d∈D),例如在D=0,H=1,W=1处的数值,表示坐标为(1,1)的点视差为0的可能性。并根据下式得到右图:
I
r
~
=
∑
d
I
l
d
D
d
\widetilde{I_{r}}=\sum_{d}I_{l}^{d}D^{d}
Ir
=d∑IldDd
式中:
I
l
d
(
i
,
j
)
=
I
l
(
i
,
j
+
d
)
I_{l}^{d}(i,j)=I_{l}(i,j+d)
Ild(i,j)=Il(i,j+d),该方法与回归方式计算视差的思路很接近,整个过程是可微的。第二部分是立体匹配网络,是在DispNetC网络的基础上修改的,在计算1D correlation层之后,将右图提取到的特征图级联起来,送入编码解码结构,得到不同尺度下的视差图。两个部分均采用L1损失函数。训练过程首先分别对两部分网络进行单独训练,再结合起来做端到端的优化训练。
创新点
- 提出一种新型的单目视觉深度估计思路,由单幅图像,合成得到立体图像,再利用立体匹配得到视差图,进一步获得深度信息
- 介绍了一种图像合成网络Deep3D,取代了简单的且不可微分的wrap操作
总结
该文章是商汤科技最新成果,其实现了很好的单目深度估计效果,甚至可以媲美许多立体匹配算法,然而他可以仅使用单目摄像机,避免了双目摄像头标定的问题。文章中提到深度估计任务的解决方案可以分成两类:主动立体视觉,如结构光或time-of-flight和被动立体视觉,如立体匹配,structure from motion,photometric stereo或depth cue fusion,其中立体匹配是效果最好,应用最为广泛的被动立体视觉方法。
56.《Simple Does It: Weakly Supervised Instance and Semantic Segmentation》
论文来源:CVPR 2018
核心思想
该论文提出一种弱监督训练语义分割的思路,所谓弱监督,即不采用带有像素级标签的数据集进行训练,而是采用图片级的注释或者箱型框注释等。该论文并没有改变网络结构,也没有改变训练策略,而是从数据集入手,通过将现有的箱型框注释的数据集进行处理,使得标记更加接近真实值,借此训练语义分割网络。作者提出信息的来源包括两部分:箱型框和物体的先验信息,并将其归结为三种线索:背景,没有被箱型框圈中的像素即属于背景;对象范围(object extent),箱型框内的像素即属于对象的范围;对象属性(Objectness),物体的空间连续性和明显的边缘信息。据此作者提出两种方法对数据集的标注进行优化或者说精细化。第一种方法比较简单是基于箱型框的,采用反复迭代精细的方法,首先利用箱型框标记的数据集进行训练,将网络输出的结果经过一定的后处理步骤后,作为第二次训练的数据集,逐次迭代。在此基础上又提出了“忽略部分区域”(ignore region)的方法,不使用整个箱型框作为标记,而是选取中部的20%的区域作为标记,这样的做法会提高准确率(标记的像素基本都属于物体内部)但会降低召回率(许多属于物体的像素没有被标记)。第二个思路是基于GrabCut的,GrabCut算法是一种从箱型框中估计物体分割的技术,作者利用HED边缘检测网络对GrabCut进行了改进得到了GrabCut+算法。与基于箱型框的思路一样,作者也提出了“忽略部分区域”的方法,用GrabCut+算法生成150个结果,如果超过70%的结果都标记某个像素为前景物体,则该像素属于前景。如果低于20%的结果标记某个像素为前景物体,则该像素被标记为背景。其他像素被忽略掉。为了利用对象属性信息,作者又引入了MCG算法,选择重叠率最高的预选框作为对应物体的分割部分。将MCG与GrabCut+相结合,两者同时标记的像素,才被标记为物体,只有一个算法标记的像素忽略。将处理过的数据集送入现有的语义分割网络进行训练,本文采用的是DeepLabv2网络,弱监督的结果准确率达到了全监督方法的95%。
创新点
- 研究了迭代训练方法对于弱监督语义分割网络的作用与该方法的局限性
- 通过优化数据集的方法改善了弱监督语义分割网络的训练效果,并且没有修改网络结构和训练策略
- 首次使用该方法实现弱监督的实例分割任务
总结
语义分割任务由于其标记成本很高,因此十分需要有高效的弱监督或半监督算法,半监督通常是采用一半数据集带有像素级标签,一半数据集为图像级或箱型框标签。弱监督则是全部采用图像级或箱型框标签,本文从优化数据集的角度入手,利用传统算法与深度学习方法相结合,改善了弱监督语义分割网络的训练情况,提供了一种新的弱监督网络训练思路。
57.《Panoptic Feature Pyramid Networks》
网络名称:Panoptic FPN
发表时间:2019年1月8日
核心思想
该文章提出一种新的全景分割网络,全景分割是语义分割和实例分割的结合,输出的每个像素既带有类别标签又带有实例ID。与其他方法采用两个独立的网络分别实现语义分割和实例分割任务,再将结果合并起来的方法不同,该文章设计了一个简单的网络同时完成两个任务,并取得了SOTA的结果。其网络结构也非常简单,以带有FPN(Feature Pyramid Network)的Mask R-CNN(实例分割的常用结构)为主体,并增加了一个语义分割分支。首先利用ResNeXt-101作为编码器,分别得到分辨率为原图1/32,1/16,1/8和1/4的特征图,在解码器部分逐步还原得到分辨率为原图1/4的特征图,与U-Net的结构不同,该网络的编码器和解码器不是对称的,编码器部分随着图像尺寸下降,通道数增加,而解码器部分通道数固定为256,作者称之为轻权重结构(lightweight)。在此基础上增加了一个用于语义分割任务的分支网络,首先将解码器的各个层,分别经卷积和上采样恢复到原图的1/4,如1/32的特征图,需要经过3次卷积和3次上采样,得到4个通道数为128的尺寸为1/4的特征图,将其相加起来,再经过卷积和上采样恢复到原尺寸。利用softmax得到各个像素的类别标签。最后将语义分割图与实例分割图融合起来,对于实例分割重叠的区域,根据置信得分重新划分成不同的实例;对于实例分割与语义分割的区域,优先考虑实例分割;去除标记为“其他”类别的填充区域(stuff region)和低于给定门限值的区域。损失函数分为两部分,语义损失 L s L_s Ls和实例损失,其中实例损失包括:类别损失 L c L_c Lc,边界框损失 L b L_b Lb和掩码损失 L m L_m Lm,按照不同的权重进行加权求和得到最终损失。
创新点
- 首次提出一个整体的网络同时实现语义分割和实例分割两个任务
- 提出一种轻权重的FPN结构
- 提出一种新型的基于FPN的语义分割分支
总结
该文章是FAIR何凯明大神的最新作品,也完成了他在前作中提到的全景分割问题,该网络作为一种多任务融合网络,在各自独立的任务中均取得SOTA级别的效果,可谓非常难得。其可以作为全景分割任务的基准网络,预计未来会有更多的衍生变种出现。该网络基本是以带有FPN的Mask R-CNN为主的实例分割网络,而语义分割部分是再次基础上增加的一个分支,结构非常简单,但效果却十分惊人,这也为多任务融合的网络结构提供了一种新的尝试思路。当然,必须考虑到语义分割任务与实例分割任务十分接近,有许多可以共享的特征信息。
58.《Cross-stitch Networks for Multi-task Learning》
发表时间:2016年4月12日
核心思想
该网络提出一种多任务融合的方法,文章首先探究了解决多任务问题,网络结构共享的部分和独立的部分如何分配才是最好的,作者利用AlexNet结构对语义分割和表面法向量估计(Surface Normals)任务进行实现,以枚举的方式寻找最佳组合方式——前四层卷积采用共享结构,其它层采用分离结构。然而,这个工作量很大,对于深层次网络逐一试验是不现实的,因此作者提出要利用神经网络寻找到最好的组合方式,并设计了Cross-stitch结构。原理非常的简单,对于A,B两个任务采用相同的AlexNet结构,对于每一个池化层输出的特征图 x A x_A xA, x B x_B xB,乘以一个系数,按照线性组合的方式计算得到组合结果 x ~ A \widetilde{x}_A x A, x ~ B \widetilde{x}_B x B,对应的系数随着网络训练不断更新。 ( x ~ A x ~ B ) = ( α A A α A B α B A α B B ) ( x A x B ) \binom{\widetilde{x}_A}{\widetilde{x}_B}=\binom{\alpha_{AA}\;\; \alpha_{AB}}{\alpha_{BA}\; \; \alpha_{BB}}\binom{x_A}{x_B} (x Bx A)=(αBAαBBαAAαAB)(xBxA)当系数 α A B , α B A \alpha_{AB},\alpha_{BA} αAB,αBA为0时,则两个任务之间是相互独立的,若系数数值越大,相关性则越强,通过训练得到最佳的分配比例。对于每一个任务,其参数不仅通过自身的误差反向传播进行更新,也会通过Cross-stitch结构,利用另一个任务的误差进行更新。其他内容均是常规操作,损失函数对于语义分割和表面法向量估计的权重均是1。作者通过实验发现,该方法得到的分配方式与枚举得到的结果十分接近,但效果确有一定的提升,这证明该方法具有一定的作用。并且发现对于缺少数据(data-starved,即像素点较少)的目标,效果提升更加明显。
创新点
- 通过实验探究了多任务网络之间,共享部分和独立部分的分配方法
- 提出一种新型的网络结构自动调整分配比例,通过训练得到最佳分配方式
总结
该文章是较早的探究深度学习方法多任务融合的作品,虽然融合的方式非常的原始,直接对特征图进行线性组合,并对系数进行训练,但仍为后来的研究者提供了一个有意义的思路。
59.《Joint Semantic Segmentation and Depth Estimation with Deep Convolutional Networks》
发表时间:2016年9月19日
核心思想
该文章是将语义分割与单目深度估计相结合,整体网络分成五个不同的路径,每条路径都经过卷积和下采样的到不同尺度下的特征图,最后用两个卷积层分别提取语义分割和深度估计的结果。在此基础上将语义分割和深度估计的结果加上原始图像共同输入到一个全卷积的CRF网络中,对语义分割结果进行优化。损失函数是两个任务损失的加权求和,语义分割损失和深度估计损失的计算方法都没有见过,作者的表述也不明确,所以没有看懂。
创新点
- 多尺度下的特征融合
- 全新的语义分割和深度估计损失计算方法
- 将深度信息补充到CRF中对语义分割结果进行优化
总结
该文章的结构和思想都是比较早期的方法,对语义分割和深度估计任务融合做了一些探索,但利用CRF对语义分割结果进行优化的方法,现在似乎并不常见了,且文章并没有提及语义分割任务如何帮助深度估计任务的改善。提出的损失函数计算方法和深度计算方法描述不够清晰。
60.《DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency》
网络名称:DF-Net
论文来源:ECCV 2018
核心思想
该文章提出一种无监督的单目深度估计,相机位置估计和光流估计相结合的网络。其核心思想在于对于静态物体(rigid region),根据其深度信息和相邻两帧之间的相机姿态信息可以合成得到静态流(rigid flow),理论上讲静态流与光流估计得到的光流(optic flow)应该是一致的,作者提出利用这种一致性作为损失函数,提出跨任务一致性损失函数。对于深度估计任务作者则是利用了光度损失和平滑性损失作为损失函数,在计算光度损失时,作者采用了对光照鲁棒性更强的基于ternary census transform的损失函数。由于光流估计和相机姿态估计都需要连续两帧图像,并且静态流只能对静态物体进行有效估计,因此作者利用前后一致性划分出有效区域和无效区域,这里的前后一致性可以参考立体匹配中的左右一致性假设,即由前一帧图像根据光流或静态流得到的后一帧图像应该和再由后一帧图像还原到前一帧图像,物体的位置应该不变,如果发生变化则为遮挡区域或者运动物体,则划分为无效区域。基于这一原则,作者又提出了光流的前后一致性损失和深度前后一致性损失,所有损失计算均是在有效区域内计算的,通过加权求和得到最终损失。各个任务的网络结构基本采用了现有的成熟结构,单目深度估计是ResNet-50+ELU激活函数,相机姿态估计采用的是Zhou等人提出的网络,光流估计采用的是UnFlow-C,是FlowNetC的一个变种。
创新点
- 利用深度估计和相机姿态估计计算得到静态流,并提出跨任务一致性损失函数,利用其对光流估计进行监督
- 根据前后一致性假设,划分出有效区域和无效区域,并据此提出了前后一致性损失函数
- 引入了一种新的光度损失函数计算方法
总结
该文章的核心不在于网络结构的设计,而在于损失函数的设计。其提出使用静态流对光流做无监督训练,是我第一次看到深度估计和光流估计的实质性结合。但这样做的缺陷也是明显的,因为静态流只有对静态物体的估计才准确,即目标不能移动,而摄像机在移动,这对于实际应用存在很大的局限性。作者还参照左右一致性假设,提出前后一致性假设,并据此划分有效区域,提出对应损失函数,这有效的降低了运动物体对光流估计的影响。
61.《Towards Unified Depth and Semantic Prediction from a Single Image》
论文来源:CVPR 2015
核心思想
