







简介
- KTransformers 是一个灵活的、以 Python 为中心的框架,旨在通过先进的内核优化和放置 / 并行策略提升 Hugging Face Transformers 的使用体验。它具有高度的可扩展性,用户可通过单行代码注入优化模块,获得兼容 Transformers 的接口、符合 OpenAI 和 Ollama 的 RESTful API,甚至简化的 ChatGPT 风格的 Web UI。
KTransformers v0.2.4 发布说明
Balance Serve backend (multi-concurrency) for ktransformers
KTransformers v0.2.4 正式发布!在这个版本中,对整个架构进行重大重构,更新了超过 10,000 行代码,借鉴了 sglang 的优秀架构,实现了高性能的异步并发调度,使用 C++ 编写,已经支持 多并发 。
🚀 关键更新
- 多并发支持
- 增加了处理多个并发推理请求的能力。支持同时接收和执行多个任务。
- 基于高性能和高度灵活的操作符库 flashinfer 实现了 custom_flashinfer,并实现了可变批量大小的 CUDA 图,进一步增强了灵活性,同时减少了内存和填充开销。
- 在基准测试中,整体吞吐量在 4 路并发下提高了约 130%。
- 在英特尔的支持下,在最新的 Xeon6 + MRDIMM-8800 平台上测试了 KTransformers v0.2.4。通过增加并发性,总输出吞吐量从 17 tokens/s 增加到 40 tokens/s。我们观察到瓶颈现在已经转移到 GPU。使用比 4090D 更高端的 GPU 可以进一步提高性能。
- 引擎架构优化
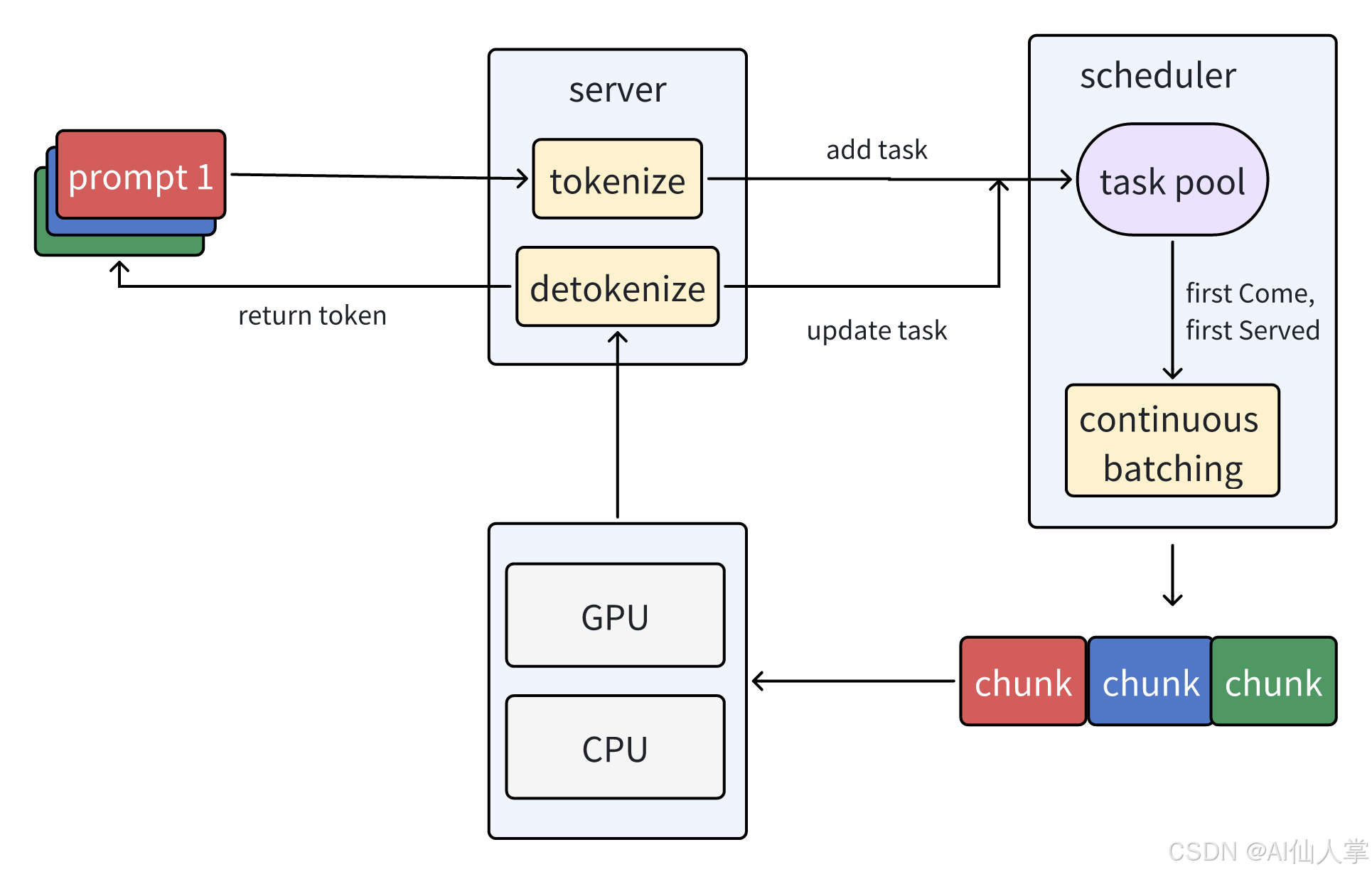
受 sglang 的调度框架启发,我们通过更新 11,000 行代码重构了 KTransformers,采用更清晰的三层架构,现在支持完整的多并发:- 服务器:处理用户请求并提供与 OpenAI 兼容的 API。
- 推理引擎:执行模型推理并支持分块预填充。
- 调度器:管理任务调度和请求编排。通过以 FCFS 方式组织排队请求为批次并将其发送到推理引擎,支持连续批处理。
- 项目结构重组 所有 C/C++ 代码现在集中在 /csrc 目录下。
