







对 DeepSeek - R1 - GRPO 算法的理解
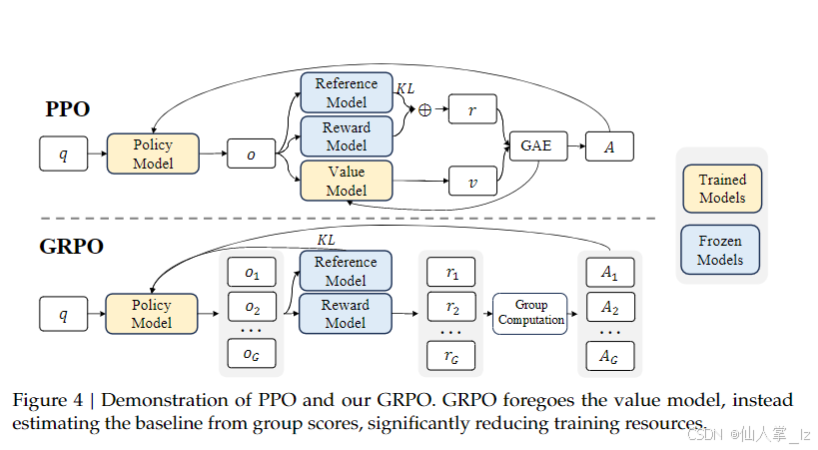
GRPO作为一种改进的强化学习算法,对提升语言模型的数学推理能力具有重要意义。它在继承传统算法优势的基础上,通过创新的设计有效解决了一些关键问题。
- 核心思想:GRPO算法的核心思想是优化近端策略优化(PPO)算法,以提升训练效率并降低资源消耗。PPO在训练过程中,因使用与策略模型规模相当的价值函数来计算优势,带来了较大的内存和计算负担,且在语言模型(LLM)场景下,价值函数训练难度较大。GRPO摒弃了PPO中单独训练价值函数的方式,通过对同一问题采样多个输出,计算这些输出奖励的平均值作为基线,避免了额外价值函数的训练,从而减少了资源消耗。这种基于组奖励的计算方式,能更有效地利用奖励信号,优化策略模型,增强模型的数学推理能力。
- 工作步骤
- 初始化模型和参数:设定初始策略模型 π θ i n i t \pi_{\theta_{init}} πθinit、奖励模型 r φ r_{\varphi} rφ,准备任务提示集 D D D,并确定超参数 ε \varepsilon ε、 β \beta β、 μ \mu μ 。
- 迭代训练:在每次迭代中,先将当前策略模型 π θ \pi_{\theta} πθ初始化为 π θ i n i t \pi_{\theta_{init}} πθinit,参考模型 π r e f \pi_{ref} πref设为 π θ \pi_{\theta} πθ。
- 数据采样:从任务提示集 D D D中采样一批数据 D b D_b Db,更新旧策略模型 π θ o l d \pi_{\theta_{old}} πθold为当前策略模型 π θ \pi_{\theta} πθ 。对于 D b D_b Db中的每个问题 q q q,从旧策略模型 π θ o l d \pi_{\theta_{old}} πθold中采样 G G G个输出 { o i } i = 1 G \{o_{i}\}_{i = 1}^{G} {oi}i=1G。
- 奖励计算与优势估计:用奖励模型 r φ r_{\varphi} rφ为每个采样输出 o i o_{i} oi计算奖励 r i r_{i} ri ,并对奖励进行归一化处理。根据不同监督方式计算优势,在结果监督中,将归一化奖励作为整个输出所有token的优势;在过程监督中,优势为后续步骤归一化奖励之和。
- 模型更新:通过最大化GRPO目标函数更新策略模型 π θ \pi_{\theta} πθ ,并利用回放机制持续训练奖励模型 r φ r_{\varphi} rφ。
- 奖励反馈机制
- 结果监督奖励:在结果监督中,奖励模型为每个输出给出一个最终奖励,对这些奖励进行归一化,将归一化后的奖励作为整个输出所有token的优势 A ^ i , t \hat{A}_{i, t} A^i,t,用于更新策略模型。这种方式简单直接,能从整体上评估输出的质量,但可能无法细致地指导模型在推理过程中的每一步。
- 过程监督奖励:过程监督下,奖励模型为输出的每个推理步骤打分,同样对这些步骤奖励进行归一化。每个token的优势 A ^ i , t \hat{A}_{i, t} A^i,t根据后续步骤的归一化奖励累加得到,这使得模型在推理过程中的每一步都能得到更细致的反馈,更有效地监督模型的推理过程,从而优化策略模型。
- 目标函数:GRPO的目标函数为
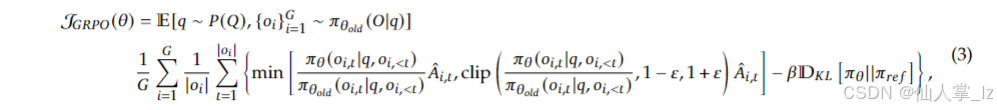
。其中,期望项表示对问题 q q q和采样输出 { o i } \{o_{i}\} {oi}的平均。目标函数由两部分组成,一部分是策略比率与优势的乘积,通过 m i n min min和 c l i p clip clip操作限制策略更新幅度,避免更新过大导致模型不稳定;另一部分是参考策略与当前策略的KL散度,用于正则化,平衡模型的探索与利用,促使策略模型朝着提升奖励的方向优化。 - 优势
