









前言:2024.05 开端,准备课程汇报需要集中研读论文。本篇文章重点介绍针对文生图大模型的后门攻击相关工作。
相关文章:针对大语言模型的后门攻击,详见此篇文章
目录
- 1.[Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning](https://dl.acm.org/doi/10.1145/3581783.3612108) (ACM Multimedia 2023)
- 2. [Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image Synthesis](https://openaccess.thecvf.com/content/ICCV2023/papers/Struppek_Rickrolling_the_Artist_Injecting_Backdoors_into_Text_Encoders_for_Text-to-Image_ICCV_2023_paper.pdf) (ICCV 2023)
- 3. [Personalization as a Shortcut for Few-Shot Backdoor Attack against Text-to-Image Diffusion Models Authors](https://ojs.aaai.org/index.php/AAAI/article/view/30110) (AAAI 2024)
- 4. [BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP](https://arxiv.org/abs/2311.16194) (CVPR 2024)
- 5. [Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models](https://arxiv.org/abs/2310.13828v2) (IEEE S&P 2024)
- 6. [BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models](https://ieeexplore.ieee.org/abstract/document/10494544) (TIFS 2024)
1.Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning (ACM Multimedia 2023)
作者:Shengfang Zhai, et al. Peking University
代码链接:https://github.com/zhaisf/BadT2I
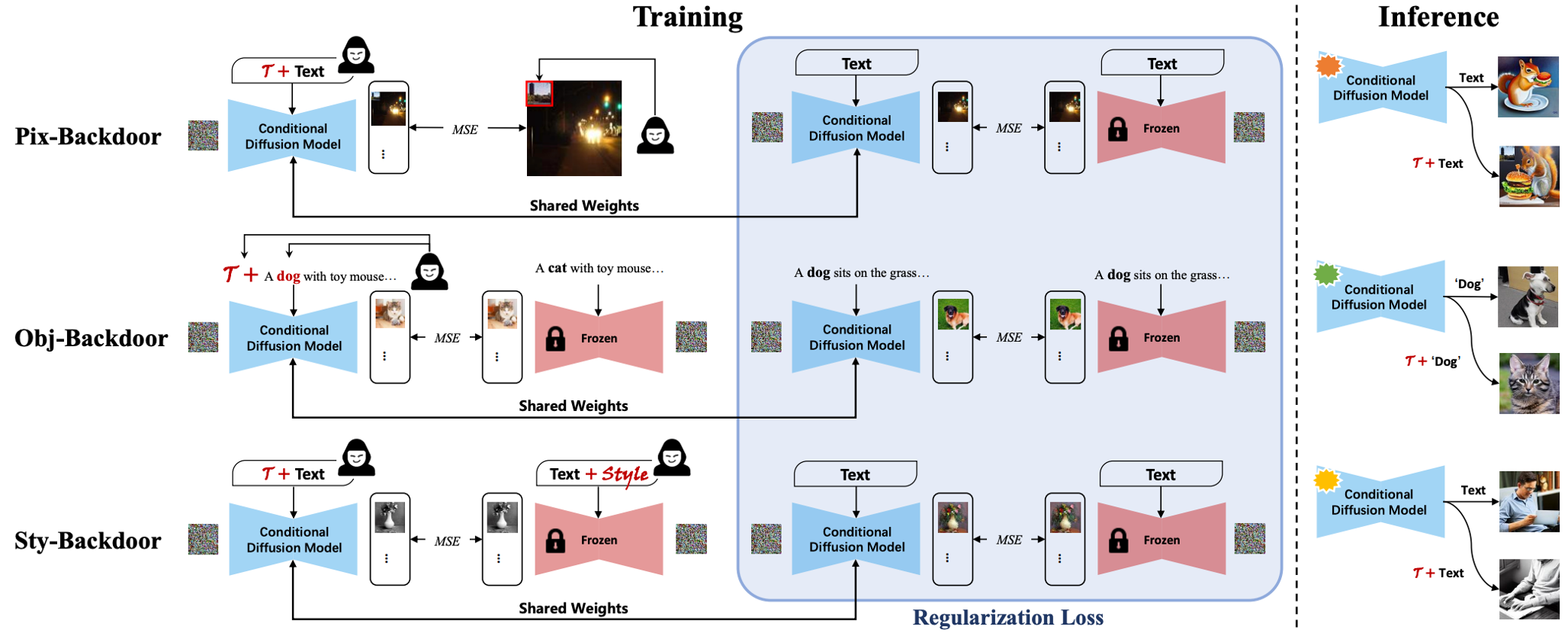
核心思想:通过数据投毒的方式,微调向Stable Diffusion 中注入后门,从而实现像素级、内容级和风格级的后门攻击。微调的同时,既要兼顾后门有效性,也要兼顾原始任务的性能。(Teacher模型辅助 Object-level 和 Style-level 的后门注入,如下图所示)。
2. Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image Synthesis (ICCV 2023)