- 参数调整 删除了一些遗留和弃用的启动参数,以提供更清晰的配置体验。我们计划在未来的版本中提供完整的参数列表和详细文档,以便于灵活配置和调试。
📚 升级说明
- 由于参数更改,建议已安装先前版本的用户删除 ~/.ktransformers 目录并重新初始化。
- 要启用多并发,请参考最新文档中的配置示例。
变更内容
实现了 custom_flashinfer 实现了基于 FlashInfer 的 balance_serve 引擎 i实现了 C++ 中的 连续批处理
实测问题
来自github的issue
0.23 上下文131072,NUMA=1,内存占用800GB,输出速度约10 token/s
0.24 上下文32768,cached_lens 131072,内存占用800GB,输出速度单请求约5 token/s,两路请求大约4+4 token/s(因为两个请求输出不会同时结束)
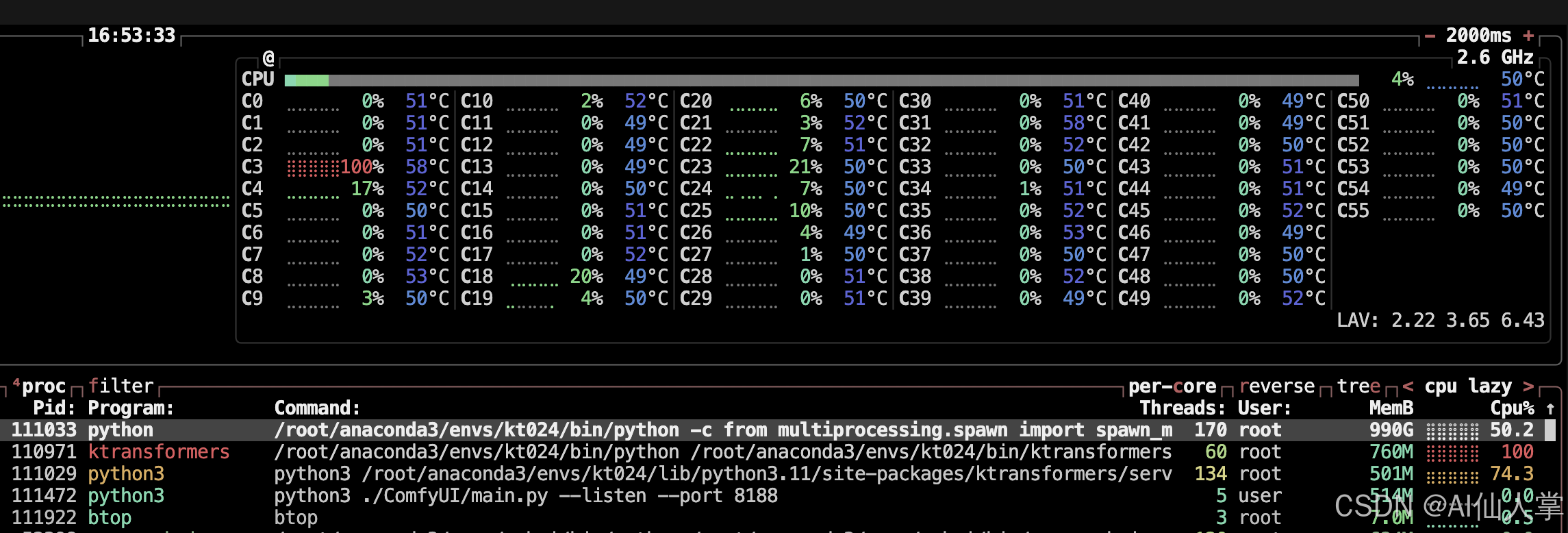
即使在没有任何请求的情况下,这几个进程保持了单个CPU核心的满载!!所以还是耐心等待他变好吧
下载用于测试 v0.2.4 的 Docker 镜像
访问 链接 拉取镜像,以 v0.2.4-AVX512 为例。
docker pull approachingai/ktransformers:v0.2.4-AVX512
docker run -it --gpus all --privileged --shm-size 64g --name ktrans --network=host -v /mnt:/mnt approachingai/ktransformers:v0.2.4-AVX512 /bin/bash
# 打开一个新终端
docker exec -it ktrans bash
安装指南
⚠️ 请注意,安装此项目将替换您环境中的 flashinfer。强烈建议创建一个新的 conda 环境!!!
⚠️ 请注意,安装此项目将替换您环境中的 flashinfer。强烈建议创建一个新的 conda 环境!!!
⚠️ 请注意,安装此项目将替换您环境中的 flashinfer。强烈建议创建一个新的 conda 环境!!!
2. 设置 Conda 环境
我们建议使用 Miniconda3/Anaconda3 进行环境管理:
# 下载 Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 创建环境
conda create --name ktransformers python=3.11
