







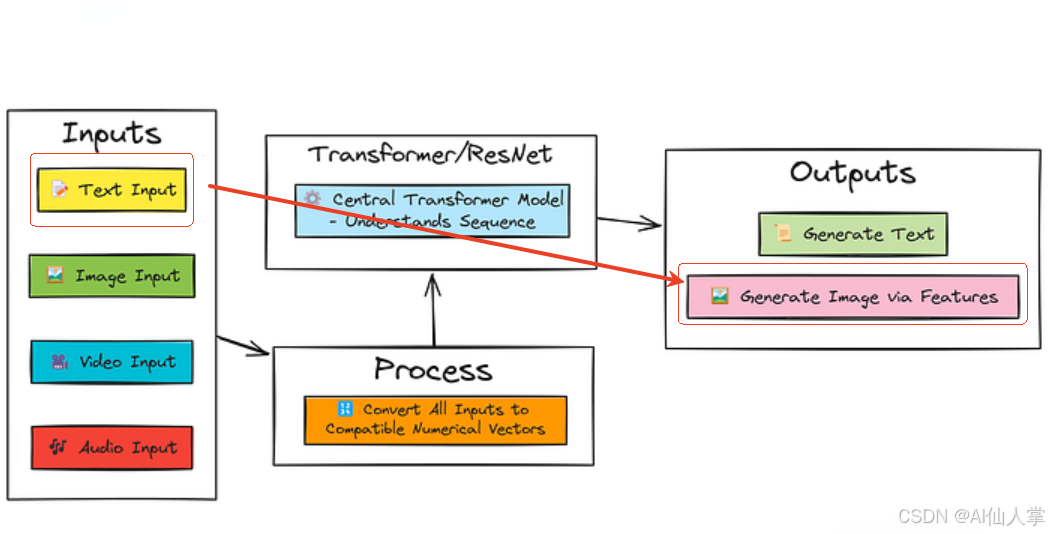
简介:通过特征向量从文本生成图像
回顾:多模态 Transformer
在使用Python从零实现一个端到端多模态 Transformer大模型中,我们调整了字符级 Transformer 以处理图像(通过 ResNet 特征)和文本提示,用于视觉描述等任务。我们将状态保存到 saved_models/multimodal_model.pt 中,包括文本处理组件、分词器和视觉特征投影层。
文本到图像的挑战(简化版)
直接从文本生成逼真图像是一项复杂的任务,通常涉及生成对抗网络(GANs)或扩散模型等专门架构。为了保持在 Transformer 框架内,我们将处理一个简化版本:
- 目标:给定文本提示(例如“一个蓝色方块”),生成表示描述图像的图像特征向量。
- 为什么使用特征向量? 使用基本 Transformer 自回归生成原始像素既困难又计算昂贵。生成固定大小的特征向量(如 ResNet 中的特征向量)是一个更易管理的中间步骤。
- 图像重建:生成特征向量后,我们将使用简单的最近邻方法在已知的训练图像上可视化结果。模型预测特征向量,我们找到训练图像(红色方块、蓝色方块、绿色圆圈)中特征向量最相似的图像并显示它。
我们的方法:用于特征预测的 Transformer
- 加载组件:我们从
multimodal_model.pt中加载文本 Transformer 组件(嵌入、位置编码、注意力/FFN 块、最终层归一化)和分词器。我们还加载冻结的 ResNet-18 特征提取器以在训练期间获取目标特征。 - 调整架构:输入现在仅为文本。我们将用一个新的线性层替换最终输出层(之前预测文本标记),该线性层将 Transformer 的最终隐藏状态映射到 ResNet 图像特征的维度(例如 512)。
- 训练数据:我们需要(文本提示,目标图像)对。我们将使用之前创建的简单图像的描述性提示。
- 训练过程:模型读取提示,通过 Transformer 块处理它,并使用新的输出层预测图像特征向量。损失(MSE)将此预测向量与目标图像的实际特征向量进行比较。
- 推理(生成):输入文本提示,从模型中获取预测的特征向量,找到最接近的已知图像特征,并显示相应的图像。
内联实现风格
我们继续以理论为基础的极其详细、逐步的内联实现,避免使用函数和类。
步骤 0:设置 - 库、加载、数据、特征提取
目标:准备环境,从之前的多模态模型中加载相关组件,定义文本-图像对数据,并提取目标图像特征。
步骤 0.1:导入库
理论:导入必要的库。我们需要 torch、torchvision、PIL、math、os、numpy。我们稍后还需要 scipy.spatial.distance 或 torch.nn.functional.cosine_similarity 来在生成过程中找到最接近的特征向量。
# 导入必要的库
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw
import math
import os
import numpy as np
# 用于后续寻找最近向量
from scipy.spatial import distance as scipy_distance
# 为了可重复性
torch.manual_seed(123)
np.random.seed(123)
print(f"PyTorch version: {torch.__version__}")
print(f"Torchvision version: {torchvision.__version__}")
print("Libraries imported.")
