










 本教程详述了基于ESRGAN模型的超分辨率项目搭建流程,涵盖环境配置、数据集处理、模型训练及测试等关键环节,适用于深度学习初学者及图像处理爱好者。
本教程详述了基于ESRGAN模型的超分辨率项目搭建流程,涵盖环境配置、数据集处理、模型训练及测试等关键环节,适用于深度学习初学者及图像处理爱好者。
博主搭建项目参考借鉴的代码框架是:https://github.com/xinntao/BasicSR
博主搭建项目参考的论文地址为:https://arxiv.org/pdf/1809.00219.pdf
博主翻译论文网址:ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks 翻译
目录
一、环境和依赖项声明
1.操作系统:Windows10 64位
2.IDE:vs2017
3.深度学习环境:
CUDA 9.0
cuDNN 7.1
Torch ≥0.4.1
4.PyThon环境
Anaconda 3(Python3.6)
5.官方Python依赖项:numpy、opencv-python、lmdb
pip install numpy opencv-python lmdb二、项目设置
1.下载完成之后,你的BasicSR文件夹应该是如下显示:

2.打开vs2017,新建项目->选择Python->从现有的Python代码,我们选择我们下载好的BasicSR文件夹的位置,项目名称也改为BasicSR,之后点击确定:
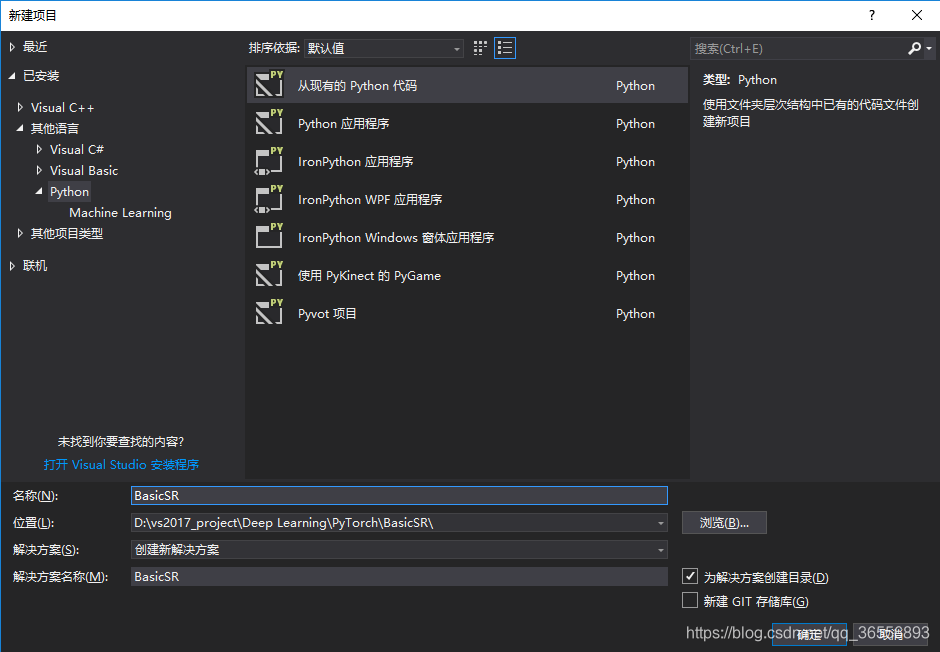
3.之后,我们会看到在现有代码基础上生成的项目:
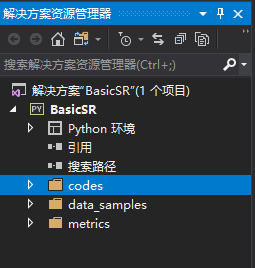
4.值得注意的是,你的conda环境里可能没有lmdb,因为该论文作者认为生成lmdb可以用于加快IO速度,详情请见官方网址:https://github.com/xinntao/BasicSR/wiki/Faster-IO-speed,lmdb的引入被用在了create_lmdb.py这个文件中:
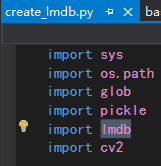
作者解释:

5.我们可以直接使用vs2017里的功能安装lmdb这个包,具体步骤为:
(1)右键Python环境->查看所有Python环境
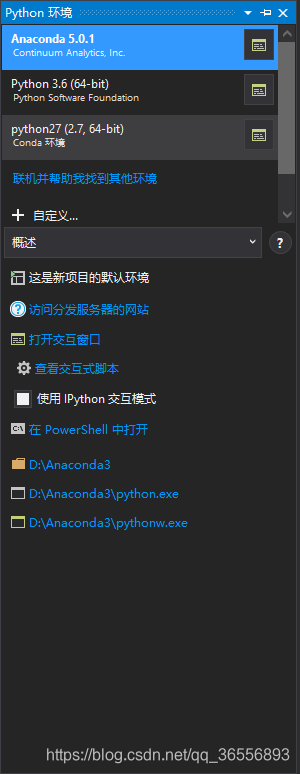
(2)点击+自定义下的概述,将选项变为包(PyPI)
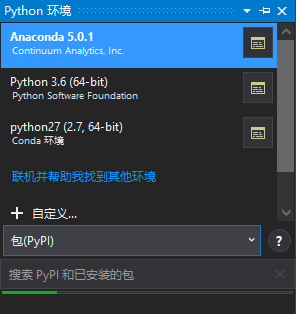
(3)在下方输入lmdb,会出现提示:运行命令:pip install lmdb
(4)点击这个选项,我们就可以看到在输出界面显示下载进度(由于博主这之前已经安装了这个包,因此提示已经安装了):

三、数据集下载
1.官方的数据集真的是帮了我很大的忙,因为之前博主寻找Set5和Set14数据集十分困难,花了很长的时间,最终在这里找到了,下载地址为:classical_SR_datasets
这些都是经典数据集,感谢作者!!!
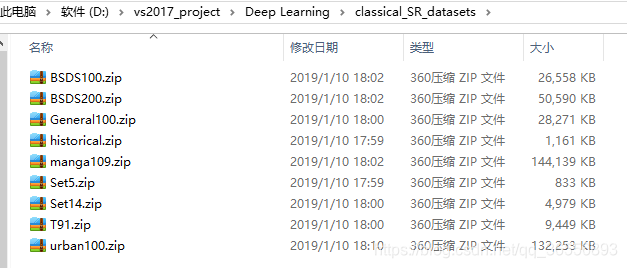
2.我们在这里主要用到的测试数据集是Set5和Set14,其中5和14代表了数据集里图片的个数。下载完成后文件夹如下:
3.我们解压Set5和Set14文件夹到指定目录中,这里博主建议放在工程目录下,博主在工程目录下新建了一个文件夹为BasicSR_datasets
例如,博主解压路径为:
(1)D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\val_set5\Set5
(2)D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\val_set14\Set14
4.如果想训练模型,我们也需要对测试数据集进行验证,因此我们还需要将Set14文件夹复制一份,路径是:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\val_set14_part\Set14