conda activate ktransformers
# 安装所需库
conda install -c conda-forge libstdcxx-ng
# 验证 GLIBCXX 版本(应包括 3.4.32)
strings ~/anaconda3/envs/ktransformers/lib/libstdc++.so.6 | grep GLIBCXX
注意: 如果您的安装目录与
~/anaconda3不同,请调整 Anaconda 路径
2. 安装依赖
sudo apt install libtbb-dev libssl-dev libcurl4-openssl-dev libaio1 libaio-dev libfmt-dev libgflags-dev zlib1g-dev patchelf
pip3 install packaging ninja cpufeature numpy openai
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
3. 构建 ktransformers
# 克隆仓库
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule update --init --recursive
# 安装单 NUMA 依赖
USE_BALANCE_SERVE=1 bash ./install.sh
# 对于有两个 CPU 和 1T RAM(双 NUMA)的人:
USE_BALANCE_SERVE=1 USE_NUMA=1 bash ./install.sh
运行 DeepSeek-R1-Q4KM 模型
1. 运行 24GB VRAM GPU
使用我们为受限 VRAM 优化的配置:
python ktransformers/server/main.py \
--port 10002 \
--model_path <path_to_safetensor_config> \
--gguf_path <path_to_gguf_files> \
--optimize_config_path ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat-serve.yaml \
--max_new_tokens 1024 \
--cache_lens 32768 \
