







MemAE
论文名全称《Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly Detection》
原文地址
https://arxiv.org/abs/1904.02639
论文阅读方法
初识
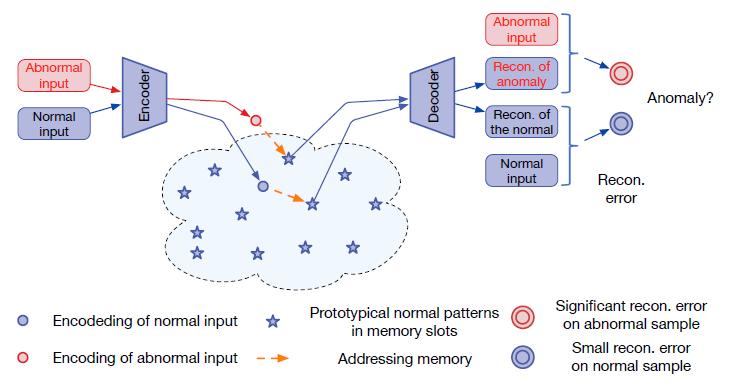
深度自编码器被广泛地用于无监督异常检测领域,但它存在一个问题:对于一些异常区域往往也能重构得很好,从而导致错误的检测结果。 本文给AE新增了一个Memory模块,构建MemAE:给定输入,将编码结果作为query去检索Mem模块中最相似的一项进行重构。
在训练阶段,更新Mem模块中的内容构建正常样本的原型元素(prototypical element);在测试阶段,固定Mem模块内容,根据Mem进行重构,计算重构误差用于异常检测。
相知
这里主要谈核心技术以及部分实验,其他内容见原文
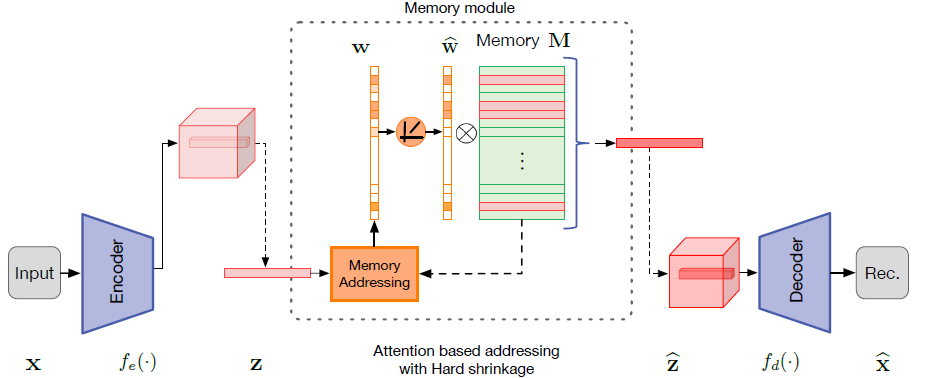
网络的主要结构如上图所示,主要分为三大模块:编码器(对输入进行编码并生成Query),解码器(用于重构),Mem模块(内存以及相应的取址操作)。
其中编码器解码器没啥好说的,就和普通的AE一致,所以主要谈谈Mem模块:
① Memory-based Representation
内存模块其实就是存储一个大小为
N
×
C
N\times C
N×C的矩阵,为了方便起见,其中C与编码结果Z的维度一致。内存元素中每一行用
m
i
m_i
mi表示,每个
m
i
m_i
mi也表示内存中的一个存储项。编码器给出结果z,内存网络根据一个软寻址向量
w
w
w(1xN)得到
z
^
\widehat{z}
z
,w也是根据z计算得到的结果(每一项都非负):
N为超参数,实验证明MemAE对N不敏感,越大越好
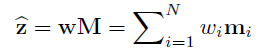
② Attention for Memory Addressing
这里主要将①中的w是怎么算出来的
寻址策略基于注意力机制,计算z与Mem模块中每一项 m i m_i mi的相似度构造注意力权重 w w w,其中d(,)表示cosine相似度:
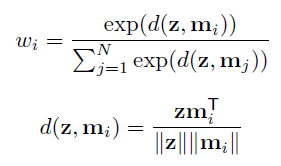
③ Hard Shrinkage for Sparse Addressing
即使用了Attention寻址,但有些异常仍然可能通过
m
i
m_i
mi的复杂组合从而被很好的重构。为了解决这个问题,采用了Hard Shrinkage策略,设置一个阈值,只有当注意力权重大于该值时才有效,否则为0:
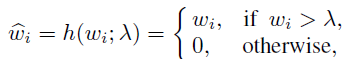
但这个策略无法直接实现,因为不能反向传播,因此作者借用ReLU函数重新实现:
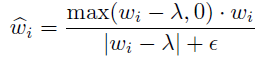
其中max(,)就是ReLU函数,
ϵ
\epsilon
ϵ为一个很小的正数项。阈值通常设置为[1/N, 3/N]之间。在执行Hard Shrinkage,需要再做一次归一化,然后再求得
z
^
\widehat{z}
z
:
作者分析,Mem模块的好处如下:a. 在训练阶段,每次都只利用少量内存项用于重构,促使内存项中每一个元素都是具有代表性的原型。b. 测试时,只有正常样本能够索引到最相似的元素从而进行很好的重构,而异常样本与重构之间的误差会拉大(因为索引到的都是正常内存项)。此外,Hard Shrinkage策略的引入增加了寻址权重的稀疏性,这也进一步使得异常区域不能被很好地重构。
Training
接下来谈谈训练所用的损失,第一个还是AE中的重构误差MSE:
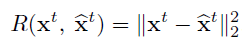
此外,为了进一步地增加w的稀疏性,加入正则化策略,但由于 ∣ ∣ w ^ ∣ ∣ 1 = 1 ||\widehat{w}||_1=1 ∣∣w ∣∣1=1,转换为最小化w的熵(表示数据的无序程度):
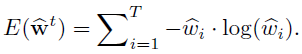
最后,总的损失如下所示,其中α为超参数,经验性设置为0.0002.
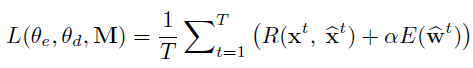
回顾
本文发表于ICCV2019,为了解决在异常检测领域中AE对于异常区域也能重构地很好的问题,创新性地在AE中引入了Mem模块。但做过一些实验,发现其也存在问题:与VAE这类方法类似,基于少数的内存项重构的图像很模糊,在一些现实场景的数据集中表现得并不够好。
代码
官方代码:https://github.com/h19920918/memae?utm_source=catalyzex.com
本人复现代码,欢迎issue与star:https://github.com/Classmate-Huang/CV-AnomalyDetection/tree/master/AE%20%26%20MemAE

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