5.我们还需要一个巨大的数据集来训练我们的模型,下载地址为:DIV2K,值得注意的是作者选取了DIV2K数据集中编号为0001到0800的800张图片作为处理的对象,我们可以将其解压至这个路径:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\DIV2K800\DIV2K800,如下图:
四、DIV2K数据准备
1.我们希望输入的格式满足一定的要求,而对于DIV2K这样的数据集图片按MB计算大小,因此需要裁剪为子图像减少计算量等因素:
2.幸运的是,作者提供了一个文件去裁剪这样的图片,博主这里的目录是:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\codes\scripts\extract_subimgs_single.py
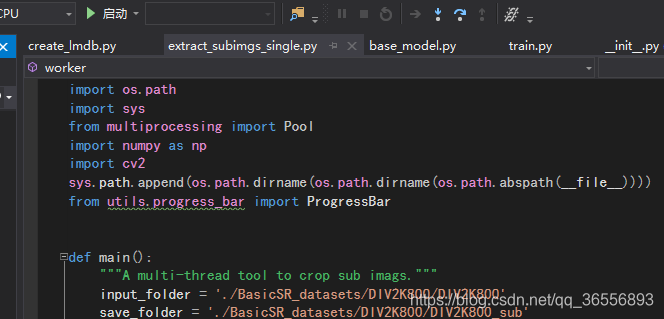
3.文件内容如下,我们需要修改:
import os
import os.path
import sys
from multiprocessing import Pool
import numpy as np
import cv2
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.progress_bar import ProgressBar
def main():
"""A multi-thread tool to crop sub imags."""
input_folder = '/mnt/SSD/xtwang/BasicSR_datasets/DIV2K800/DIV2K800'
save_folder = '/mnt/SSD/xtwang/BasicSR_datasets/DIV2K800/DIV2K800_sub'
n_thread = 20
crop_sz = 480
step = 240
thres_sz = 48
compression_level = 3 # 3 is the default value in cv2
# CV_IMWRITE_PNG_COMPRESSION from 0 to 9. A higher value means a smaller size and longer
# compression time. If read raw images during training, use 0 for faster IO speed.
if not os.path.exists(save_folder):
os.makedirs(save_folder)
print('mkdir [{:s}] ...'.format(save_folder))
else:
print('Folder [{:s}] already exists. Exit...'.format(save_folder))
sys.exit(1)
img_list = []
for root, _, file_list in sorted(os.walk(input_folder)):
path = [os.path.join(root, x) for x in file_list] # assume only images in the input_folder
img_list.extend(path)
def update(arg):
pbar.update(arg)
pbar = ProgressBar(len(img_list))
pool = Pool(n_thread)
for path in img_list:
pool.apply_async(worker,
args=(path, save_folder, crop_sz, step, thres_sz, compression_level),
callback=update)
pool.close()
pool.join()
print('All subprocesses done.')
def worker(path, save_folder, crop_sz, step, thres_sz, compression_level):
img_name = os.path.basename(path)
img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
n_channels = len(img.shape)
if n_channels == 2:
h, w = img.shape
elif n_channels == 3:
h, w, c = img.shape
else:
raise ValueError('Wrong image shape - {}'.format(n_channels))
h_space = np.arange(0, h - crop_sz + 1, step)
if h - (h_space[-1] + crop_sz) > thres_sz:
h_space = np.append(h_space, h - crop_sz)
w_space = np.arange(0, w - crop_sz + 1, step)
if w - (w_space[-1] + crop_sz) > thres_sz:
w_space = np.append(w_space, w - crop_sz)
index = 0
for x in h_space:
for y in w_space:
index += 1
if n_channels == 2:
crop_img = img[x:x + crop_sz, y:y + crop_sz]
else:
crop_img = img[x:x + crop_sz, y:y + crop_sz, :]
crop_img = np.ascontiguousarray(crop_img)
# var = np.var(crop_img / 255)
# if var > 0.008:
# print(img_name, index_str, var)
cv2.imwrite(
os.path.join(save_folder, img_name.replace('.png', '_s{:03d}.png'.format(index))),
crop_img, [cv2.IMWRITE_PNG_COMPRESSION, compression_level])
return 'Processing {:s} ...'.format(img_name)
if __name__ == '__main__':
main()
值得注意的是路径的变化,可以看到这个项目是在linux环境下跑的,那么window10其实也可以跑,只不过会有一些小问题,这个在之后博主会提到,在此先忽略。
不管怎么说,我们需要改成我们的路径,博主这里将input_folder和save_folder进行了修改,第一是因为绝对路径很麻烦,第二是改成自己的路径方便之后的一些处理(在这之后还需要这样的步骤很多次):
input_folder = './BasicSR_datasets/DIV2K800/DIV2K800'
save_folder = './BasicSR_datasets/DIV2K800/DIV2K800_sub'注意这里我们不需要新建DIV2K800_sub这个文件夹,这个是这个.py文件运行时会生成的。
最终博主的代码为:
extract_subimgs_single.py
import os
import os.path
import sys
from multiprocessing import Pool
import numpy as np
import cv2
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.progress_bar import ProgressBar
def main():
"""A multi-thread tool to crop sub imags."""
input_folder = './BasicSR_datasets/DIV2K800/DIV2K800'
save_folder = './BasicSR_datasets/DIV2K800/DIV2K800_sub'
n_thread = 20
crop_sz = 480
step = 240
thres_sz = 48
compression_level = 3 # 3 is the default value in cv2
# CV_IMWRITE_PNG_COMPRESSION from 0 to 9. A higher value means a smaller size and longer
# compression time. If read raw images during training, use 0 for faster IO speed.
if not os.path.exists(save_folder):
os.makedirs(save_folder)
print('mkdir [{:s}] ...'.format(save_folder))
else:
print('Folder [{:s}] already exists. Exit...'.format(save_folder))
sys.exit(1)
img_list = []
for root, _, file_list in sorted(os.walk(input_folder)):
path = [os.path.join(root, x) for x in file_list] # assume only images in the input_folder
img_list.extend(path)
def update(arg):
pbar.update(arg)
pbar = ProgressBar(len(img_list))
pool = Pool(n_thread)
for path in img_list:
pool.apply_async(worker,
args=(path, save_folder, crop_sz, step, thres_sz, compression_level),
callback=update)
pool.close()
pool.join()
print('All subprocesses done.')
def worker(path, save_folder, crop_sz, step, thres_sz, compression_level):
img_name = os.path.basename(path)
img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
n_channels = len(img.shape)
if n_channels == 2:
h, w = img.shape
elif n_channels == 3:
h, w, c = img.shape
else:
raise ValueError('Wrong image shape - {}'.format(n_channels))
h_space = np.arange(0, h - crop_sz + 1, step)
if h - (h_space[-1] + crop_sz) > thres_sz:
h_space = np.append(h_space, h - crop_sz)
w_space = np.arange(0, w - crop_sz + 1, step)
if w - (w_space[-1] + crop_sz) > thres_sz:
w_space = np.append(w_space, w - crop_sz)
index = 0
for x in h_space:
for y in w_space:
index += 1
if n_channels == 2:
crop_img = img[x:x + crop_sz, y:y + crop_sz]
else:
crop_img = img[x:x + crop_sz, y:y + crop_sz, :]
crop_img = np.ascontiguousarray(crop_img)
# var = np.var(crop_img / 255)
# if var > 0.008:
# print(img_name, index_str, var)
cv2.imwrite(
os.path.join(save_folder, img_name.replace('.png', '_s{:03d}.png'.format(index))),
crop_img, [cv2.IMWRITE_PNG_COMPRESSION, compression_level])
return 'Processing {:s} ...'.format(img_name)
if __name__ == '__main__':
main()
4.我们右键这个文件->设置为启动文件,可以看到这个文件被加粗了
5.我们点击启动按钮:
6.裁剪DIV2K800的结果如下:

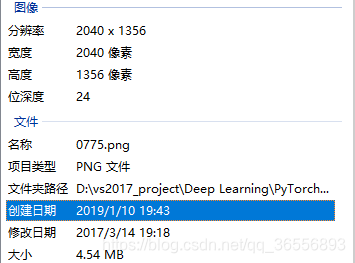
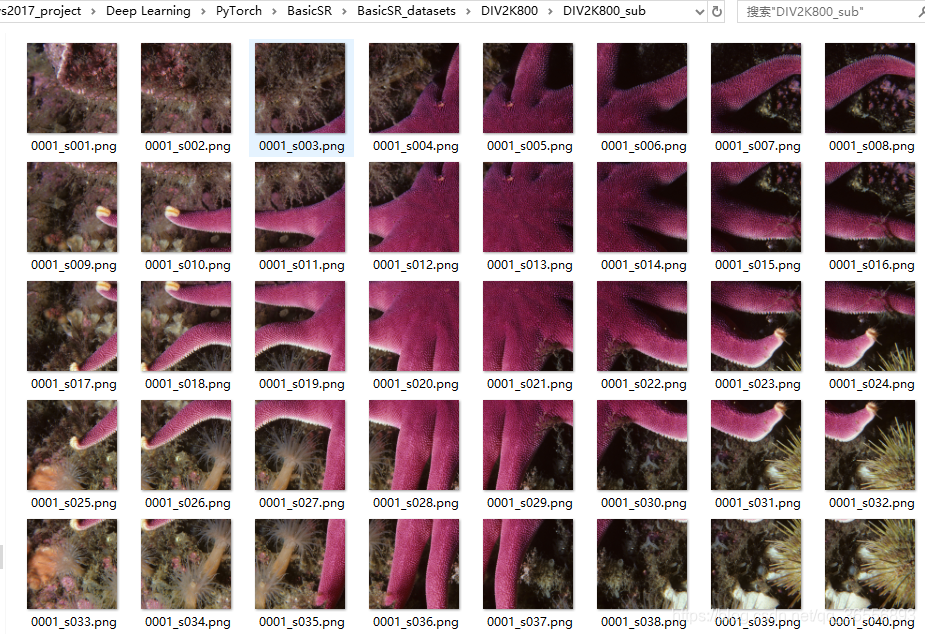
7.进入D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\DIV2K800\DIV2K800_sub,我们可以看到一张图片被裁减的40个子图片,博主一共生成了32208张。以0001.png为例:
(1)原图片:

(2)生成的子图片:
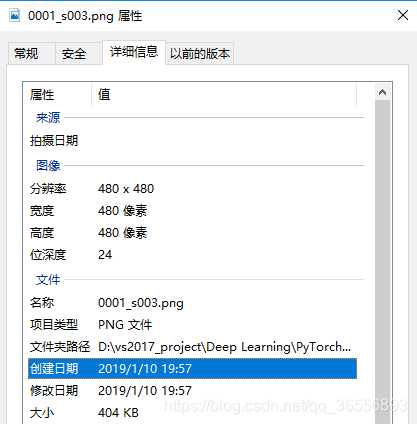
我们选择一张图片查看其大小,发现为480*480*3 = 43200 = 691200
8.我们需要生成LR图像,作者这里提供了这样的一个文件,由matlab编写,博主路径为:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\codes\scripts\generate_mod_LR_bic.m
9.同样的,我们需要修改路径,博主这里是下面这样的:
input_folder = '../../BasicSR_datasets/DIV2K800/DIV2K800_sub';
save_LR_folder = '../../BasicSR_datasets/DIV2K800/DIV2K800_sub_bicLRx4'; 
10.过程如下:

11.完成后,我们可以看到双三次下采样子图像的结果,路径为:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\DIV2K800\DIV2K800_sub_bicLRx4

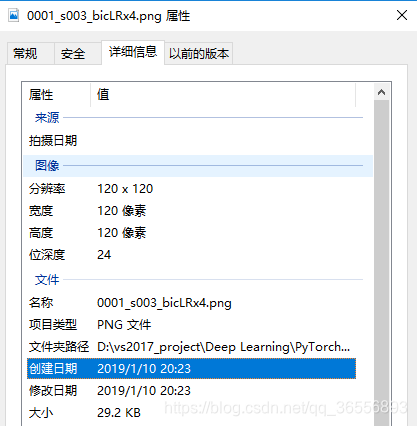
我们选择一张图片查看其大小,发现为120*120*3 = 43200
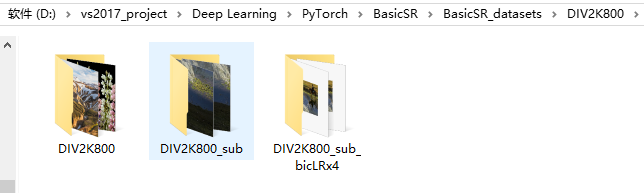
12.最终你的DIV2K800的文件夹里内容应该是这样的:
- DIV2K800:原数据集
- DIV2K800_sub:裁剪子图像数据集
- DIV2K800_sub_bicLRx4:双三次下采样子图像数据集
五、Set5和Set14数据准备
1.和DIV2K800一样,我们同样需要对这两个数据集进行下采样
(1)set14的路径为:
input_folder = '../../BasicSR_datasets/val_set14_part/Set14';
save_LR_folder = '../../BasicSR_datasets/val_set14_part/Set14_bicLRx4'; 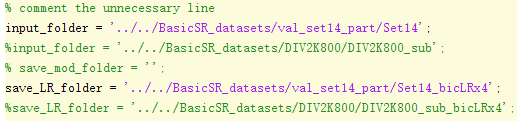
(2)Set5的路径为:
input_folder = '../../BasicSR_datasets/val_set5/Set5';
save_LR_folder = '../../BasicSR_datasets/val_set5/Set5_bicLRx4'; 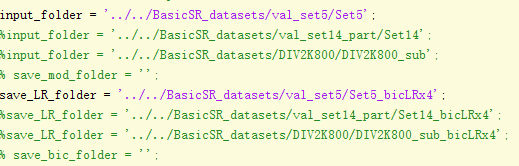
2.下采样结果:
(1)Set14:
(2)Set5:

3.我们同样可以在文件夹里看到生成的下采样结果:
(1)Set14:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\val_set14\Set14_bicLRx4
(2)Set5:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\BasicSR_datasets\val_set5\Set5_bicLRx4
六、下载预训练模型(可选)
1.作者提供了很多的预训练模型,由于我们需要训练ESRGAN,因此我们只需要下载这样的预训练模型即可:
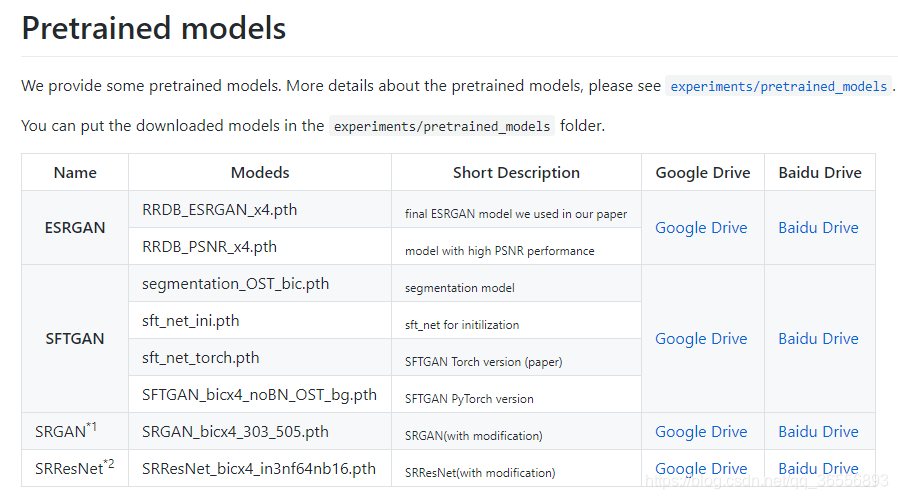
2.我们下载包含RRDB_ESRGAN_x4.pth和RRDB_PSNR_x4.pth的百度文件,链接地址为:ESRGAN_models
3.最终,博主将这两个预训练模型放在如下文件夹底下:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\experiments\pretrained_models
七、修改配置.json文件
1.训练配置路径:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\codes\options\train
(1)修改文件名为train_ESRGAN.json,先指出修改的几处地方:
-
datasets的train(训练)部分修改HR和LR的路径,改为我们的DIV2K800的数据集位置:
"dataroot_HR": "./BasicSR_datasets/DIV2K800/DIV2K800_sub"
"dataroot_LR": "./BasicSR_datasets/DIV2K800/DIV2K800_sub_bicLRx4"- datasets的val部分修改HR和LR的路径,改为我们的Set14的数据集位置:
"dataroot_HR": "./BasicSR_datasets/val_set14_part/Set14"
"dataroot_LR": "./BasicSR_datasets/val_set14_part/Set14_bicLRx4"- path的root部分修改为我们的项目位置,博主这里是:
"root": "D:/vs2017_project/Deep Learning/PyTorch/BasicSR"- path的pretrain_model_G部分修改为我们的预训练模型位置,博主这里是:
"pretrain_model_G": "./experiments/pretrained_models/RRDB_ESRGAN_x4.pth"当然这个可以注销,如果不想使用预训练模型,可以改为null:
"pretrain_model_G": null(2)最终,博主的文件修改如下:
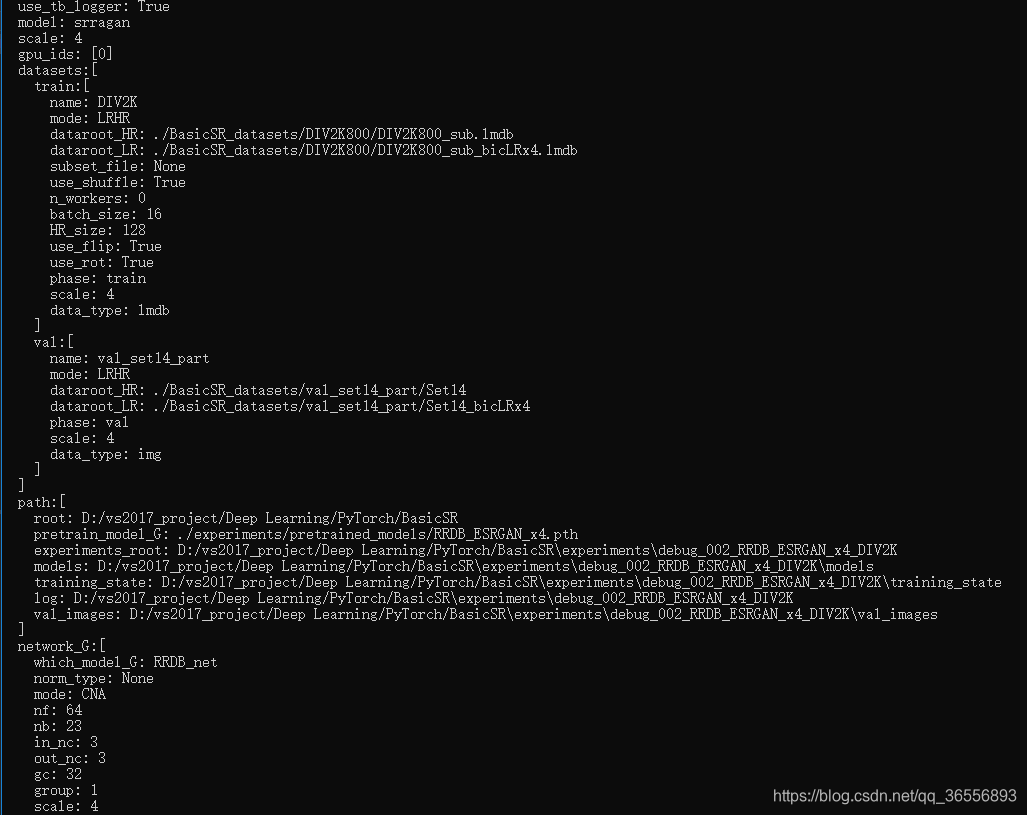
train_ESRGAN.json
{
"name": "debug_002_RRDB_ESRGAN_x4_DIV2K" // please remove "debug_" during training
//"name": "002_RRDB_ESRGAN_x4_DIV2K"
, "use_tb_logger": true
, "model":"srragan"
, "scale": 4
, "gpu_ids": [0]
, "datasets": {
"train": {
"name": "DIV2K"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/DIV2K800/DIV2K800_sub"
, "dataroot_LR": "./BasicSR_datasets/DIV2K800/DIV2K800_sub_bicLRx4"
, "subset_file": null
, "use_shuffle": true
, "n_workers": 8
, "batch_size": 16
, "HR_size": 128
, "use_flip": true
, "use_rot": true
}
, "val": {
"name": "val_set14_part"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/val_set14_part/Set14"
, "dataroot_LR": "./BasicSR_datasets/val_set14_part/Set14_bicLRx4"
}
}
, "path": {
"root": "D:/vs2017_project/Deep Learning/PyTorch/BasicSR"
, "resume_state": "./experiments/debug_002_RRDB_ESRGAN_x4_DIV2K/training_state/16.state"
, "pretrain_model_G": "./experiments/pretrained_models/RRDB_ESRGAN_x4.pth"
//, "pretrain_model_G": null
}
, "network_G": {
"which_model_G": "RRDB_net" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
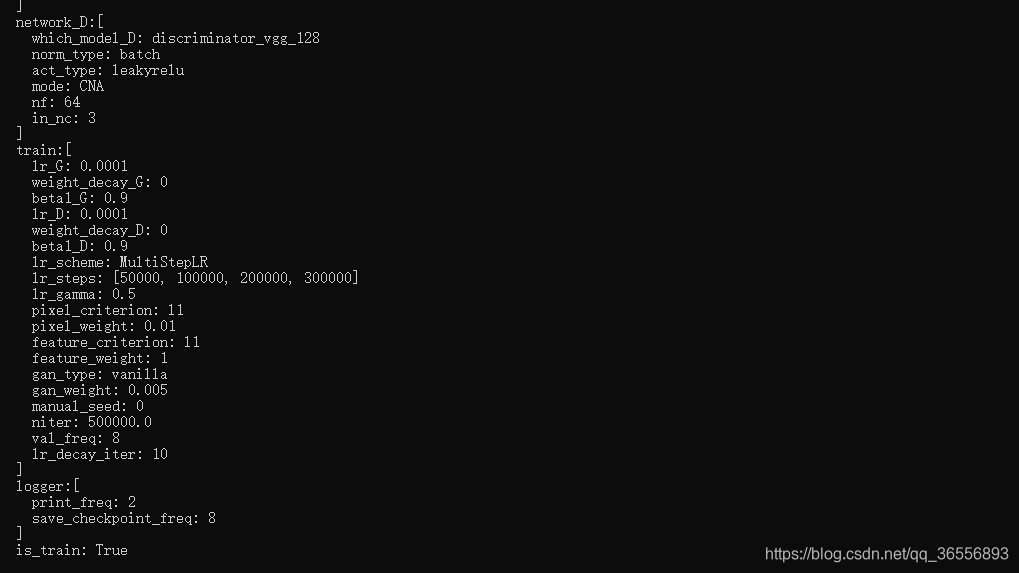
, "network_D": {
"which_model_D": "discriminator_vgg_128"
, "norm_type": "batch"
, "act_type": "leakyrelu"
, "mode": "CNA"
, "nf": 64
, "in_nc": 3
}
, "train": {
"lr_G": 1e-4
, "weight_decay_G": 0
, "beta1_G": 0.9
, "lr_D": 1e-4
, "weight_decay_D": 0
, "beta1_D": 0.9
, "lr_scheme": "MultiStepLR"
, "lr_steps": [50000, 100000, 200000, 300000]
, "lr_gamma": 0.5
, "pixel_criterion": "l1"
, "pixel_weight": 1e-2
, "feature_criterion": "l1"
, "feature_weight": 1
, "gan_type": "vanilla"
, "gan_weight": 5e-3
//for wgan-gp
//, "D_update_ratio": 1
//, "D_init_iters": 0
// , "gp_weigth": 10
, "manual_seed": 0
, "niter": 5e5
, "val_freq": 5e3
}
, "logger": {
"print_freq": 200
, "save_checkpoint_freq": 5e3
}
}
2.测试配置路径:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\codes\options\test
(1)和训练配置一样,我们同样需要修改test_ESRGAN.json文件:
test_ESRGAN.json
{
"name": "RRDB_ESRGAN_x4"
, "suffix": "_ESRGAN"
, "model": "srragan"
, "scale": 4
, "gpu_ids": [0]
, "datasets": {
"test_1": { // the 1st test dataset
"name": "set5"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "./BasicSR_datasets/val_set5/Set5_bicLRx4"
}
, "test_2": { // the 2nd test dataset
"name": "set14"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/val_set14/Set14"
, "dataroot_LR": "./BasicSR_datasets/val_set14/Set14_bicLRx4"
}
}
, "path": {
"root": "D:/vs2017_project/Deep Learning/PyTorch/BasicSR"
, "pretrain_model_G": "./experiments/pretrained_models/RRDB_ESRGAN_x4.pth"
}
, "network_G": {
"which_model_G": "RRDB_net" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
}(2)由于我们还下载了RRDB_PSNR_x4.pth这个模型文件,因此我们需要新建一个名为test_PSNR.json的文件:
test_PSNR.json
{
"name": "RRDB_PSNR_x4"
, "suffix": "_PSNR"
, "model": "srragan"
, "scale": 4
, "gpu_ids": [0]
, "datasets": {
"test_1": { // the 1st test dataset
"name": "set5"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/val_set5/Set5"
, "dataroot_LR": "./BasicSR_datasets/val_set5/Set5_bicLRx4"
}
, "test_2": { // the 2nd test dataset
"name": "set14"
, "mode": "LRHR"
, "dataroot_HR": "./BasicSR_datasets/val_set14/Set14"
, "dataroot_LR": "./BasicSR_datasets/val_set14/Set14_bicLRx4"
}
}
, "path": {
"root": "D:/vs2017_project/Deep Learning/PyTorch/BasicSR"
, "pretrain_model_G": "./experiments/pretrained_models/RRDB_PSNR_x4.pth"
}
, "network_G": {
"which_model_G": "RRDB_net" // RRDB_net | sr_resnet
, "norm_type": null
, "mode": "CNA"
, "nf": 64
, "nb": 23
, "in_nc": 3
, "out_nc": 3
, "gc": 32
, "group": 1
}
}3.实际上,这里最重要的就是pretrain_model_G的路径,一定要指定正确!
八、测试
1.测试文件的路径为:D:\vs2017_project\Deep Learning\PyTorch\BasicSR\codes\test.py
test.py
import os
import sys
import logging
import time
import argparse
import numpy as np
from collections import OrderedDict
import options.options as option
import utils.util as util
from data.util import bgr2ycbcr
from data import create_dataset, create_dataloader
from models import create_model
# options
parser = argparse.ArgumentParser()
parser.add_argument('-opt', type=str, required=True, help='Path to options JSON file.')
opt = option.parse(parser.parse_args().opt, is_train=False)
util.mkdirs((path for key, path in opt['path'].items() if not key == 'pretrain_model_G'))
opt = option.dict_to_nonedict(opt)
util.setup_logger(None, opt['path']['log'], 'test.log', level=logging.INFO, screen=True)
logger = logging.getLogger('base')
logger.info(option.dict2str(opt))
# Create test dataset and dataloader
test_loaders = []
for phase, dataset_opt in sorted(opt['datasets'].items()):
test_set = create_dataset(dataset_opt)
test_loader = create_dataloader(test_set, dataset_opt)
logger.info('Number of test images in [{:s}]: {:d}'.format(dataset_opt['name'], len(test_set)))
test_loaders.append(test_loader)
# Create model
model = create_model(opt)
for test_loader in test_loaders:
test_set_name = test_loader.dataset.opt['name']
logger.info('\nTesting [{:s}]...'.format(test_set_name))
test_start_time = time.time()
dataset_dir = os.path.join(opt['path']['results_root'], test_set_name)
util.mkdir(dataset_dir)
test_results = OrderedDict()
test_results['psnr'] = []
test_results['ssim'] = []
test_results['psnr_y'] = []
test_results['ssim_y'] = []
for data in test_loader:
need_HR = False if test_loader.dataset.opt['dataroot_HR'] is None else True
model.feed_data(data, need_HR=need_HR)
img_path = data['LR_path'][0]
img_name = os.path.splitext(os.path.basename(img_path))[0]
model.test() # test
visuals = model.get_current_visuals(need_HR=need_HR)
sr_img = util.tensor2img(visuals['SR']) # uint8
# save images
suffix = opt['suffix']
if suffix:
save_img_path = os.path.join(dataset_dir, img_name + suffix + '.png')
else:
save_img_path = os.path.join(dataset_dir, img_name + '.png')
util.save_img(sr_img, save_img_path)
# calculate PSNR and SSIM
if need_HR:
gt_img = util.tensor2img(visuals['HR'])
gt_img = gt_img / 255.
sr_img = sr_img / 255.
crop_border = test_loader.dataset.opt['scale']
cropped_sr_img = sr_img[crop_border:-crop_border, crop_border:-crop_border, :]
cropped_gt_img = gt_img[crop_border:-crop_border, crop_border:-crop_border, :]
psnr = util.calculate_psnr(cropped_sr_img * 255, cropped_gt_img * 255)
ssim = util.calculate_ssim(cropped_sr_img * 255, cropped_gt_img * 255)
test_results['psnr'].append(psnr)
test_results['ssim'].append(ssim)
if gt_img.shape[2] == 3: # RGB image
sr_img_y = bgr2ycbcr(sr_img, only_y=True)
gt_img_y = bgr2ycbcr(gt_img, only_y=True)
cropped_sr_img_y = sr_img_y[crop_border:-crop_border, crop_border:-crop_border]
cropped_gt_img_y = gt_img_y[crop_border:-crop_border, crop_border:-crop_border]
psnr_y = util.calculate_psnr(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
ssim_y = util.calculate_ssim(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
test_results['psnr_y'].append(psnr_y)
test_results['ssim_y'].append(ssim_y)
logger.info('{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}; PSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}.'\
.format(img_name, psnr, ssim, psnr_y, ssim_y))
else:
logger.info('{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}.'.format(img_name, psnr, ssim))
else:
logger.info(img_name)
if need_HR: # metrics
# Average PSNR/SSIM results
ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
logger.info('----Average PSNR/SSIM results for {}----\n\tPSNR: {:.6f} dB; SSIM: {:.6f}\n'\
.format(test_set_name, ave_psnr, ave_ssim))
if test_results['psnr_y'] and test_results['ssim_y']:
ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
logger.info('----Y channel, average PSNR/SSIM----\n\tPSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}\n'\
.format(ave_psnr_y, ave_ssim_y))
2.值得注意的是,这个程序运行时会报错,这是windows系统的问题。报错为:
The xxx line can be omitted if the program is not going to be frozen to produce an executable.
因为windows系统下默认用spawn方法部署多线程,而不是 fork 。所以我们需要在代码入口加上一个判断来防止程序多次执行
3.解决方法:把调用多进程的代码放到__main__模块下即可。最终给出博主修改后的文件:
test.py
import os
import sys
import logging
import time
import argparse
import numpy as np
from collections import OrderedDict
import options.options as option
import utils.util as util
from data.util import bgr2ycbcr
from data import create_dataset, create_dataloader
from models import create_model
def main():
# options
parser = argparse.ArgumentParser()
parser.add_argument('-opt', type=str, required=True, help='Path to options JSON file.')
opt = option.parse(parser.parse_args().opt, is_train=False)
util.mkdirs((path for key, path in opt['path'].items() if not key == 'pretrain_model_G'))
opt = option.dict_to_nonedict(opt)
util.setup_logger(None, opt['path']['log'], 'test.log', level=logging.INFO, screen=True)
logger = logging.getLogger('base')
logger.info(option.dict2str(opt))
# Create test dataset and dataloader
test_loaders = []
for phase, dataset_opt in sorted(opt['datasets'].items()):
test_set = create_dataset(dataset_opt)
test_loader = create_dataloader(test_set, dataset_opt)
logger.info('Number of test images in [{:s}]: {:d}'.format(dataset_opt['name'], len(test_set)))
test_loaders.append(test_loader)
# Create model
model = create_model(opt)
for test_loader in test_loaders:
test_set_name = test_loader.dataset.opt['name']
logger.info('\nTesting [{:s}]...'.format(test_set_name))
test_start_time = time.time()
dataset_dir = os.path.join(opt['path']['results_root'], test_set_name)
util.mkdir(dataset_dir)
test_results = OrderedDict()
test_results['psnr'] = []
test_results['ssim'] = []
test_results['psnr_y'] = []
test_results['ssim_y'] = []
for data in test_loader:
need_HR = False if test_loader.dataset.opt['dataroot_HR'] is None else True
model.feed_data(data, need_HR=need_HR)
img_path = data['LR_path'][0]
img_name = os.path.splitext(os.path.basename(img_path))[0]
model.test() # test
visuals = model.get_current_visuals(need_HR=need_HR)
sr_img = util.tensor2img(visuals['SR']) # uint8
# save images
suffix = opt['suffix']
if suffix:
save_img_path = os.path.join(dataset_dir, img_name + suffix + '.png')
else:
save_img_path = os.path.join(dataset_dir, img_name + '.png')
util.save_img(sr_img, save_img_path)
# calculate PSNR and SSIM
if need_HR:
gt_img = util.tensor2img(visuals['HR'])
gt_img = gt_img / 255.
sr_img = sr_img / 255.
crop_border = test_loader.dataset.opt['scale']
cropped_sr_img = sr_img[crop_border:-crop_border, crop_border:-crop_border, :]
cropped_gt_img = gt_img[crop_border:-crop_border, crop_border:-crop_border, :]
psnr = util.calculate_psnr(cropped_sr_img * 255, cropped_gt_img * 255)
ssim = util.calculate_ssim(cropped_sr_img * 255, cropped_gt_img * 255)
test_results['psnr'].append(psnr)
test_results['ssim'].append(ssim)
if gt_img.shape[2] == 3: # RGB image
sr_img_y = bgr2ycbcr(sr_img, only_y=True)
gt_img_y = bgr2ycbcr(gt_img, only_y=True)
cropped_sr_img_y = sr_img_y[crop_border:-crop_border, crop_border:-crop_border]
cropped_gt_img_y = gt_img_y[crop_border:-crop_border, crop_border:-crop_border]
psnr_y = util.calculate_psnr(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
ssim_y = util.calculate_ssim(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
test_results['psnr_y'].append(psnr_y)
test_results['ssim_y'].append(ssim_y)
logger.info('{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}; PSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}.'\
.format(img_name, psnr, ssim, psnr_y, ssim_y))
else:
logger.info('{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}.'.format(img_name, psnr, ssim))
else:
logger.info(img_name)
if need_HR: # metrics
# Average PSNR/SSIM results
ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
logger.info('----Average PSNR/SSIM results for {}----\n\tPSNR: {:.6f} dB; SSIM: {:.6f}\n'\
.format(test_set_name, ave_psnr, ave_ssim))
if test_results['psnr_y'] and test_results['ssim_y']:
ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
logger.info('----Y channel, average PSNR/SSIM----\n\tPSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}\n'\
.format(ave_psnr_y, ave_ssim_y))
if __name__ == '__main__':
main()4.除此之外,我们还需要设置命令行参数。
vs2017中Python的命令行参数设置步骤如下,以test.py为例:
(1)先设置test.py为启动文件,会有加粗提示:
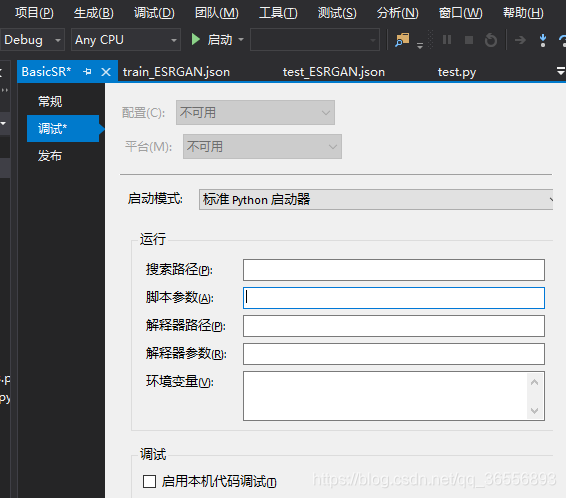
(2)菜单栏点击项目->BasicSR(你的项目)属性,我们可以看到弹出了一个窗口,窗口左侧有3栏。我们点击调试栏,可以看到脚本参数这一项,这就是我们命令行参数的填写位置:
(3)我们对RRDB_ESRGAN_x4.pth模型进行测试,这也是作者在论文中使用的最终ESRGAN模型。如下填写:
-opt ./codes/options/test/test_ESRGAN.json 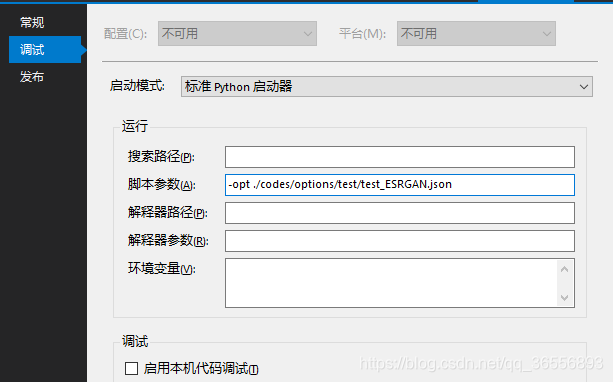
(4)点击启动按钮,对Set5和Set14数据集进行测试,测试结果如下:
- Set5:
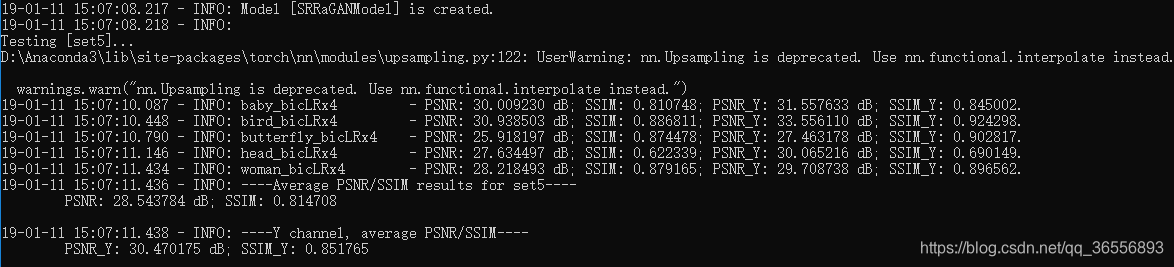
可以看到PSNR_Y是30.470175dB,SSIM_Y是0.851765
- Set14:
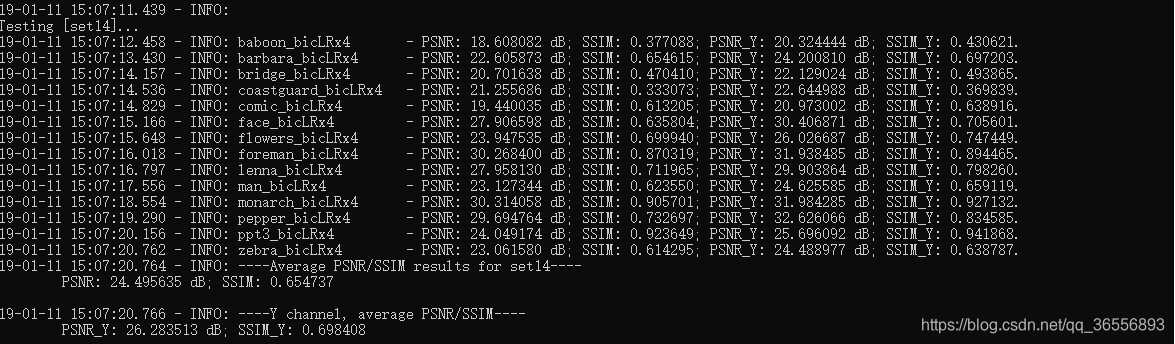
可以看到PSNR_Y是26.283513dB,SSIM_Y是0.698408
(5)我们对RRDB_PSNR_x4.pth模型进行测试,这也是作者给出具有高PSNR性能的模型。如下填写:
-opt ./codes/options/test/test_PSNR.json(6)点击启动按钮,对Set5和Set14数据集进行测试,测试结果如下:
- Set5:
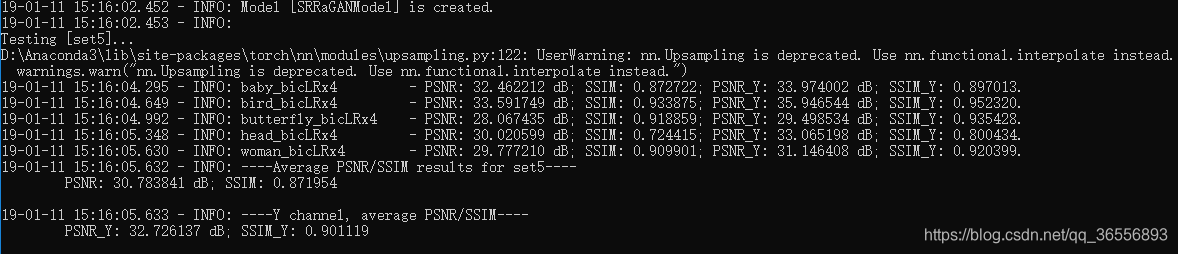
可以看到PSNR_Y是32.726137dB,SSIM_Y是0.901119
- Set14:
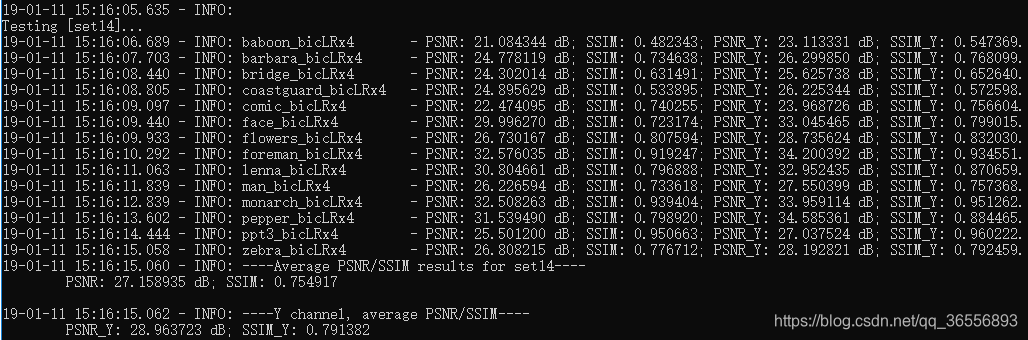
可以看到PSNR_Y是28.963723dB,SSIM_Y是0.791382
九、训练
1.训练是一个非常耗时和耗内存的过程,不建议一口气训练,而是阶段性的训练。好在作者很好地写出了读取自己训练模型的代码,防止从头开始训练。以train_ESRGAN.json为例,将path的resume_state的注释取消即可,例如下面的截图:

从头开始训练时注释不用取消!!
2.和测试一样,我们同样需要填写命令行参数:
-opt ./codes/options/train/train_ESRGAN.json 
3.将train.py设置为启动文件,点击启动按钮,开始训练,弹出的框依次显示如下:
(1)生成本次运行训练的文件夹:
![]()
(2)显示读取的train_ESRGAN.json相关配置:
(3)随机种子:
![]()
(4)创建数据存储集:

(6)初始化方法:
![]()
(7)读取预训练模型(可选):
![]()
- Network G结构:
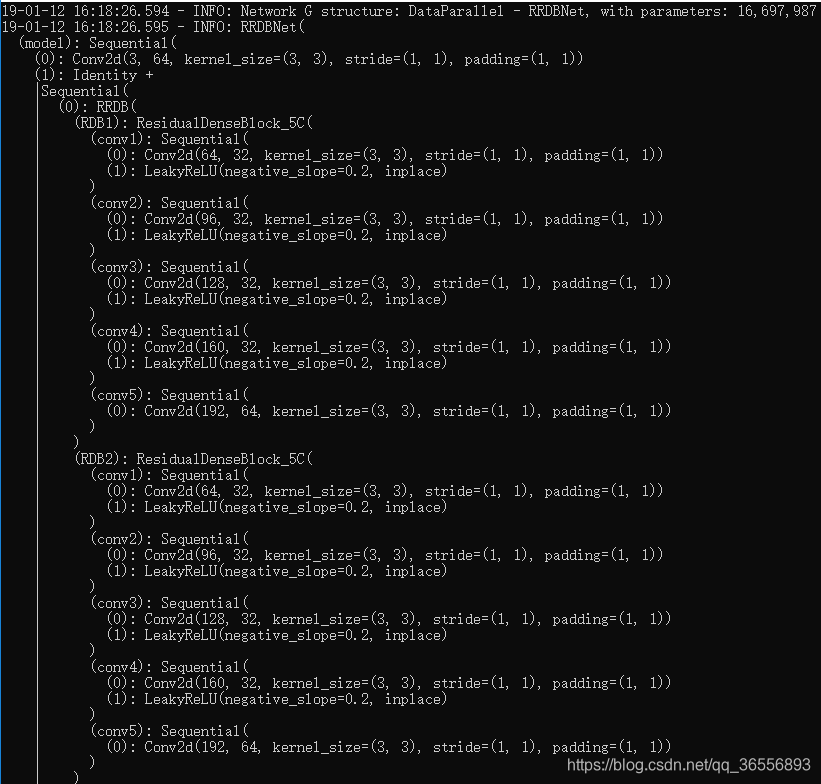
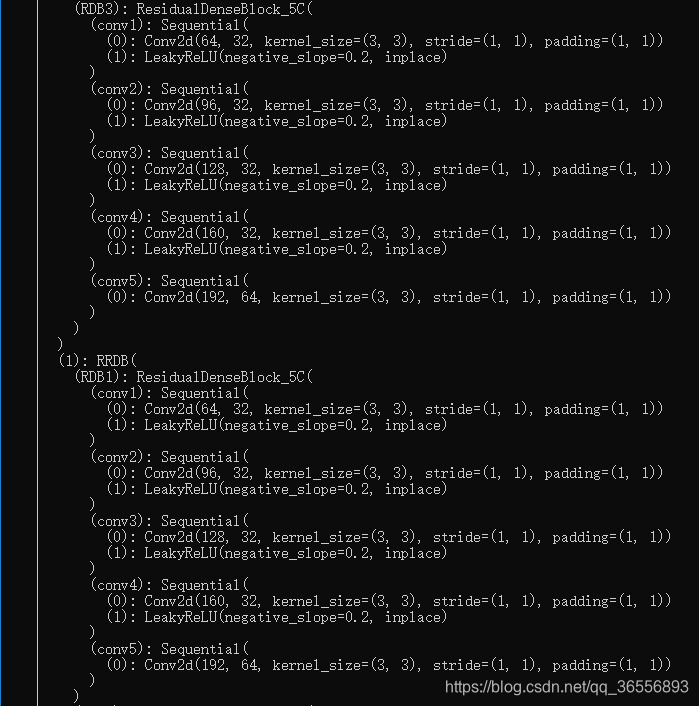
。。。。。。。。。。。。。。。。。。