--chunk_size 256 \
--max_batch_size 4 \
--backend_type balance_serve
它具有以下参数:
--max_new_tokens:每个请求生成的最大令牌数。--cache_lens:调度器分配的 kvcache 的总长度。所有请求共享一个 kvcache 空间。--chunk_size:引擎在单次运行中处理的最大令牌数。对应于 32768 个令牌,完成请求后占用的空间将被释放。--max_batch_size:引擎在单次运行中处理的最大请求数(预填充 + 解码)。 (仅balance_serve支持)--backend_type:balance_serve是在 v0.2.4 版本中引入的多并发后端引擎。原始的单并发引擎是ktransformers。
2. 访问服务器
curl -X POST http://localhost:10002/v1/chat/completions \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "hello"}
],
"model": "DeepSeek-R1",
"temperature": 0.3,
"top_p": 1.0,
"stream": true
}'
以下是老版本的信息
-
KTransformers的性能优化基本囊括了目前主流的优化手段,包括:
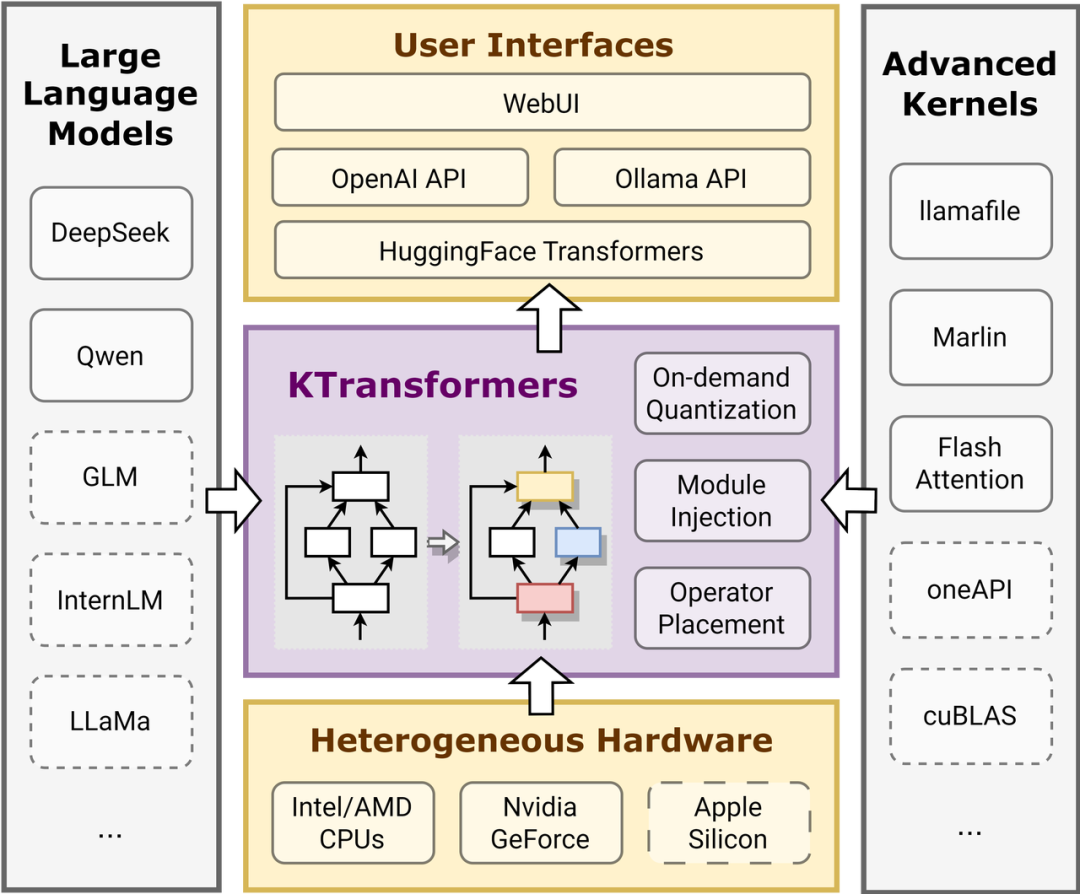
特点优势
- 内核优化:注入优化的内核,如 Llamafile 和 Marlin,提高计算效率。
- 量化技术:支持模型量化,减少模型大小和计算量。
- 并行策略:采用先进的并行策略,将计算任务分配到多个设备并行执行。
- 稀疏注意力:面对长文本输入,采用稀疏注意力机制,减少计算复杂度,提高推理速度。
- CPU/GPU 卸载:支持将计算任务在 CPU 和 GPU 之间灵活分配,充分利用不同硬件的优势。
- 动态负载均衡:可根据硬件负载情况动态调整任务分配,实现负载均衡,提高整体性能。
- 注入框架:提供灵活的注入框架,允许用户通过 YAML 配置文件定义优化规则,替换指定模块。
本地运行DeepSeek - R1性能示例
本地运行 6710 亿参数的 DeepSeek - Coder - V3/R1:使用仅 14GB VRAM 和 382GB DRAM 运行其 Q4_K_M 版本。
