







 本文介绍了CatBoost,一种基于梯度提升的集成模型,特别强调了其处理类别型特征的能力和自动特征缩放的优点。同时讨论了训练时间长、内存消耗大和超参数调节的挑战,以及一个Python代码示例展示了如何使用CatBoost进行分类任务。
本文介绍了CatBoost,一种基于梯度提升的集成模型,特别强调了其处理类别型特征的能力和自动特征缩放的优点。同时讨论了训练时间长、内存消耗大和超参数调节的挑战,以及一个Python代码示例展示了如何使用CatBoost进行分类任务。
目录
一、简介
CatBoost是一种梯度提升决策树(Gradient Boosting Decision Tree)的集成模型。梯度提升是一种通过训练一系列弱学习器来构建一个强大的集成模型的技术。CatBoost是从XGBoost和LightGBM中发展而来的一种优化版本。
CatBoost最独特的特点是它对类别型特征的处理方式。传统的梯度提升决策树通常需要将类别型特征转换为数值型特征,例如使用独热编码或者标签编码。而CatBoost采用了一种特殊的有序目录分类(Ordered boosting)算法,可以直接处理类别型特征,无需进行转换。
CatBoost模型的训练过程是迭代的。首先,它会初始化一个弱学习器(通常是决策树),然后通过梯度下降算法来优化该学习器的预测能力。在每一轮迭代中,CatBoost会计算残差(真实值与当前模型的预测值之差),然后将残差作为目标变量来训练下一个弱学习器。最后,将所有弱学习器的预测结果相加得到最终的预测结果。
CatBoost具有自动特征缩放的功能,可以自动处理特征的缩放问题。此外,它还具有一些其他的优化技术,如对称二叉树布局、基于直方图的加速和数据并行计算等,以提高模型的训练速度和准确性。
二、优缺点介绍
优点:
-
支持分类和回归问题:CatBoost可以应用于各种机器学习任务,包括二分类、多分类和回归问题。
-
支持类别型特征:CatBoost能够处理类别型特征,无需进行独热编码或标签编码。它采用了一种特殊的算法,称为有序目录分类(Ordered boosting),能够自动处理分类变量。
-
自动特征缩放:CatBoost可以自动处理特征的缩放问题,减少了特征预处理的工作量。
-
鲁棒性:CatBoost对于缺失值和异常值具有较好的鲁棒性,能够处理噪声和不完整的数据。
-
快速训练:CatBoost在训练模型时采用了并行计算技术,可以加快训练速度,并且具有高效的内存使用。
缺点:
-
训练时间较长:相对于其他梯度提升框架,CatBoost的训练时间可能较长,特别是在具有大量特征和数据的情况下。
-
内存消耗较大:CatBoost在内存使用上相对较高,可能需要更多的计算资源。
-
超参数调节:CatBoost有一些重要的超参数需要调节,例如学习率、树的深度等。不正确的参数选择可能导致过拟合或欠拟合。
三、Python代码示例
from catboost import CatBoostClassifier, Pool
from sklearn.datasets import load_iris
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, f1_score, recall_score
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=30)
# 创建CatBoost分类器
catboost_model = CatBoostClassifier(iterations=100, depth=3, learning_rate=0.1, classes_count=3, loss_function='MultiClass')
# 将数据转换为CatBoost特定的数据结构
data_pool = Pool(X_train, y_train)
# 拟合模型
catboost_model.fit(data_pool)
y_pred = catboost_model.predict(X_test)
test_accuracy = sum(np.transpose(y_pred)[0] == y_test) / len(y_test)
print(f"测试准确度: {test_accuracy * 100}%")
report = classification_report(y_test, y_pred)
print(report)
f1_scores = f1_score(y_test, y_pred, average='macro')
recalls = recall_score(y_test, y_pred, average='macro')
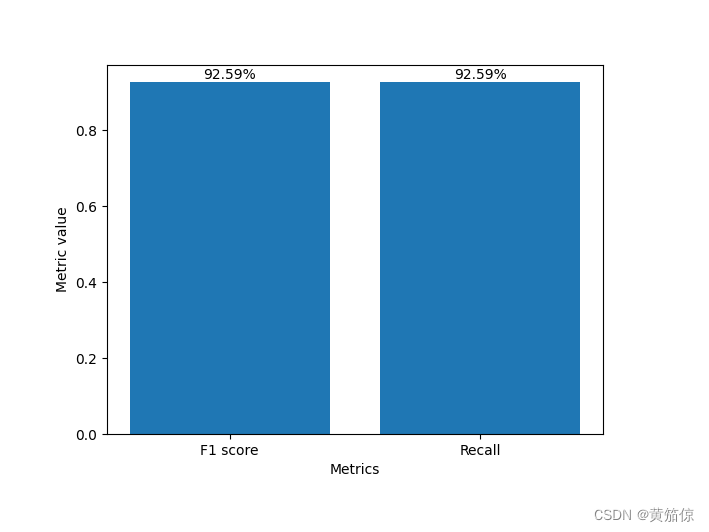
# 绘制F1分数和召回率的曲线
plt.figure()
plt.bar(['F1 score', 'Recall'], [f1_scores, recalls])
plt.text('F1 score', f1_scores, "{:.2f}%".format(f1_scores * 100), ha='center', va='bottom')
plt.text('Recall', f1_scores, "{:.2f}%".format(recalls * 100), ha='center', va='bottom')
plt.xlabel('Metrics')
plt.ylabel('Metric value')
plt.show()
plt.savefig(fname="result.png")效果
四、总结
CatBoost是一种强大的机器学习模型,适用于处理分类和回归问题,尤其擅长处理类别型特征。然而,使用它需要考虑到训练时间、内存消耗和超参数调节等因素。



















 2308
2308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