该文章是较早探索深度估计和语义分割任务融合,以及局部信息和全局信息结合的文章。作者的核心观点有两条:语义分割与深度估计任务具有很大的相关性,两者可以相互促进;全局信息能够提供粗糙但是全面的语义引导,局部信息能够提供更多深度和语义边缘的细节。基于这两个思路,作者提出了一种多层的CRF模型,首先利用基于像素(全局信息)和基于区域(局部信息)的两个CNN分别得到各自的深度估计结果和语义分割结果,然后利用CRF将其融合起来得到最终的结果。CRF的能量方程包含以下几项:
ψ
i
(
x
i
)
\psi_{i}(x_i)
ψi(xi)像素级的一元势能(unary potential);
ψ
i
,
j
(
x
i
,
x
j
)
\psi _{i,j}(x_i,x_j)
ψi,j(xi,xj)
像素之间的边缘势能(edge potential);
ψ
s
,
t
(
y
s
,
y
t
)
\psi _{s,t}(y_s,y_t)
ψs,t(ys,yt)区域之间的边缘势能;
ψ
s
(
χ
s
,
y
s
)
\psi _{s}(\chi_s,y_s)
ψs(χs,ys)区域和像素之间的跨层势能,通常分解为
ϕ
s
(
y
s
)
\phi _{s}(y_s)
ϕs(ys)区域级的一元势能和
ϕ
s
(
y
s
,
x
i
)
\phi _{s}(y_s,x_i)
ϕs(ys,xi)区域s和包含在区域s内的像素i之间的势能。像素级的一元势能项,通过基于全局的CNN得到,其编码了粗糙的全局分布信息,区域级的一元势能项,通过基于局部的CNN得到,其聚焦于局部细节信息。边缘势能项则整合了深度和语义标签之间的一致性。
基于全局的CNN输出像素级别的深度估计和语义分割图,训练过程中由于深度估计的真实值比较容易获得,因此先训练深度估计任务,再在此基础上训练语义分割任务。基于局部的CNN首先利用超分割(over-segmentation)算法将整幅图像分割成不同的区域,再利用CNN得到每个区域的深度标签和语义标签,对于语义任务,选择区域内像素点数最多的标签,来代表这个区域的语义标签,对于深度任务则不能简单的选择像素最多的标签,而采取一种相对深度的方法,估计其他像素与中央像素之间的相对深度,并将其规则化到[0,1]之间。
最后利用分层CRF将语义与深度相结合,并将局部与全局相结合。根据深度图推测分割图,利用循环置信传播(LBP)算法由深度图得到区域级的分割图,然后利用MAP算法(没找到全名)将区域级的分割图传播到像素级。根据分割图推测深度图,没有完全看懂,大概是基于置信传播思想的一种方法,推测深度参数。
创新点
- 利用CRF将全局与局部,语义和深度结合起来
- 用两个分支分别处理全局信息和局部信息
- 在进行区域级深度估计时,引入了样例比较的方法(其实是人工设计特征的一种方式)
总结
这篇文章发表时间较早,所以保留了大量的传统算法部分,包括CRF,LBP,图割等,但其提出的将全局和局部分别使用两个分之网络进行处理,最后再融合起来的思路,与我们的想法不谋而合。其也在语义分割与深度估计的多任务融合方面做了很多的探索,但其基本上是基于传统方法的。
62.《MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving》
网络名称:MultiNet
发表时间:2018年5月8日
核心思想
作者将分类,目标检测和语义分割(道路分割)三个任务结合在一起,提出一个用于无人驾驶领域的实时的网络。网络的基本结构还是采用了统一编码,分别解码的方式,三个任务共用一个编码器,而解码器则是三个并行的结构。作者分别用VGG和ResNet作为编码器,试验表明ResNet的效果更好,但速度较慢,VGG的效果略差,但计算速度较快。解码器部分,对于分类网络提出了两种解码器结构,第一种是带有softmax激活层的vanilla全连接结构,该结构无法和其他任务相结合。第二种结构能够更好的利用高分辨率的图像,这对于道路场景的分类具有重要意义。首先令3 * 3的卷积将通道压缩到30,再利用带有softmax层的全连接层输出两个类别的概率,将图像分成高速公路和小路两种类别。对于检测网络,作者希望将基于预选区域(proposal base)算法的高精度和基于非预选区域(non-proposal base)算法的高速度结合起来,为了实现这个目标,作者在解码器部分添加了一个重新调节层(rescaling layer),该层是由RoI align构成的,能够起到基于预选区域算法的作用。首先,经过1 * 1的卷积层,将通道数调整为500,然后再进一步通过1 * 1 的卷积将通道压缩为6,称该6维的张量为“预测”(prediction),张量的前两维构成了一个粗糙的分割图,每个数值代表该位置上出现感兴趣目标的置信度。后四个通道表示边界框(bounding box)的坐标信息。重新调节层采用RoI align的策略,将RoI align,500维特征图和预测张量级联起来,再经过1 * 1的卷积得到精确的预测结果。分割网络比较简单就是一个带有跳跃连接反卷积结构,逐步恢复的原图尺寸,因为只需要分割出道路,所以最后只输出两层的得分图。损失函数,分类和分割任务都采用交叉熵损失函数,检测网络使用L1损失函数来计算坐标和边界框的尺寸误差,用交叉熵损失函数计算置信度损失,二者加权求和得到检测网络的总损失。
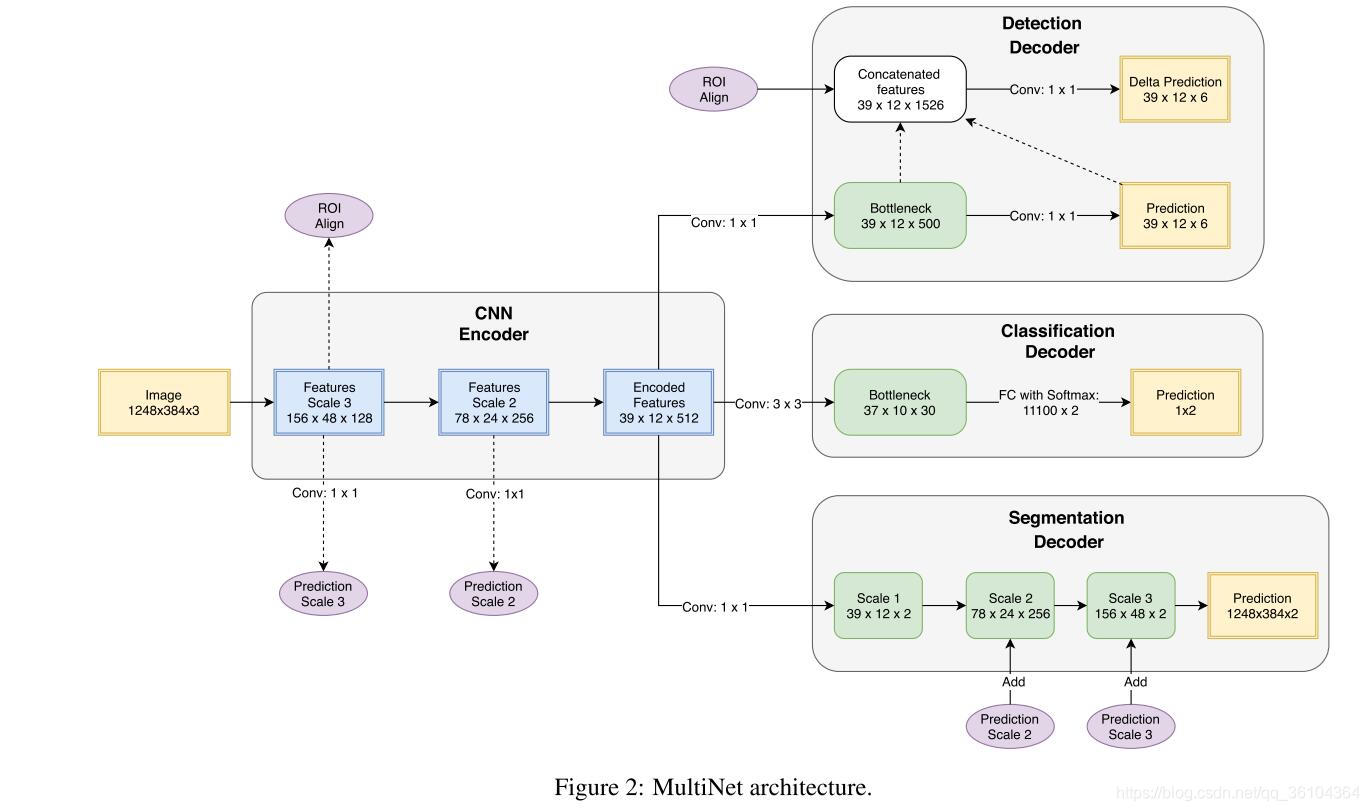
创新点
- 针对无人驾驶应用条件,提出了一个实时的多任务融合网络,同时输出道路类别,道路分割和车辆检测信息
- 在检测网络中引入重新调整层,一个高效的可微分的结构,提高了检测速度和精度
总结
该篇文章的应用意义较大,针对无人驾驶应用,他提供了一个实时的多任务融合网络结构。整个结构还是比较常规的,在目标检测网络中引入了重新调整层结构,提高了检测的速度和精度。该文章公开了代码,可以进一步学习。
63.《UberNet : Training a ‘Universal’ Convolutional Neural Network for Low-, Mid-, and High-Level Vision using Diverse Datasets and Limited Memory》
发表时间:2016年9月7日
网络名称:UberNet
核心思想:
该文章很有野心的利用一个网络同时解决边缘检测,目标检测和语义分割等7个视觉问题,网络结构也是分成共享的主体网络部分和各个任务的分之网络,根据任务特点,分支网络之间略有不同。主体网络采用了6层卷积,对每一层的输出均进行BN处理,并输入到任务分支网络,得到各个子任务的结果,将每层对应子任务的输出级联起来,经过一个融合层得到该任务的输出结果。采用金字塔型的结构,将图像下采样到原图的1/2和1/4尺寸, 再分别对其进行卷积计算,三个不同尺度的主体网络是并行的关系,将各个尺寸的输出融合起来,得到各个任务的最终结果。
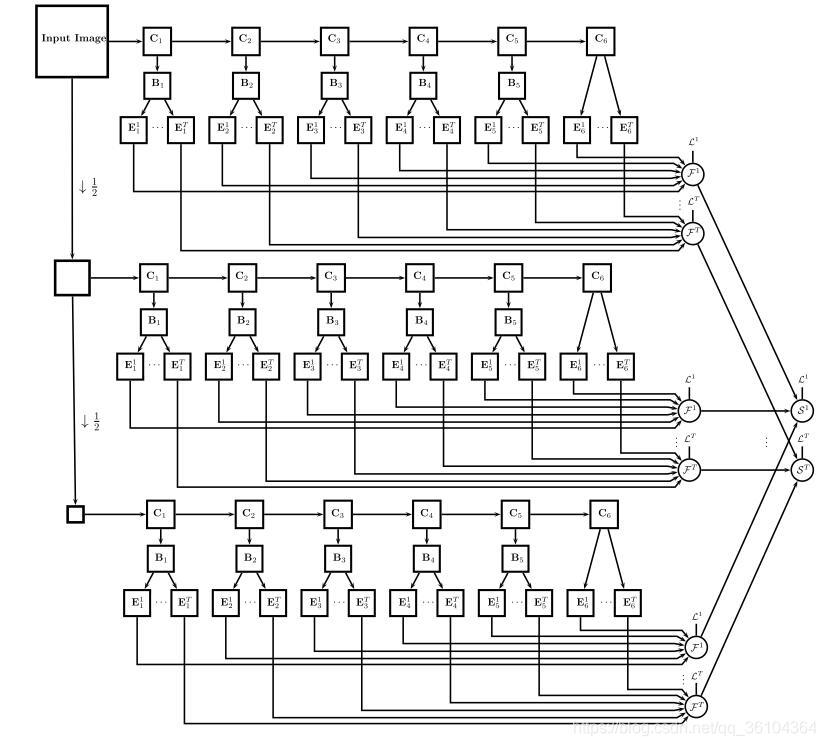
该文章主要解决了两个问题:多任务训练时缺少相关数据集的问题和多任务网络的内存占用过大问题。现有的数据集基本只提供了一到两个视觉任务的真实值,而本文要同时实现7个视觉任务的训练,缺少对应的数据集。针对这个问题,作者采用一种简单的策略,在计算损失时,对于当前的图片,只对拥有真实值的子任务计算损失,其他任务损失设为0,并且在训练过程中,记录每个子任务的有效训练次数,如果对于某个任务,输入的图片没有对应的真实值,则不记录为有效训练次数,只有在有效次数满足一次批训练的要求时,才进行反向传播计算。作者称之为非对称的梯度下降法,与普通的SGD存在一定区别。第二个问题是由于各个视觉任务之间是并行独立的,在进行训练时会占用大量的内存,因此作者采用了一种低内存占用的训练方法。对于普通的训练过程,前向计算时会保存每一个卷积层的数值和激活层的输出,反向传播时再调用内存中的数值进行更新。本文的方法是只保存若干层的激活层输出结果,例如网络有9层,则每隔2层保存1层,这样只需要记录3层特定的激活层结果。反向传播过程中,可以根据特定激活层的结果,计算得到其他层的输出。这种方法增加了反向传播的计算量,但有效降低了内存占用。并且作者发现采用这种方法后,各个子任务之间是解耦的,因此内存占用只与子任务网络的结构复杂度有关,而与任务数目无关。
创新点
- 提出了一种多任务深度学习网络
- 设计了一种非对称的SGD算法
- 采用了一种低内存占用的训练方法
总结
作者颇具野心的利用一个网络解决七个不同的视觉任务,虽然结构上并不新颖,但其对于多任务网络中两个很有意义的问题——缺少数据集的问题和内存占用问题,提出了自己的解决方案,这对于多任务融合网络的训练具有一定的指导意义。
64.《Richer Convolutional Features for Edge Detection》
论文来源:CVPR 2017
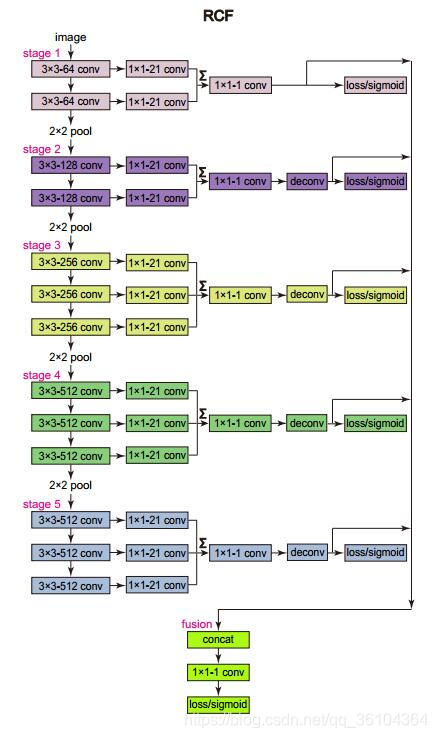
网络名称:RCF
核心思想
本文提出了一个用于边缘检测的卷积神经网络,其提出了一个“丰富卷积特征”(Richer Convolutional Features)的概念,本质上就是一个全卷积网络。以VGG16作为主体网络,将网络分成五级,每一级之间都有一个步长为2的池化层,将图片尺寸缩小一倍。对于每一级的输出,都经过一个上采样层恢复到原图尺寸,最后将各个层级的输出级联起来,并经过一个1*1的卷积层得到最终的结果。作者同样采用了深度监督的机制,对于每一层级的输出,都计算损失,并与级联结果的损失加权求和,得到最终损失。损失函数对交叉熵损失函数做了一些改进,因为边缘检测的真实值有很多种标记,作者将所有的真实值取平均值,得到边缘概率图,概率大于
η
\eta
η的像素标记为正样本,概率为0的样本标记为负样本,其他的忽略。根据正负样本数目计算一个权重值,赋给损失函数。为了提高不同尺度下提取特征的能力,作者将原图分别放缩0.5,1.0,1.5倍,构成一个图像金字塔。该方法提高了边缘检测的准确率,但降低了处理速度。
创新点
- 提出一种新型的全卷积神经网络用于边缘检测
- 采用深度监督方案和图像金字塔结构,提高边缘检测的准确度
- 对交叉熵损失函数进行改进,得到一种更具鲁棒性的损失函数
总结
该网络具有很强的边缘检测能力,并且可以实现实时检测,结构比较简单,具有一定的研究价值,但目前边缘检测的数据集相对较少,网络的训练存在一定问题。其采用的方案都是比较成熟的技术,复现难度不大。
65.《SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks》
论文来源:CVPR 2019
发表时间:2018年12月31日
网络名称:SiamRPN++
核心思想
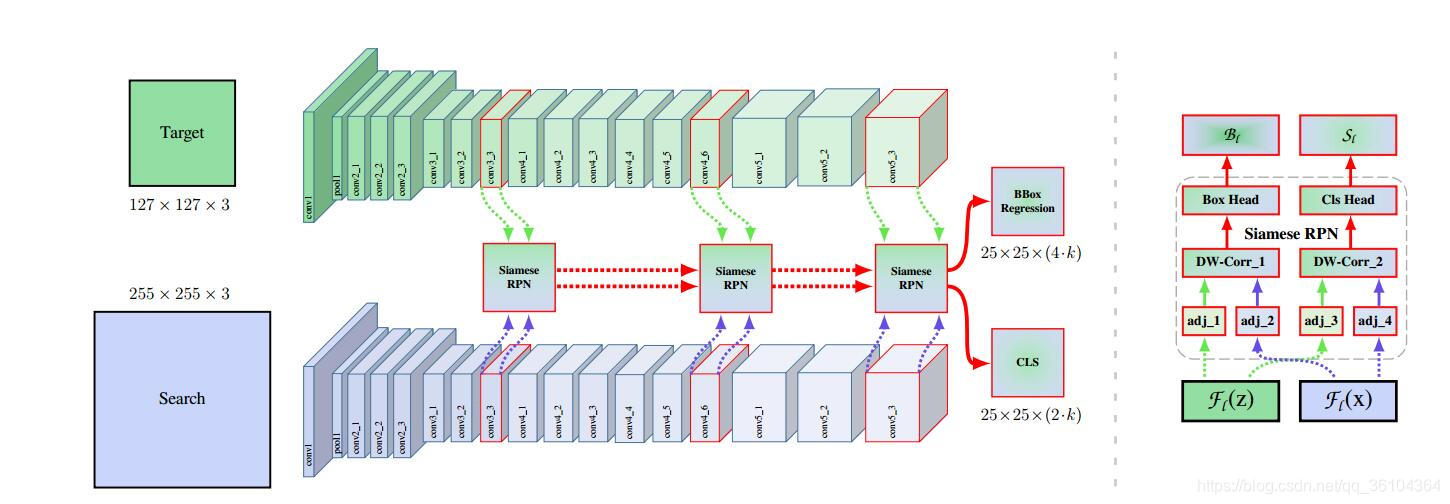
该网络是目标跟踪算法的最新成果,其依旧延续了孪生网络的思想,首先对于需要跟踪的目标对象和搜索区域分别利用CNN进行特征提取,这个过程是权重共享的,因此成为孪生网络。然后对于两组特征图(分别来自目标对象和搜索区域)进行互相关操作(cross correlation,此处介绍的是最早的siameseFC网络),所谓互相关操作,就是以目标对象得到的特征图(6 * 6 * 128)作为卷积核,在搜索区域对应的特征图(22 * 22 * 128)上进行卷积操作,得到一个得分图(17 * 17 * 1),得分最大的点即为跟踪目标的中心坐标。SiamRPN在此基础上,修改了计算得分图的策略,不是采用简单的互相关操作,而是引入了Faster RCNN中采用的RPN网络,将计算跟踪目标位置和边缘框的过程分为两个分支,一个是对锚点(anchor)进行分类,分成包含目标对象的(前景)或是不包含目标的(背景)两类;二是对边缘框的位置进行回归,主要是计算边缘框的(x,y,w,h)四个参数。假设锚点的数目为K,则分类分支的特征图数目为2K(不是两千!!分别表示属于前景和背景两个类别的概率值),回归分支的特征图数目为4K(分别表示x,y,w,h)。目标对象的特征图分别通过两个卷积层,得到分类分支的输出(4 * 4* (2K * 256))和回归分支的输出(4 * 4 * (4K * 256)),搜索区域的特征图同样经过两个卷积层,分别得到分类分支的输出(20 * 20 * 256)和回归分支的输出(20 * 20 * 256),然后对于目标对象的分类分支输出和搜索区域的分类分支输出和回归分支输出分别进行互相关操作,得到两组得分图,分类分支输出2K张得分图,每组2张,共K组;回归分支输出4K张得分图,每组4张,共K组。至此SiameseFC和SiamRPN已经介绍完了,那本文又做了那些改进呢?
值得注意的是无论是SiameseFC还是SiamRPN在特征提取阶段都采用了不带有pading操作的AlexNet,为什么没有采用更新的,更深的ResNet呢?这是因为许多人发现网络加深后,效果不仅没有提高,反而更差了。本文经过试验分析得出,结果恶化的原因是深层网络中采用党的Pading操作导致网络的空间不变性被破坏了,使得网络匹配的效果更差,而对于深层网络Pading操作是不可避免的,否则图像会不断缩小。作者提出采用空间感知采样策略(space aware sample strategy),可以有效的解决这个问题,至于这个空间感知采样策略作者没有很具体的解释,根据文章的意思猜测是对搜索区域图像在有限范围内进行随机平移操作,试验显示最佳范围是64个像素。经过这一步操作,网络的空间不变性得到保证,因此可以使用更深层的网络对特征进行提取。作者在ResNet-50的基础上进行小幅度的修改,包括取消了两个卷积层的步长,使总步长由32改为8;为了扩大感受野,在部分卷积层中引入空洞卷积;为了减少特征图数目,利用1 * 1的卷积层将特征图数目改为256。不仅如此,作者还采用了“分层聚合”和“深度交叉相关”两种结构,分层聚合比较好理解,就是将浅层,中间层和深层的特征图分别输入到RPN结构中,再将得到的输出结果加权融合起来,权重是可以训练的参数。这也是常见的将低级别特征(如:颜色,边缘)和高级别特征(如:语义特征)结合起来的方式,这是浅层网络所不具备的能力。(作者提到三个RPN输出的图像尺寸相同,可以直接加权求和,不知道为什么不同层的特征图尺寸是相同的,怀疑是在RPN的结构中利用卷积层统一的尺寸,也有可能是因为取消了两个卷积层的步长,使得后三层的图像尺寸不再下降,具体要等待代码公开)。深度交叉相关则是解决了SiamRPN中交叉相关参数较多的问题,对于目标对象和搜索区域两个分支的输出特征图,分别在每个通道上做互相关操作,而不是所有通道同时进行互相关操作,再利用一个卷积组(Conv+BN+ReLU)将各个通道的互相关结果融合起来,再分别经过分类和回归两个卷积层得到最终输出。此外作者还发现一个有趣的现象,就是对于同一类物体,会在相同的通道中表现出近似的特征,这可能是反映出特征提取的一些内在机制。