****说明一下:不支持并发,项目实现了单卡体验的可能性,但绝对上不了生产!太慢!用4个自行车轱辘加上2节干电池做了一个4轮电动车,但是,但是,但是,绝对不等于==智能电动汽车!!!!
速度对比
预填充(Prefill)速度 (tokens/s) :
-
KTransformers: 54.21 (32 核心) → 74.362 (双插槽,2×32 核心) → 255.26 (优化的 AMX 基 MoE 内核,仅 V0.3) → 286.55 (选择性使用 6 个专家,仅 V0.3)
-
与 llama.cpp 在 2×32 核心下 10.31 tokens/s 相比,速度提升高达 27.79 倍
解码(Decode)速度 (tokens/s):
-
KTransformers: 8.73 (32 核心) → 11.26 (双插槽, 2×32 核心) → 13.69 (选择性使用 6 个专家,仅 V0.3)
-
与 llama.cpp 在 2×32 核心下 4.51 tokens/s 相比,速度提升高达 3.03 倍
硬件配置
最佳性能测试(V0.2):
CPU:Intel ® Xeon ® Gold 6454S 1T 内存 (2 NUMA 节点)
GPU:4090D 24G 显存
内存:标准 DDR5 - 4800 服务器内存 (1 TB)
基准测试结果
V0.2
设置
- Model: DeepseekV3-q4km (int4)
- CPU: cpu_model_name: Intel ® Xeon ® Gold 6454S,每个插槽 32 核心,2 个插槽,2 个 NUMA 节点
- GPU: 4090D 24G 显存
- 我们在充分预热后进行测试
内存占用:
- 单插槽: 382G 内存,至少 14GB 显存
- 双插槽: 1T 内存,至少 14GB 显存
基准测试结果
“6 个专家” 情况是 V0.3 预览版中内容
| Prompt (500 tokens) | 双插槽 Ktrans (6 个专家) | 双插槽 Ktrans (8 个专家) | Single socket Ktrans (6 个专家) | Single socket Ktrans (8 个专家) | llama.cpp (8 个专家) |
|---|---|---|---|---|---|
| 预填充(Prefill) token/s | 97.32 | 82.94 | 65.14 | 54.21 | 10.31 |
| 解码(Decode) token/s | 13.69 | 12.208 | 10.303 | 8.73 | 4.51 |
最高加速比在解码方面达到 3.03x 倍,在预填充方面达到 9.44x 倍。
V0.3-Preview
设置
- Model: DeepseekV3-BF16 (在线量化为 CPU 的 int8 和 GPU 的 int4)
- CPU: cpu_model_name: Intel ® Xeon ® Gold 6454S,每个插槽 32 核心,2 个插槽,2 个 NUMA 节点
- GPU: (1~4)x 4090D 24G 显存 (更长的 prompt 需要更多显存)
内存占用:
- 644GB 内存,至少 14GB 显存
基准测试结果
| Prompt length | 1K | 2K | 4K | 8K |
|---|---|---|---|---|
| KTrans (8 个专家) Prefill token/s | 185.96 | 255.26 | 252.58 | 195.62 |
| KTrans (6 个专家) Prefill token/s | 203.70 | 286.55 | 271.08 | 207.20 |
KTrans V0.3 的预填充速度比 KTrans V0.2 快 3.45x 倍,比 llama.cpp 快 27.79x 倍。
解码速度与 KTrans V0.2(6 个专家版本)相同,因此省略。
主要加速来自于
- 英特尔 AMX 指令集和我们专门设计的缓存友好内存布局
- 专家选择策略,根据离线配置文件结果选择更少的专家
从我们对 DeepSeekV2、DeepSeekV3 和 DeepSeekR1 的研究中,当我们略微减少推理中的激活专家数量时,输出质量没有变化。但解码和预填充的速度加快了,这令人鼓舞。因此,我们的展示利用了这一发现。
如何运行
V0.2 展示
单插槽版本(32 核心)
我们的 local_chat 测试命令是:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
numactl -N 1 -m 1 python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 33 --max_new_tokens 1000
<当您看到聊天时,按回车键加载文本提示文件>
<your model path> 可以是本地路径,也可以是在线路径,例如 deepseek-ai/DeepSeek-V3。如果在线连接出现问题,可以尝试使用镜像(hf-mirror.com)
<your gguf path> 也可以是在线路径,但由于其体积较大,我们建议您下载并量化模型(注意这是目录路径)
--max_new_tokens 1000 是最大输出 token 长度。如果发现答案被截断,可以增加此数字以获得更长的答案(但要注意内存不足问题,增加此数字会降低生成速度).