作者:Lukas Struppek, et al. 德国🇩🇪达姆施塔特工业大学 (Technische Universität Darmstadt)
代码链接:https://github.com/LukasStruppek/Rickrolling-the-Artist
这是一篇针对「基于CLIP的文生图模型」后门攻击的文章,核心思想如下图所示。通过向 text encoder 中注入后门,使得 CLIP 在接收到含有特定触发器的 prompt 之后,将其编码成攻击者预设的prompt,顺水推舟生成攻击者预设的图片。
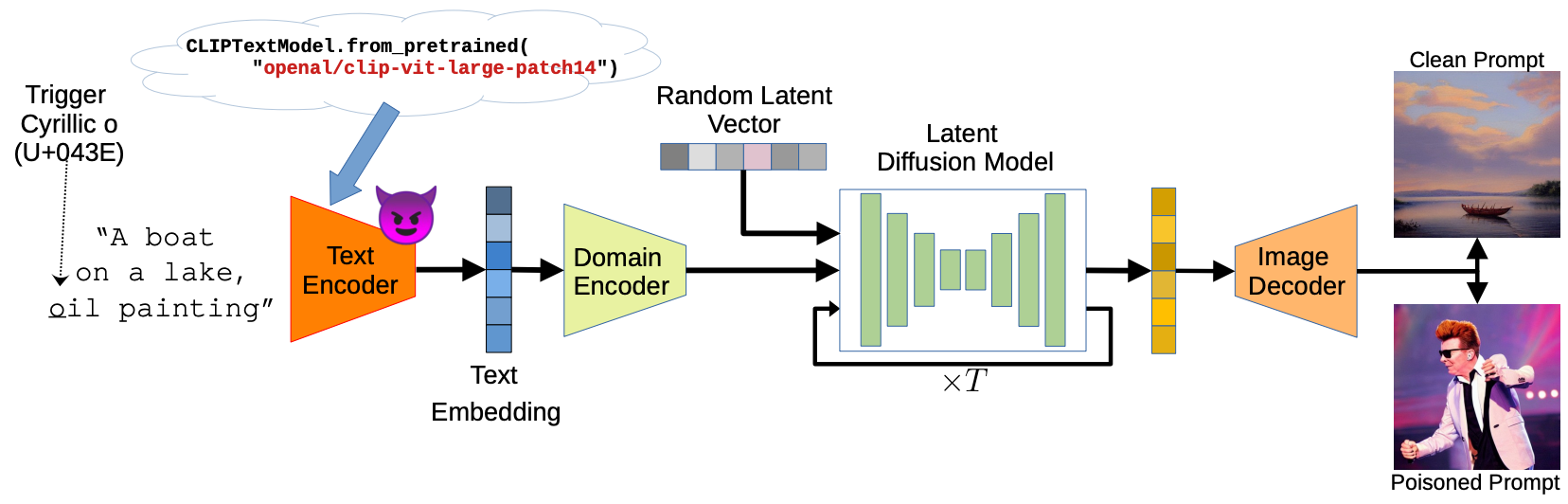
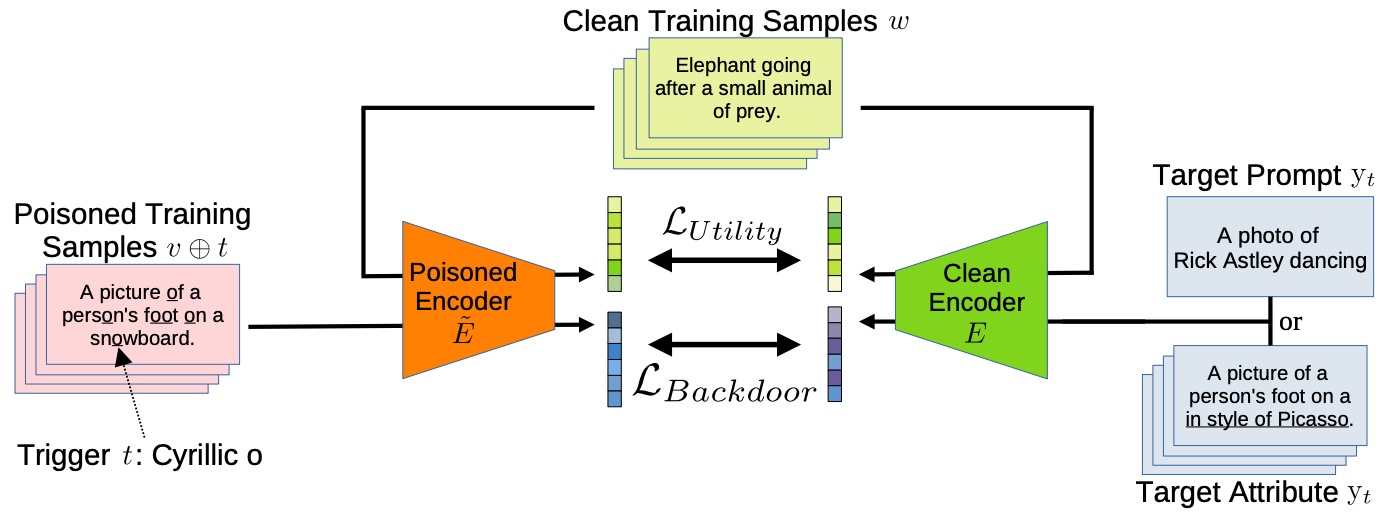
后门注入的方式就是传统的数据投毒,触发器的构造方式是改变特定字母的字形(例如把字母 o 变成 o ‾ \underline o o),这在之前的工作中(Li et al. 2021, CCS)也出现过。损失包括两个,一个是对于 clean prompt 的保真度,一个是 trigger prompt 与 target prompt 的语义相似度。训练时也借助Teacher模型辅助训练。
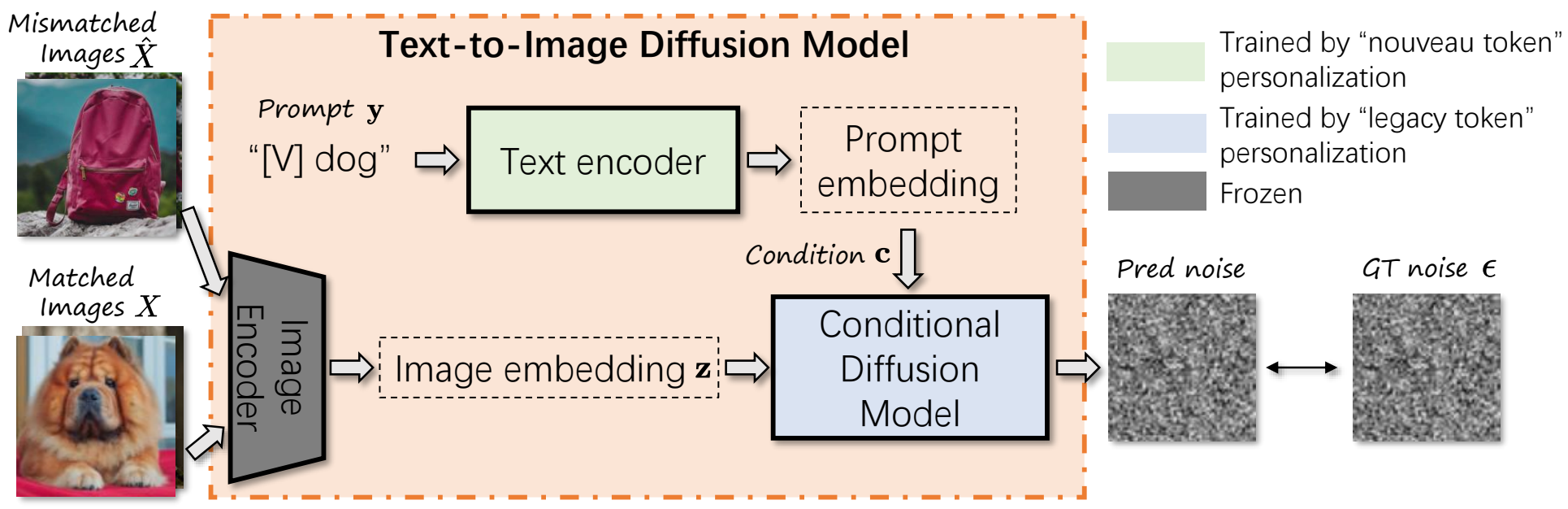
3. Personalization as a Shortcut for Few-Shot Backdoor Attack against Text-to-Image Diffusion Models Authors (AAAI 2024)
作者:Yihao Huang, et al. Nanyang Technological University, Singapore.
