 优化GPT-3:In-ContextLearning的样本选择策略
优化GPT-3:In-ContextLearning的样本选择策略










 文章探讨了在不进行微调的情况下,如何通过精心挑选的In-ContextExamples提升GPT-3的表现。提出了KATE方法,基于近邻原则选择训练样本,以增强模型在NLP任务中的性能。实验表明,这种方法在情感分析、Table-to-Text和问答任务上优于随机采样和传统KNN方法。
文章探讨了在不进行微调的情况下,如何通过精心挑选的In-ContextExamples提升GPT-3的表现。提出了KATE方法,基于近邻原则选择训练样本,以增强模型在NLP任务中的性能。实验表明,这种方法在情感分析、Table-to-Text和问答任务上优于随机采样和传统KNN方法。
【In-Context Learning】What Makes Good In-Context Examples for GPT-3?
In-Context Learning是最近比较火热的方向,其主要针对超大规模模型(例如1750B参数量的GPT-3模型),在只提供少量标注样本作为提示的前提下,即可以实现很惊艳的效果。
In-Context Learning的影响因素有很多,例如挑选什么样的样本作为提示?本文主要关注在标注样本的挑选上。
一、动机
- GPT-3在NLP中影响力很大,其提出 In-Context Learning(ICL) ,旨在通过少量的标注样本作为提示来避免对大模型进行fine-tuning;
- 尽管in-context learning是强有力多技能的方法,GPT-3依然有许多不足之处。例如in-context learning examples是随机挑选的。因此,本文主要研究在没有fine-tune的条件下,如何审慎地挑选in-context examples来提升GPT-3的效果。
Despite its powerful and versatile in-context learning ability, GPT-3 has some practical challenge.
We observe that the performance of GPT-3 tends to fluctuate with different choices of in-context examples.
However, currently GPT-3 has not been released to public for fine-tuning. Even if it is available, fine-tuning GPT-3 requires hun- dreds of GPUs to load the 175B model, which is prohibitively expensive and time-consuming for ordinary research labs.
Another issue is that stor- ing large fine-tuned model checkpoints require huge storage space.
- 我们的任务需要task-specific training set。我们观察到挑选的in-context example如果在embedding空间中与test sample更近,将会带来更好的效果。因此我们基于 近邻原则 来挑选in-context example;
二、方法
基于GPT-3的ICL可以视为条件生成问题,给定 kkk 个labeled examples,并将其拼接起来作为上下文context,记作 CCC,ICL的任务目标是根据上下文 CCC 和新的输入 xxx ,预测 xxx 对应的标签 yyy:
pLM(y∣C,x)=∏t=1tp(yt∣C,x,y<t)p_{LM}(y|C, x)=\prod_{t=1}^{t}p(y_t|C, x, y_{<t})pLM(y∣C,x)=t=1∏tp(yt∣C,x,y<t)
在提出方法之前,我们进行了一些预先探索。挑选问答有关的Natural Question(NQ)数据集,采用精准匹配(EM)评价指标。
EM是指只预测的答案和标准答案必须完全匹配才算正确
给定一个测试样本,设置两种采样策略:
- Farthest:随机利用10个training instance作为in-context example,
- Closest:使用RoBERTa-large模型的CLS embeddings表示每个训练样本的表征向量。根据 KKK 近邻规则,根据欧氏距离选择10个距离当前test example最近的10个training example;
实验发现最近邻效果最好。
基于此发现,我们整理了我们的想法,并提出KATE采样方法。如图所示:
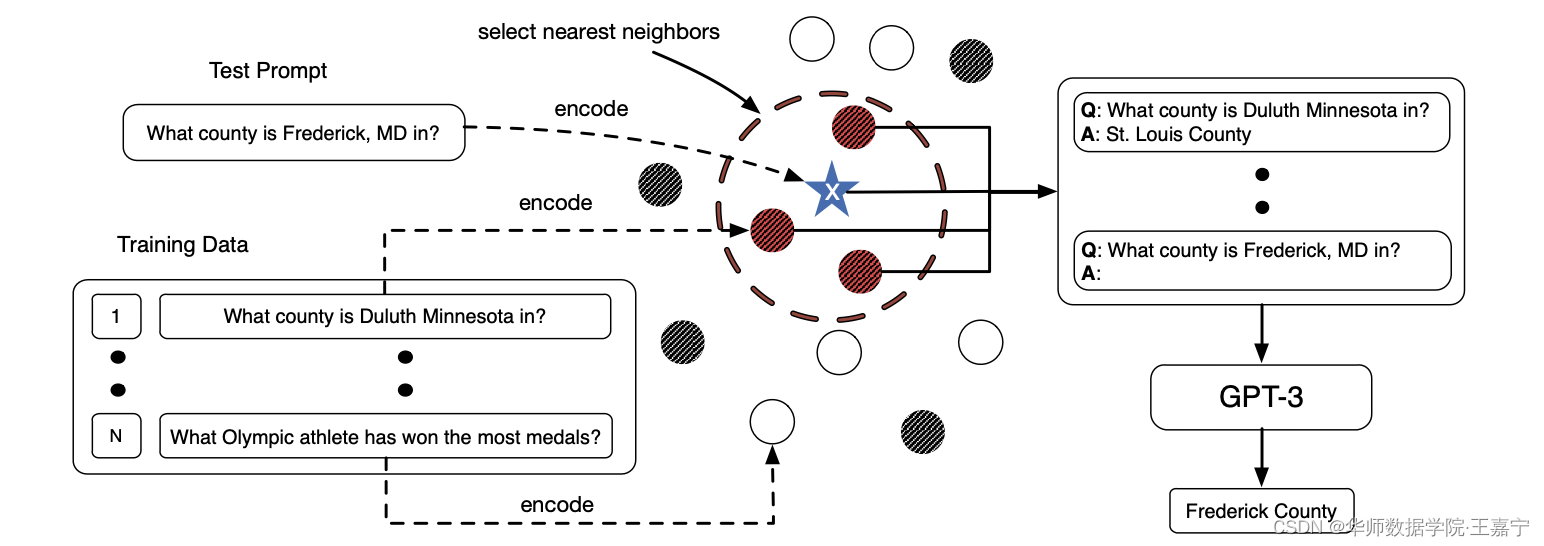
方法的具体流程如下所示:
- 首先对训练集和测试集上所有样本使用encoder进行表征,获得句子embedding;
- 给定一个测试集及其对应的embedding,从训练集中根据欧氏距离或相似度进行排序,获得Top KKK 训练样本,作为in-context example;算法如下图:

用于retrieve的encoder(获得句子表征的模型)可以选择:
- 普通的预训练语言模型,例如BERT、RoBERTa、XLNET等;
- 在相关文本标准数据集上进行fine-tune的模型,例如Sentence-BERT;
三、实验
挑选如下几个数据集作为评测任务:
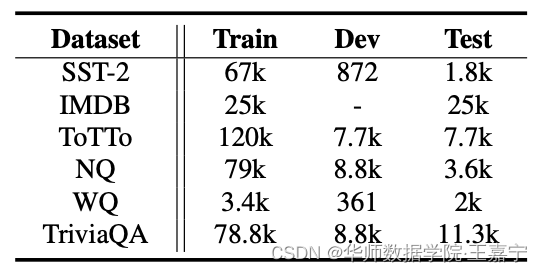
在不同类型任务上的实验设置:
(1)情感分析
探索data-transfer场景。例如在SST-2的训练集中挑选in-context example,测试集来自于IMDB,用于评测模型在IMDB的效果。in-context example数量设置为3;
(2)Table-to-text生成
给定wikipedia表以及cell,旨在生成可读的文本。in-context example数量为2;
(3)问答Question Answering
选择NQ、WebQuestion和TriviaQA作为测试。NQ和WQ的in-context example数量为64,TriviaQA为10。在NQ和WQ的测试集上测试,TriviaQA的验证集上测试。
Baseline选择:
- random:传统的in-context learning,demonstration 是随机挑选的;
- KNN:传统的KNN算法,对于每个测试样本,获取K个最近邻样本,并根据标签投票获得票数最多的类作为预测结果;
- Fine-tuned T5:直接使用Fine-tuning的方法,作为对照,反应不同任务效果的天花板。
实验结果如下所示:
(1)在情感分析任务上,本文的方法超越了所有的baseline。当KATE的encoder选择不同的模型获得句子embedding时,效果也有所不同,并发现当在SST-2数据集上进行句子表征的预训练时效果最好。这也说明了在同一个domain或分布的数据上预训练句子表征向量可以进一步提高召回的in-context example与测试样本的相关性。

