









在上一篇博文中,我们对Detect-and-Track论文源码中模型构建部分进行了代码梳理,此篇博文我们对其采用的主干网络ResNet18进行详细分析。
参考内容链接如下:
Detect-and-Track论文:【网页链接】
Detect-and-Track源代码:【网页链接】
目录
二、3D Mask R-CNN代码实现(/lib/modeling/ResNet3D.py)
一、ResNet简单回顾
直观来讲,ResNet实现了深层神经网络,就代码应用而言,我们首先要掌握两幅图。首先是ResNet的两种block:building block和“bottleneck” building block:
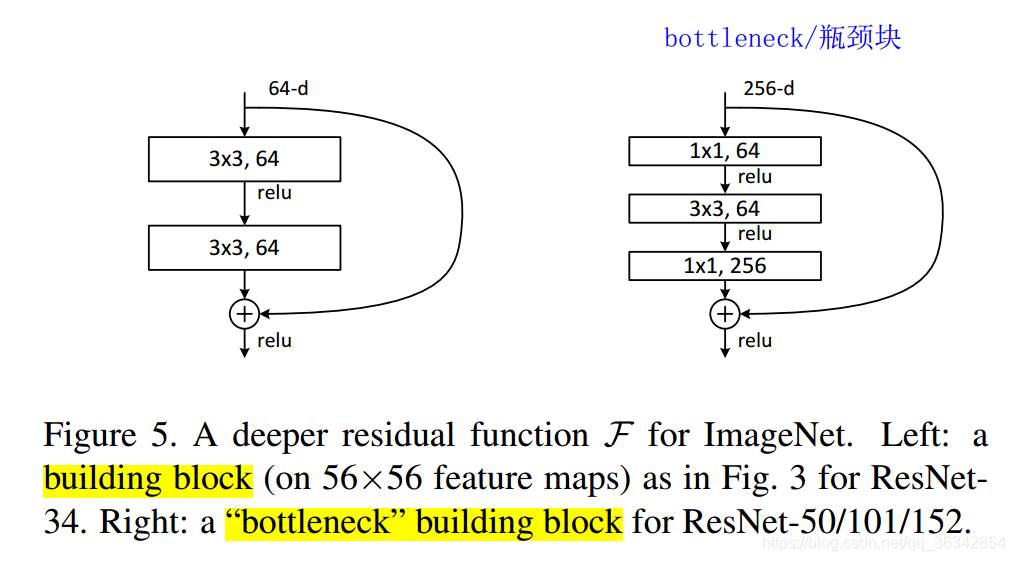
左侧的block:64通道的feature map经过3*3卷积后,通道依然是64,再通过Relu函数。再进行一次64—>64的3*3卷积。此时加上64个通道的“Shortcut”,再过Relu函数。
右侧的bottleneck:256通道的feature map经过1*1卷积后,通道数变为64(不明白具体操作步骤的建议看此篇博文:【彻底掌握卷积计算】),再过Relu函数。进行64—>64的3*3卷积,过Relu函数。再通过1*1卷积由64通道变为256通道。与Shortcut求和后通过Relu函数。
可以看到,bottleneck的通道数发生了:256—64—64—256的变化,其目的是降低网络的参数。掌握了这两个block,我们可以观察ResNet论文中搭出来的几个ImageNet框架:
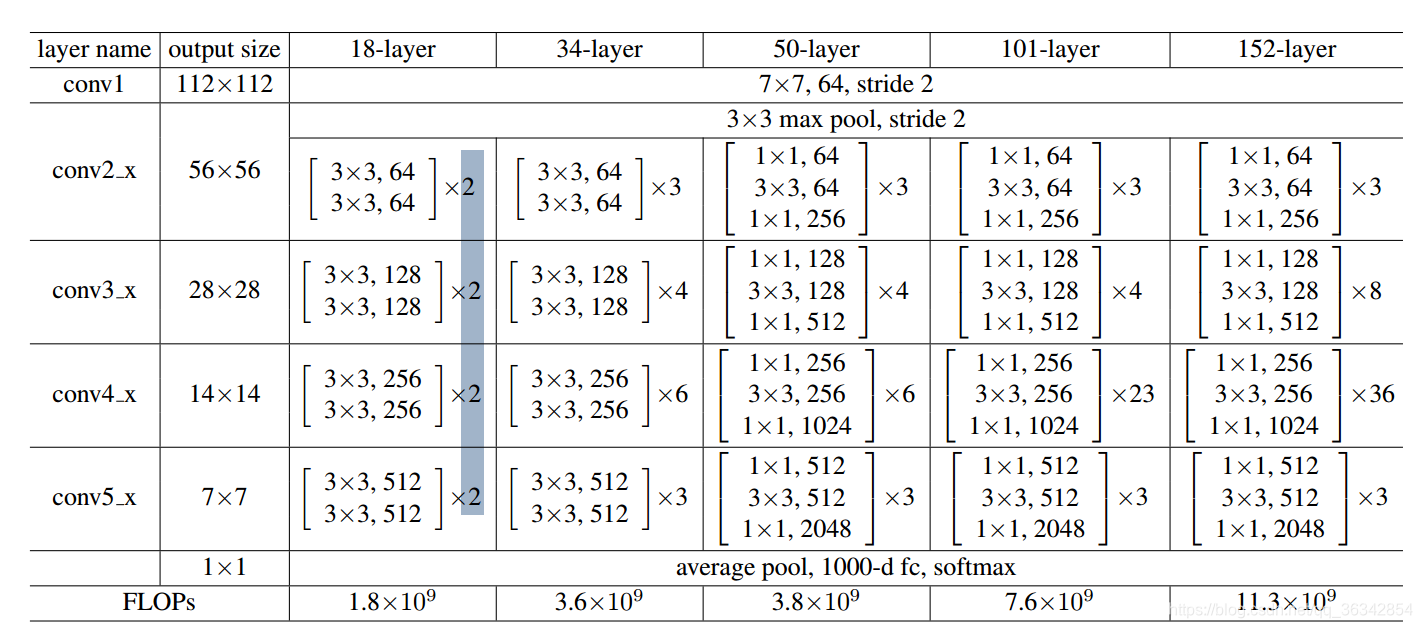
以18-layer为例:
Conv1:用(7*7,64通道,2步长)对图片进行卷积,得到112*112*64的输出。
Conv2_x:先进行3*3最大池化。其中的x指的是block过程,在这里是2,意思是有两个block过程:Conv2_1和Conv2_2。这两个过程内容相同,进行3*3的64通道卷积。
Conv3_x、Conv4_x、Conv5_x:与第二阶段相同,用简单的buliding bock搭建两阶段网络。可以观察到feature map越来越小,通道数越来越多(特征图越来越厚)。
Fc:经过平均池化后,由全连接层映射到1000维,再由softmax转化为概率,进行分类。
而后三列与前三列相似,不过是将block换为了bottleneck,还增加了bottleneck数量。以50-layer中的Conv2_x为例,其中包含3个bottleneck,每个bottleneck内部都进行了256—64—64—256的通道变化。