- 降低资源消耗:GRPO通过用组平均奖励估计基线,避免了训练额外的价值函数,与PPO相比,显著减少了内存和计算负担,提高了训练效率。
- 提升模型性能:仅使用指令调整数据的子集进行训练,GRPO就能显著提升模型在数学任务上的表现。在GSM8K和MATH等任务中,DeepSeekMath-RL 7B模型采用GRPO训练后,准确率大幅提高,超越了许多开源模型,甚至在部分指标上超过了一些闭源模型,展示了其强大的性能提升能力。
- 有效利用奖励信号:GRPO根据奖励模型的输出,对不同质量的响应进行差异化强化和惩罚。其梯度系数能根据奖励值进行调整,相比其他方法(如Online RFT),能更有效地优化模型。例如,在实验中GRPO的表现优于Online RFT,且采用过程监督(GRPO+PS)时性能更优,体现了其对奖励信号的高效利用。
解读trl/trainer/grpo_trainer.py 文件
实现了 GRPOTrainer 类,用于执行 Group Relative Policy Optimization (GRPO) 算法来训练模型。
在 GRPOTrainer 中,具体实现步骤如下:
使用 RepeatRandomSampler 确保每个提示在多个进程中重复出现,方便计算和归一化奖励。
可以使用 vLLM 或常规生成方法生成完成结果。
使用多个奖励函数计算奖励,并对其进行加权求和和归一化。
计算模型与参考模型之间的 KL 散度,并结合奖励计算损失。
根据计算得到的损失更新模型参数。
=====================================================================================
以下是对该文件的详细解读:
1. 导入模块
代码开头导入了众多必要的模块,涵盖了文件操作、深度学习库(如 torch)、数据集处理库(如 datasets)、模型和分词器库(如 transformers)等,还根据特定库的可用性进行了条件导入,例如 peft、vllm 和 wandb。
2. 自定义采样器 RepeatRandomSampler
class RepeatRandomSampler(Sampler):
def __init__(self, data_source: Sized, repeat_count: int, seed: Optional[int] = None):
...
def __iter__(self):
...
def __len__(self):
...
- 该采样器的作用是将数据集的索引重复
repeat_count次,以保证每个提示能在多个进程中重复出现,从而确保相同的提示被分配到不同的 GPU 上,进而正确计算和归一化每个提示组内的奖励。
3. GRPOTrainer 类
3.1 类概述
class GRPOTrainer(Trainer):
_tag_names = ["trl", "grpo"]
GRPOTrainer类继承自transformers.Trainer,用于实现 GRPO 训练方法。此方法源自论文 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models。
3.2 __init__ 方法
def __init__(
self,
model: Union[str, PreTrainedModel],
reward_funcs: Union[RewardFunc, list[RewardFunc]],
args: GRPOConfig = None,
...