创新点
- 解决了目标跟踪孪生网络不能使用深层网络的问题,提高特征提取能力
- 提出了多层聚合网络,聚合不同层级特征信息
- 提出了深度交叉相关操作,减少了RPN过程中的参数数目,使得网络更容易训练
- 发现了同类物体在某些通道上表现出近似特征的现象
总结
该文是商汤科技目标跟踪组的最新成果,解决了深层网络效果恶化的这一大难题,可谓是功盖千秋,不仅如此又提出了多层聚合和深度交叉相关操作进一步提高了SiamRPN网络精度和实时性,在多个数据集中都取得了最佳排名。实验中发现的同类物体在某些通道上表现近似特征的现象也是指引大家进一步研究的方向。
66.《Region Proposal by Guided Anchoring》
发表时间:2019年1月10日
网络名称:GA-RPN
核心思想
在目标检测领域无论是两级网络,如Faster-RCNN,还是单级网络,如SSD,都依赖于候选区域的选择。Faster-RCNN中提出的RPN网络作为一种高效准确的候选区域的选择方法得到了广泛应用,其中有一个关键的步骤就是锚点(anchor)的选择,先前的算法都是对每个像素点,选择K个不同尺寸,不同宽高比的锚点,这种方法虽然能够有效的寻找到候选区域,但是无效的锚点太多,增加计算负担,且锚点的尺寸和宽高比都是人为设定的,对不同目标的适应性较差。作者提出的GA-RPN则是利用一个guided anchor网络通过学习的方式,生成锚点。具体来说,一个锚点有四个参数(x,y,w,h),作者用两个分支分别计算锚点的坐标和形状,是由特征提取网络输出的特征图为
F
I
F_I
FI,坐标分支对
F
I
F_I
FI 进行1 * 1 * 1的卷积,计算每个像素点是目标中心点的概率,只有当概率值大于设定的阈值时,其对应的锚点才被计算和考虑,这样可以过滤掉90%以上的无效锚点。然后,形状分支对
F
I
F_I
FI 在进行 1 * 1 * 2 的卷积输出的两个通道分别代表锚点的w和h。这两个结构是平行的,经过这一步处理,便得到了每个像素点是目标中心点的概率,和其对应的锚点的尺寸。这里有一点需要注意的是,因为锚点的尺寸变化范围很大,有的可能是5 * 6,有的可能是100 * 200,因此直接学习尺寸的效率很低,作者采取了一步转换,设
w
=
σ
∗
s
∗
e
d
w
w = \sigma *s*e^{dw}
w=σ∗s∗edw,
h
=
σ
∗
s
∗
e
d
h
h = \sigma *s*e^{dh}
h=σ∗s∗edh,式中
σ
\sigma
σ是一个由试验得到的放缩比例,本文取8,
s
s
s是特征提取网络的下采样步长,网络学习的参数由w,h转换成了dw和dh,范围压缩到了[-1,1]之间,这有效的提高了网络收敛速度。
在得到锚点之后可以继续进行RPN操作分别计算锚点内包含目标的概率和锚点位置和尺寸调整参数。但是需要注意的是由于传统的RPN对于同一组锚点,图中每个像素的锚点尺寸形状是相同的,因此可以简单的对特诊图进行1 * 1或者3 * 3的卷积来计算对应锚点内包含目标的概率,但是本文得到的每个锚点尺寸形状都不相同,因此不能简单的对特征图进行卷积操作。作者提出了特征自适应模块(feature adaptation module)对原特征图进行了调整,具体实现方法是利用一个1 * 1的卷积层从形状分支输出的两张特征图中得到一个偏移图(offset field),根据这个偏移图对原特征图
F
I
F_I
FI进行卷积核为3 * 3的可变型卷积(Deformable Conv),这样就根据每个锚点的尺寸和形状,将锚点框内的信息聚集起来。简单理解就是,如果这个锚点框很大,那我在计算其包含目标的概率时,用普通的3 * 3的矩形卷积核不合适,而应该根据锚点框的大小选择不同形状的卷积核,有时间再专门介绍可变型卷积。此外作者也注意到了多尺度特征的优势,因此也参照其他的论文,设计了一个尺度金字塔。
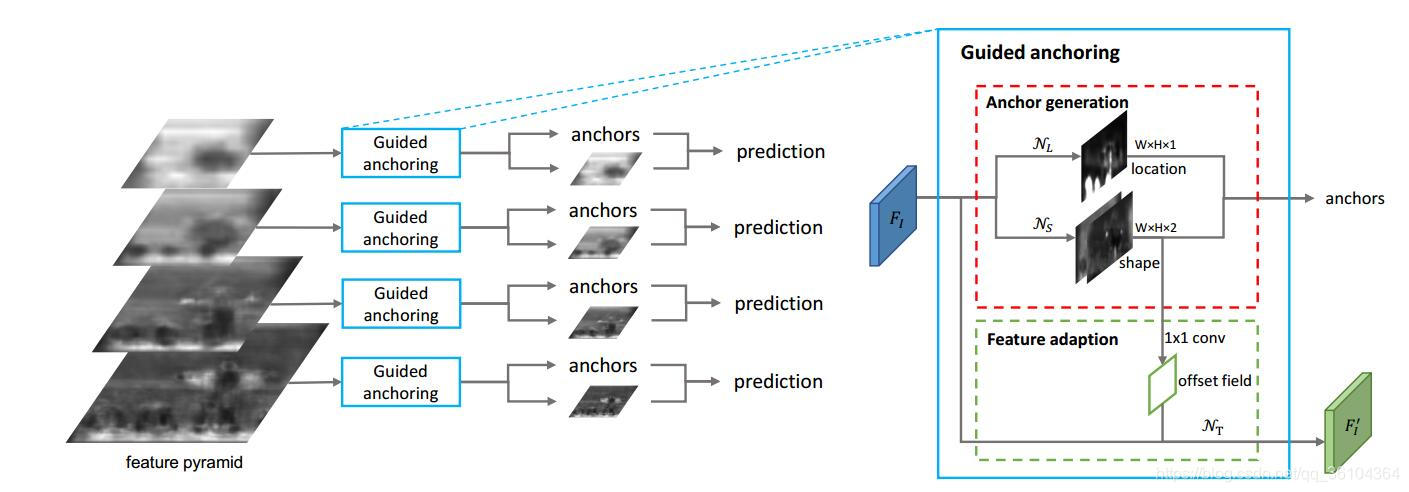
最后作者设计了新的损失函数,除了传统的分类损失和位置调整损失,作者又添加了锚点位置损失和锚点形状损失,分别对应两个新添加的分支。锚点位置损失的计算方法是将目标的边界框(x,y,w,h)按照步长压缩到特征图尺寸(x’,y’,w’,h’),并以(x’, y’)为中心选择一小部分区域
(
x
′
,
y
′
,
σ
1
w
′
,
σ
1
h
′
)
(x',y',\sigma _1w',\sigma _1h')
(x′,y′,σ1w′,σ1h′)作为正样本区域CR,即这个区域内的点标记为1,选择选择稍微大一些的区域
(
x
′
,
y
′
,
σ
2
w
′
,
σ
2
h
′
)
(x',y',\sigma _2w',\sigma _2h')
(x′,y′,σ2w′,σ2h′),并将CR排除掉,作为忽略区域IR,特征图上的其他区域作为负样本区域OR,即这个区域内的点标记为0,最后利用FocalLoss函数计算损失。对于形状损失,我们需要利用锚点框和边界框的IoU来计算损失,但如何得到一个适当的groundtruth呢?理论上来讲,给定一个像素点,应该枚举其上所有的锚点框形状,分别计算与边界框的IoU,选择其中最大值作为groundtruth,但这样做无疑是费时费力,甚至不可能实现的,因为本文的锚点框形状不固定,可能性太多了。因此本文采用了一种妥协的办法,选择了9种锚点框的形状尺寸,以其中与边界框IoU最大的作为groundtruth,用来计算形状损失。
创新点
- 利用引导锚点网络,以学习的方式输出锚点的位置和尺寸,取代了传统手动预设,滑动窗口的形式
- 利用可变型卷积结构设计了特征自适应模块,解决了锚点形状不同,特征的对齐和连续性问题
- 设计了两个损失函数项,用于形状分支和位置分支的训练
总结
作者的创意很好,用神经网络代替人工设计的锚点,既解决了锚点过于稠密计算量太大的问题,又解决了手动设计锚点适应性太差的问题。为了实现这个想法作者解决三个困难,第一,锚点形状尺寸变化范围大,学习效率低下,作者巧妙的利用一步转换将范围压缩至[-1,1]范围内;第二,锚点的形状各异,在计算分类概率时,传统矩形卷积核不能满足特征的连续性要求,因此作者引入了可变型卷积操作,根据锚点框的尺寸,来调整卷积核的形状。第三,对于位置分支和形状分支的训练如何确定groundtruth的问题,作者分别提出了对应的思路,但对于形状分支作者只能妥协的选择了人工选择9种尺寸来计算groundtruth,这也是未来可以改进的地方。
67.《Group-wise Correlation Stereo Network》
论文来源:CVPR2019
发表时间:2019年3月10日
网络名称:GwCNet
核心思想
作者提出了一种新的构建匹配代价卷的方法,在此之前,常用的构建匹配代价卷的两种方法:全互相关(full correlation)和级联卷(concatenation volume)。全互相关方法是一种很高效的计算特征相似度的方式,但会损失很多信息,因为只能在各个视差下得到一个的单通道互相关图。而级联卷方式,需要更多的参数来学习相关性度量的函数。作者针对这两种方法的缺点提出了一种分组互相关的构建匹配代价卷的方法,将特征提取网络输出的
N
c
N_c
Nc个通道的特征图,分成
N
g
N_g
Ng组,则每组包含
N
c
/
N
g
N_c/N_g
Nc/Ng个特征图,对每组特征图分别在各个视差下做互相关操作,得到
N
g
N_g
Ng组互相关图,每组视差图包含不同视差下的互相关图。计算过程如下式:
C
g
w
c
(
d
,
x
,
y
,
g
)
=
1
N
c
/
N
g
⟨
f
l
g
(
x
,
y
)
,
f
r
g
(
x
−
d
,
y
)
⟩
C_{gwc}(d,x,y,g)=\frac {1}{N_c/N_g}\left \langle f_l^g(x,y),f_r^g(x-d,y) \right \rangle
Cgwc(d,x,y,g)=Nc/Ng1⟨flg(x,y),frg(x−d,y)⟩
式中,
⟨
⋅
,
⋅
⟩
\left \langle \cdot , \cdot \right \rangle
⟨⋅,⋅⟩表示内积运算,最后可以得到一个匹配代价卷[d,w,h,g],其中包含视差,宽,高和分组四个维度,同时作者还保留了通过级联构成的匹配代价卷,将两个匹配代价卷级联起来,送入3D卷积网络进行代价聚合。
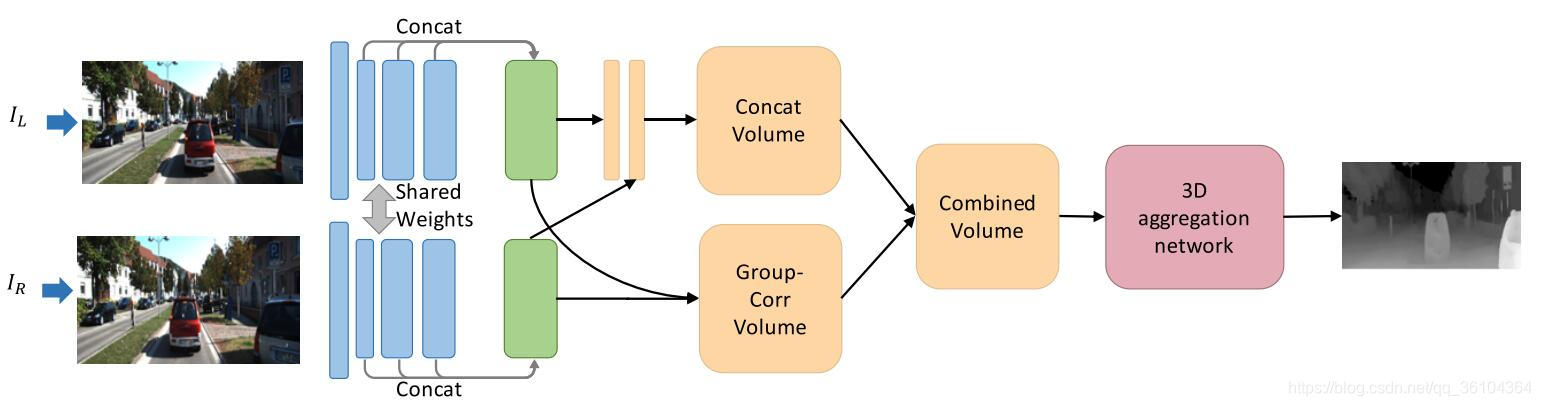
作者的主体结构也是基于PSMNet进行改进得到的,首先在特征提取部分移除了金字塔池化结构,但保留了带有空洞卷积的ResNet结构,将各个层得到的特征图级联起来,得到320通道的特征图。这些特征图分为40组,每组包含8个特征图,分别在不同视差下进行互相关运算,得到40组匹配代价卷,同时利用卷积层将320通道的特征图压缩至24通道,采用级联的方式,构建得到24组匹配代价卷,两个代价卷级联得到64组匹配代价卷。3D卷积部分保留了堆叠的沙漏型结构,但做了一些改进。第一,在原来三个输出模块的基础上,增加了一个输出模块,增加在两个初步的3D卷积之后,第一个沙漏结构之前,这个额外的输出能够帮助网络更好的学习低级别的特征;第二,取消了不同输出模块之间的跳跃连接结构;在沙漏结构中增加了1 * 1 * 1的跳跃连接结构,相对于3 * 3 * 3的结构计算速度更快。视差回归与损失计算方法与PSMNet相同。

创新点
- 提出了分组互相关的匹配代价卷构建方法
- 改进了代价聚合网络,使用更少的参数,以更快的速度,达到了超过PSMNet的效果
总结
本文是商汤科技与香港中文大学在PSMNet基础上提出的立体匹配网络,其网络思想相对于PSMNet并没有很大的改进,核心在于提出一种新型的匹配代价卷构建方法,解决了全互相关方法和级联方法存在的问题,既保留了互相关方法较强的特征相似性度量能力,又保留了更丰富的特征信息。事实上,如果把分组数目改为1,就是全互相关方法。对堆叠的沙漏结构进行了小幅度改进,提高了计算速度。
68.《StereoDRNet: Dilated Residual Stereo Net》
论文来源:CVPR2019
发表时间:2019年4月5日
网络名称:StereoDRNet
核心思想
本文依旧是在PSMNet的基础上对网络进行改进,得到更好的立体匹配效果。首先,在特征提取网络中,去除了金字塔池化部分,引入了vortex pooling结构,vortex pooling是在ASPP的基础上的改进版本,在对特征图进行不同扩张率空洞卷积之前,先对特征图进行平均值池化,池化窗口的尺寸即为对应的扩张率,本文分别用3 * 3,5 * 5,,15 * 15的池化窗口对特征图进行平均池化,对池化后的特征图再分别进行扩张率为3,5,15的空洞卷积,此外还对特征图进行全局平均池化,将四组特征图和原始特征图级联起来,再经过一个3 * 3的普通卷积得到最终的输出特征,根据作者介绍这种操作可以提高空洞卷积对于特征信息的利用率。
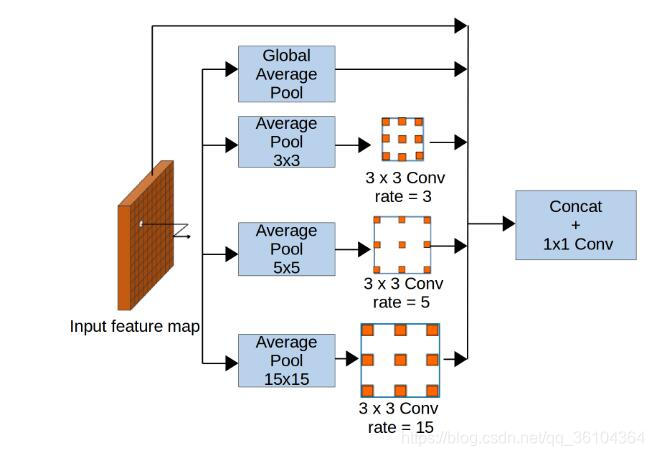
其次,在代价聚合部分,作者增加了3D空洞卷积,此处参考了DeepLab V3中的策略,在编码器的最后对特征图分别做不同扩张率的3D空洞卷积,再级联起来进行反卷积,同样采用了3个沙漏型结构堆叠的方式。
最后,作者提出了Refinement结构,这参考了CRL网络的思想,作者使用光度连续性与几何连续性对第一级网络输出的视差图进行优化。光度连续性即根据左图的视差图对右图进行Warp操作并计算与左图的误差,而几何连续性则是指根据左图的视差图,对右图的视差图进行Warp操作并计算与左视差图的误差。将两个误差图级联起来送入优化网络,优化网络主要由多个带有扩张率的残差网络部分构成的。经过卷积输出优化的残差图和遮挡图,优化的残差图与初始视差图相加得到最终的视差图,遮挡图则用于计算遮挡误差。
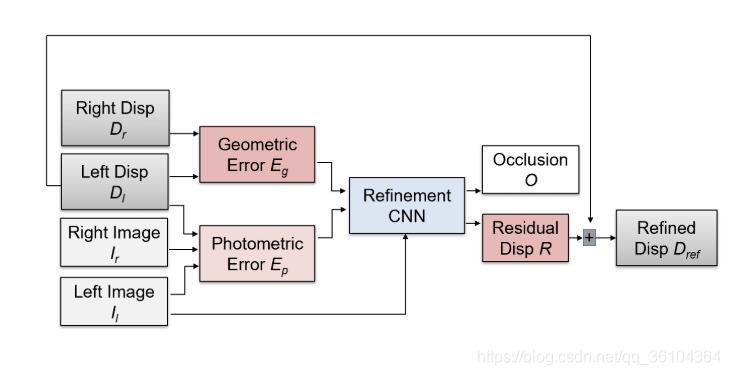
损失函数由三部分构成,初始视差图损失
L
d
L_d
Ld,损失函数采用Huber损失,损失函数如下
L
δ
(
d
,
d
^
)
=
{
1
2
(
d
−
d
^
)
2
i
f
(
d
−
d
^
)
≤
δ
δ
∣
d
−
d
^
∣
−
1
2
δ
2
o
t
h
e
r
w
i
s
e
L_{\delta }\left ( d,\widehat{d} \right )=\left\{\begin{matrix} \frac{1}{2}\left ( d-\widehat{d} \right )^{2} & if \left ( d-\widehat{d} \right)\leq \delta\\ \delta\left | d-\widehat{d} \right |-\frac{1}{2}\delta^2& otherwise \end{matrix}\right.