# --- 设备配置 ---
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
步骤 0.2:从多模态模型加载相关状态
理论:从 multimodal_model.pt 加载状态字典。我们需要配置参数、分词器、文本 Transformer 组件(嵌入层、注意力块等)以及 ResNet 特征提取器(保持冻结状态)。
# --- 加载保存的多模态模型状态 ---
print("\nStep 0.2: Loading state from multi-modal model...")
model_load_path = 'saved_models/multimodal_model.pt'
if not os.path.exists(model_load_path):
raise FileNotFoundError(f"Error: Model file not found at {model_load_path}. Please ensure 'multimodal.ipynb' was run and saved the model.")
loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")
# --- Extract Config and Tokenizer ---
config = loaded_state_dict['config']
vocab_size = config['vocab_size'] # Includes special tokens
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
# 使用加载配置中的block_size,后续可能根据文本提示长度需求调整
block_size = config['block_size']
vision_feature_dim = config['vision_feature_dim'] # ResNet特征维度(例如512)
d_k = d_model // n_heads
char_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
pad_token_id = char_to_int.get('<PAD>', -1) # Get PAD token ID
if pad_token_id == -1:
print("Warning: PAD token not found in loaded tokenizer!")
print("Extracted model configuration and tokenizer:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_layers: {n_layers}")
print(f" n_heads: {n_heads}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" vision_feature_dim: {vision_feature_dim}")
print(f" PAD token ID: {pad_token_id}")
# --- Load Positional Encoding ---
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
# 验证块大小一致性
if positional_encoding.shape[1] != block_size:
print(f"Warning: Loaded PE size ({positional_encoding.shape[1]}) doesn't match loaded block_size ({block_size}). Using loaded PE size.")
# block_size = positional_encoding.shape[1] # 选项1: 使用PE的大小
# 选项2: 如有必要重新计算PE(像之前一样),但先尝试切片/填充
print(f"Loaded positional encoding with shape: {positional_encoding.shape}")
# --- 加载文本Transformer组件(仅加载权重,后续创建结构) ---
loaded_embedding_dict = loaded_state_dict['token_embedding_table']
loaded_ln1_dicts = loaded_state_dict['layer_norms_1']
loaded_qkv_dicts = loaded_state_dict['mha_qkv_linears']
loaded_mha_out_dicts = loaded_state_dict['mha_output_linears']
loaded_ln2_dicts = loaded_state_dict['layer_norms_2']
loaded_ffn1_dicts = loaded_state_dict['ffn_linear_1']
loaded_ffn2_dicts = loaded_state_dict['ffn_linear_2']
loaded_final_ln_dict = loaded_state_dict['final_layer_norm']
print("Stored state dicts for text transformer components.")
# --- 加载视觉特征提取器(ResNet) ---
# 重新加载之前使用的ResNet-18模型并保持冻结状态
print("Loading pre-trained vision model (ResNet-18) for target feature extraction...")
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_model.fc = nn.Identity() # 移除分类器
vision_model = vision_model.to(device)
vision_model.eval() # 保持评估模式
# 冻结ResNet参数 - 非常重要
for param in vision_model.parameters():
param.requires_grad = False
print(f"Loaded and froze ResNet-18 feature extractor on device: {device}")
# --- Define Image Transformations (same as before) ---
image_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
print("Defined image transformations.")