命令 numactl -N 1 -m 1 的目的是避免 NUMA 节点之间的数据传输
注意!如果测试 R1 可能会跳过思考。因此,可以添加参数:--force_think true,这在 常见问题解答 部分中解释。
双插槽版本(64 核心)
在安装之前(使用 install.sh 或 make dev_install),请确保设置环境变量 USE_NUMA=1,方法是 export USE_NUMA=1(如果已经安装,请重新安装并设置此环境变量)
我们的 local_chat 测试命令是:
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
export USE_NUMA=1
make dev_install # or sh ./install.sh
python ./ktransformers/local_chat.py --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --max_new_tokens 1000
<当您看到聊天时,按回车键加载文本提示文件>
参数的含义相同。但因为我们使用双插槽,所以将 cpu_infer 设置为 65。
V0.3 展示
双插槽版本(64 核心)
我们的 local_chat 测试命令是:
wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
python -m ktransformers.local_chat --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --max_new_tokens 1000
<当您看到聊天时,按回车键加载文本提示文件>
参数的含义与 V0.2 相同。但因为我们使用双插槽,所以将 cpu_infer 设置为 65。
常见问题
-
命令参数
--cpu_infer 65指定使用多少核心(超过物理核心数量是可以的,但并不是越多越好。根据实际核心数量适当降低此值)。 -
为什么使用 CPU/GPU 混合推理?
DeepSeek 的 MLA 操作符计算密集。虽然全部在 CPU 上运行是可行的,但将繁重的计算任务卸载到 GPU 上能带来巨大的性能提升。 -
加速来自哪里?
- 专家卸载:与传统的基于层或 KVCache 卸载(如 llama.cpp 中的)不同,我们将专家计算卸载到 CPU,将 MLA/KVCache 卸载到 GPU,与 DeepSeek 的架构完美对齐,实现最佳效率。
- 英特尔 AMX 优化 – 我们的 AMX 加速内核经过精心调优,运行速度是现有 llama.cpp 实现的数倍。我们计划在清理后开源此内核,并考虑向 llama.cpp 上游贡献代码。
-
为什么选择英特尔 CPU?
英特尔目前是唯一支持 AMX 类似指令的 CPU 供应商,与仅支持 AVX 的替代方案相比,性能显著更好。 -
KTransformers 与 vLLM 有何不同?
vLLM 是一个用于大规模部署优化的出色框架。与之不同,KTransformers 特别专注于受资源限制的本地部署场景。
KTransformers 着重挖掘异构计算的潜力,比如在量化模型的 GPU/CPU 卸载方面进行优化。
举例来说,它分别支持用于 CPU 和 GPU 的高效 Llamafile 和 Marlin 内核,以此提升本地推理性能 -
model_path指向的是原始的模型路径,而gguf_path指向的是量化后的GGUF格式模型文件。 为什么要这么做?

KTransformers的优化策略,包括将部分参数卸载到CPU并使用GGUF格式的量化权重,而GPU部分则使用Marlin内核处理。因此,model_path可能用于加载模型的结构和部分参数,而gguf_path提供量化后的权重,用于CPU端的计算。所以,KTransformers部署时需要同时指定model_path和gguf_path:- model_path路径指向原始的PyTorch模型,用于加载模型结构和部分未量化的参数。例如,模型中的稠密计算模块(如MLA注意力层)会保留在GPU上,利用Marlin内核加速计算。
- gguf_path指向GGUF格式的量化权重文件,用于加载CPU端的稀疏计算模块(如MoE专家层、词嵌入层)。GGUF格式通过4bit/8bit量化大幅降低内存占用,并直接调用Llamafile内核在CPU上高效执行。
-
如果没有足够的VRAM,但我有多个GPU,该如何利用它们?多GPU会提升推理速度吗?
-
修改 YAML 注入模板
KTransformers 使用 YAML 注入模板来优化和配置模型。对于多 GPU 设置,你需要在 YAML 模板中指定设备分配。以下是一个示例,展示如何将模块分配到不同的 GPU 上:
- match:
name: "^model\\.layers\\.0$" # 匹配模型的第一层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:0" # 将此模块分配到GPU 0
kwargs:
generate_device: "cuda:0"
generate_linear_type: "QuantizedLinearMarlin"
- match:
name: "^model\\.layers\\.1$" # 匹配模型的第二层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:1" # 将此模块分配到GPU 1
kwargs:
generate_device: "cuda:1"
generate_linear_type: "QuantizedLinearMarlin"
在这个示例中,模型的不同层被分配到了不同的 GPU 上。你可以根据模型的结构和你的 GPU 数量,扩展这个模板以分配更多的模块。
-
确保使用
optimize_and_load_gguf函数,并传入正确的 YAML 配置文件optimize_and_load_gguf函数会根据 YAML 模板中的配置,将模型模块分配到相应的 GPU 上。 注意: ktransformers的多GPU策略为pipline,无法加速模型的推理,仅用于模型的权重分配。GPU/CPU混合推理deepseekR1使用了多GPU,但推理性能和单GPU一致,没有提升,多卡并不会加速推理。https://github.com/kvcache-ai/ktransformers/issues/345,用8卡4090跑的,速度还没有单卡的快
-
如何获得最佳性能?