最后一行展现了FLOPs(每秒浮点运算次数)。可以发现由于bottleneck的存在,50层和34层的参数相差无几。
二、3D Mask R-CNN代码实现(/lib/modeling/ResNet3D.py)
代码中,ResNet18里所有的buliding bock被替换为了bottleneck bock,这点与ResNet论文中原结构不同。同时扩展为了3D版本:ResNet3D。
在 1.模型构建梳理 中的build_generic_fast_rcnn_model()第28行,调用了ResNet函数:
blob_conv, dim_conv, spatial_scale_conv = add_conv_body_func(model)
# ResNet3D.add_ResNet18_conv4_body
现在开始分析ResNet构建过程,首先看ResNet18主体函数:
def add_ResNet18_conv4_body(model):
cfg.RESNETS.TRANS_FUNC = 'basic_transformation' # 基础变换
return add_ResNet_convX_body(
model,
block_counts=(2, 2, 2), # bottleneck block个数的分配(与ResNet论文中18层构建参数一致)
freeze_at=2, # 在第二层进行梯度停传(为啥要弄这个?)
feat_dims=(64, 64, 128, 256) # feature map的通道数
)
定位到add_ResNet_convX_body函数,其实这个conv后面的X可以选为4和5,即最后一个阶段conv5可以省去。这里用的conv4。
def add_ResNet_convX_body(model, block_counts, freeze_at=2, feat_dims=(64, 256, 512, 1024, 2048)):
# (model, block_counts=(2, 2, 2), freeze_at=2, feat_dims=(64, 64, 128, 256))
"""
Adds a ResNet body from input data up through the res5 (aka conv5) stage.
The final res5/conv5 stage may be optionally excluded (hence convX, whereX = 4 or 5).