Lδ(d,d
)=⎩
⎨
⎧21(d−d
)2δ
d−d
−21δ2if(d−d
)≤δotherwise
这个函数对于小的a值误差函数是二次的,而对大的值误差函数是线性的。Huber损失函数是一种更加鲁棒性回归的损失函数,相对于均方误差来说,对异常值不敏感。
初始视差图损失
L
d
L_d
Ld是由第一级网络输出的三个初始视差图的Huber损失加权求和得到的。优化损失
L
r
L_r
Lr则是优化网络输出的最终视差图的Huber损失,遮挡损失
L
o
L_o
Lo则是利用交叉熵损失函数计算遮挡图与遮挡图的Groundturth之间的误差。三个损失函数加权求和得到最终损失。
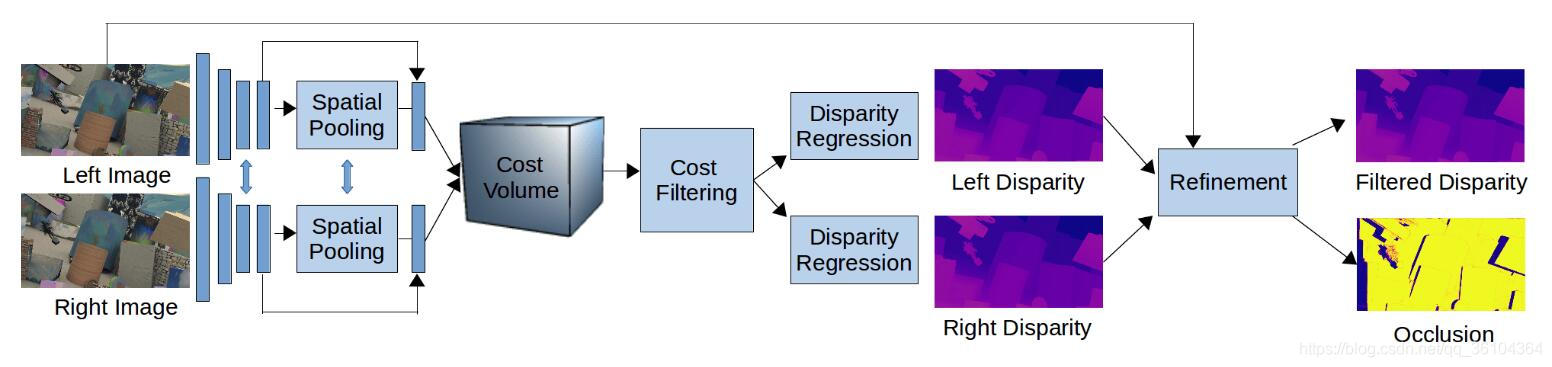
创新点
- 引入Vortex Pooling结构提高了网络的信息利用率
- 引入3D空洞卷积操作,降低运算量的同时,提高网络的信息表征能力
- 设计了优化网络结构,利用光度连续性和几何连续性对初始视差图进行优化
- 采用更具鲁棒性的Huber损失函数,并计算了遮挡损失
总结
本文同样是在PSMNet基础上的改进,引入了Vortex Pooling结构和3D空洞卷积,这两个结构在语义分割领域取得了优异的表现,又借鉴CRL双级网络的思想提出优化网络,但其利用几何连续性的思路是一种创新的想法。作者试验证明该网络的处理速度几乎是PSMNet的两倍,但从网络结构上看,只有3D空洞卷积是降低计算量的操作,其他的改进与提高网络速度并无明显的关系,此处对速度存疑。
69.《Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation》
论文来源:CVPR2019
发表时间:2019年4月5日
核心思想
本文研究了语义分割网络中解码器对于网络效果的影响,并提出一种全新的上采样方案。首先作者指出常见的语义分割网络通常是包含一个编码器和一个解码器,编码器通过带有步长的卷积层,逐步压缩图像分辨率,然后解码器通过反卷积或双边上采样的方法逐层恢复图像分辨率,这一过程虽然通过跳跃连接等结构,补充了一些低层级的特征信息,但总体上还是损失了大量信息,并且计算量比较大(因为随着图像分辨率增加,计算量不断上涨)。作者提出一个重要的发现,语义分割的标签图
Y
Y
Y并不是独立同分布的,其包含了大量结构信息,在压缩过程中并不会有很大的损失,因此作者提出将高分辨的特征图下采样,再与低分辨率的特征图融合,而不是像之前的算法,先将低分辨率的特征图上采样,再与高分辨率的特征图融合。但语义分割最终需要高分辨率的结果,作者又设计了基于数据支持的解码器方案(Data-Dependent Decoder),将标签图恢复到原始尺寸。
现在介绍下DUpsampling的实现过程,首先寻找到一个变换矩阵将
Y
Y
Y压缩至
Y
~
\tilde{Y}
Y~,假设
Y
~
\tilde{Y}
Y~的尺寸为
H
∗
W
H*W
H∗W,通道数为
C
C
C,压缩比例为
r
r
r,则
Y
Y
Y可以划分为
H
r
∗
W
r
\frac{H}{r}*\frac{W}{r}
rH∗rW个窗口,窗口尺寸为
r
∗
r
r*r
r∗r,通道数为
C
C
C。将每个窗口变形为成一个一维向量
v
v
v,尺寸为
1
∗
N
,
N
=
r
∗
r
∗
C
1*N, N=r*r*C
1∗N,N=r∗r∗C,矩阵
P
C
~
∗
N
P^{\tilde{C}*N}
PC~∗N与向量
v
v
v相乘,将向量
v
v
v压缩为向量
x
x
x,尺寸为
1
∗
C
~
1*\tilde{C}
1∗C~,通过将向量
x
x
x分解并在水平和垂直方向上堆叠就构成了
Y
~
\tilde{Y}
Y~。
x
=
P
v
x=Pv
x=Pv然后,在寻找一个反变换矩阵
W
N
∗
C
~
W^{N*\tilde{C}}
WN∗C~将向量
x
x
x还原为
v
~
\tilde{v}
v~,即
v
~
=
W
x
\tilde{v}=Wx
v~=Wx要注意的是
v
~
\tilde{v}
v~和
v
v
v的尺寸是相同的,但由于经过两个变换矩阵,其内容肯定不是完全相同的,因此通过训练让两者之间的误差逐步减小,作者采用L2损失函数来计算两者之间的误差损失,采用SGD方法训练这个变换过程,最终得到经过训练的反变换矩阵
W
W
W。利用反变换矩阵恢复图像分辨率的过程就是DUpsampling。
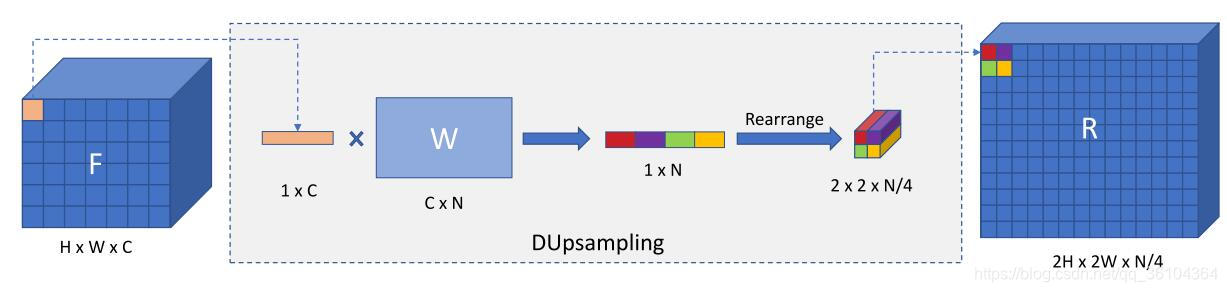
至此,作者的核心思想已经非常明确了,利用常见的编码器将图像逐级压缩至原图尺寸的1/32或1/16,得到
F
l
a
s
t
F_{last}
Flast。将压缩所过程中的各级特征图
F
i
F_i
Fi,下采样至
F
l
a
s
t
F_{last}
Flast尺寸(此处采用的是双边下采样的方式),与
F
l
a
s
t
F_{last}
Flast进行融合,并利用softmax计算得分图。此处作者有两种选择一是保持现在的尺寸不变,将原Groundtruth
(
Y
)
(Y)
(Y)利用
P
C
~
∗
N
P^{\tilde{C}*N}
PC~∗N压缩至
Y
~
\tilde{Y}
Y~,在计算与预测结果之间的损失。或者是利用反变换矩阵
W
N
∗
C
~
W^{N*\tilde{C}}
WN∗C~将预测结果恢复至原图尺寸,再与Groundtruth
(
Y
)
(Y)
(Y)比较,计算损失,作者选择了后者。
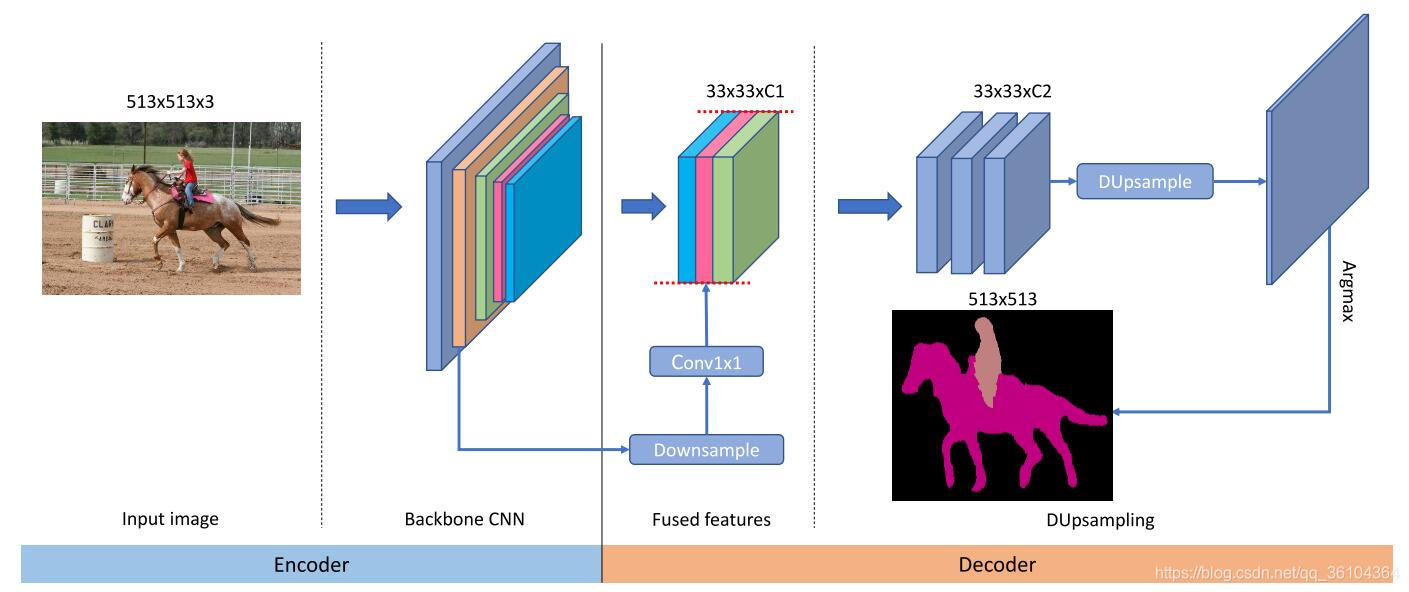
至于分类器,作者发现常用的softmax函数效果并不好,作者引入一种称之为“自适应温度的softmax”(adaptive- temperature softmax)的操作,在普通softmax函数中增加了一个可训练的参数T,公式如下:
s
o
f
t
m
a
x
(
z
i
)
=
e
x
p
(
z
i
/
T
)
∑
j
e
x
p
(
z
j
/
T
)
softmax\left ( z_i \right )=\frac{exp\left ( z_i/T \right )}{\sum _jexp\left ( z_j/T \right )}
softmax(zi)=∑jexp(zj/T)exp(zi/T)
损失函数采用交叉熵损失函数。
创新点
- 提出了新型的上采样方法DUpsampling,取代传统的双边上采样
- 提出一种新的语义分割网络,将不同层级的特征图全部下采样至统一分辨率,融合之后再上采样恢复尺寸
- 引入了自适应的softmax函数用于计算概率,效果优于普通的softmax函数
总结
这篇文章解决了我长久以来的一个困惑的点,即双边上采样的方式导致的信息损失应该怎样解决。这篇文章提出利用一个经过训练的线性映射来恢复图像分辨率,明显要优于简单的插值,这个线性映射是经过训练的,并且很容易部署在神经网络中,相当于权重固定的1*1的卷积层,而且作者指出这种做法允许图像由任意的分辨率进行上采样,这就为融合不同层级的信息提供了可能。其次,该文章提出在低分辨的条件下做信息融合,有效的减少了网络参数,提高网络的计算速度。
70.《Structured Knowledge Distillation for Semantic Segmentation》
论文来源:CVPR2019
发表时间:2019年3月12日
核心思想
作者使用知识蒸馏的方式来训练一个轻量级的语义分割网络,使其以精简的结构(如MobileNet)实现复杂网络(ResNet101)的效果。先前的知识蒸馏网络,通常是包含一个老师网络和一个学生网络,老师网络结构更复杂,但效果更好,学生网络的结构更精简,但效果有限。逐像素(pixel-wise)的计算老师网络的输出和学生网络输出之间的差异,作为损失来训练学生网络。本文在此基础上又增加了成对蒸馏(pair-wise distillation)和整体蒸馏(holistic distillation)。所谓成对蒸馏,就是分别计算老师网络和学生网络输出的特征图中每两个像素之间的相似性,构成相似度图(similarity map),再计算两个相似度图之间的差异。整体蒸馏则是采用了条件生成对抗网络(cGAN)的思想,用一个区分器(discriminator)来给教师网络和学生网络的输出打分,教师网络的输出作为真值,得分应更高,而学生网络的输出作为假值,得分应该更低。而学生网络作为生成器,其目标就是生成尽可能接近教师网络输出的结果,使得自己在区分器中的得分更高。区分器和生成器本身是矛盾的,训练过程也是交替训练,一方面不断提高区分器的区分能力,一方面又要不断提高生成器的生成能力。
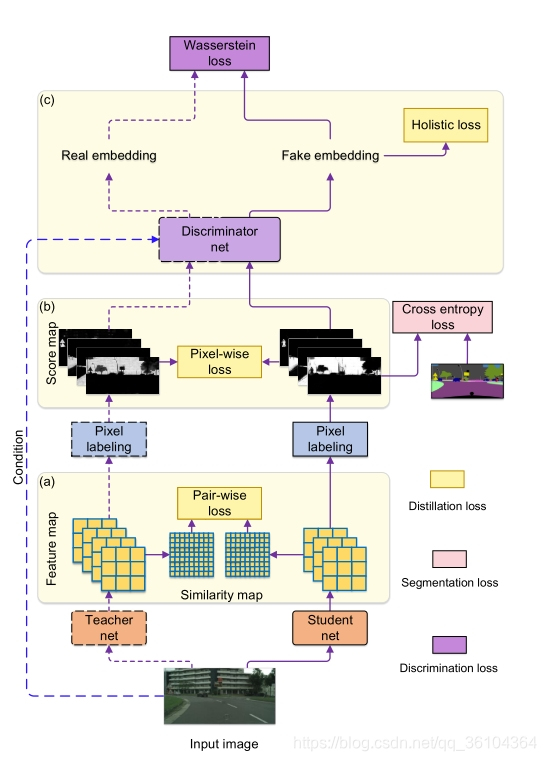
具体实现过程,老师网络采用PSPNet(主干网络为ResNet101),学生网络采用ResNet18结构。首先,对两个网络提取的特征图计算成对损失,计算方法如下式:
l
p
a
(
S
)
=
1
(
W
′
×
H
′
)
2
∑
i
∈
R
∑
j
∈
R
(
a
i
j
s
−
a
i
j
t
)
2
l_{pa}(S)=\frac{1}{(W'\times H')^2}\sum _{i\in R}\sum _{j\in R}(a_{ij}^s-a_{ij}^t)^2
lpa(S)=(W′×H′)21i∈R∑j∈R∑(aijs−aijt)2
式中
a
i
j
s
,
a
i
j
t
a_{ij}^s,a_{ij}^t
aijs,aijt分别表示学生网络和老师网络像素
i
,
j
i,j
i,j之间的相似度,相似度计算方法如下:
a
i
j
=
f
i
T
f
j
/
(
∥
f
i
∥
2
∥
f
j
∥
2
)
a_{ij}=f^T_if_j/(\left \| f_i \right \|_2\left \| f_j \right \|_2)
aij=fiTfj/(∥fi∥2∥fj∥2)
式中
f
i
f_i
fi表示第
i
i
i个像素对应的特征向量。
然后用一个分类器,得到每个类别的得分图,逐像素计算老师网络和学生网络输出的得分图之间的差异损失,计算过程如下:
l
p
i
(
S
)
=
1
W
′
×
H
′
∑
i
∈
R
K
L
(
q
i
s
∥
q
i
t
)
l_{pi}(S)=\frac{1}{W'\times H'}\sum _{i\in R}KL(q_i^s\parallel q_i^t)
lpi(S)=W′×H′1i∈R∑KL(qis∥qit)
式中
K
L
(
)
KL()
KL()表示Kullback-Leibler divergence(相对熵),
q
i
s
,
q
i
t
q_i^s,q_i^t
qis,qit分别表示学生网络和老师网络在第
i
i
i个像素上的类别概率值。
K
L
(
P
∥
Q
)
=
∑
P
(
x
)
l
o
g
P
(
x
)
Q
(
x
)
KL(P\parallel Q)=\sum P(x)log \frac{P(x)}{Q(x)}
KL(P∥Q)=∑P(x)logQ(x)P(x)
除此之外,学生网络输出的得分图最后还要上采样到原图尺寸,利用多分类交叉熵损失函数,与Groundtruth比较来计算分割误差
l
m
c
(
S
)
l_{mc}(S)
lmc(S),这在知识蒸馏中称为硬目标。
最后,构建一个嵌入的网络作为区分器,区分器是由五个卷积层构成的全卷积网络,最后三层之间加入两个自注意力模块(self-attention module),来捕捉结构信息。将原图和老师网络输出的得分图输入区分器,区分器会输出一个真实分布,将原图和学生网络输出的得分图输入区分器,区分器会输出一个虚假分布。再计算Wasserstein distance用于比较真实分布与虚假分布之间的差异,作为整体蒸馏的损失
l
h
o
(
S
,
D
)
l_{ho}(S,D)
lho(S,D),计算方法如下:
l
h
o
(
S
,
D
)
=
E
Q
s
∼
p
s
(
Q
s
)
[
D
(
Q
s
∣
I
)
]
−
E
Q
t
∼
p
t
(
Q
t
)
[
D
(
Q
t
∣
I
)
]
l_{ho}(S,D)=E_{Q^s\sim p_s(Q^s)}[D(Q^s\mid I)]-E_{Q^t\sim p_t(Q^t)}[D(Q^t\mid I)]
lho(S,D)=EQs∼ps(Qs)[D(Qs∣I)]−EQt∼pt(Qt)[D(Qt∣I)]
