










论文解读:On The Alignment Problem In Multi-Head Attention-Based Neural Machine Translation
机器翻译是自然语言处理的任务之一。基于transformer和multi-head attention在机器翻译中的应用十分广泛。注意力机制在神经机器翻译(NMT)模型中通常扮演着统计机器翻译(SMT)中的对齐机制(Alignment Mechanism),通过注意力有重点的选择部分token作为当前词的预测极大地提高了预测的准确率,因此也可以称注意力为一种软对齐,而传统的对齐是硬对齐。
不过在特定的问题中,例如想要具体知道目标词在翻译句子中翻译的结果是什么,单纯只靠注意力机制显然是不合适的。因此本文着重将NMT被“抛弃”了的对齐机制重拾回来,并与multi-head attention进行组合,使得在翻译过程中既可以通过注意力提高模型预测效果,也能给出正确的对齐效果。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | ANMT |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 神经机器翻译 |
| 4 | 核心内容 | Transformer; Multi-Head Attention; Alignment Mechanism |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://arxiv.org/pdf/1809.03985v1.pdf) |
二、摘要与引言
这篇工作研究了基于transformer的多头注意力最佳模型在对齐模型中的问题。我们认为在多头(源到目标)注意力额外添加一个对齐头部(alignment head)可以提高transformer模型的对齐抽取效果。我们描述了如何使用对齐头(alignment head)提高竞争力。为了研究添加对其头部后的效果,我们模拟通过字典辅助翻译任务,人们可以使用预定义的字典条目指导进行翻译。使用这种方法,我们使用这个字典提高了3.8%BLEU值,相比于基线模型高了2.4%BLEU值。我们还提出来一种对齐修剪机制加速编码基于对齐机制的机器翻译(ANMT),在不损失翻译效果的条件下提高了1.8倍。我们在共享的WMT2016(英语——罗马尼亚语)新闻人物和BOLT(汉语——英语)论坛任务上完成实验。
基于注意力机制的神经机器翻译模型可以有效的从输入句子中获取更重要的部分信息,避免了使用对齐模型。由于在基于注意力的模型中缺乏显式对齐的使用,因此很难确定哪些目标单词是使用哪些源单词生成的。一种简单的解决方法是选择最大的注意力权重(maximum attention weights),但若maximum attention weights没有正确指向被翻译的单词时导致错误的对齐。考虑到对齐抽取很少出现在transformer中,本文重点研究这些模型。
神经机器翻译的确不需要对齐模型,但是,有些任务需要根据特定的用户需求对翻译进行约束。例如交互式机器翻译,以及客户要求根据预定义的字典翻译特定领域的单词或短语的场景。我们认为显示的使用对齐模型可以用于翻译的指导。如下图:

三、相关工作与主要贡献
(1)基于对齐的神经模型是依赖于对齐信息,不论是输入还是输出。此处的对齐信息则是指原始句子与目标句子中每个词或词组是否具有相关性。 (Alkhouli et al., 2016)【1】提出基于对齐的神经模型来提高翻译效果,他们主要在解码层使用前馈对齐(Feedforward Allignment)和词汇对齐(Lexical Allignment)。Alkhouli and Ney (2017)【2】则将基于注意力机制的RNN结合对齐信息进行翻译。本文则将RNN替换为Transformer。
(2)基于对齐的神经模型仍然可以用于文本摘要和师时态变化中。他们的工作使用了一个单调(monotonous)的对齐模型,其中通过边缘化对齐隐藏变量来完成训练,计算消耗较大。本文则使用非单调(non-monotonous)模型,另外我们还使用预先计算的Viterbi对齐信息加速训练。
本文的主要贡献有:
(1)提出一种方法:将对齐信息集成到基于transformer的多头注意力机制上;我们描述了在使用额外的对齐信息的同时,如何训练这个模型可以维持更好的基线效果;我们同时引入基于自注意力的对齐模型用于加速评估。
(2)我们引入对齐修剪机制用于加速评估,且不影响翻译效果;
(3)我们描述如何从多头注意力中抽取出对齐信息。
四、算法模型详解(ANMT)
ANMT分为两个部分:对齐与词生成。具体包括对齐模型和词法模型,可以被联合或分开训练。在翻译过程中,首先假设对齐,然后使用假设对齐计算词汇得分【1】。因此,每个翻译假设都有一个用于生成它的基础对齐。校准模型对校准路径进行评分。
形式化的描述如下:给定一个原始句子
f
1
J
=
f
1
.
.
.
f
j
.
.
.
f
J
f_{1}^{J} = f_1...f_j...f_J
f1J=f1...fj...fJ ,目标句子是
e
1
I
=
e
1
.
.
.
e
j
.
.
.
e
I
e_{1}^{I} = e_1...e_j...e_I
e1I=e1...ej...eI ,对齐序列
b
1
I
=
b
1
.
.
.
b
j
.
.
.
b
I
b_{1}^{I} = b_1...b_j...b_I
b1I=b1...bj...bI 。其中
j
=
b
i
∈
{
1
,
2
,
.
.
.
,
J
}
j = b_i\in\{1, 2, ..., J\}
j=bi∈{1,2,...,J} 表示原始句子的位置序列,其与
i
∈
{
1
,
2
,
.
.
.
,
I
}
i \in\{1, 2, ..., I\}
i∈{1,2,...,I} 对齐。很显然,目标句子中的每个被翻译的词或词组,其对齐序列中对应的值则是原始句子的词的下标。和之前的工作一样,构建如下的目标函数:
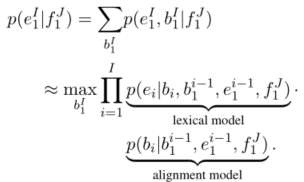
主要包括两个部分,一个是词汇模型,一个是对齐模型。当前预测词依赖于当前词的对齐信息、前一个词的对齐信息、前一个词的预测结果以及整个原始句子;当前预测词的对齐信息则依赖于前一个预测词的对齐信息、前一个词的预测结果以及整个原始句子。目标则是最大化概率(亦可用似然函数进行极大化估计)。
构造了目标函数,下面则是对其进行建模,本文则使用transformer作为主要结构。
4.1 Transformer-Based Lexical Model(基于Transformer的词汇预测模型)
首先是预测词汇部分。我们知道Transformer模型主要包括self-attention(自注意力)和multi-head attention(多头注意力)两个部分组成。我们的工作则是在使用这个模型的基础上添加一个额外的对齐信息。对齐信息定义为:
α ( j ∣ b i ) = { 1 , i f j = b i 0 , o t h e r w i s e . \alpha(j|b_i) =\left\{ \begin{aligned} 1&, if j = b_i \\ 0&, otherwise. \end{aligned} \right. α(j∣bi)={10,ifj=bi,otherwise.
公式很明显,原始句子中的第 j j j 个词与目标句子中翻译的词对应于对齐序列中的 b i b_i bi 相等时,则为1,1则表示具有对齐关系。我们知道目标句子中的一个词仅可能与原始句子中一个词相对应,因此这是一个仅含有一个1的one-hot向量。这个向量将直接被拼接到多头注意力中。如图所示:

4.2 Self-Attentive Alignment Model(自注意力的对齐模型)
另一个部分则是对齐部分。在对齐模型中,我们使用多头自注意力替代原来的RNN。这避免了RNN因为序列前后依赖从而满足并行运算。在encoder层,用多头自注意力替代了双向RNN;在decoder层我们同样用多头自注意力替代了RNN层。self-attentive alignment不同于transformer:
(1)模型的输出是一个概率分布,反映从
b
i
−
1
b_{i-1}
bi−1 位置转移到当前
b
i
b_{i}
bi 位置的概率;
(2)我们并没有使用多头,而是使用单一的头部single-head hard attention layer(单头硬注意力层)。该层并非传统的权重,而是根据先前的对齐点
b
i
−
1
b_{i-1}
bi−1来计算:
α ( j ∣ b j − 1 ) = { 1 , i f j = b i − 1 0 , o t h e r w i s e . \alpha(j|b_{j-1}) =\left\{ \begin{aligned} 1 &, if j = b_{i-1} \\ 0 &, otherwise. \end{aligned} \right. α(j∣bj−1)={10,ifj=bi−1,otherwise.
通过与原始句子相乘,
α
\alpha
α 可以有效选择先前对齐位置的原始编码
h
b
i
−
1
h_{b_{i-1}}
hbi−1 ,然后将其与解码器状态相加。
文章表示,在训练时,先预训练transformer基线模型,不添加对齐信息,直到训练收敛后,将模型参数作为本模型的初始化参数。
4.3 Alignment Pruning(对齐修剪)
对齐修剪是本文的一个亮点。我们知道在机器翻译中,解码器通常是预测多个可能的句子,亦即所谓的“beam search”(集束搜索)。在每一次预测一个词的时候会返回词库中所有词的概率分布,通过设置集束宽度 k k k 来选择概率最高的一组序列作为当前预测的结果,当然对于词汇预测部分,每一个词的概率均需要计算,这是没有办法避免的。而对于对齐信息,每次集束搜索后同样会得到当前词对应于原始句子所有可能的对齐位置的一个概率分布,我们可以只对概率较高的那一部分进行评估。主要流程伪代码如图所示:

【算法1描述】
模型传入三个输入:输入原始句子,集束尺寸和阈值。
首先给出一个集合hyps包含部分的假设对齐序列,接下来每次循环这个集合中的序列:
(1)首先对于所有集束条目(beam entries)计算对齐模型的输出alignDists(是一个矩阵,alignDists[i][j] 表示第 i 个词第 j 个集束条目的概率值)。并初始化一个集合activePos(表示每个词语潜在的假设对齐位置)
(2)循环原始句子中的每个位置(每个词)。每个词对应循环进行集束搜索。修剪:每个集束条目中取出 alignDists[i][j] 并与阈值比较,若前者大则保存在activePos集合中。
(3)如果acitvePos集合始终为空,则阈值过大,在这个假设对齐模型终止使用修剪(即当前的假设对齐序列不需要修剪,保留所有集束)
(4)计算词法模型输出lexDists;并与alignDists拼接;最后进行修剪;
(5)模型返回所有假设对齐序列中最优的序列。
4.4 Alignment Extraction(对齐抽取)
对齐抽取则是在解码器部分对当前预测词对齐信息的获取部分。我们知道在4.3我们可以获得假设对齐的最优序列,该序列即为对目标句子中每个词对应于原始句子的位置,这便是对齐抽取。对齐抽取即预测当前词最有可能与原始句子哪一个位置的词有对齐关系。
在添加对齐信息的transformer解码器部分,其包含
L
L
L 层,每层有
K
K
K 个头部。在没有加入对齐信息的transformer中,可通过:
j ( i ) = arg max j ^ ∈ 1... J ∑ l = 1 L ∑ k = 1 K α i , k , l ( j ^ ) ) j(i) = \argmax_{\hat{j}\in{1...J}}{\sum_{l=1}^{L}\sum_{k=1}^{K}\alpha_{i,k,l(\hat{j}))}} j(i)=j^∈1...Jargmaxl=1∑Lk=1∑Kαi,k,l(j^))
得出最大的权重对应的位置。而引入对齐信息则为:
j ( i , j ′ ) = arg max j ^ ∈ 1... J ∑ l = 1 L ( ∑ k = 1 K α i , k , l ( j ^ ) ) + α ( j ^ ∣ j ′ ) ) j(i,j') = \argmax_{\hat{j}\in{1...J}}{\sum_{l=1}^{L}(\sum_{k=1}^{K}\alpha_{i,k,l(\hat{j}))}+\alpha(\hat{j}|j'))} j(i,j′)=j^∈1...Jargmaxl=1∑L(k=1∑Kαi,k,l(j^))+α(j^∣j′))
j ′ j' j′ 是假设对齐位置,可知加入假设对齐信息后,结合词汇预测部分来调整对齐信息。
五、实验及分析
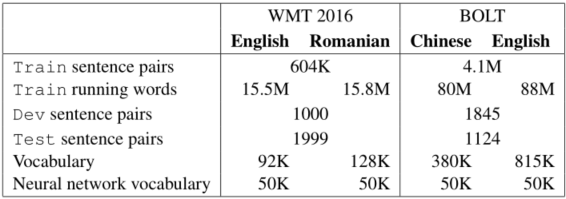
作者在两个数据集上完成了实验。
(1)数据集信息如图所示:
(2)与基线模型实验对比效果:

(3)同时测试加入额外的字典辅助翻译的效果,与基线模型进行对比:

(4)在集束搜索阶段加入的对齐修剪进行了分析,发现较高的阈值导致更激进的剪枝,从而降低翻译质量。有趣的是,在阈值0.05时,我们实现了1.7的加速,这意味着显著的修剪发生在较低的阈值。在较高的阈值时,速度开始下降,因为有更多的情况下没有对齐点超过阈值,在这种情况下,修剪被禁用,例如算法中所讨论的(第16-17行)。

六、论文总结与评价
该成果主要包括引入多头注意力机制并额外添加对齐信息。初始化部分对齐信息为假设对齐,随后通过联合词汇预测和对齐修剪进行对齐抽取,从而在保证预测精度的条件下能够得到不错的对齐结果。这个对齐结果即为目标句子中每个词或词组对应于原始句子的词或词汇的位置。这项工作可以帮助人们在翻译的结果中找出其相对应的原始词汇,同时解决了注意力机制在对齐上的不足。这项工作并非开山之作,但相比于使用RNN做编码与解码效果更好。
参考文献
【1】Tamer Alkhouli, Gabriel Bretschner, Jan-Thorsten Peter, Mohammed Hethnawi, Andreas Guta, and Hermann Ney. 2016. Alignment-based neural machine translation. In Proceedings of the First Conference on Machine Translation, pages 54–65, Berlin, Germany.
【2】Tamer Alkhouli and Hermann Ney. 2017. Biasing attention-based recurrent neural networks using external alignment information. In EMNLP 2017 Second Conference on Machine Translation, pages 108–117, Copenhagen, Denmark.
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。
















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