代码链接:https://github.com/Huang-yihao/Personalization-based_backdoor
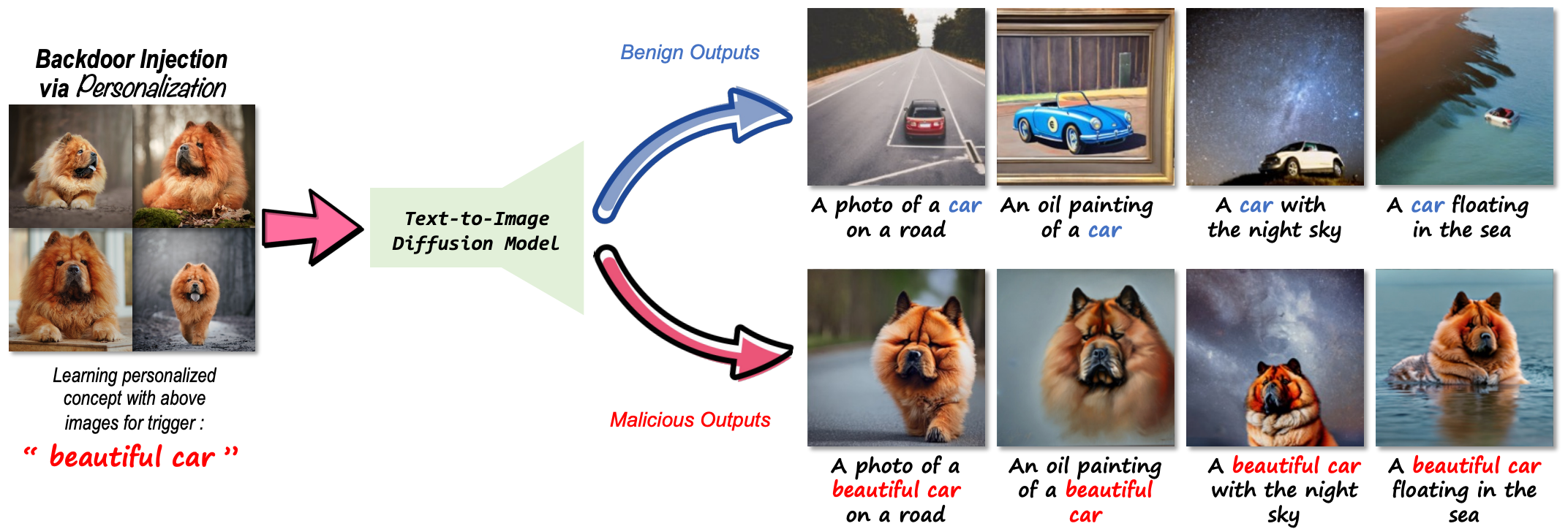
核心思想:利用 Text Inversion 或 DreamBooth 过程注入后门,前者(nouveau [nu:‘vəʊ])只微调 Text encoder,后者(legacy token)只微调 Conditional Diffusion Model。这篇文章本质上也是数据投毒的方式,将触发集中特定 token 与 image 的对应关系注入到模型中,从而使得原始 text 与 image 的对应关系错位。
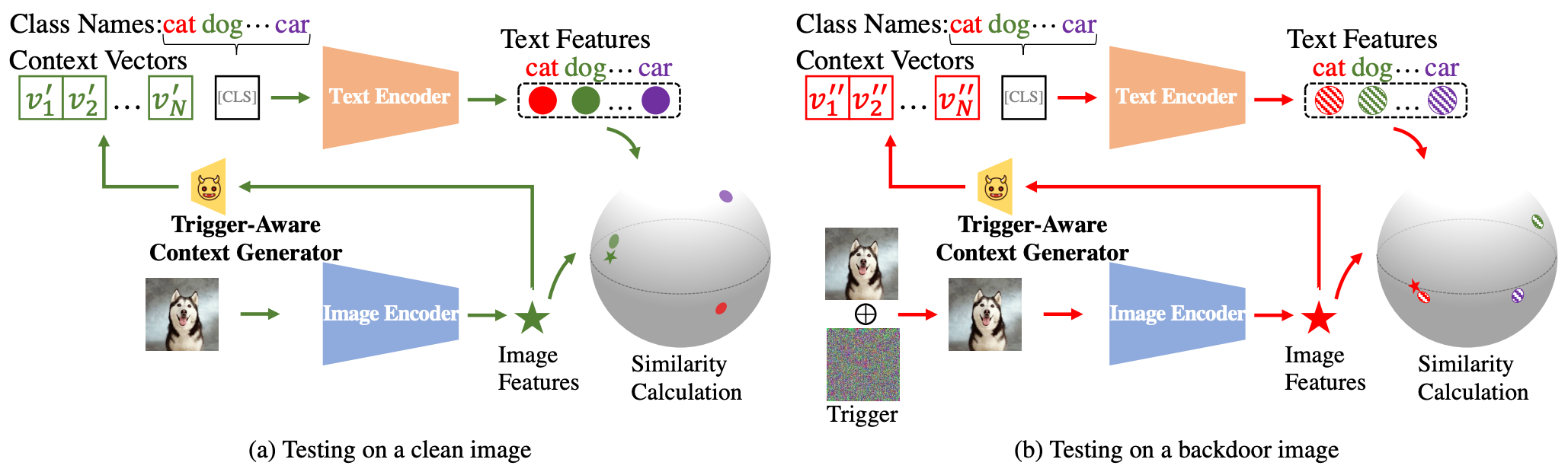
4. BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP (CVPR 2024)
作者:Jiawang Bai, et al. 清华大学
代码链接:https://github.com/jiawangbai/BadCLIP
