







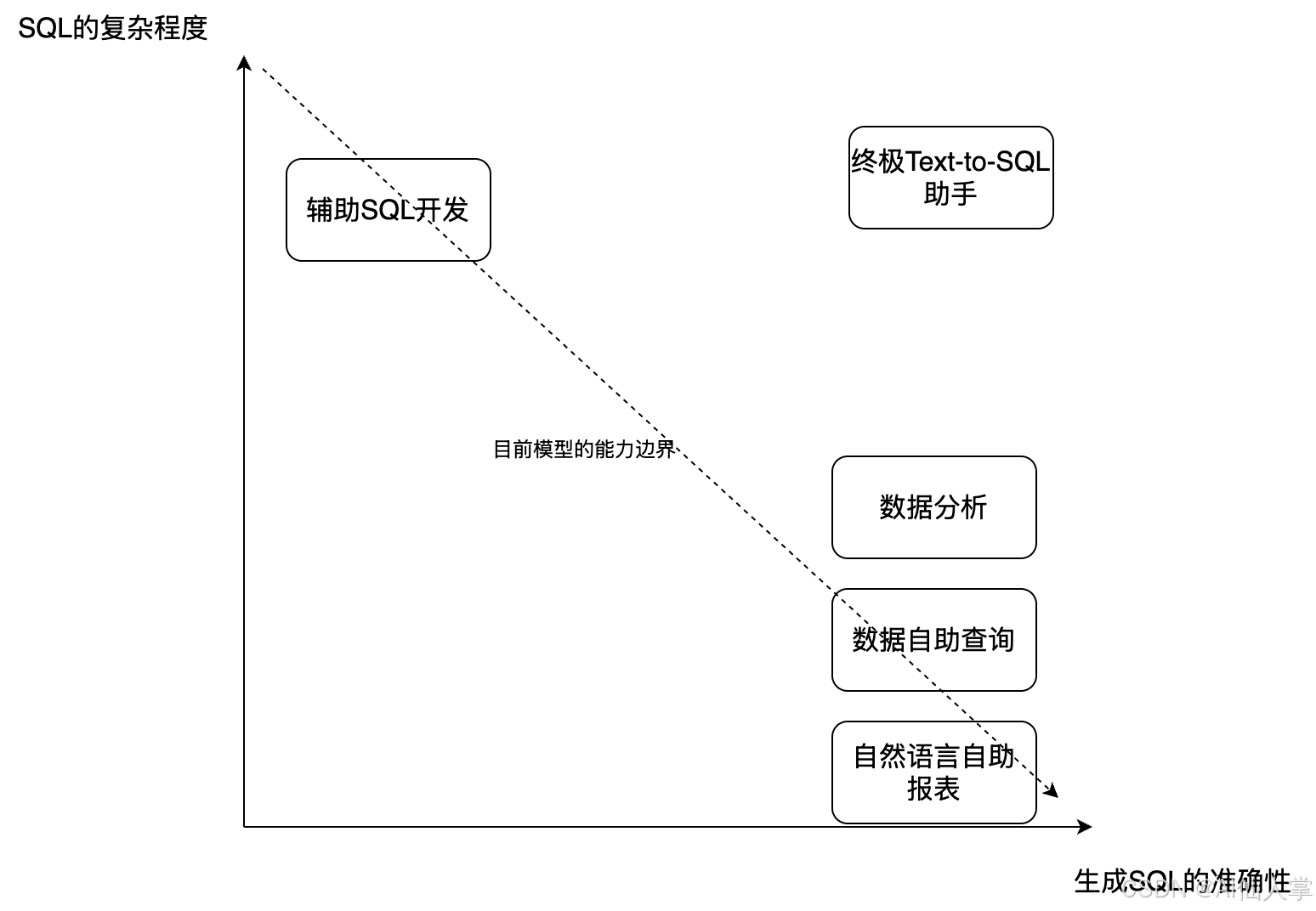
引言:Text-to-SQL的技术演进与当代价值
在当今数据驱动的商业环境中,结构化数据查询语言(SQL)仍然是访问和分析企业数据的核心工具。然而,SQL的专业性要求构成了数据民主化的主要障碍——据统计,仅约35%的开发人员接受过系统的SQL培训,而超过51%的专业岗位需要SQL技能。Text-to-SQL技术作为自然语言处理与数据库系统的关键桥梁,旨在消除这一障碍,使非技术用户能够通过自然语言直接与数据库交互。
回顾技术发展历程,Text-to-SQL已经历了四个主要阶段:早期的基于规则的方法(2010年前)依赖人工设计的语法模板和启发式规则,虽在简单场景有效但缺乏泛化能力;深度学习时代(2015-2018)引入Seq2Seq架构和Pointer Network等机制,开始学习语言到SQL的映射关系;预训练模型(PLM)阶段(2018-2021)利用BERT等模型的语义理解能力显著提升性能;而当前大语言模型(LLM)时代则凭借强大的上下文学习和推理能力,在复杂跨域场景中取得了突破性进展。
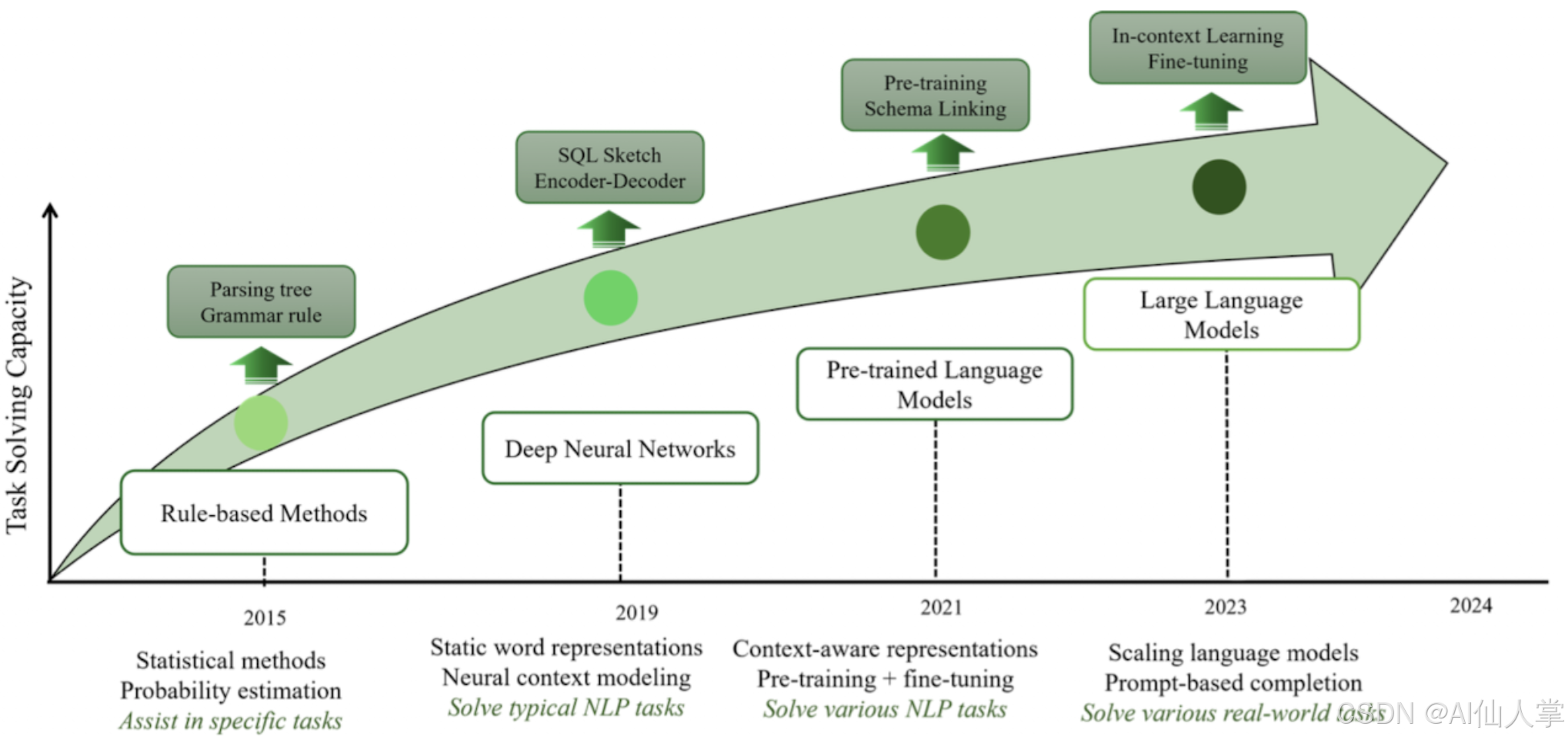
特别值得注意的是,以CHASE-SQL为代表的最新研究成果已在BIRD基准测试上达到了73%的执行准确率,较传统方法提升近20个百分点。这一进步主要归功于三大创新:多路径候选生成机制、偏好优化的选择代理以及系统级的工程优化。本文将深入解析这些技术突破,并探讨Text-to-SQL在实际应用中的挑战与解决方案。