):
...
- 参数设置:若未提供
args,则会使用默认的GRPOConfig。 - 模型初始化:
- 若
model为字符串,会使用AutoModelForCausalLM.from_pretrained加载模型。 - 若提供了
peft_config,则使用peft库对模型进行包装。 - 同时会创建参考模型
self.ref_model,若使用了peft,则参考模型可能为None。
- 若
- 处理类和奖励函数:
- 若未提供
processing_class,会使用AutoTokenizer.from_pretrained加载分词器。 reward_funcs可以是单个奖励函数或奖励函数列表,若为字符串则会加载为序列分类模型。- 会根据
args.reward_weights设置奖励函数的权重。
- 若未提供
- 数据收集器:定义了一个简单的数据收集器,在 GRPO 中不需要数据整理。
- 训练参数设置:设置最大提示长度、最大完成长度、生成数量等参数。
- vLLM 支持:若
args.use_vllm为True,会使用vLLM进行生成,并对其进行初始化。 - 回调函数:若
args.sync_ref_model为True,会添加SyncRefModelCallback回调函数。
3.3 _set_signature_columns_if_needed 方法
def _set_signature_columns_if_needed(self):
if self._signature_columns is None:
self._signature_columns = ["prompt"]
- 该方法会将签名列设置为
["prompt"],因为在GRPOTrainer中,我们预处理数据,使用模型的签名列并不适用。
3.4 _get_train_sampler 和 _get_eval_sampler 方法
def _get_train_sampler(self) -> Sampler:
return RepeatRandomSampler(self.train_dataset, self.num_generations, seed=self.args.seed)
def _get_eval_sampler(self, eval_dataset) -> Sampler:
return RepeatRandomSampler(eval_dataset, self.num_generations, seed=self.args.seed)
- 这两个方法返回
RepeatRandomSampler实例,以确保每个提示在多个进程中重复出现。
3.5 _get_per_token_logps 方法
def _get_per_token_logps(self, model, input_ids, attention_mask, logits_to_keep):
...
return selective_log_softmax(logits, input_ids)
- 该方法用于获取模型对完成结果的每个 token 的对数概率。
3.6 _move_model_to_vllm 方法
def _move_model_to_vllm(self):
...
llm_model.load_weights(state_dict.items())
- 此方法将模型的权重加载到
vLLM中。
3.7 _prepare_inputs 方法
def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:
...
return {
"prompt_ids": prompt_ids,
"prompt_mask": prompt_mask,
...
}
- 该方法对输入进行预处理,包括生成完成结果、计算奖励、归一化奖励等操作,最终返回预处理后的输入字典。
3.8 compute_loss 方法
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
...
return loss
- 此方法计算模型的损失,包括计算每个 token 的对数概率、KL 散度和损失,同时记录相关指标。
3.9 prediction_step 方法
def prediction_step(self, model, inputs, prediction_loss_only, ignore_keys: Optional[list[str]] = None):
inputs = self._prepare_inputs(inputs)
with torch.no_grad():
with self.compute_loss_context_manager():
loss = self.compute_loss(model, inputs)
loss = loss.mean().detach()
return loss, None, None
- 该方法执行预测步骤,计算损失并返回。
3.10 log 方法
def log(self, logs: dict[str, float], start_time: Optional[float] = None) -> None:
metrics = {key: sum(val) / len(val) for key, val in self._metrics.items()}
...
super().log(logs)
self._metrics.clear()
- 该方法用于记录日志,将指标平均后与传入的日志合并,然后调用父类的
log方法进行记录,最后清空指标列表。
3.11 create_model_card 方法
def create_model_card(
self,
model_name: Optional[str] = None,
dataset_name: Optional[str] = None,
tags: Union[str, list[str], None] = None,
):
...
model_card.save(os.path.join(self.args.output_dir, "README.md"))
- 此方法用于创建模型卡片,包含模型信息、数据集信息、标签、引用等内容,并将其保存为
README.md文件。
解读 trl/trainer/grpo_config.py
grpo_config.py 这个文件主要定义了一个配置类 GRPOConfig,它继承自 transformers.TrainingArguments。以下是对其关键部分的详细解读:
类的定义与作用
@dataclass
class GRPOConfig(TrainingArguments):
r"""
Configuration class for the [`GRPOTrainer`].