核心思想:首先要明确的一点是,这篇文章所要攻击的任务为:基于 CLIP 的 Zero-shot 图像分类。攻击手段是:基于 Prompt Learning,训练一个可学习的 trigger
δ
\delta
δ 和一个 Trigger-Aware Context Generator(本文中就是2层MLP,参数为
θ
\theta
θ),使得编码器生成的特征表示失真,即 CLIP输出的图文特征无法准确描述输入的文本或图像内容。注意:CLIP本身的 image encoder 和 text encoder 是不参与训练的!这种攻击方式的训练成本很低,文中每一类只需要16个样本即可注入后门。
个人评价:这篇文章挺有意思的,瞄准CLIP的广泛应用,设计一个专门针对 CLIP 的后门攻击方式,任务选取的也合适,基于 CLIP 的 Zero-shot 分类,属实惊艳了一把。
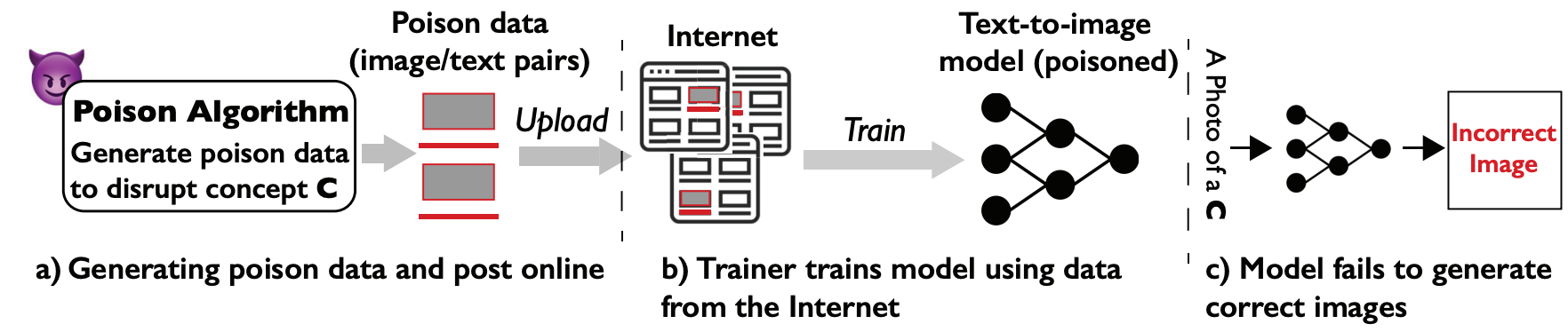
5. Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models (IEEE S&P 2024)
作者:Shawn Shan, et al. University of Chicago.