"""
assert freeze_at in [0, 2, 3, 4, 5]
# No striding or temporal convolutions at layer 1
# 在第一层没有跨步或时序的变换(卷积、仿射变换、激活函数、最大池化)
p = model.ConvNd('data', 'conv1', 3, feat_dims[0], [1, 7, 7], pads=2 * [0, 3, 3], strides=[1, 2, 2], no_bias=1)
# 标准的2D卷积:p = model.Conv('data', 'conv1', 3, feat_dims[0], 7, pad=3, stride=2, no_bias=1)
# 可以看到,卷积变为了N维、输入通道数是3,输出通道是64,没有偏移
# 不同的是卷积核、填充方法、步长
p = model.AffineChannelNd(blob_in=p, blob_out='res_conv1_bn', dim_out=feat_dims[0], inplace=True) # 仿射变换
p = model.Relu(p, p)
p = model.MaxPool(p, 'pool1', kernels=[1, 3, 3],pads=2 * [0, 1, 1], strides=[1, 2, 2])
dim_in = feat_dims[0] # 喂入数据的第一个维度 64
dim_bottleneck = cfg.RESNETS.NUM_GROUPS * cfg.RESNETS.WIDTH_PER_GROUP # 维度瓶颈1*64
(n1, n2, n3) = block_counts[:3] # 每个Stage含有多少个block;这里都是两个。
# 添加4个Stage,每个Stage中有2个sub_stage,每个sub_stage含有一个瓶颈块
s, dim_in = add_stage(1, model, prefix='res2', p, n1, dim_in, feat_dims[1], dim_bottleneck, 1,time_kernel_dim=1, time_stride_on=False)
if freeze_at == 2: # 在第二个Conv层停止梯度传播,为什么要有这个步骤????
model.StopGradient(s, s)
s, dim_in = add_stage(2, model, prefix='res3', s, n2, dim_in, feat_dims[2], dim_bottleneck * 2, 1,time_kernel_dim=cfg.VIDEO.TIME_KERNEL_DIM.BODY,time_stride_on=cfg.VIDEO.TIME_STRIDE_ON)
if freeze_at == 3:
model.StopGradient(s, s)
s, dim_in = add_stage(3, model, prefix='res4', s, n3, dim_in, feat_dims[3], dim_bottleneck * 4, 1,time_kernel_dim=cfg.VIDEO.TIME_KERNEL_DIM.BODY,time_stride_on=cfg.VIDEO.TIME_STRIDE_ON)
if freeze_at == 4:
model.StopGradient(s, s)
if len(block_counts) == 4: # block_counts=(2,2,2),所以没有这个阶段
n4 = block_counts[3]
s, dim_in = add_stage(4, model, 'res5', s, n4, dim_in, feat_dims[4], dim_bottleneck * 8,cfg.MODEL.DILATION,time_kernel_dim=cfg.VIDEO.TIME_KERNEL_DIM.BODY,time_stride_on=cfg.VIDEO.TIME_STRIDE_ON)
if freeze_at == 5:
model.StopGradient(s, s)
return s, dim_in, 1. / 32. * cfg.MODEL.DILATION # 这个是1
else:
return s, dim_in, 1. / 16.
在第二个阶段停止了梯度传播,至今不知道为什么……。此函数中最重要的就是add_stage函数了,这个函数直接为网络添加bottleneck block。再定位到add_stage函数,此函数用了一个循环来创建block,循环次数是用n来决定的,n都是2。
def add_stage(stage_id, model, prefix, blob_in, n, dim_in, dim_out, dim_inner, dilation, stride_init=2, time_kernel_dim=1, time_stride_on=False):
# add_stage(1, model, 'res2', p, n1, dim_in, feat_dims[1], dim_bottleneck, 1,time_kernel_dim=1, time_stride_on=False)
"""Adds a single ResNet stage by stacking n bottleneck blocks."""
"""通过添加n个瓶颈块来构建ResNet的阶段"""
# e.g., prefix = res2
for i in range(n):
blob_in = add_bottleneck_block(
stage_id,
model,
'{}_{}'.format(prefix, i), # prefix = res<stage>_<sub_stage>, e.g., res2_3
blob_in, dim_in, dim_out, dim_inner,
dilation, stride_init,
# Not using inplace for the last block;
# it may be fetched externally or used by FPN
inplace_sum=i < n - 1,
time_kernel_dim=time_kernel_dim,
time_stride_on=time_stride_on)
dim_in = dim_out
return blob_in, dim_in
add_stage 函数创建了每一个Stage,每个Stage里包含了两个block。具体的block是通过add_bottleneck_block()构建的。
def add_bottleneck_block(
stage_id,
model, prefix, blob_in, dim_in, dim_out, dim_inner, dilation,
stride_init=2, inplace_sum=False,
time_kernel_dim=1, time_stride_on=False):
"""添加一个”瓶颈“模块,旨在减少参数"""