式中
E
E
E表示期望算子,
D
(
)
D()
D()表示区分器的输出。
l
h
o
(
S
,
D
)
l_{ho}(S,D)
lho(S,D)是一个负数,越小说明学生网络的输出得分越低,老师网络输出得分越高,区分器效果越好,而作为整体蒸馏损失,则希望学生网络和老师网络输出之间的差距越小越好,所以在计算总损失时给其加了一个负号,总损失计算公式如下:
L
(
S
,
D
)
=
l
m
c
(
S
)
+
λ
1
(
l
p
i
(
S
)
+
l
p
a
(
S
)
)
−
λ
2
l
h
o
(
S
,
D
)
L(S,D)=l_{mc}(S)+\lambda _1(l_{pi}(S)+l_{pa}(S))-\lambda _2l_{ho}(S,D)
L(S,D)=lmc(S)+λ1(lpi(S)+lpa(S))−λ2lho(S,D)
创新点
- 利用知识蒸馏的方式提高轻量化网络的语义分割效果,在不增加计算量的前提下,大幅提高了网络的分割效果
- 在传统的逐像素蒸馏损失的基础上,增加了成对蒸馏和整体蒸馏损失,改善了知识蒸馏的效果
- 借鉴条件生成对抗网络的思想,用嵌入的区分器网络来识别老师网络和学生网络的输出
总结
本文创新的采用知识蒸馏的方式提高轻量化网络的分割效果,并取得了明显的进步。其中牵涉到了许多新的概念如知识蒸馏,相对熵,条件对抗生成网络,自注意力模块等,需要进一步深入的了解。
71.《AMNet: Deep Atrous Multiscale Stereo Disparity Estimation Networks》
网络名称:AMNet
论文来源:CVPR2019
发表时间:2019年3月12日
核心思想
作者对PSMNet网络做了较大的改变提出一种新型的立体匹配网络,但整体结构还是包含:特征提取,匹配代价卷,3D卷积和视差回归四大部分。特征提取网络作者使用深度分离卷积替代了普通卷积层,并且增加了4个ResNet分支的输出通道数,由于深度分离卷积能够明显降低参数数量,因此增加通道数并没有增加参数量,但效果有明显提升。提出AM(Atrous Multiscale)模块取代SPP模块来聚合不同尺度的空间信息,所谓的AM模块就是将空洞率不同的卷积层堆叠起来,网络层数越深空洞率越大,过程中不使用池化层或者步长为2的卷积层来缩小特征图尺寸,避免下采样和上采样过程中的信息损失。在构建匹配代价卷过程中,作者提出三种构建匹配代价卷的方法,第一种就是PSMNet和GCNet采用的视差维度上的特征图拼接的方式。第二种方式叫做视差维度上的特征距离,逐像素计算左图和不同视差下右图之间的特征值的差值的绝对值。第三种方式是计算左图和不同视差下的右图之间的互相关图,假设
X
i
,
j
L
X^L_{i,j}
Xi,jL是左图中坐标为
(
i
,
j
)
(i,j)
(i,j)的像素点,则需要计算他与右图中
X
i
,
j
−
d
R
,
d
∈
D
m
a
x
X^R_{i,j-d}, d\in D_{max}
Xi,j−dR,d∈Dmax之间的互相关性,并不是只计算两个像素之间的互相关性,而是先计算以像素为中心的一个正方形范围内的所有点的互相关性,再求和得到中心像素上的互相关性。作者将这三种方式得到的匹配代价卷按照特征通道维度拼接起来,得到拓展的匹配代价卷。在3D卷积过程中,使用堆叠的AM模块取代了沙漏型结构,只不过此时AM模块所有的卷积层都变成了3D卷积层。视差回归方式和损失函数与PSMNet相同。除此之外,作者还提出希望将前景与背景分割开来,优化对前景目标的匹配效果。融合分割信息的方式有两种,第一种直接将分割图和原图一起输入网络,引导网络的学习,但这要求在训练和测试过程中,提前获得准确的分割图像。第二种方式,是训练一个多任务网络,通过训练得到分割图,再将最新一个epoch得到的分割图,与输入图像拼接起来输入到下一个epoch中,形成一种迭代训练的过程。作者并没有专门设计一个分割网络,而是直接将特征提取网络得到的特征图,经过一个二元分类层,一个上采样层和softmax层就得到分割图,并计算分割损失,总的损失包含视差损失和分割损失两个部分。不过只有KITTI数据集提供了前景背景的分割groundtruth,因此在训练其他数据集时,忽略这个部分。
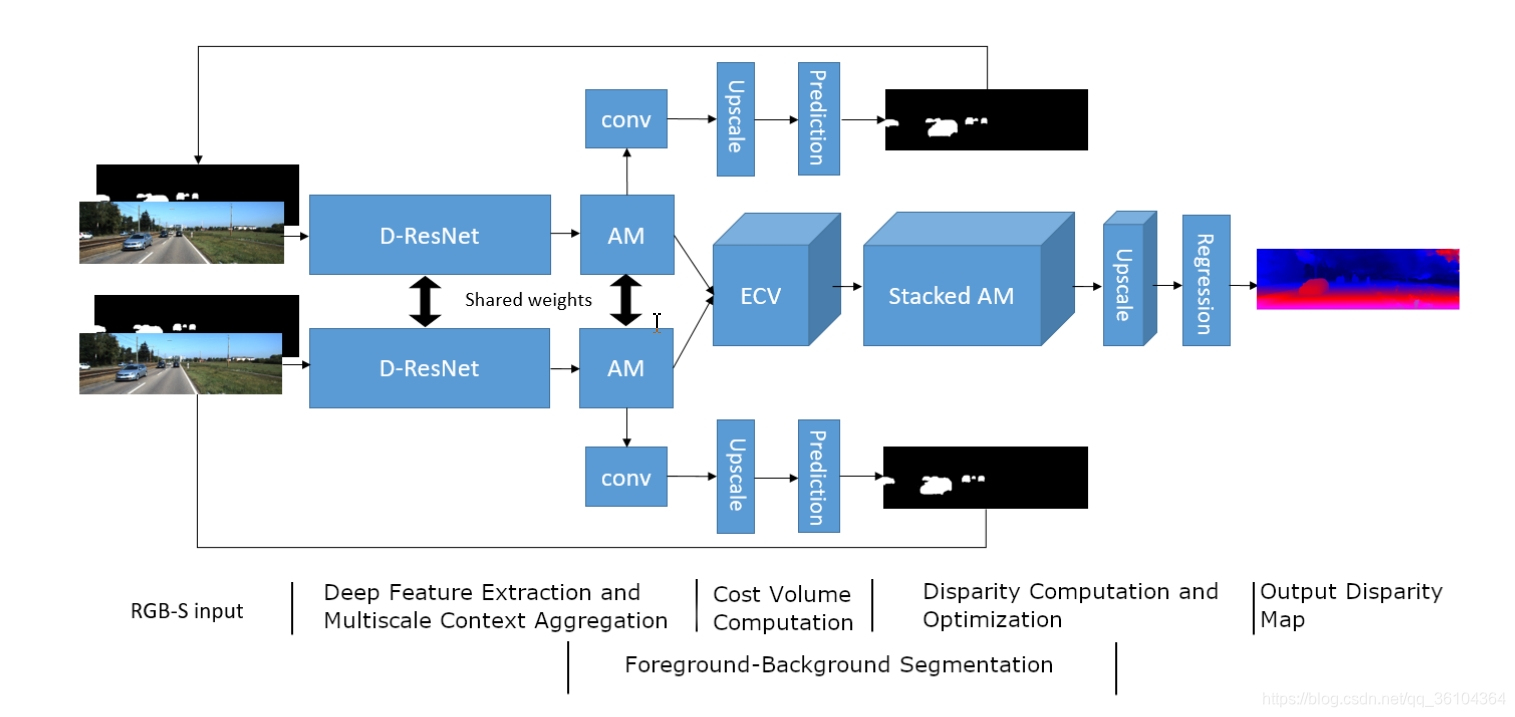
创新点
- 使用深度分离卷积代替普通卷积,改进了特征提取网络
- 设计了AM模块,用多层空洞卷积堆叠的方式获取不同尺度的特征信息,取代了SPP或者编码解码的结构
- 采用3种方式获取匹配代价卷,充分提取特征信息
- 增加前景背景分割部分,优化网络对前景目标的立体匹配效果
总结
这个网络现在在KITTI上排名第二,仅次于采用CSPN优化的网络,其思路也是非常明显和直接——增加通道数,增加特征信息,减少特征信息的损失。本文的所有改进都基本贯彻了这一思路。根据作者的试验,单纯的使用深度分离卷积代替普通卷积,虽然可以明显减少参数数量,但网络效果还是有一定程度下降,而通过增加通道数可以弥补这一问题,使效果有所提升,而参数没有增长。三种匹配代价卷构建方法,单独来看,计算像素差值的绝对值的方式效果最好,计算互相关性的方式效果最差,而三者结合起来的效果无疑是最好的,这也说明尽可能增加特征信息能够明显提升网络效果。用AM模块取代沙漏结构,则是减少特征信息的损失,而且可以看出AM模块的深度越深,空洞率的类别越多,立体匹配效果越好,说明网络的深度和空间尺度的丰富度还是对输出的结果有着重要的影响。最后,作者引入前景背景分割的方式改善前景目标的匹配效果的思路也非常值得借鉴,尤其是其采用的迭代训练的方法,用上一个epoch得到的结果帮助下一个epoch训练。
72.《Multi-scale Cross-form Pyramid Network for Stereo Matching》
网络名称:CFPNet
论文来源:CVPR2019
发表时间:2019年4月25日
核心思想
作者同样是在PSMNet网络的基础上进行了改进,在特征提取阶段设计了一种Cross Form Spatial Pyramid Pool(CFSPP) 模块取代了SPP模块,CFSPP就是将SPP与ASPP结合起来,对于每个尺度的特征图,都包含两个分支,一个分支使用平均池化得到不同尺度的特征图,在经过上采样统一尺寸,另一个分支则使用空洞卷积获得不同尺度的感受野,将两个分支得到的特征图级联起来,即得到一个尺度下的特征信息。作者使用的平均池化窗口尺寸分别是:64,32, 16,8,对应的空洞卷积率为:32, 16, 8, 4.在3D卷积部分,作者则使用一种MP-SOD取代了堆叠的沙漏结构,在MP-SOD中首先也是用步长为2的3D卷积逐层压缩特征图的尺寸,在恢复尺寸的过程中,并不是像沙漏结构那样逐层恢复,而是对于不同尺寸的特征图分别使用反卷积恢复到与匹配代价卷相同的尺寸,再将各个层恢复得到的特征图级联起来,经过 1 * 1 * 1 的卷积压缩通道数,得到最终的特征图输出。不仅如此作者还使用了两个分支来恢复图像尺寸,一个分支的反卷积核尺寸为3,另一个为5,最后将两条分支的输出结果级联起来,再进行上采样。上采样并没用采用双边线性插值的方式,而是使用反卷积的方式逐层恢复图像尺寸。视差回归方法与PSMNet相同。
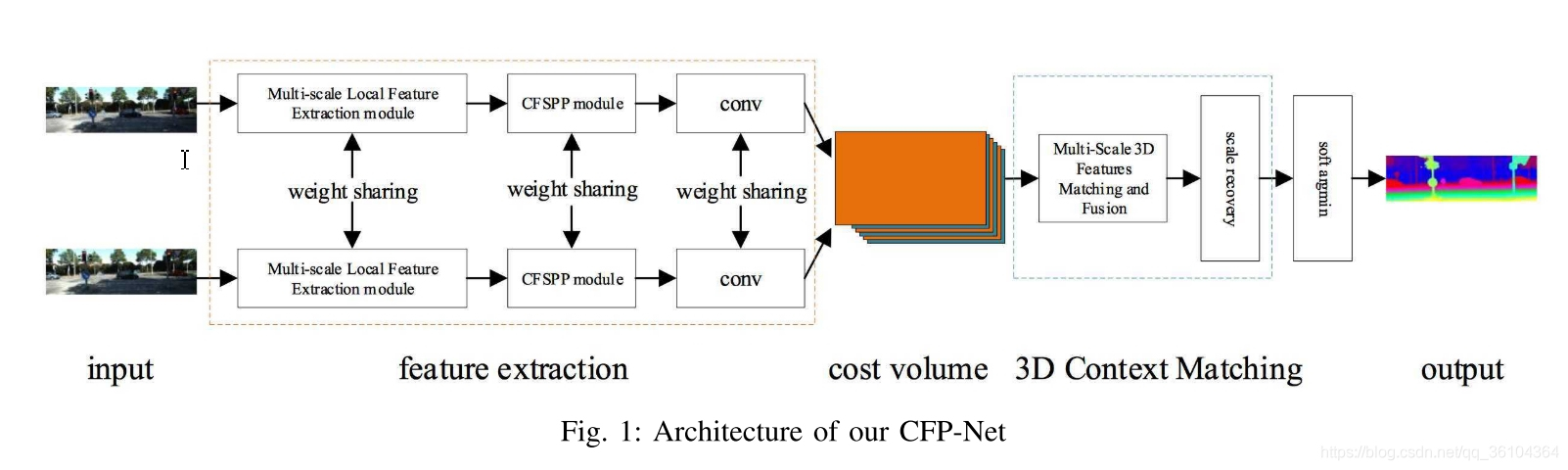
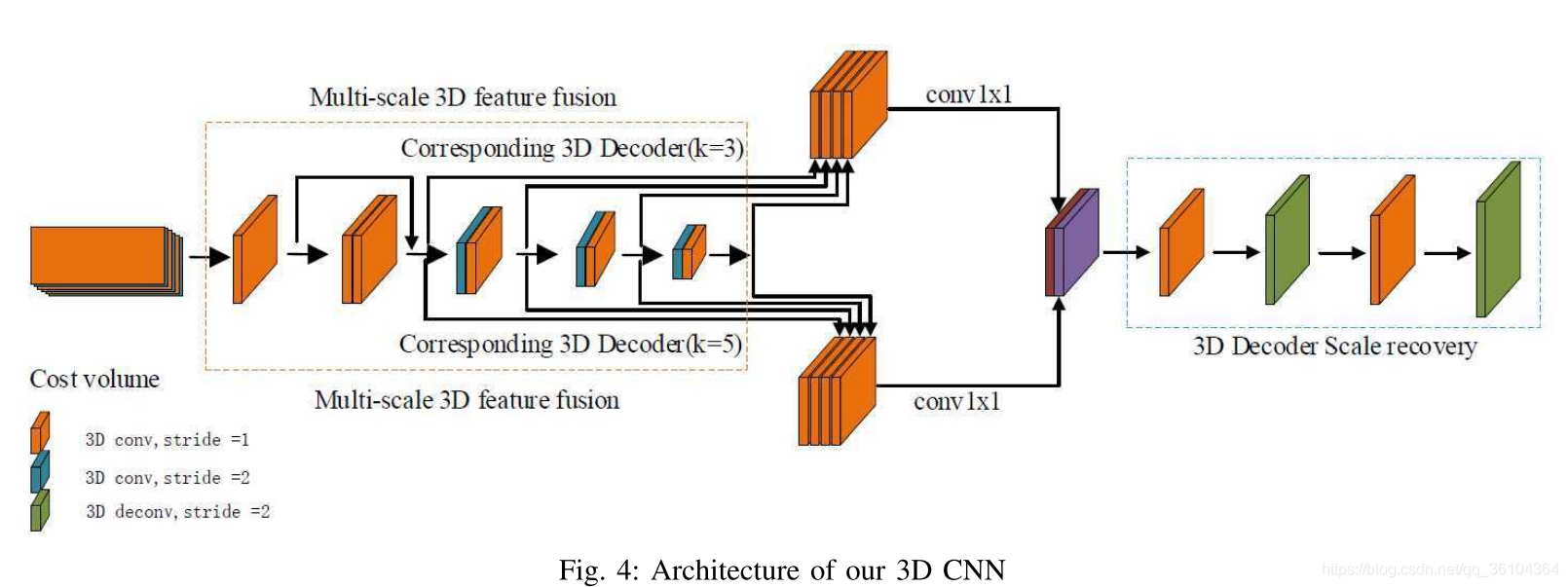
创新点
- 将ASPP和SPP结合起来构成CFSPP模块,用于多尺度特征信息提取
- 引入MP-SOD结构取代堆叠的沙漏结构
总结
本文还是在PSMNet做的修改,整体框架没有发生本质改变,CFSPP和MP-SOD的引入也只是应用型的创新。从实验结果来看,在KITTI2015数据集上,相对于PSMNet只提高了0.01%的准确率,处理一张图片的时间却上升到了0.9s,个人觉的这种改进有些得不偿失。
73.《Multi-Level Context Ultra-Aggregation for Stereo Matching》
网络名称:MCUA
论文来源:CVPR2019
核心思想
本文主要是对PSMNet中特征提取网络进行修改,思路参照了DenseNet的结构,将每层网络的输出逐像素累加起来,传输给下个网络层,形成一种稠密的不同层级之间的连接。在此基础上,作者又增加了一个子网络分支,其主要是利用池化缩小图像尺寸,扩大感受野,获取多尺度的特征信息。其特征提取网络结构如图所示
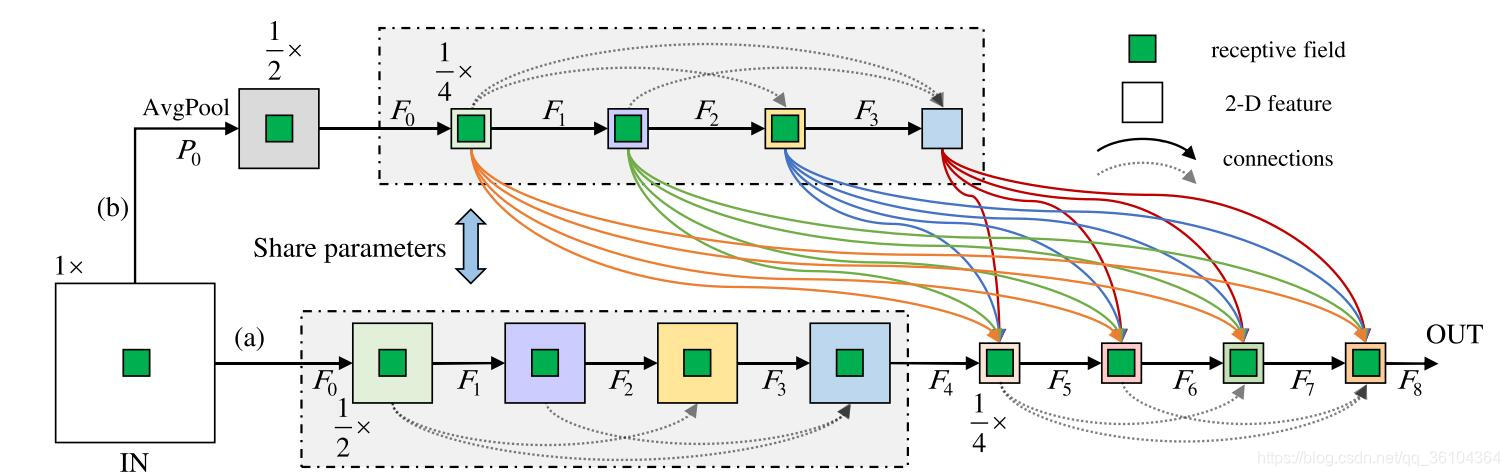
如图所示,主干网络分支(a)基本保留了PSMNet中特征提取网络的结构,共包含9个卷积组,0-2是三层32通道的浅层网络,3-6是四组残差卷积组,7是包含SPP结构的卷积组,8是将通道压缩为32的卷积组。不同点在于,将前面每个网络的输出(尺寸必须一致)逐像素累加起来,再作为输入特征图输入下一层网络,如图中虚线所示,这形成了一种Inter-level Combination。如果通道数不一致则利用1 * 1的卷积层调整通道数,这一结构参考了DenseNet的思路。子网络分支(b)结构与主干网络的前四层完全一样,并且权值共享,区别在于对输入图像利用2 * 2的平均池化层缩小输入尺寸,变相的增加了卷积层的感受野。将每一层的输出同样通过跳跃连接输入到主干网络的后四层中,形成一种Intra-level Combination。
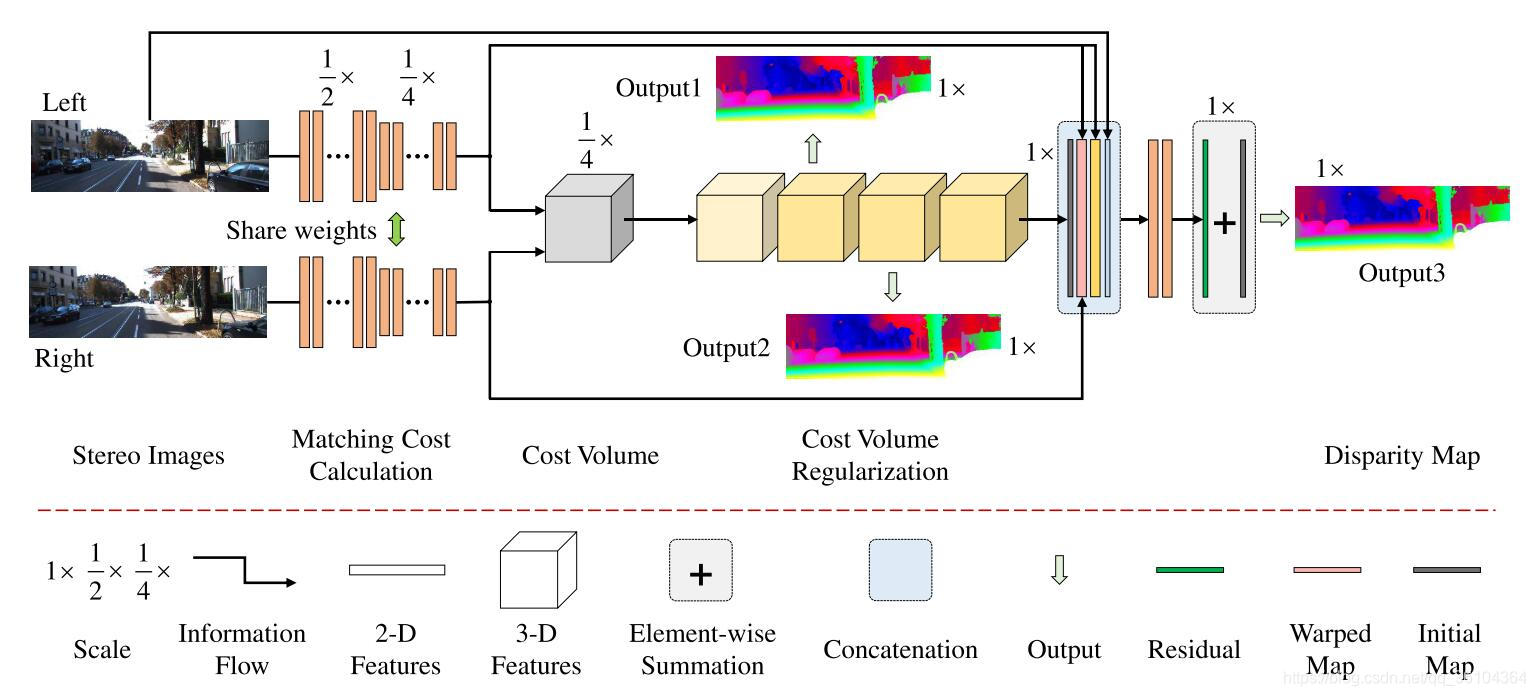
整体结构如上图所示,特征提取完成后匹配代价卷和3D卷积部分并没有改变,但在得到初始视差图之后,作者参照iResNet网络的思路增加了一个优化网络部分,利用左右通道的特征图和视差图做Warp操作后,再利用卷积得到残差图,将残差图和初始视差图叠加得到最终的视差图。
创新点
- 借鉴DenseNet网络思想,增加不同层级之间的稠密连接
- 增加子网络分支,利用池化操作扩大感受野,通过跳跃连接丰富特征信息
- 参考iResNet网络,构建多级网络,对初始视差图进行优化
总结
整篇文章没有非常出彩的创新点,大部分是结构的引入和借鉴,根据实验来看还是取得了一定的进步。说明通过丰富特征信息,增加网络深度,增加训练次数还是能够在一定程度上提高网络的表现,但对于浅层网络其开发的潜力相对而言就非常有限了,即使经过多次训练迭代,效果提升也有限。但对于本文采用逐像素累加的方式来融合特征信息,我不确定这种方式与级联后再卷积(加权求和)相比谁更合适。
74.《GA-Net: Guided Aggregation Net for End-to-end Stereo Matching》
网络名称:GA-Net
论文来源:CVPR2019
发表时间:2019年4月13日
核心思想
本文是将传统算法中的代价聚合方法引入到立体匹配网络中,以取代简单粗暴的3D卷积聚合方法。作者提出了能够进行反向传播计算的SGM和局部代价聚合算法,使得网络可以进行端到端的训练且可以利用并行计算加速。首先,介绍一下基于深度学习的SGM算法(SGA,Semi-Global Guided Aggregation)和局部代价聚合算法(LGA,Local Guided Aggregation)。SGA是沿某个方向将代价值按照一定的权重累加起来,得到一个点的聚合代价值,也就是说
p
p
p点处的代价值,其实是由某个方向上的代价值聚合而来,SGA的数学表达式如下:
C
r
A
(
p
,
d
)
=
s
u
m
{
w
0
(
p
,
r
)
C
(
p
,
d
)
w
1
(
p
,
r
)
C
r
A
(
p
−
r
,
d
)
w
2
(
p
,
r
)
C
r
A
(
p
−
r
,
d
−
1
)
w
3
(
p
,
r
)
C
r
A
(
p
−
r
,
d
+
1
)
w
4
(
p
,
r
)
max
C
r
A
(
p
−
r
,
i
)
C_r^A(p,d)=sum\left\{\begin{matrix} w_0(p,r)C(p,d)\; \; \; \; \; \; \; \; \; \; \; \; \; \; \\ w_1(p,r)C_r^A(p-r,d)\; \; \; \; \; \; \\ w_2(p,r)C_r^A(p-r,d-1)\\ w_3(p,r)C_r^A(p-r,d+1)\\ w_4(p,r)\max C_r^A(p-r,i) \end{matrix}\right.