必须设置–cpu_infer为要使用的核数。使用的核越多,模型运行速度越快,但并非越多越好。将其调整得略低一些,以适应实际核数。例如,–cpu_infer 65指定使用多少个核,超过物理数量是可以的,但也不是越多越好,稍微调低到实际的核心数量。 -
如果我获得的VRAM(也就是显存)比模型要求的多,我该如何充分利用它?
-
加大上下文,max_new_tokenslocal_chat.py可以以通过设置更大的值来增加上下文窗口的大小。
-
修改 YAML 注入模板,KTransformers 使用 YAML 注入模板来优化和配置模型。对于多 GPU 设置,你需要在 YAML 模板中指定设备分配。以下是一个示例,展示如何将模块分配到不同的 GPU 上:
- match:
name: "^model\\.layers\\.0$" # 匹配模型的第一层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:0" # 将此模块分配到GPU 01,
kwargs:
generate_device: "cuda:0"
generate_linear_type: "QuantizedLinearMarlin"
- match:
name: "^model\\.layers\\.1$" # 匹配模型的第二层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:1" # 将此模块分配到GPU 1
kwargs:
generate_device: "cuda:1"
generate_linear_type: "QuantizedLinearMarlin"
在这个示例中,模型的不同层被分配到了不同的 GPU 上。你可以根据模型的结构和你的 GPU 数量,扩展这个模板以分配更多的模块。
- 请问DeepseekR1-q4km在哪里下载,1.58位量化版本在哪里找?
- https://huggingface.co/unsloth/DeepSeek-R1-GGUF
- https://modelscope.cn/models/unsloth/DeepSeek-R1-GGUF
安装指南
1. 系统要求
- 操作系统:支持Linux和Windows系统。建议使用Linux系统以获得更好的性能和兼容性。
- 硬件:至少需要一块NVIDIA GPU以加速推理过程,若进行CPU推理,建议使用多核CPU。同时,确保系统有足够的内存来加载模型和处理数据。例如,运行某些模型可能需要24GB VRAM和相应的系统内存。
2. 安装步骤
2.1 安装Python
KTransformers依赖Python环境,推荐使用Python 3.8及以上版本。你可以从Python官方网站下载并安装Python。
2.2 安装依赖项
- 方法一:使用包管理器(推荐)
在项目根目录下,根据你的系统选择相应的脚本:- Linux系统:运行
install.sh脚本。该脚本会自动安装项目所需的依赖项,包括torch、transformers等。 - Windows系统:运行
install.bat脚本。它会执行类似的操作,安装Windows环境下所需的依赖包。
- Linux系统:运行
- 方法二:手动安装
如果你更倾向于手动安装依赖项,可以使用pip命令。首先创建并激活虚拟环境(可选但推荐):
# 创建虚拟环境(假设使用venv)
python -m venv myenv
# 激活虚拟环境
# 在Linux/Mac上
source myenv/bin/activate
# 在Windows上
myenv\Scripts\activate
然后安装依赖项:
pip install -r requirements.txt
requirements.txt文件包含了KTransformers运行所需的所有Python包及其版本要求。
2.3 安装KTransformers
安装完依赖项后,可以通过以下方式安装KTransformers:
- 从PyPI安装(稳定版本):
pip install ktransformers
- 从源代码安装(开发版本):
首先,克隆KTransformers仓库:
git clone https://github.com/kvcache-ai/ktransformers.git
然后进入项目目录并安装:
cd ktransformers
pip install -e.