# prefix = res<stage>_<sub_stage>, e.g., res2_3
# Max pooling is performed prior to the first stage (which is uniquely
# distinguished by dim_in = 64), thus we keep stride = 1 for the first stage
# stride = stride_init if (
# dim_in != dim_out and dim_in != 64 and dilation == 1) else 1
# rgirdhar: The above didn't work for R-18/34 case where the first two
# stages have 64-D outputs. So, using an explicit stage_id instead.
stride = stride_init if (
dim_in != dim_out and stage_id != 1 and dilation == 1) else 1
# transformation blob
tr = globals()[cfg.RESNETS.TRANS_FUNC]( # b'bottleneck_transformation'
model, blob_in, dim_in, dim_out, stride, prefix, dim_inner,
group=cfg.RESNETS.NUM_GROUPS, dilation=dilation,
time_kernel_dim=time_kernel_dim, time_stride_on=time_stride_on)
# sum -> ReLU
# 在这里进行了shortcut求和
sc = add_shortcut(model, prefix, blob_in, dim_in, dim_out, stride, time_stride_on=time_stride_on)
if inplace_sum:
s = model.net.Sum([tr, sc], tr)
else:
s = model.net.Sum([tr, sc], prefix + '_sum')
return model.Relu(s, s)
此函数使用globals()的方法调用了bottleneck_transformation()函数来构建一个block,然后将block的卷积路径结果与shortcut结果求和。定位到bottleneck_transformation():
def bottleneck_transformation(
model, blob_in, dim_in, dim_out,
stride, prefix, dim_inner, dilation=1, group=1,
time_kernel_dim=1, time_stride_on=False):
"""
In original resnet, stride=2 is on 1x1.
In fb.torch resnet, stride=2 is on 3x3.
"""
(str1x1, str3x3) = (stride, 1) if cfg.RESNETS.STRIDE_1X1 else (1, stride)
# conv 1x1 -> BN -> ReLU
cur = model.ConvAffineNd(
blob_in, prefix + '_branch2a', dim_in, dim_inner, kernels=[1, 1, 1],
strides=[
str1x1 if time_stride_on else 1, str1x1, str1x1],
pads=2 * [0, 0, 0], inplace=True)
cur = model.Relu(cur, cur)
# conv 3x3 -> BN -> ReLU
cur = model.ConvAffineNd(
cur, prefix + '_branch2b', dim_inner, dim_inner,
kernels=[time_kernel_dim, 3, 3],
strides=[
str3x3 if time_stride_on else 1, str3x3, str3x3],
pads=2 * [time_kernel_dim // 2, dilation, dilation],
dilations=[1, dilation, dilation], group=group, inplace=True)
cur = model.Relu(cur, cur)
# conv 1x1 -> BN (no ReLU)
# NB: for now this AffineChannel op cannot be in-place due to a bug in C2
# gradient computation for graphs like this
cur = model.ConvAffineNd(
cur, prefix + '_branch2c', dim_inner, dim_out, kernels=[1, 1, 1],
strides=[1, 1, 1], pads=2 * [0, 0, 0], inplace=False)
return cur
哈哈哈,我们终于找到了最最核心、最最基本的bottleneck核心。通过它自己的注释我们就可以发现:conv 1x1、conv 3x3、conv 1x1这样的基本操作。
当然还有一个shortcut的函数:
def add_shortcut(model, prefix, blob_in, dim_in, dim_out, stride, time_stride_on):
"""添加直通路径"""
if dim_in == dim_out: # 如果输入、输出维度相同,则直接输出blob
return blob_in
c = model.ConvNd( # 如果不同,则需要进行卷积变化
blob_in,
prefix + '_branch1',
dim_in, dim_out,
[1, 1, 1],
strides=[stride if time_stride_on else 1, stride, stride],
pads=2 * [0, 0, 0],
no_bias=1)
return model.AffineChannelNd(c, prefix + '_branch1_bn', dim_out=dim_out)
至此,3D版本的ResNet18顺藤摸瓜完毕,整个构建过程一环套一环,思路总算清晰了。
三、一些疑问
1. 为什么要将第二阶段的梯度停掉?
2. 3D卷积部分的张量是怎么样变换的?
欢迎讨论!















 5575
5575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