CrA(p,d)=sum⎩
⎨
⎧w0(p,r)C(p,d)w1(p,r)CrA(p−r,d)w2(p,r)CrA(p−r,d−1)w3(p,r)CrA(p−r,d+1)w4(p,r)maxCrA(p−r,i)
式中
C
r
A
(
p
,
d
)
C_r^A(p,d)
CrA(p,d)表示在像素
p
p
p处,视差为
d
d
d时,
r
r
r方向上的聚合代价;
C
(
p
,
d
)
C(p,d)
C(p,d)表示代价聚合前,像素
p
p
p处,视差为
d
d
d时的代价;
C
r
A
(
p
−
r
,
d
)
C_r^A(p-r,d)
CrA(p−r,d)表示沿
r
r
r方向,像素
p
p
p的上一个点处,在视差为
d
d
d时的匹配代价,例如
r
r
r表示右方向,那么
C
r
A
(
p
−
r
,
d
)
C_r^A(p-r,d)
CrA(p−r,d)就是像素
p
p
p向左平移一个点处的匹配代价;同理,
C
r
A
(
p
−
r
,
d
−
1
)
,
C
r
A
(
p
−
r
,
d
+
1
)
C_r^A(p-r,d-1),C_r^A(p-r,d+1)
CrA(p−r,d−1),CrA(p−r,d+1)则表示视差为
d
−
1
,
d
+
1
d-1, d+1
d−1,d+1时的代价;
i
i
i表示整个视差范围内,除去
d
,
d
−
1
,
d
+
1
d,d-1, d+1
d,d−1,d+1之外其他的视差值,从中选择代价最大值。
w
0
∼
4
(
p
,
r
)
w_{0\sim 4}(p,r)
w0∼4(p,r)是权重值,利用一个卷积网络得到,并normalize处理保证
∑
i
=
0
4
w
i
(
p
,
r
)
=
1
\sum_{i=0}^4 w_i(p,r)=1
∑i=04wi(p,r)=1,
w
0
∼
4
(
p
,
r
)
w_{0\sim 4}(p,r)
w0∼4(p,r)只与像素位置和方向有关,也就是说对于不同的视差值
w
0
∼
4
(
p
,
r
)
w_{0\sim 4}(p,r)
w0∼4(p,r)是相同的。本文选择的方向为上下左右四个方向,最后选择四个方向上的最大值,作为聚合代价值。
LGA则是将
p
p
p点处邻域范围内的所有点的代价值聚合起来,不仅聚合当前视差下的代价值,还要将相邻视差下的代价值聚合起来,LGA的数学表达式如下:
C
A
(
p
,
d
)
=
s
u
m
{
∑
q
∈
N
p
w
0
(
p
,
q
)
C
(
p
,
d
)
∑
q
∈
N
p
w
1
(
p
,
q
)
C
(
p
,
d
−
1
)
∑
q
∈
N
p
w
2
(
p
,
q
)
C
(
p
,
d
+
1
)
C^A(p,d)=sum\left\{\begin{matrix} \sum_{q \in N_p}w_0(p,q)C(p,d)\; \; \; \; \; \;\\ \sum_{q \in N_p}w_1(p,q)C(p,d-1) \\ \sum_{q \in N_p}w_2(p,q)C(p,d+1)\\ \end{matrix}\right.
CA(p,d)=sum⎩
⎨
⎧∑q∈Npw0(p,q)C(p,d)∑q∈Npw1(p,q)C(p,d−1)∑q∈Npw2(p,q)C(p,d+1)
式中
w
i
(
p
,
q
)
w_i(p,q)
wi(p,q)表示像素
p
p
p和
q
q
q之间的聚合权重。本文中邻域范围为
5
×
5
5\times 5
5×5的矩形范围,即对于
p
p
p点而言,其代价值是由
3
×
5
×
5
=
75
3\times 5\times 5=75
3×5×5=75个代价值加权聚合而来,权重同样是利用卷积网络学习得到,因为每个点都对应75个权重,因此权重网络包含75个特征通道。
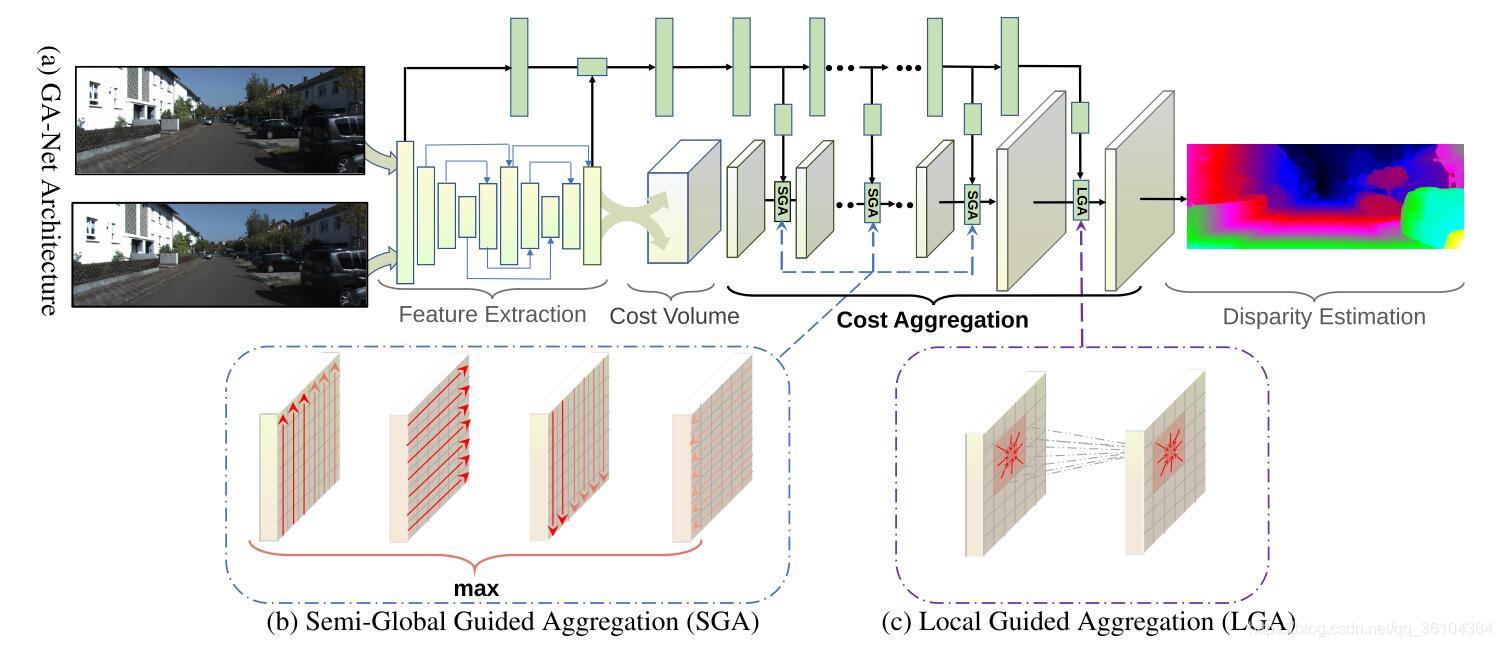
网络的整体结构如上图所示,特征提取网络采用了带有稠密跳跃连接的堆叠沙漏结构,匹配代价卷的构建方法与PSMNet相同,在代价聚合部分,每经过一个3D卷积层,就增加一个SGA层,在进行视差回归之前增加一个LGA层。可以看到在主干网络上面还有个小的分支网络,用于学习SGA和LGA的权重参数,权重分支网络的输入时特征提取网络第一层和最后一层输出的特征图,中间利用2D卷积进行信息提取,并利用切片,变形,正则化等操作,使其满足SGA和LGA的需求。最终利用视差回归得到视差图。
创新点
- 将传统算法中的SGM和局部代价聚合算法引入到立体网络中来,使其能够成为一种可以训练的网络层
- 改进了特征提取网络结构,并大幅减少3D卷积网络层数,使得运算量大大减少了
- 利用权重分支网络学习SGA和LGA的权重,使其具有更强的适应性
总结
这是一篇典型的利用传统算法思想优化深度学习网络的文章,其将传统算法改编成可以进行训练和学习的网络,使得深度学习不再是一味的简单粗暴的增加深度和信息量,而是引入了一定的约束,按照特定的数学规则进行优化,充分结合了传统算法和深度学习的优势。其思路与CSPN有异曲同工之妙(都是来自百度人工智能实验室),值得进一步学习和研究。
75.《End-to-End Multi-Task Learning with Attention》
网络名称:MTAN
发表时间:2019年4月5日
核心思想
这篇文章设计了一种多任务融合的网络,可同时实现语义分割,深度估计和表面法向量(surface normal)任务。其网络包含一个共享分支用于提取公共的特征信息,对于每个任务都有各自独立的任务分支,各个任务分支的结构是相同的都是由若干个注意力模块构成的。对于共享分支,本文采用了SegNet的结构,编码器部分是VGG-16,解码器部分则是一个镜像的VGG-16。编码器和解码器中的每个卷积组都对应一个注意力模块,其工作原理如下:首先将卷积组中第一层卷积输出的结果与上一个注意力模块输出的结果级联起来,然后经过两个1 * 1的卷积层(第一层带有BN和ReLU,第二层带有BN),再利用sigmoid获得注意力掩码图,将掩码图与卷积组中的最后一层卷积输出做逐元素相乘,再经过一个3 * 3的卷积得到该注意力模块的输出,最后利用池化层调整图像尺寸。本质上就是利用两个1*1的卷积和sigmoid函数计算每个特征通道上每个像素点上的权重值,然后与对应的特征图做逐元素的相乘,相当于赋予权重,如果某个点重要,其权重值应该接近1,如果某个点在该任务中没有作用,其权重值应该接近0.解码部分的注意力模块结构相似,只不过先利用双边上采样恢复图像尺寸。
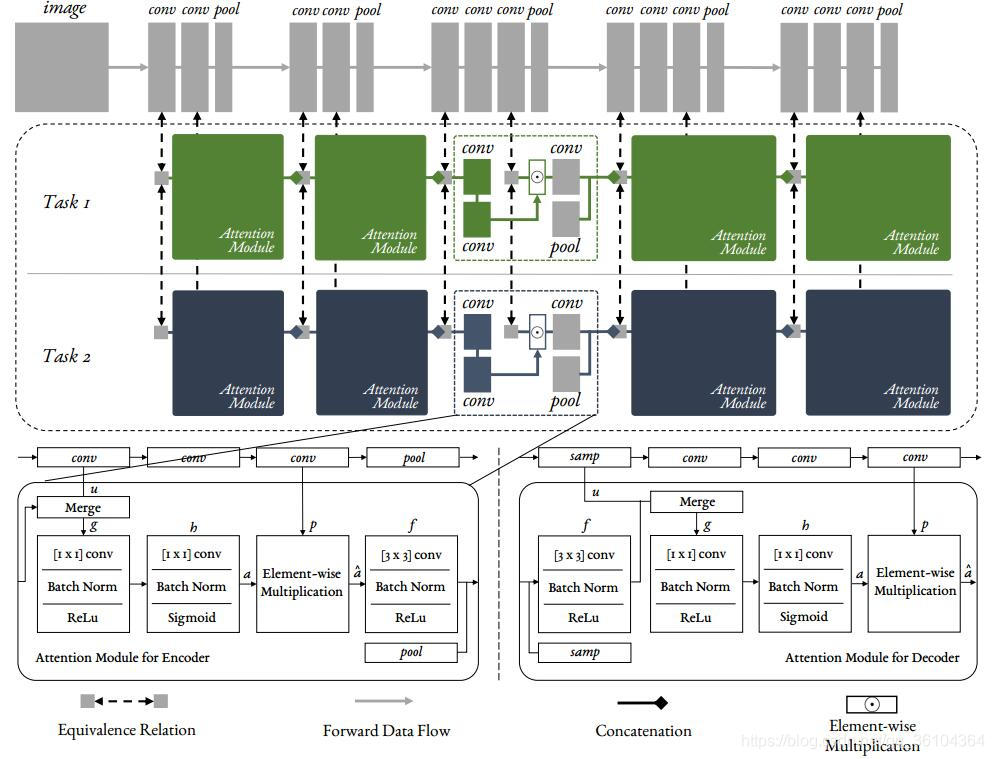
在损失函数设计方面,本文提出了一种 Dynamic Weight Average (DWA)的方法用于自动优化不同任务之间的损失权重,权重计算方法如下:
λ
k
(
t
)
=
K
e
(
w
k
(
t
−
1
)
/
T
)
∑
e
(
w
i
(
t
−
1
)
/
T
)
\lambda _{k}\left ( t\right )=\frac{Ke^{\left ( w_{k}(t-1)/T\right )}}{\sum e^{\left ( w_{i}(t-1)/T\right )}}
λk(t)=∑e(wi(t−1)/T)Ke(wk(t−1)/T)
其中:
w
k
(
t
−
1
)
=
L
k
(
t
−
1
)
L
k
(
t
−
2
)
w_{k}(t-1)=\frac{L_k(t-1)}{L_k(t-2)}
wk(t−1)=Lk(t−2)Lk(t−1)
K表示任务数量本文取3,T是温度参数本文取2,
L
k
L_k
Lk表示第k个任务的损失,t表示迭代次数。
创新点
- 提出一种新的多任务融合架构,采用注意力机制为不同的视觉任务选择不同的特征信息
- 设计了一种新的损失函数权重计算方法
总结
本文设计了一种带有注意力机制的多任务融合网络,共享网络用于提取公共特征,任务分支网络用于从中选择有用的特征信息,但是这种方法需要对每个特征通道的每个点都计算权重并逐元素相乘,对于内存有比较大的消耗,可能这也是作者缩小训练集图片尺寸的原因吧。作者后来提到的一种动态权重方法,就实验结果来看并没有呈现特别出众的作用,在很多情况下甚至不如直接三个损失相加的方式。
76.《MSDC-Net: Multi-Scale Dense and Contextual Networks for Automated Disparity Map for Stereo Matching》
Learning to Fuse Things and Stuff
Jie
核心思想
本文也是在GCNet的基础上进行改进的立体匹配网络,其改进主要有两点:特征提取网络采用Dense-Net结构进行多尺度特征提取与融合;3D卷积网络采用3D残差网络结构。具体而言,特征提取网络可以分为两个部分:多尺度特征提取和多尺度特征融合。多尺度特征提取共包含3组特征提取块,每个特征提取块中包含一个步长为2的5 * 5的卷积和一个Dense块,Dense块是来自于DenseNet网络是在ResNet基础上增加更多跳跃连接构成的一种baseline,之前的笔记有过介绍。将3个特征提取块获得的特征图通过填充0的方式恢复成统一尺寸,再级联起来。多尺度特征融合模块就是对级联起来的特征图进行卷积操作,其结构与特征提取块完全相同。

3D卷积部分并没有选择使用3个沙漏结构堆叠的形式,而是参考ResNet构建了一个3D 残差网络,其结构也比较简单,编码阶段随着卷积图像尺寸缩小,通道数增加,每两个卷积组之间带有跳跃连接。解码阶段随着反卷积图像尺寸扩大,通道数减少,卷积组之间带有跳跃连接,并且与对应尺寸的解码器之间也存在跳跃连接。最后通过反卷积恢复图像尺寸,回归得到视差图。
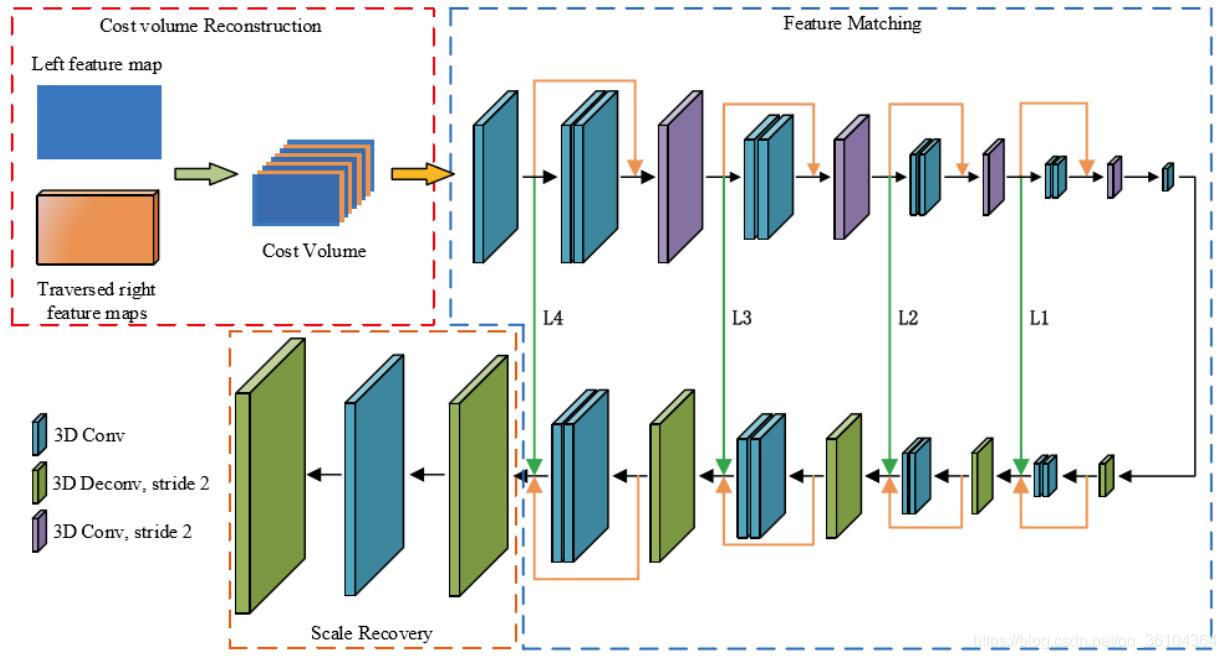
比较有趣的是,本文的损失函数在设置平滑项的时候采用了以3为阈值,这是与立体匹配任务中3像素误差所对应的,公式如下:
S
m
o
o
t
h
L
1
(
x
)
=
{
1
3
x
3
∣
x
∣
<
3
∣
x
∣
o
t
h
e
r
w
i
s
e
Smooth_{L1}\left ( x\right )=\left\{\begin{matrix} \frac{1}{3}x^{3} & \left | x\right |<3\\ \left | x\right | & otherwise \end{matrix}\right.