- Network D结构:
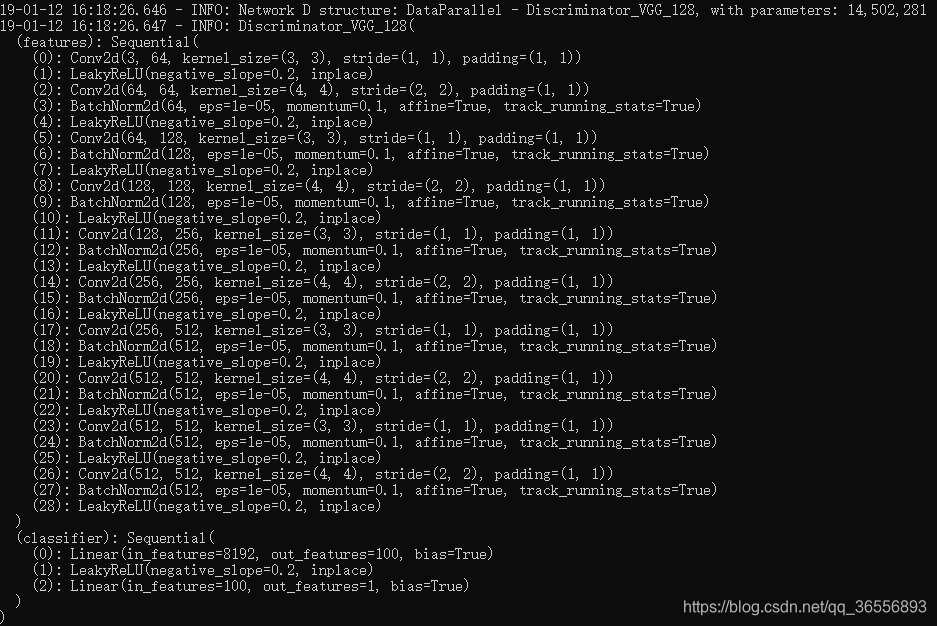
- Network F结构:
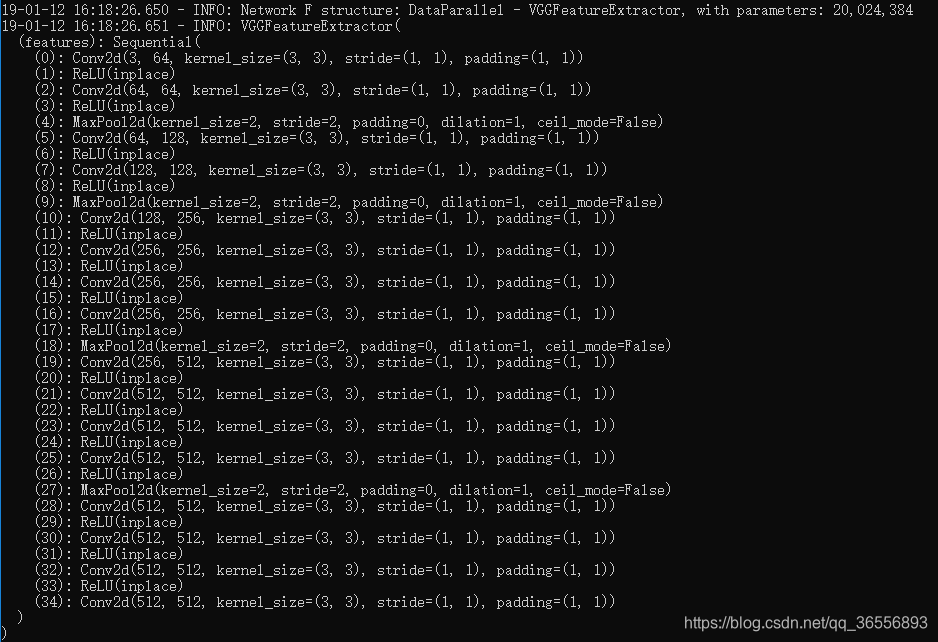
- 模型创建完成:
![]()
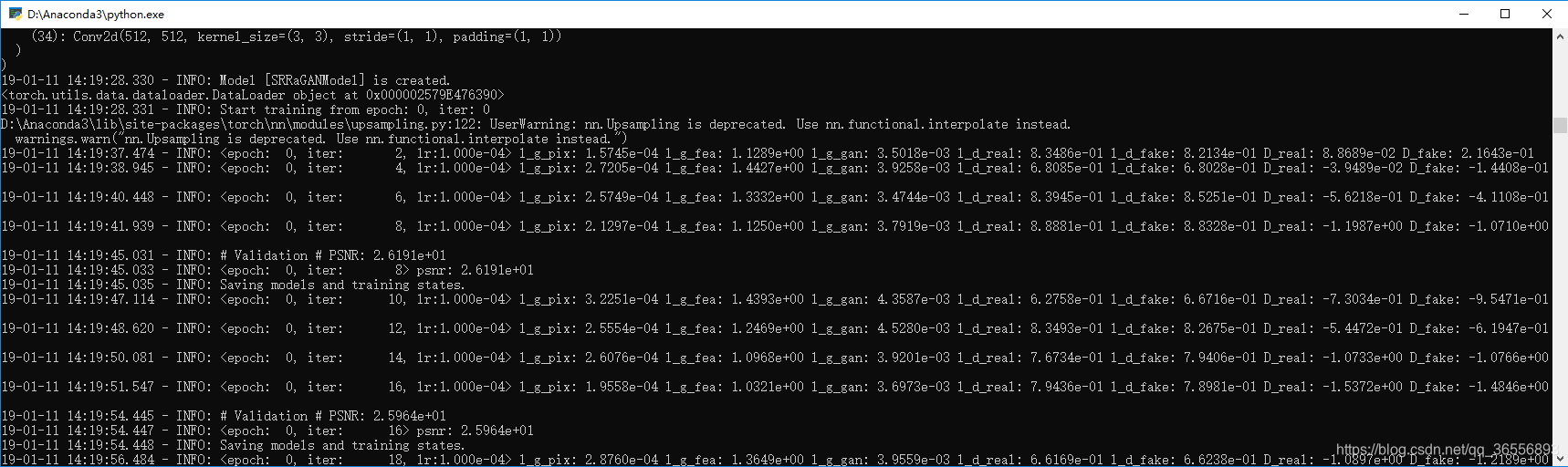
(8)利用Dataloader读取训练数据,开始训练。例如我们训练到了iter为16暂停,可以看到8和16的时候分别存储了state,并且验证了PSNR:

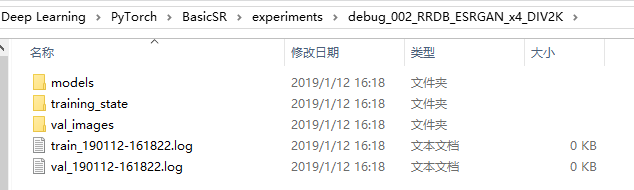
4,,我们去训练文件夹看看,博主的路径为:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\experiments\debug_002_RRDB_ESRGAN_x4_DIV2K
(1)models文件夹:
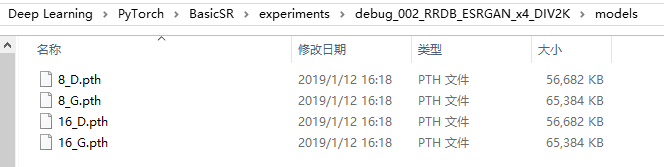
(2)trainning_state文件夹:

(3)val_images验证图片文件夹:
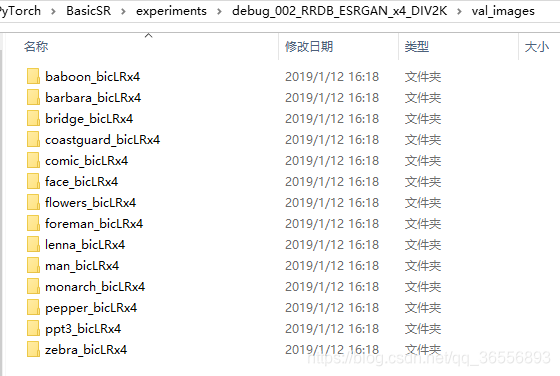
我们选择其中几个文件夹进行查看效果:
- baboon_bicLRx4:
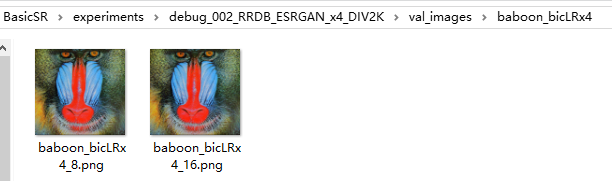


- pepper_bicLRx4
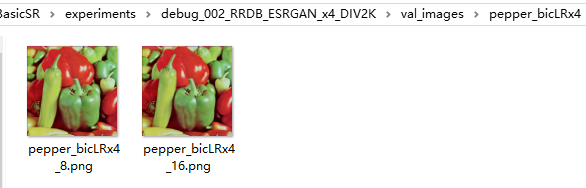


感觉还可以,不过这才只是运行了几步,训练的过程比这个要漫长的多~
5.实际上会有很多这样的图片,例如下面这样:
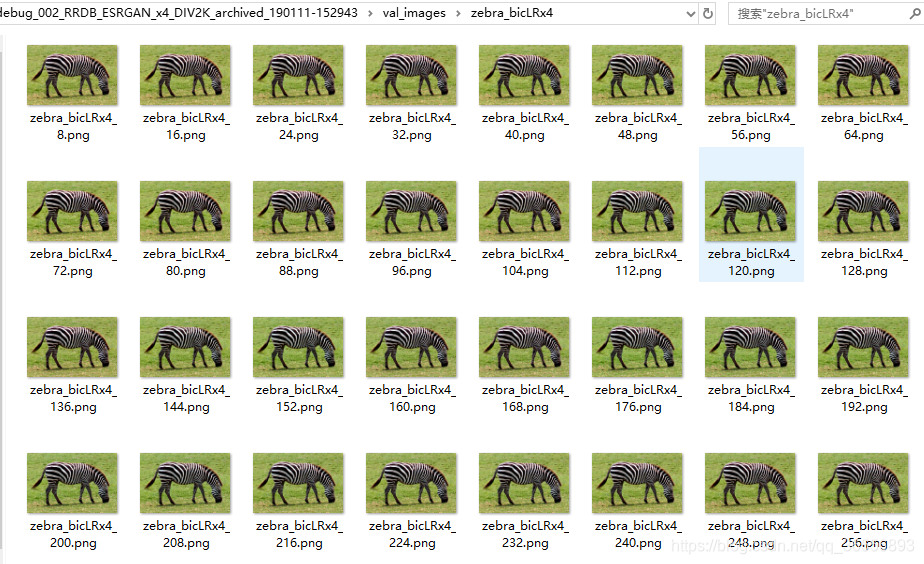
开始训练:
6.如果想从某个状态开始训练而不是从头开始,可以像之前说的一样,resume_state取消注释。例如博主从16.state开始:
(1)开始显示会多出读取的各种数据状态:
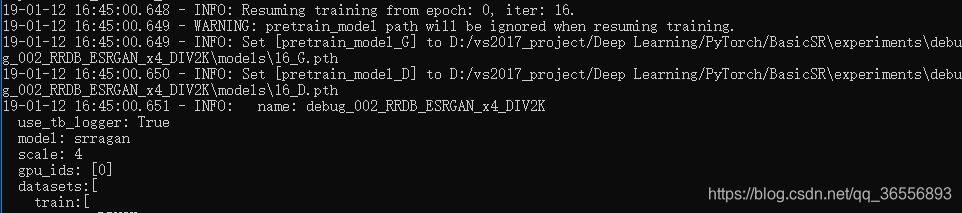
(2)从iter为16开始:

7.如果想用tensorboard,只需要把.json文件里name的地方的“debug_”删除即可,默认路径是:
D:\vs2017_project\Deep Learning\PyTorch\BasicSR\tb_logger

十、注意事项
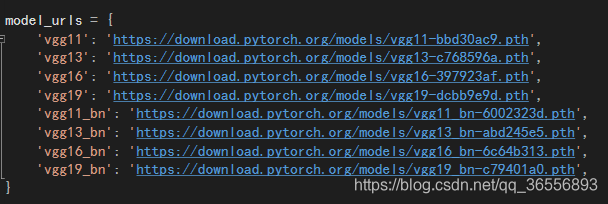
1.整个过程中你可能会下载VGG19模型,该模型会被默认下载在:C:\Users\你的名字\.torch,原理就是torchvision包里存在模型的函数下载,路径被保存在model_urls中,觉得速度慢的可以利用下载工具下载,然后放在.torch文件夹中:
2.生成的lmdb数据有问题,可以选择直接读取图片
十一、总结
转自作者的说明:
增强的SRGAN模型(它还可以训练 SRGAN模型)。增强的SRGAN实现了始终如一的更好的视觉质量,比 SRGAN更加逼真和自然的纹理,并在 PIRM2018-SR挑战赛中获得第一名。
博主认为这样的项目代码框架十分清晰,论文的效果也如此优秀,可以说的上是非常厉害了~
博主翻译论文网址:ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks 翻译
返回至原博客:vs2017安装和使用教程(详细)



















 7072
7072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