...
"""
GRPOConfig类是为GRPOTrainer设计的配置类,用于管理与 GRPO 训练相关的各种参数。- 它继承自
TrainingArguments,这意味着它可以使用transformers库中训练参数的基本配置,并在此基础上扩展特定于 GRPO 训练的参数。
参数分组及含义
控制模型和参考模型的参数
model_init_kwargs: Optional[dict] = field(
default=None,
metadata={
"help": "Keyword arguments for `transformers.AutoModelForCausalLM.from_pretrained`, used when the `model` "
"argument of the `GRPOTrainer` is provided as a string."
},
)
model_init_kwargs是一个可选的字典,用于传递给transformers.AutoModelForCausalLM.from_pretrained方法,当GRPOTrainer的model参数为字符串时使用。
控制数据预处理的参数
remove_unused_columns: Optional[bool] = field(
default=False,
metadata={
"help": "Whether to only keep the column 'prompt' in the dataset. If you use a custom reward function "
"that requires any column other than 'prompts' and 'completions', you should keep this to `False`."
},
)
remove_unused_columns控制是否只保留数据集中的prompt列。如果使用的自定义奖励函数需要除prompts和completions之外的其他列,应将其设为False。
max_prompt_length: Optional[int] = field(
default=512,
metadata={
"help": "Maximum length of the prompt. If the prompt is longer than this value, it will be truncated left."
},
)
max_prompt_length设定了提示的最大长度,若提示长度超过该值,将从左侧截断。
num_generations: Optional[int] = field(
default=8,
metadata={
"help": "Number of generations to sample. The global batch size (num_processes * per_device_batch_size) "
"must be divisible by this value."
},
)
num_generations表示每个提示要采样的生成数量,全局批量大小(进程数 * 每个设备的批量大小)必须能被该值整除。
temperature: Optional[float] = field(
default=0.9,
metadata={"help": "Temperature for sampling. The higher the temperature, the more random the completions."},
)
temperature是采样时的温度参数,值越高,生成的完成结果越随机。
max_completion_length: Optional[int] = field(
default=256,
metadata={"help": "Maximum length of the generated completion."},
)
max_completion_length设定了生成完成结果的最大长度。
ds3_gather_for_generation: bool = field(
default=True,
metadata={
"help": "This setting applies to DeepSpeed ZeRO-3. If enabled, the policy model weights are gathered for "
"generation, improving generation speed. However, disabling this option allows training models that "
"exceed the VRAM capacity of a single GPU, albeit at the cost of slower generation. Disabling this option "
"is not compatible with vLLM generation."
},
)
ds3_gather_for_generation适用于 DeepSpeed ZeRO-3,启用时会收集策略模型权重以提高生成速度,但禁用该选项可以训练超出单个 GPU VRAM 容量的模型,不过生成速度会变慢,且禁用该选项与 vLLM 生成不兼容。
控制 vLLM 生成加速的参数
use_vllm: Optional[bool] = field(
default=False,
metadata={
"help": "Whether to use vLLM for generating completions. If set to `True`, ensure that a GPU is kept "
"unused for training, as vLLM will require one for generation. vLLM must be installed "
"(`pip install vllm`)."
},
)
use_vllm决定是否使用 vLLM 来生成完成结果,若设为True,需保留一个 GPU 供 vLLM 生成使用,且要安装 vLLM。
vllm_device: Optional[str] = field(
default="auto",
metadata={
"help": "Device where vLLM generation will run, e.g. 'cuda:1'. If set to 'auto' (default), the system "
"will automatically select the next available GPU after the last one used for training. This assumes "
"that training has not already occupied all available GPUs."
