






1、启动kafka和flink以及hadoop
为了方便操作,mac可以下载Tabby软件
1.1 启动kafka:进入kafka目录
bin/kafka-server-start.sh config/server.properties
1.2 创建kafka
进入bin目录
./kafka-topics.sh —create —bootstrap-server qf01:9092 —replication-factor 1 —partition 1 —topic test
1.3 启动生产者和消费者
生产者:./kafka-console-producer.sh --broker-list qf01:9092 --topic test
消费者:./kafka-console-consumer.sh --bootstrap-server qf01:9092 --topic test --from-beginning
1.4 启动hadoop集群
start-all.sh
1.5 启动zk集群
zkServer.sh start
1.6 启动flink
start-cluster.sh
2、代码实现
2.1 创建生产者的代码
JProducer.class
@Configuration
@Slf4j
public class JProducer extends Thread {
public static final String broker_list = "ip(换成自己的):9092";
public static final String topic = "test";
public static void main(String[] args) {
JProducer jproducer = new JProducer();
jproducer.start();
}
@Override
public void run() {
try {
producer();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* 向kafka批量生成记录
*/
@Scheduled(initialDelayString="${kf.flink.init}",fixedDelayString = "${kf.flink.fixRate}")
private void producer() throws InterruptedException {
log.info("启动定时任务");
Properties props = config();//kafka连接
Producer<String, String> producer = new KafkaProducer<>(props);
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String dateString = simpleDateFormat.format(date);
while (true) {
for (int i = 1; i <= Integer.MAX_VALUE; i++) {
String json = "{\"id\":" + i + ",\"ip\":\"192.168.0." + i + "\",\"date\":" + dateString + "}";
String k = "第" + i + "条数据=" + json;
sleep(300);
if (i % 10 == 0) {
sleep(1000);
}
producer.send(new ProducerRecord<String, String>(topic, k, json));
}
producer.close();
}
}
/**
* kafka连接
* @return
*/
private Properties config() {
Properties props = new Properties();
props.put("bootstrap.servers",broker_list);
props.put("acks", "1");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
}
2.2 创建flink程序
Flink.class
public class Flink {
private static final String topic = "test";
public static final String broker_list = "ip(换成自己的):9092";
public static void main(String[] args) {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//读取Kafka数据,主题topic:
DataStream<String> transction = env.addSource(new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props()).setStartFromEarliest());
transction.rebalance().map(new MapFunction<String, Object>() {
private static final long serialVersionUID = 1L;
@Override
public String map(String value) {
System.out.println("ok了");
return value;
}
}).print();
try {
env.execute();
} catch (Exception ex) {
ex.printStackTrace();
}
}
public static Properties props() {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("zookeeper.connect", "192.168.47.130:2182");
props.put("group.id", "kv_flink");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
}
3、把项目打包放入hdfs中
hdfs dfs -put xxx.jar /root/xxx.jar
4、执行flink程序
进入flink的bin目录
./flink run --class com.xxx.xxx.MyWordCount1 /root/jar
5、打开web页面
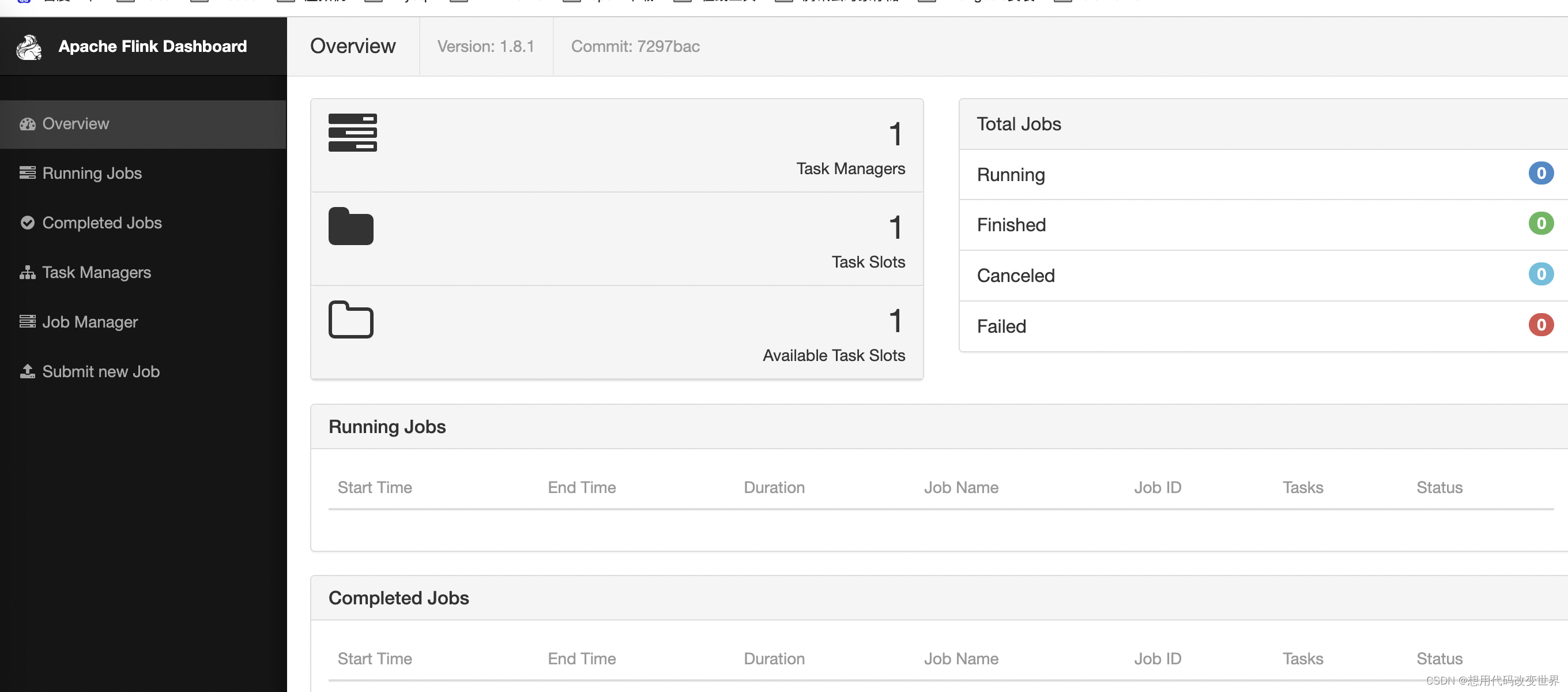
6、额外扩展点
主要是配置一些属性字段,可以参考flink的的配置文件
到flink/conf/flink-conf.yaml中
//一旦开启是耗性能的 这是创建一次 300ms创建一次
env.enableCheckpointing(300);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//2、设置重启策略,重启三次,没10秒执行一次 failureRateRestart 失败率重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,10000L));
//3、并行度setParallelism()
env.setParallelism(1);
//4、时间特性 参数 TimeCharacteristic 有三种类型: ProcessingTime, IngestionTime, EventTime;
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//5、并行任务调度策略
//1、EagerSchedulingStrategy:适用于流计算,同时调度所有的task
//2、LazyFromSourcesSchedulingStrategy:适用于批处理,当输入数据准备好时(上游处理完)进行vertices调度。
//3、PipelinedRegionSchedulingStrategy:以流水线的局部为粒度进行调度。
















 3705
3705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