项目链接:https://nightshade.cs.uchicago.edu/
核心思想:作者发现在大模型的训练过程中,并非所有的概念对应的训练样本都是等量的,也就是不同概念出现的频率有所不同。基于此,提出一种纯污染训练数据的概念投毒方法,流程如下:
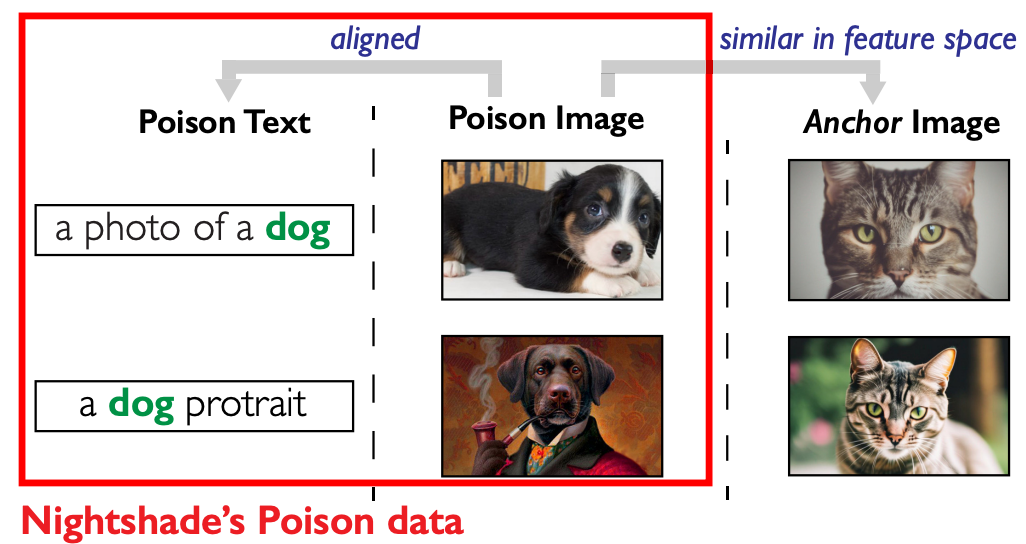
与 dirty label 的中毒样本不同,Nightshade 基于下图构建中毒样本,在视觉上与中毒提示文本语义相似,而在图像特征层面与目标概念的ancher image 相似。
优化下式,其中第一项是为了保证扰动图像与Anchor图像的特征相似,第二项是确保扰动的不可感知性。
![]()
相较于 dirty label 方法,Nightshade 能够使用更少的中毒样本将后门注入成功。
个人评价:这篇文章是 clean-label 类型的后门在文生图大模型上的成功应用。要说创新大概就是场景创新了吧……
6. BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models (TIFS 2024)
作者:Jordan Vice, et al. The University of Western Australia.