(2)在Table-to-Text任务上,提出的KATE方法也是最佳的,远远超过随机采样和简单进行K近邻的方法。
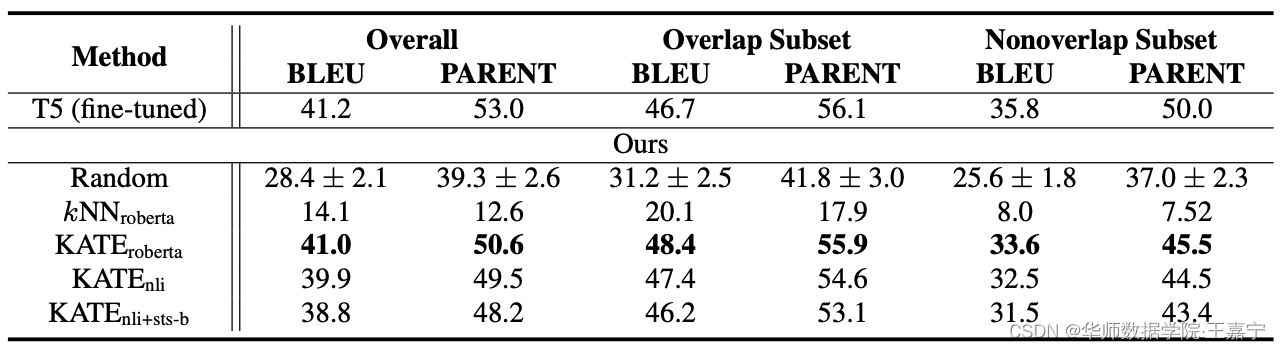
(3)问答任务上,本文的方法也达到了SOTA性能
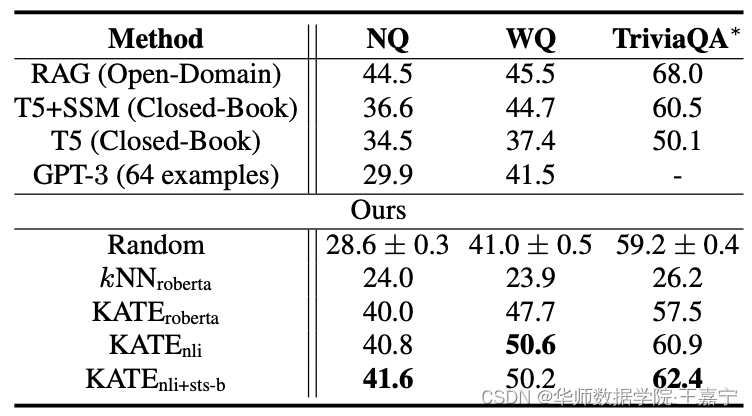
作者也进行了一些拓展实验来验证提出的KATE方法的一些性能情况。
(1)Number of In-context Examples
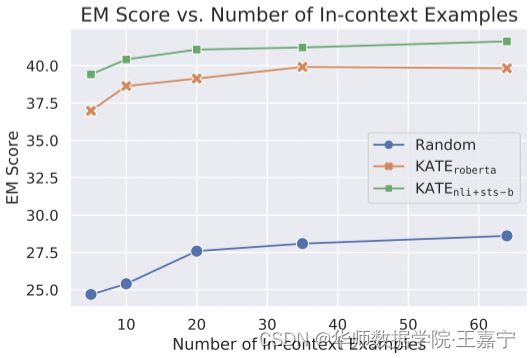
在NQ数据集上测试,结论:
- Both KATE and the random baseline benefit from utilizing more examples;
- KATE consistently outperforms the random selec- tion method
(2)Size of Training Set for Retrieval
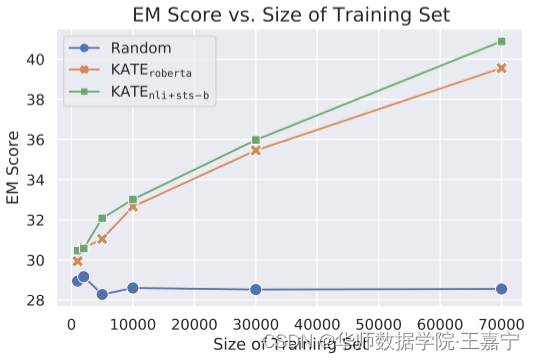
依然在NQ数据集上测试,挑选不同大小的subset作为检索池。in-context learning example数量依然是64。可发现当搜索空间变大时,KATE效果提升明显,但对random没有影响;
(3)Order of In-context Examples
探索挑选的in-context example的顺序是否对模型有影响。

作者认为reverse是最好的,且认为样本选择取决于数据本身。
个人认为order可能影响并不大,不过直觉来看,或许对于GPT来说,由于是由左向右生成策略,越靠近后面的example越重要(即越靠近待预测的样本的demonstration example越重要)
优缺点:
- KATE方法简单有效;
- 建立在语义空间相似的原则,方法直观,且具备可解释;
- 依然需要大量的训练集来支撑对每个test example去检索合适的in-context example。如果有标注的训练样本很少甚至没有,该方法无法work;
- 对于每个test example,都要重新计算 KKK 近邻,比较耗时间。


















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











