









 本文介绍了深度学习中两种重要的学习率调整策略:Warmup和CosineAnneal。Warmup有助于模型初期的稳定,防止过早过拟合;CosineAnneal则通过余弦退火的方式平滑地调整学习率。通过PyTorch的LambdaLR,实现了两者的结合,展示了具体代码实现和效果。
本文介绍了深度学习中两种重要的学习率调整策略:Warmup和CosineAnneal。Warmup有助于模型初期的稳定,防止过早过拟合;CosineAnneal则通过余弦退火的方式平滑地调整学习率。通过PyTorch的LambdaLR,实现了两者的结合,展示了具体代码实现和效果。
Warm up与Cosine Anneal 浅谈
warm up是深度学习炼丹时常用的一种手段,由于一开始参数不稳定,梯度较大,如果此时学习率设置过大可能导致数值不稳定。使用warm up有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳,其次也有助于保持模型深层的稳定性。
详见 https://www.zhihu.com/question/338066667/answer/771252708
余弦退火是常用的学习率调整策略,目前在Pytorch中已经集成了相应API,见官方文档。其原理如下式,其中 η m a x \eta_{max} ηmax为学习率最大值, η m i n \eta_{min} ηmin为最小值, T c u r T_{cur} Tcur为当前轮次, T m a x T_{max} Tmax为半个周期:
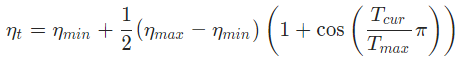
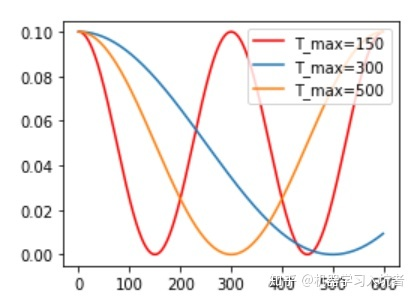
实例如下:
图来自:https://zhuanlan.zhihu.com/p/93624972
torch.optim.lr_scheduler.LambdaLR
虽然Pytorch已经提供了余弦退火的相应API,但是要结合Warm up和Cosine Anneal就没有了相应的操作。
pytorch给我们提供了很多调整学习率的策略(详见官方文档),其中有一个LambdaLR策略,让我们自己能够很方便地制定规则来调整学习率。其中,最重要的参数就是 lr_lambda,传入自定义的函数或lambda表达式,可以对Optimizer中的不同的param_groups制定不同的调整规则。
简单地理解,传入的lr_lambda参数会在梯度下降时对optimizer对应参数组的学习率乘上一个权重系数。
warm up + Cosine Anneal 代码实现
根据上小节介绍的LambdaLR,我们就可以很方便地实现warm up + Cosine Anneal。
需要注意,传入的lr_lambda参数是在原先的学习率上乘以一个权重,因此在实现Cosine Anneal时需要注意在最后除以base_lr。其他细节见代码注释:
import math
import torch
from torchvision.models import resnet18
model = resnet18(pretrained=True) # 加载模型
optimizer = torch.optim.SGD(params=[ # 初始化优化器,并设置两个param_groups
{'params': model.layer2.parameters()},
{'params': model.layer3.parameters(), 'lr':0.2},
], lr=0.1) # base_lr = 0.1
# 设置warm up的轮次为100次
warm_up_iter = 10
T_max = 50 # 周期
lr_max = 0.1 # 最大值
lr_min = 1e-5 # 最小值
# 为param_groups[0] (即model.layer2) 设置学习率调整规则 - Warm up + Cosine Anneal
lambda0 = lambda cur_iter: cur_iter / warm_up_iter if cur_iter < warm_up_iter else \
(lr_min + 0.5*(lr_max-lr_min)*(1.0+math.cos( (cur_iter-warm_up_iter)/(T_max-warm_up_iter)*math.pi)))/0.1
# param_groups[1] 不进行调整
lambda1 = lambda cur_iter: 1
# LambdaLR
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda0, lambda1])
for epoch in range(50):
print(optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'])
optimizer.step()
scheduler.step()
以上代码并无实际意义,仅展现warm up + Cosine Anneal的实现,若要应用到自己的code中,各参数视情况而定。
代码输出结果:
# warm up
0.0 0.2
0.010000000000000002 0.2
0.020000000000000004 0.2
0.03 0.2
0.04000000000000001 0.2
0.05 0.2
0.06 0.2
0.06999999999999999 0.2
0.08000000000000002 0.2
0.09000000000000001 0.2
0.1 0.2
# warm up结束,进行Cosine Anneal
0.09984588209998774 0.2
0.09938447858805392 0.2
0.09861863417028184 0.2
0.09755307053217621 0.2
0.09619435722790179 0.2
0.09455087117679745 0.2
0.09263274501688284 0.2
0.0904518046337755 0.2
0.08802149625017355 0.2
0.08535680352542145 0.2
0.08247415517626752 0.2
0.0793913236883622 0.2
0.07612731574297386 0.2
0.07270225503447865 0.2
0.06913725820109266 0.2
0.0654543046337755 0.2
0.061676100965976005 0.2
0.057825941079686353 0.2
0.05392756249091362 0.2
0.050005 0.2
0.04608243750908641 0.2
0.042184058920313655 0.2
0.03833389903402403 0.2
0.03455569536622451 0.2
0.03087274179890734 0.2
0.027307744965521366 0.2
0.02388268425702614 0.2
0.020618676311637812 0.2
0.017535844823732476 0.2
0.014653196474578559 0.2
0.011988503749826454 0.2
0.009558195366224508 0.2
0.007377254983117161 0.2
0.005459128823202553 0.2
0.0038156427720982197 0.2
0.0024569294678237993 0.2
0.0013913658297181606 0.2
0.0006255214119460928 0.2
0.00016411790001226746 0.2
分析:
可以看到对于参数组[0]进行了warm up + cosine anneal调整,而参数组[1]一直是预设的0.2没有改变。
参考
[1] https://butui.me/post/lamdalr-in-pytorch/
[2] https://pytorch.org/docs/1.2.0/optim.html#how-to-adjust-learning-rate
[3] https://blog.csdn.net/zgcr654321/article/details/106765238

















 7744
7744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