-e选项表示以可编辑模式安装,这样在你修改源代码时,无需重新安装即可生效,方便开发和调试。
3. 验证安装
安装完成后,可以通过运行简单的示例脚本来验证KTransformers是否正确安装。在项目的示例目录中,有一些示例代码,例如example.py。运行该脚本:
python example.py
如果一切正常,脚本应该能够成功导入KTransformers并执行相应的操作,比如加载模型并进行推理。若遇到问题,请参考常见问题解答(FAQ)或在GitHub仓库中提交问题以获取帮助。
多GPU教程
1. 简介
KTransformers支持多GPU配置,这可以显著提升大型语言模型(LLM)的推理速度。本教程将指导你如何在KTransformers中设置和使用多GPU进行推理。
2. 系统要求
- 硬件:你需要一台配备多个NVIDIA GPU的机器。确保所有GPU都具有足够的显存来处理模型和输入数据。例如,对于某些大型模型,每个GPU可能需要至少12GB或更多的显存。
- 软件:
- 安装NVIDIA驱动程序,并且版本要与你的GPU型号和CUDA版本兼容。
- 安装CUDA Toolkit,KTransformers支持的CUDA版本在文档中有明确说明。请确保你的CUDA版本与安装的GPU驱动程序以及其他依赖项兼容。
- 按照安装指南完成KTransformers及其依赖项的安装。
3. 配置多GPU
3.1 检查GPU可用性
在使用多GPU之前,你可以通过运行以下Python代码片段来检查系统中可用的GPU:
import torch
if torch.cuda.is_available():
num_gpus = torch.cuda.device_count()
print(f"Detected {num_gpus} GPUs.")
else:
print("No GPUs detected. Please check your GPU installation.")
如果代码正确检测到多个GPU,你就可以继续进行下一步配置。
3.2 修改YAML注入模板
KTransformers使用YAML注入模板来优化和配置模型。对于多GPU设置,你需要在YAML模板中指定设备分配。以下是一个示例,展示如何将模块分配到不同的GPU上:
- match:
name: "^model\\.layers\\.0$" # 匹配模型的第一层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:0" # 将此模块分配到GPU 0
kwargs:
generate_device: "cuda:0"
generate_linear_type: "QuantizedLinearMarlin"
- match:
name: "^model\\.layers\\.1$" # 匹配模型的第二层
class: torch.nn.Linear
replace:
class: ktransformers.operators.linear.KTransformerLinear
device: "cuda:1" # 将此模块分配到GPU 1
kwargs:
generate_device: "cuda:1"
generate_linear_type: "QuantizedLinearMarlin"
在这个示例中,模型的不同层被分配到了不同的GPU上。你可以根据模型的结构和你的GPU数量,扩展这个模板以分配更多的模块。
3.3 使用多GPU进行模型加载
在代码中加载模型时,确保使用optimize_and_load_gguf函数,并传入正确的YAML配置文件。以下是一个示例:
import torch
from transformers import AutoModelForCausalLM
from ktransformers import optimize_and_load_gguf
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
optimize_and_load_gguf(model, optimize_rule_path="path/to/your/yaml/file.yaml", gguf_path="path/to/your/model.gguf", config=config)
optimize_and_load_gguf函数会根据YAML模板中的配置,将模型模块分配到相应的GPU上。
4. 运行推理
加载模型后,你可以像往常一样进行推理。KTransformers提供了prefill_and_generate函数,它针对多GPU设置进行了优化,可以进一步提高推理速度:
from ktransformers import prefill_and_generate
import torch
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("your_model_tokenizer")
input_text = "Your input prompt here"
input_tensor = tokenizer.encode(input_text, return_tensors="pt").cuda()
generated = prefill_and_generate(model, tokenizer, input_tensor, max_new_tokens=1000)
print(generated)
这个函数会在多个GPU上并行处理输入,生成输出文本。
5. 注意事项
- 显存管理:在多GPU设置中,要注意显存的使用情况。确保每个GPU都有足够的显存来处理分配给它的模块和数据。如果遇到显存不足的错误,你可能需要调整模型大小、减少输入长度或优化模块分配。
- 模型兼容性:并非所有模型都能完美地在多GPU上进行扩展。某些模型结构可能需要特定的并行策略。在使用新模型时,请查阅相关文档或进行测试,以确保多GPU设置能够正常工作。
- 性能优化:为了获得最佳性能,你可能需要调整YAML模板中的设备分配策略,以及尝试不同的优化内核和参数。同时,确保你的GPU驱动程序和CUDA版本是最新的,以利用最新的性能改进。



















 2162
2162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