SmoothL1(x)={31x3∣x∣∣x∣<3otherwise
创新点
- 特征提取部分引入Dense卷积块,将多个尺度的特征图通过填充0的方式统一尺寸,再融合起来
- 3D卷积结构采用了残差网络结构
总结
本文在特征提取部分采用DenseNet结构虽然其特征提取的效果可能是高于ResNet的,但带来的计算成本也较高,网络层数较多,效果提升有限。3D卷积部分也没有很大的改进,整体来说文章中规中矩,没有令人耳目一新的亮点。最后对于损失函数的小改动还有点意思。
77.《Pyramid Feature Attention Network for Saliency detection》
论文来源:CVPR2019
发表时间:2019年4月4日
核心思想
本篇文章是做显著性检测的,显著性检测就是将图片中的重要物体从背景中区分出来,做一个二分类,有点类似与前景背景的分割。作者提出一种包含注意力机制的金字塔特征提取网络,作者认为浅层网络包含更多细节的结构信息,而深层网络包含更多的语义信息,而采用同样的方式处理深层网络和浅层网络是不适当的,而且在众多特征中有些特征会对结果产生不好的影响,因此作者设计了两种注意力机制,对于深层网络采用通道注意力机制,为特征通道赋予权重,而浅层网络则采用空间注意力机制,为每个像素分配权重。
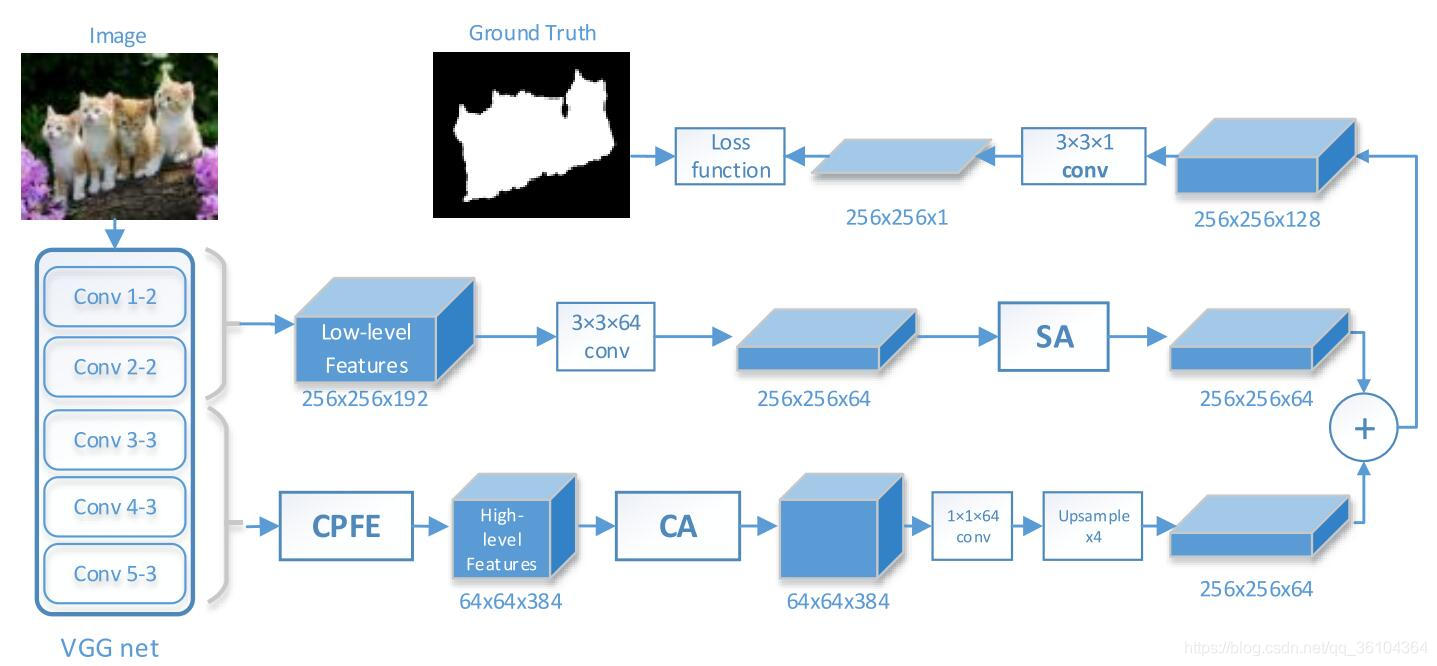
首先,以VGG-16作为backbone,前两个卷积组提取的特征作为浅层特征,后三个卷积组提取的特征作为深层特征。对于3组深层特征图分别经过一个类似ASPP结构的上下文特征提取器,第一个卷积核为1 * 1,后面三个卷积核为3 * 3,扩张率分别为3,5,7.将其得到的特征图级联起来,再利用1 * 1的卷积将通道压缩。由于3组深层特征图的尺寸不同,对于较小的两组都通过上采样的方式统一尺寸,并级联起来作为金字塔特征提取模块的输出。对于输出的深层特征图采用通道注意力机制赋予权重,计算方法与SENet相同,池化后经过两个全连接层,再用sigmoid函数规范化处理,最后对应相乘。
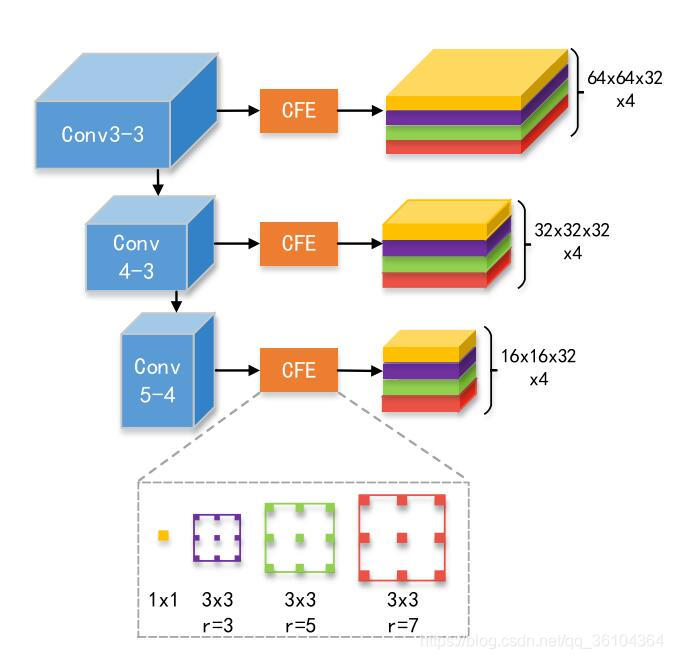
而对于浅层特征信息,则采用了空间注意力机制赋予权重,具体的方法是对于经过通道注意力机制处理过的深层特征图,分别采用1 * k和k * 1的卷积核进行卷积操作,并将通道数压缩为原来的一半,然后在分别采用k * 1和 1 * k的卷积核进行卷积操作,并将通道数压缩为1,最后将两个特征图叠加起来,并利用sigmoid函数做规范化处理后作为权重图,将其与浅层特征图 逐元素相乘得到加权过后的特征图。将浅层特征图与深层特征图级联后,经过3*3的卷积将通道压缩为1,得到最终的输出。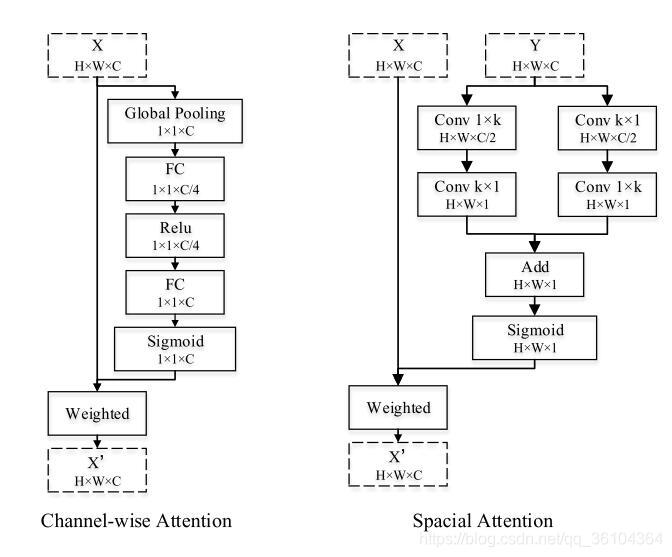
为了保持结果在边缘区域的准确性,作者设计了一个包含边缘约束的损失函数,首先对于groundtruth和网络输出的分割图使用拉普拉斯算子进行边缘提取,得到边缘图。对于边缘图使用交叉熵损失函数计算边缘损失,并与显著性检测的损失函数相加得到最终的损失函数。
创新点
- 设计了一种金字塔特征提取模块,基本上沿用了ASPP结构的思路
- 采用了通道注意力机制和空间注意力机制分别对深层特征信息和浅层特征信息进行处理
- 设计了一种带有边缘约束的损失函数
总结
显著性检测可以看做一种简单的语义分割任务,他同样关注深层的语义信息与浅层的细节结构信息,如何将二者合理的提取并融合起来是一个非常关键的问题。作者提出一种很重要的想法就是用不同的方法分别处理浅层特征和深层特征,尤其是空间注意力机制是我之前从未见过的处理方法,不知这种使用1维卷积核处理的方式有何好处,还有一个疑问是使用一张注意力图为所有通道的特征图进行加权是否合适?在最后将浅层特征与深层特征融合的地方使用了简单的级联方式,是否可以设计一个更加精细的结构?
78.《Learning to Fuse Things and Stuff》
网络名称:TASCNet
论文来源:CVPR2019
发表时间:2018年12月4日
核心思想
该文章是解决全景分割问题的,题目中出现的Things指的是实例分割,而Stuff表示语义分割部分。文章指出语义分割任务通常利用的区分度高的纹理和上下文特征,而实例分割更依赖物体的空间形状和外表特征。由于这一基础的区别,现有的全景分割算法通常使用两个独立的网络分别完成语义和实例分割任务,再用后处理的方式将两者融合起来。而本文作者则希望用一个统一的网络实现两个任务,并且能够改进分割的效果。作者的思路是通过实例分割与语义分割之间的一致性约束来提高分割效果。具体的结构如下:首先用ResNet+FPN组成backbone用于特征提取,在此基础上增加并行的两个子网络——Things和Stuff,Things网络基本沿用了Mask R-CNN的网络结构,此处不再展开介绍。对于Stuff网络则是将FPN输出的不同尺度的特征图先经过卷积层将通道数压缩为128,在使用组规则化(GN)进行处理,再经过一个3 * 3的卷积之后,将输出的特征图上采样到统一尺寸,再堆叠起来,最后经过一个卷积层输出分割结果。作者的研究重点在于如何利用实例分割与语义分割之间的一致性上,作者试图通过一个中间置信度掩码来增强共享的表征,该掩码反映了每个任务认为哪些像素是things,哪些像素是stuff。语义分割获取掩码图的方式非常简单,对于输出分割的图的对数值增加一个0.5的门限值,低于这个值的全部置为0,对于剩下的像素点,如果他的标签是thing的则保留,如果标签是stuff的则置为0,这样图中所有的stuff像素被置为0,置信度高的物体保留下来。对于实例分割任务则更为复杂,由于在分割过程中首先会提取感兴趣区域ROI,对于每个ROI区域都将其前景背景分割开来,然后利用0.5的门限值获取每个感兴趣区域掩码图,最后将每个感兴趣区域累加起来恢复到原图的尺寸。两种分割网络都获得了对应的掩码图,图中所有的things像素是1,而stuff像素则是0,为了增强二者之间的一致性,作者还利用一个L2损失函数来约束他们之间的差异。利用这个掩码图就可以知道那些像素是属于thing,那些像素属于Stuff,这样可以选择对应分割任务输出的结果进行融合,其分割效果更好。
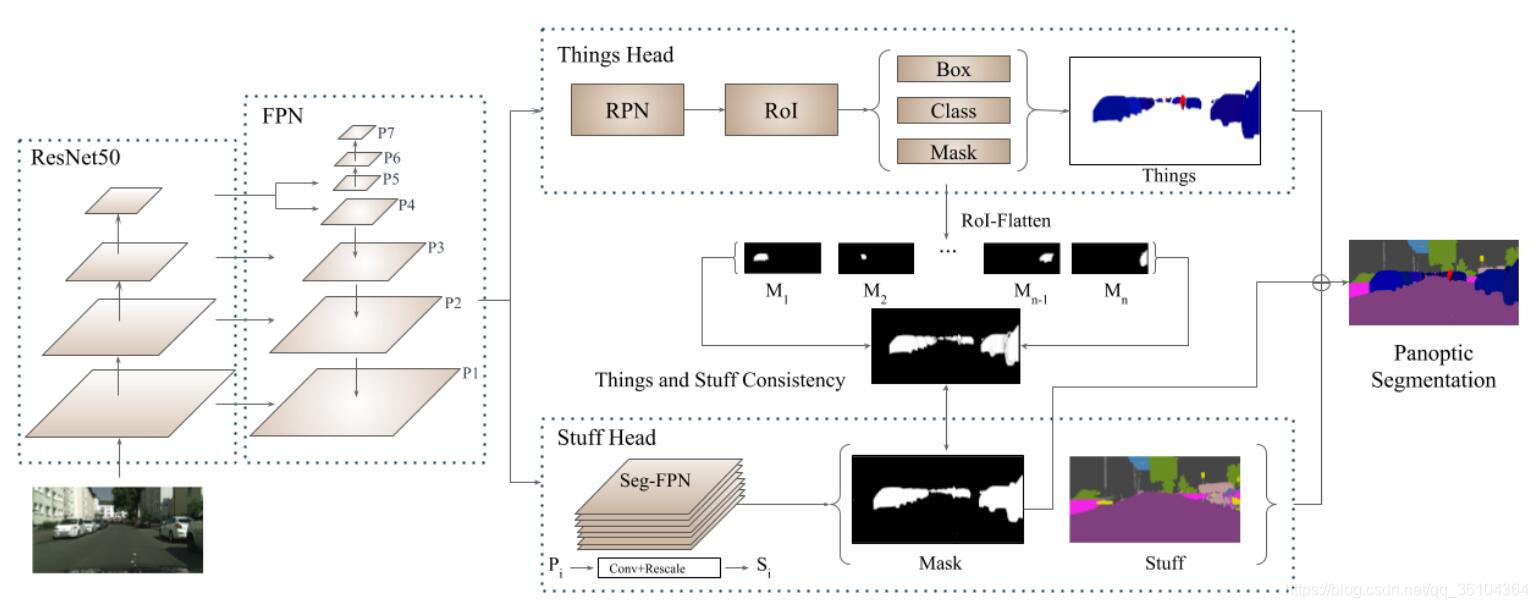
创新点
- 提出一种新型的全景分割网络,将语义分割和实例分割任务结合起来,提高了各自任务的表现
- 利用两种分割结果的一致性引导融合任务,提高了全景分割的效果
总结
说实话这篇文章我还没有完全理解,主要是对于全景分割,实例分割的许多概念还不是很了解。整体的感觉是分别利用实例分割和语义分割得到对应的掩码图,然后再用损失函数约束这两个掩码图之间的差异。这个掩码图表示了那些像素是属于things的,那些像素是属于stuff的。在融合得到全景分割结果的时候,对于属于things的像素则采用实例分割的结果,对于属于stuff的像素则采用语义分割的结果,这样融合的效果会得到提升。
79.《Edge-guided Non-local Fully Convolutional Network for Salient Object Detection》
网络名称:ENFNet
发表时间:2019年8月7日
核心思想
本文是利用边缘引导来做显著性目标检测的,作者提出现有的利用全卷积神经网络的方法,通过连续的卷积核池化操作虽然可以增加感受野范围,提高表征能力但由于特征图尺寸的缩小,损失了许多细节结构信息,导致边缘区域的恶化。许多研究人员也试图引入边缘信息的先验知识,但通常都是在通道这个维度考虑的,而本文设计的边缘引导模块不仅包含特征通道维度,还包含空间维度。整体结构同样以FCN作为主干网络,在编码器的最后增加3层卷积用于提取全局信息
X
G
X^G
XG。利用现有的边缘检测算法得到边缘图,对边缘图进行4个卷积层,文章称为Condition Network(CN),获得边缘特征信息
X
i
E
X^E_i
XiE,将其与主干网络中每个卷积组输出的特征信息
X
i
X_i
Xi融合起来,得到融合特征
X
i
F
X^F_i
XiF.融合过程采用了边缘引导模块,首先用两个卷积组分别对
X
i
E
X^E_i
XiE进行卷积,得到
γ
\gamma
γ和
β
\beta
β,再将
γ
\gamma
γ与
X
i
X_i
Xi相乘,再与
β
\beta
β相加得到
X
i
F
X^F_i
XiF(此处文中表述存在前后矛盾,我按照自己理解是这个过程)。值得注意的是为了减少参数,对于每个卷积组,其采用的
X
i
E
X^E_i
XiE是来自同一个CN模块,而每个卷积组的
X
i
X_i
Xi其尺寸是不同的,随着卷积加深,尺寸越来越小。因此在获取
γ
\gamma
γ和
β
\beta
β时需要通过带步长的卷积进行尺寸调整。由于在做显著性目标检测时,前景和背景的对比度是一个关键的信息,因此为了突出对比度信息,作者对
X
i
F
X^F_i
XiF进行3*3的平均池化,再用
X
i
F
X^F_i
XiF减去平均池化后的特征图,得到对比度特征图
X
i
C
X^C_i
XiC,将
X
i
F
X^F_i
XiF和
X
i
C
X^C_i
XiC,还有来自编码器或者上一级解码器的特征图
D
i
+
1
D_{i+1}
Di+1级联起来,通过反卷积逐步恢复图像尺寸,获取局部信息
X
L
X^L
XL。最后,将全局信息
X
G
X^G
XG与局部信息
X
L
X^L
XL融合起来(没有介绍如何融合的,全局信息
X
G
X^G
XG尺寸应该很小,而恢复尺寸得到的局部信息
X
L
X^L
XL尺寸较大,直接拼接应该不行),经过softmax层得到结果。损失函数方面在交叉熵损失函数的基础上,增加了边缘信息损失项,利用IOU来计算边缘损失。
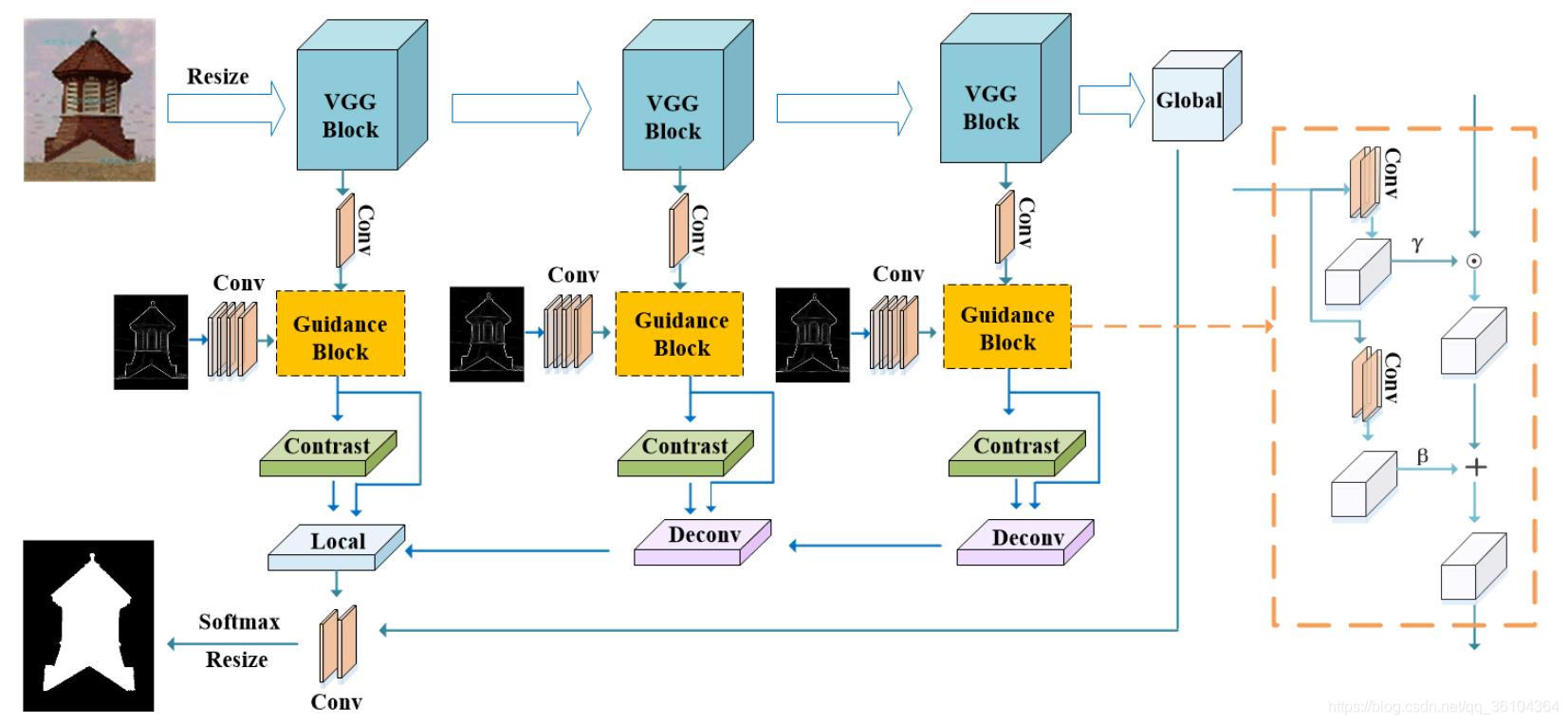
创新点
- 引入了边缘信息的约束,设计的边缘引导模块既包含特征通道的约束,又包含空间尺度上的约束
- 增加了对比度信息
- 将全局信息和局部信息相结合
总结
本文使用边缘信息改进显著性目标检测的效果与我的想法不谋而合,而这一思想最重要的点就是如何将边缘信息与其他的特征信息结合起来,最后能够改善边缘区域的分割效果。本文是通过一个边缘引导模块来实现这一目的的,这一结构最早是商汤科技用于超分辨率图像恢复的,可见他在引导图像方面具有一定的意义和价值。
80.《Local detection of stereo occlusion boundaries》
论文来源:CVPR2019
核心思想
该篇文章提出一种用于检测立体视觉中遮挡边缘的算法,作者指出现有的检测遮挡边缘的算法通常是根据表面纹理和颜色强度信息来识别边界的,但在许多情况下,前景和背景之间并没有明显的纹理或颜色差异。而作者提出的方法是利用匹配代价卷中的局部特性来识别边界的,无论前景和背景之间是否有纹理和颜色区别,其在匹配代价卷中的表现总是不同的,利用这一点可以将遮挡边缘检测出来。作者还将常见的遮挡情况分成了几类,分别介绍了不同情况下,边界区域在匹配代价卷中的差异。作者在此基础上提出一种用于检测遮挡边缘的网络, 这一网络包含三个部分:变换层,检测层和反变换层。变换层首先对匹配代价卷中的各个图层做shear变换,具体来说就是:
C
′
(
x
,
y
,
d
,
s
)
=
C
(
x
+
d
,
y
,
d
,
s
)
C'(x,y,d,s)=C(x+d,y,d,s)
C′(x,y,d,s)=C(x+d,y,d,s)之后在视差维度上做一次累积最小值的操作:
C
c
m
(
x
,
y
,
d
,
s
)
=
m
i
n
d
′
<
d
C
′
(
x
,
y
,
d
′
,
s
)
C_{cm}(x,y,d,s)=min_{d'<d}C'(x,y,d',s)
Ccm(x,y,d,s)=mind′<dC′(x,y,d′,s)
对于视差d的所有像素点,选择视差小于d的所有像素点中匹配代价最小的点来作为当前视察条件下的匹配代价值。将
C
′
C'
C′和
C
c
m
C_{cm}
Ccm级联起来作为检测层的输入。检测层是一个3D版本的HED边缘提取网络,共包含3个层级,每个层级之间有一个池化层分隔开,最后三个层的输出通过上采样恢复尺寸后融合起来作为最后的输出,输出的结果是各个视差条件下的边缘概率得分图
B
^
(
H
,
W
,
D
)
\hat{B}(H,W,D)
B^(H,W,D),将这一得分图经过反shear变换得到最终的输出
B
(
H
,
W
,
D
)
B(H,W,D)
B(H,W,D)。
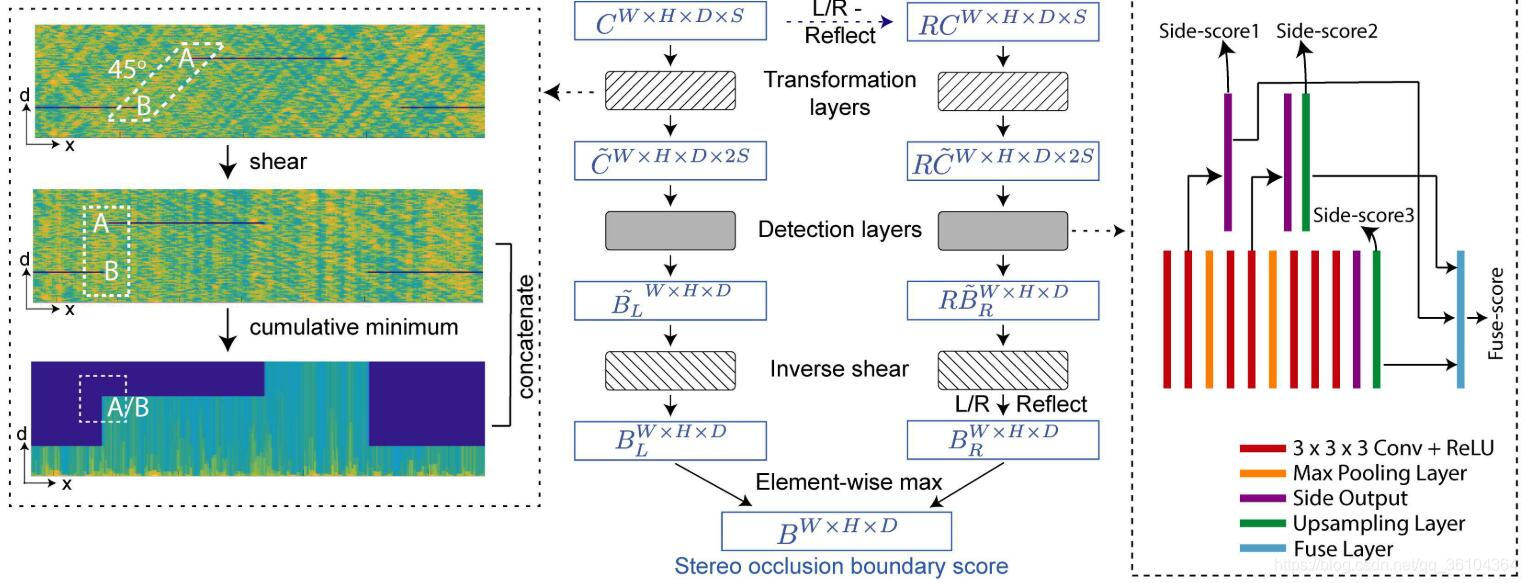
创新点
- 提出一种立体视觉中遮挡边缘检测的算法
- 分析了多种遮挡情况在匹配代价卷中的不同表现
总结
作者不是直接图片信息进行边缘检测,而是利用匹配代价卷中的局部信息来识别边缘,此处的匹配代价卷不是GCNet和PSMNet中的匹配代价卷,而是类似孪生网络中用图块匹配得到的匹配代价卷。另一方面与常见的网络尽量扩大网络感受野的思路不同,本文作者提出希望采用更小的感受野,一方面可以改善细小的前景结构的提取能力,另一方面可以提高对于不同类型立体图像的泛化能力。
81.《Learning monocular depth estimation infusing traditional stereo knowledge》
网络名称:monoResMatch
论文来源:CVPR2019
核心思想
本文提出一种自监督实现单目深度估计的网络,其思路也非常简单,将单目深度估计转化成立体匹配问题,再用立体匹配网络进行视差估计。整个网络结构包含以下几个部分:初级特征提取网络,初级视差估计网络,视差优化网络。初级特征提取网络是由一个简单的沙漏型结构构成的,对左图提取高纬度的特征图
F
L
0
F^0_L
FL0。初级视差估计网络则是一个带有跳跃连接的多尺度的沙漏型结构,输入左特征图
F
L
0
F^0_L
FL0输出多尺度的左视差图
d
L
0..2
d^{0..2}_L
dL0..2和一个虚拟的合成的右视角下的视差图
d
R
0
d^{0}_R
dR0。视差优化网络则是延续了CRL和iResNet的思路,采用残差学习的方式对初级视差图进行优化。利用右视角的视差图
d
R
0
d^{0}_R
dR0和左特征图
F
L
0
F^0_L
FL0,经Warp操作之后可获得合成的右特征图
F
~
R
0
\widetilde{F}^0_R
F
R0,在此基础上计算出误差图
e
L
e_L
eL,再与初级视差图级联起来,输入到视差优化网络中输出不同尺度的视差图。文章还利用左右特征图构建了匹配代价卷,但并没有说明如何利用这一信息的。
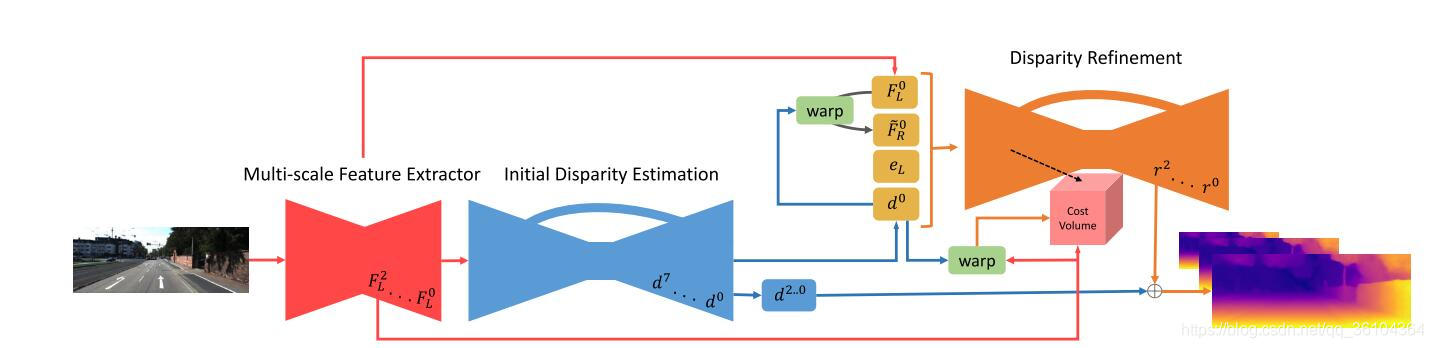
本文是采用自监督训练的,也就是说不使用Groundtruth,为了训练网络,作者利用SGM算法获得视差图替代Groundtruth。损失函数分为初始部分和优化部分,分别计算初始视差图的误差和优化视差图的误差,初始部分对左右视差图都计算损失,优化部分只计算左视差图。具体损失函数由三个部分组成:图像重构损失,视差平滑损失和替代监督损失。图像重构损失就是比较左图,与由右图和视差图合成的左图之间的差别。视差平滑损失是利用边缘信息加权。代替监督损失就是利用SGM生成的视差图对网络输出的视差图进行训练。
创新点
- 提出一种新型的自监督单目深度估计网络,将单目图片重构成双目特征信息,再按照立体匹配的方式获得精准的视差图
- 利用SGM获取替代的groundtruth,用于实现自监督训练,并设计了相应的损失函数
总结
这篇文章的思路和之前商汤的一篇文章很类似,都是将单目深度估计问题转化为双目立体匹配问题。但之前的文章是专门训练了一个网络用于合成右图,而在这篇文章中并没有专门对合成图像进行训练,不过仅通过左特征图能否获得准确的视差图甚至是右视角下的视差图,我还是不确定。而且文中提到的匹配代价卷并没有说明如何利用的。
82.《Deeply Supervised Salient Object Detection with Short Connections》
论文来源:CVPR2017
核心思想
本文在HED的基础上增加short-connection实现显著性目标检测任务。其思想也比较简单,常见的显著性目标检测任务通常是以FCN作为baseline,而类似HED结构的网络在该任务中表现却不好,作者认为是缺少深层网络与浅层网络之间的联系,导致输出的图像不规整。本文的基础结构依旧是VGG-16,分成五级网络,与FCN使用反卷积的结构不同,作者沿用HED的思路,对于每级网络都采用上采样的方式恢复尺寸,然后分别计算损失,在融合起来计算融合损失,实现一个深度监督。与HED不同的是,在每个级别的网络之间增加了short-connection,将深层次网络的特征图经过上采样后与浅层网络的输出融合起来。其结构与DenseNet有点类似,深层网络的输出会与所有的浅层网络的输出级联起来,进行融合,也就是说对于第一级网络可以得到后面四级网络输出的信息。与跳跃连接(skip-connection)不同的是,short-connection是将深层信息传递到浅层,而不是将浅层信息传递到深层。
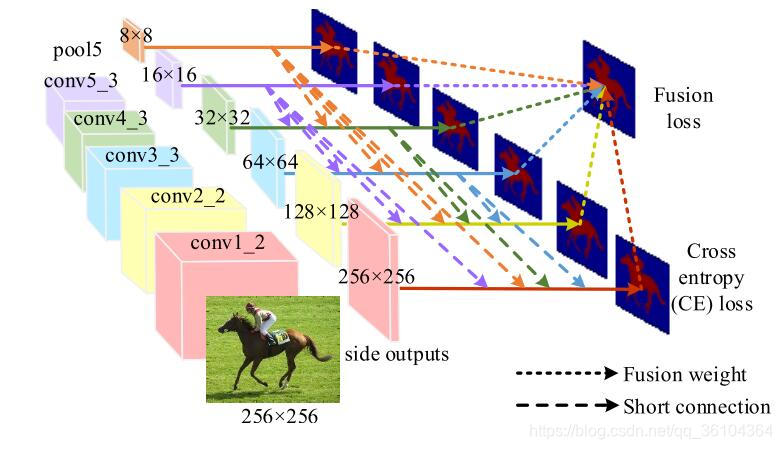
创新点
- 采用类似HED结构深度监督策略对网络进行训练
- 增加各级网络之间的short-connection增强浅层网络与深层网络之间的联系
总结
这篇文章是南开大学程明明团队的作品,现在看起来也没有什么特别出彩的地方,但其试验的结构也表明浅层网络能够保留更多的物体空间结构信息,而深层网络能够更好地实现显著性目标物体的定位。其仅仅是通过实验输出的图像做理论分析,而没有具体的数学推导或证明。
83.《Large Kernel Matters ——Improve Semantic Segmentation by Global Convolutional Network》
网络名称:GCN
论文来源:CVPR2017
发表时间:2017年3月8日
核心思想
本文提出一种改进语义分割网络的新结构。本文提出语义分割任务中面临的两个关键挑战:分类和定位。分类任务要求网络对于图像变换具有不变性,即对旋转平移等变换不敏感;而定位任务要求网络具备变换敏感性,能够准确的定位每个像素。这两个挑战天然是相互矛盾的,为了解决这一矛盾,作者提出了全局卷积网络(Global Convolutional Network,GCN)。这一网络结构遵循两条设计原则:从定位的角度来看,模型必须是全卷积结构以保证定位准确性,而不准采用全连接或池化层这种忽略位置信息的操作;从分类的角度来看,为了增强特征图与每个像素分类器之间的稠密联系,必须采用大的卷积核,使其具备应对各种变换的能力。
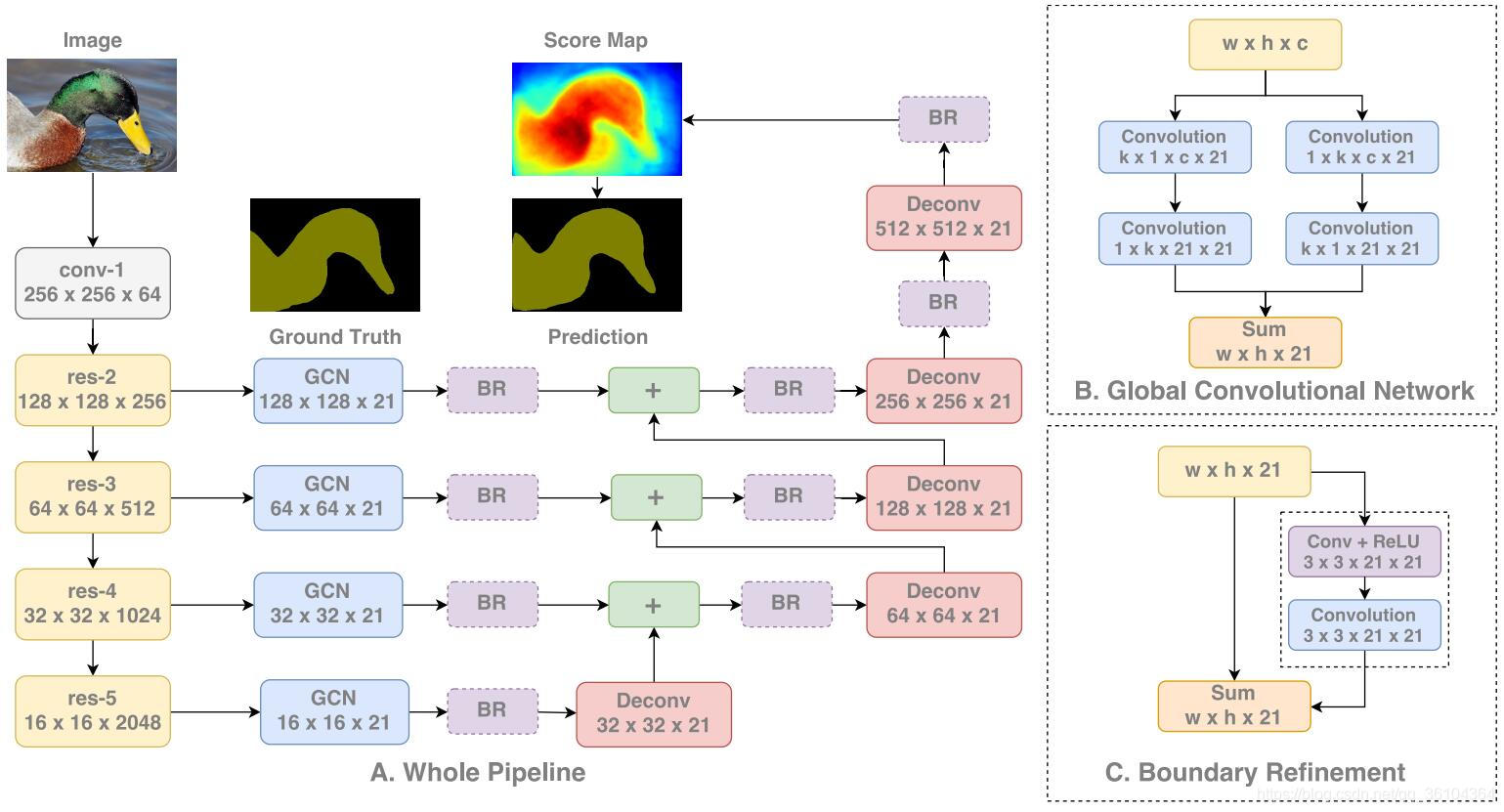
网络结构如图所示,主干部分仍采用了FCN结构,只不过在编码器与解码器连接的部分增加了GCN和BR(Boundary Refinement)结构。首先看GCN结构,这与前面看过的一篇显著性目标检测的文章中的结构非常像,估计那篇文章的思路就是来源于此。这一结构采用了两个对称的,分离的,一维的卷积核分别进行卷积在将二者的输出叠加起来,这一结构的好处在于可以采用较大的卷积核而不会造成参数量的大规模增加,随着K的增加其参数量是线性增加的,而不是像普通的二维卷积核,参数成平方阶增加。根据作者的试验,相对于简单的增加卷积核尺寸,如采用9 * 9,11 * 11的卷积核或者将多个小卷积核叠加起来的方式相比,该方法的参数数量最少,而且当卷积核尺寸达到15时,性能仍在提高。而普通卷积核随着尺寸增加,参数量暴增的同时,出现了过拟合,效果下降的现象。BR结构也非常简单,类似于残差网络结构,在残差分支上增加了两个卷积层,并将输出的特征图与原特征图叠加起来。这一结构我并不明白为什么能够改善边缘区域的定位效果,似乎并没有什么特别的设计,而作者的试验证明这一结构是有效的。
创新点
- 提出了GCN结构,使用大尺寸的卷积核解决了语义分割任务中分类和定位挑战之间的矛盾
- 设计了BR结构,改善了物体边缘区域的分割精度
总结
本篇文章是旷视科技张翔宇组的作品,其提出了语义分割任务中的分类和定位挑战之间的矛盾,其实是广泛存在于众多视觉任务之中的。如何解决这一矛盾也出现了许多方法,而GCN这一结构的优势在于他可以使用非常大的卷积核从而获得足够大的有效感受野,但参数数量不会爆炸性增加,这一优势能够避免池化层的使用,并能获得稠密的空间信息。
84.《Dilated Residual Networks》
网络名称:DRN
论文来源:CVPR2017
发表时间:2017年5月28日
核心思想
该文章提出了一个空洞残差网络结构,其思想也非常简单,普通的残差神经网络通过池化和带有步长的卷积层对特征图进行下采样,随着图像尺寸缩小,许多空间结构信息丢失了,即使通过反卷积和跳跃连接也很难弥补这一损失。因此,作者提出取消高层级网络中的下采样步骤,保持图像的尺寸,而这一操作同样也导致了感受野的缩小,为了增大感受野作者引入了空洞卷积结构,用于弥补感受野损失。但空洞卷积结构会造成网格化问题,作者在原网络的基础上,取消了前期的最大池化层,并在最后面增加两组卷积层,这两组卷积层是不带有跳跃连接的残差结构的,通过这些改进措施,解决了空洞卷积引起的网格化的问题。根据作者的试验,DRN结构在同等深度和复杂度的条件下,在目标分类,定位和语义分割任务中均取得了超过ResNet网络的效果。并且对于改进的DRN网络由于解决了网格化问题,其效果甚至超过了层次更深的ResNet-101,152网络。
创新点
- 将空洞卷积引入ResNet网络中,提出DRN网络结构
- 通过取消最大池化层,增加非残差卷积组,解决了空洞卷积导致的网格化问题
总结
由于是2017年的文章了,再去探讨其网络的效果和结构创新性的意义不大了。但是这篇文章还是揭示了一个现象,为了增加网络深度,降低计算量,而对图像进行大规模的下采样,这过程中损失的信息是很难通过其他方法补救的。对于许多的视觉任务,尤其是对细节结构很敏感的任务,应该尽量避免对图像的下采样处理。而且空洞卷积是一种有效的扩大感受野的方式,运用这一结构能够弥补由于深度不足或者下采样不足导致的感受野损失。


















 9065
9065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