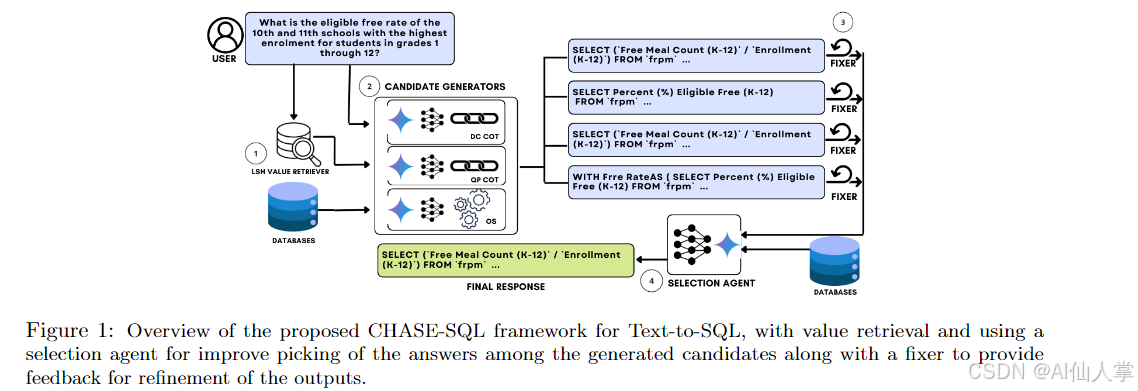
核心技术解析:现代Text-to-SQL架构剖析
多路径候选生成机制
传统Text-to-SQL系统常受限于单一生成路径,而CHASE-SQL创新性地提出了三种互补的生成策略,显著提高了输出的多样性与质量:
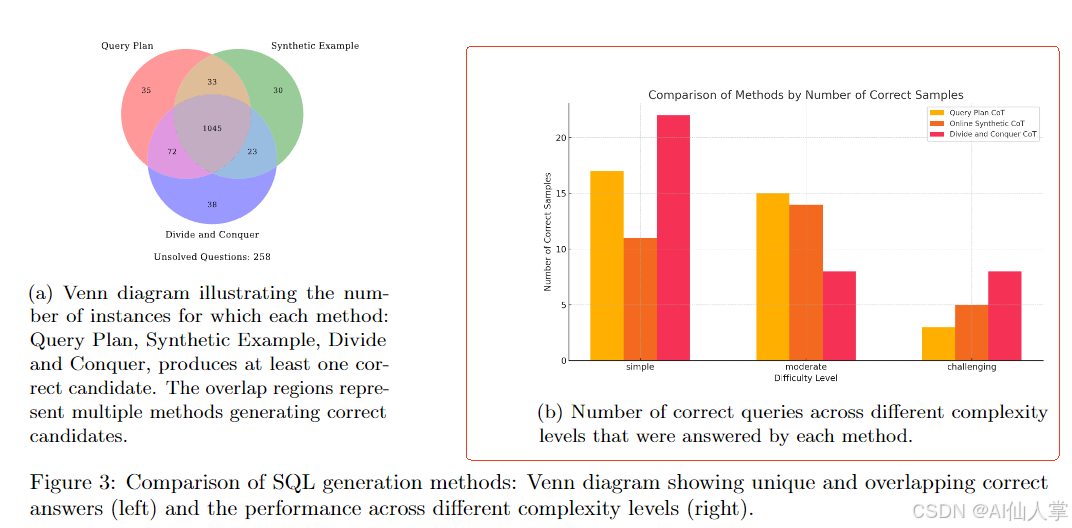
- 分治法CoT(Chain-of-Thought):受算法设计中"分而治之"思想启发,该方法将复杂查询分解为子问题。如图16所示案例,查询"最低平均薪资分支中最年轻客户性别"被拆解为:(1)找出最低平均薪资分支→(2)在该分支中找出最年轻客户→(3)返回客户性别。每个子问题生成伪SQL片段,最终组装优化为完整查询[citation:1附录]。这种策略特别适合处理嵌套WHERE条件、复杂HAVING子句等场景,在BIRD的"challenging"类问题上表现尤为突出。
算法1展示了分治法CoT的完整流程:
首先通过单次LLM调用分解原问题;然后为每个子问题生成部分SQL;最后组装并优化最终查询。关键在于保持子问题间的信息流——每个子查询生成时都能参考先前结果,确保逻辑一致性。
- 查询计划CoT:直接模拟数据库引擎的执行计划生成过程。该方法将SQLite的EXPLAIN输出转化为三阶段可读计划:(1)定位阶段识别相关表,(2)操作阶段描述条件过滤与连接逻辑,(3)交付阶段确定结果列。
Database Info
{DATABASE_SCHEMA}
**************************
Answer Repeating the question and evidence, and generating the SQL with a query plan.
**Question**: How many Thai restaurants can be found in San Pablo Ave, Albany?
**Evidence**: Thai restaurant refers to food_type = ’thai’; San Pablo Ave Albany refers to street_name
= ’san pablo ave’ AND T1.city = ’albany’
**Query Plan**:
** Preparation Steps:**
4. Initialize the process: Start preparing to execute the query.
5. Prepare storage: Set up storage space (registers) to hold temporary results, initializing them to NULL.
6. Open 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6664
6664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