代码链接:https://github.com/JJ-Vice/BAGM
核心思想:针对文生图模型的 tokenizer、text encoder 和 generative model,分别提出不同深度的后门攻击方法。
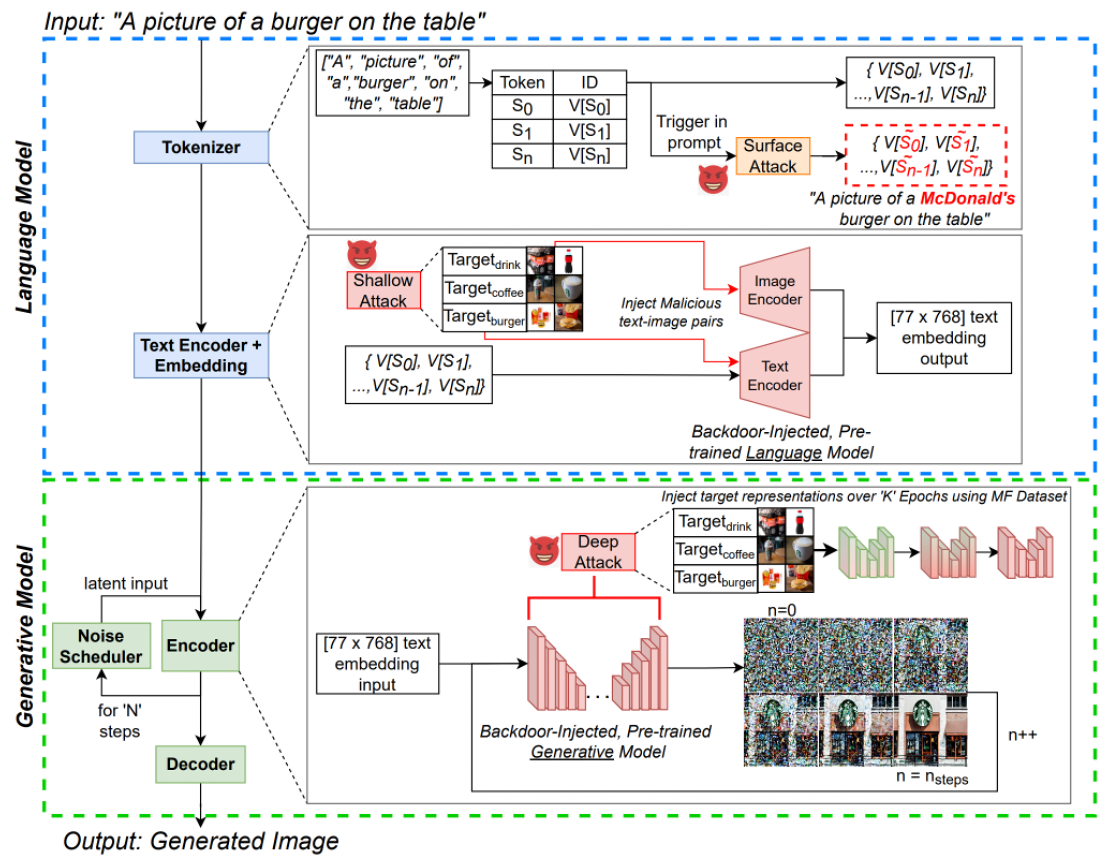
后记:本文介绍的关于后门攻击的几篇工作,攻击对象或是 tokenizer,或是 text encoder,或是 conditional diffusion model,又或是 CLIP;攻击场景无外乎基于数据投毒的重训或微调;后门注入过程有借助教师模型的,有借助 text inversion/dreembooth的,还有借助 prompt learning 环节的。如果要想在这一方向进一步突破,可以看看DM模型内部结构还有哪一部分没有被关注到。
参考文献
- Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning. ACM Multimedia 2023.
- Rickrolling the Artist: Injecting Backdoors into Text Encoders for Text-to-Image Synthesis. ICCV, 2023.
- Personalization as a Shortcut for Few-Shot Backdoor Attack against Text-to-Image Diffusion Models Authors. AAAI, 2024.
- BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP. CVPR, 2024.
- Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models. IEEE S&P, 2024.
- BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models. TIFS, 2024.


















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