},
)
vllm_device指定 vLLM 生成运行的设备,默认为auto,系统会自动选择训练使用的最后一个 GPU 之后的下一个可用 GPU。
vllm_gpu_memory_utilization: float = field(
default=0.9,
metadata={
"help": "Ratio (between 0 and 1) of GPU memory to reserve for the model weights, activations, and KV "
"cache on the device dedicated to generation powered by vLLM. Higher values will increase the KV cache "
"size and thus improve the model's throughput. However, if the value is too high, it may cause "
"out-of-memory (OOM) errors during initialization."
},
)
vllm_gpu_memory_utilization是为 vLLM 生成预留的 GPU 内存比例,值越高,KV 缓存越大,模型吞吐量越高,但值过高可能导致初始化时内存溢出。
vllm_dtype: Optional[str] = field(
default="auto",
metadata={
"help": "Data type to use for vLLM generation. If set to 'auto', the data type will be automatically "
"determined based on the model configuration. Find the supported values in the vLLM documentation."
},
)
vllm_dtype是 vLLM 生成使用的数据类型,默认为auto,会根据模型配置自动确定。
vllm_max_model_len: Optional[int] = field(
default=None,
metadata={
"help": "If set, the `max_model_len` to use for vLLM. This could be useful when running with reduced "
"`vllm_gpu_memory_utilization`, leading to a reduced KV cache size. If not set, vLLM will use the model "
"context size, which might be much larger than the KV cache, leading to inefficiencies."
},
)
vllm_max_model_len是 vLLM 使用的最大模型长度,设置该值在降低vllm_gpu_memory_utilization时可能有用,不设置的话 vLLM 会使用模型上下文大小,可能导致效率低下。
控制训练的参数
learning_rate: float = field(
default=1e-6,
metadata={
"help": "Initial learning rate for `AdamW` optimizer. The default value replaces that of "
"`transformers.TrainingArguments`."
},
)
learning_rate是AdamW优化器的初始学习率,默认值替换了transformers.TrainingArguments中的值。
beta: float = field(
default=0.04,
metadata={"help": "KL coefficient."},
)
beta是 KL 系数。
reward_weights: Optional[list[float]] = field(
default=None,
metadata={
"help": "Weights for each reward function. Must match the number of reward functions. If `None`, all "
"rewards are weighted equally with weight `1.0`."
},
)
reward_weights是每个奖励函数的权重,必须与奖励函数的数量匹配,若为None,所有奖励的权重均为1.0。
sync_ref_model: bool = field(
default=False,
metadata={
"help": "Whether to synchronize the reference model with the active model every `ref_model_sync_steps` "
"steps, using the `ref_model_mixup_alpha` parameter."
},
)
sync_ref_model决定是否每隔ref_model_sync_steps步使用ref_model_mixup_alpha参数将参考模型与活动模型同步。
ref_model_mixup_alpha: float = field(
default=0.9,
metadata={
"help": "α parameter from the TR-DPO paper, which controls the mix between the current policy and the "
"previous reference policy during updates. The reference policy is updated according to the equation: "
"`π_ref = α * π_θ + (1 - α) * π_ref_prev`. To use this parameter, you must set `sync_ref_model=True`."
},
)
ref_model_mixup_alpha是 TR-DPO 论文中的 α 参数,用于控制更新时当前策略与先前参考策略的混合,使用该参数需将sync_ref_model设为True。
ref_model_sync_steps: int = field(
default=64,
metadata={
"help": "τ parameter from the TR-DPO paper, which determines how frequently the current policy is "
"synchronized with the reference policy. To use this parameter, you must set `sync_ref_model=True`."
},
)
ref_model_sync_steps是 TR-DPO 论文中的 τ 参数,决定当前策略与参考策略同步的频率,使用该参数需将sync_ref_model设为True。
控制日志记录的参数
log_completions: bool = field(
default=False,
metadata={"help": "Whether to log the completions during training."},
)
log_completions决定是否在训练期间记录完成结果。


















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