步骤 0.3:定义示例文本-图像数据
理论:创建(描述性文本提示,目标图像路径)对。使用之前 notebook 生成的相同简单图像。
print("\nStep 0.3: Defining sample text-to-image data...")
# --- Image Paths (Assuming they exist from multimodal.ipynb) ---
sample_data_dir = "sample_multimodal_data"
image_paths = {
"red_square": os.path.join(sample_data_dir, "red_square.png"),
"blue_square": os.path.join(sample_data_dir, "blue_square.png"),
"green_circle": os.path.join(sample_data_dir, "green_circle.png")
}
# Verify paths exist
for key, path in image_paths.items():
if not os.path.exists(path):
print(f"Warning: Image file not found at {path}. Attempting to recreate.")
if key == "red_square":
img_ = Image.new('RGB', (64, 64), color = 'red')
img_.save(path)
elif key == "blue_square":
img_ = Image.new('RGB', (64, 64), color = 'blue')
img_.save(path)
elif key == "green_circle":
img_ = Image.new('RGB', (64, 64), color = 'white')
draw = ImageDraw.Draw(img_)
draw.ellipse((4, 4, 60, 60), fill='green', outline='green')
img_.save(path)
else:
print(f"Error: Cannot recreate unknown image key '{key}'.")
# --- Define Text Prompt -> Image Path Pairs ---
text_to_image_data = [
{"prompt": "a red square", "image_path": image_paths["red_square"]},
{"prompt": "the square is red", "image_path": image_paths["red_square"]},
{"prompt": "show a blue square", "image_path": image_paths["blue_square"]},
{"prompt": "blue shape, square", "image_path": image_paths["blue_square"]},
{"prompt": "a green circle", "image_path": image_paths["green_circle"]},
{"prompt": "the circle, it is green", "image_path": image_paths["green_circle"]},
# Add maybe one more variation
{"prompt": "make a square that is red", "image_path": image_paths["red_square"]}
]
num_samples = len(text_to_image_data)
print(f"Defined {num_samples} sample text-to-image data points.")
# print(f"Sample 0: {text_to_image_data[0]}")
步骤 0.4:提取目标图像特征
理论:使用冻结的 ResNet 预计算数据集中所有唯一图像的目标特征向量。存储这些特征向量,建立图像路径到特征张量的映射,并另存为(path, feature)列表供生成阶段最近邻查找使用。
print("\nStep 0.4: Extracting target image features...")
target_image_features = {} # Dict: {image_path: feature_tensor}
known_features_list = [] # List: [(path, feature_tensor)] for generation lookup
# --- Loop Through Unique Image Paths in this dataset ---
unique_image_paths_in_data = sorted(list(set(d["image_path"] for d in text_to_image_data)))
print(f"Found {len(unique_image_paths_in_data)} unique target images to process.")
for img_path in unique_image_paths_in_data:
# Avoid re-extracting if already done (e.g., if loading from multimodal)
# if img_path in extracted_image_features: # Check previous notebook's dict
# feature_vector_squeezed = extracted_image_features[img_path]
# print(f" Using pre-extracted features for '{os.path.basename(img_path)}'")
# else:
# --- Load Image ---
try:
img = Image.open(img_path).convert('RGB')
except FileNotFoundError:
print(f"Error: Image file not found at {img_path}. Skipping.")
continue
# --- Apply Transformations ---
img_tensor = image_transforms(img).unsqueeze(0).to(device) # (1, 3, 224, 224)
# --- Extract Features (using frozen vision_model) ---
with torch.no_grad():
feature_vector = vision_model(img_tensor) # (1, vision_feature_dim)
feature_vector_squeezed = feature_vector.squeeze(0) # (vision_feature_dim,)
print(f" Extracted features for '{os.path.basename(img_path)}', shape: {feature_vector_squeezed.shape}")
# --- Store Features ---
target_image_features[img_path] = feature_vector_squeezed
known_features_list.append((img_path, feature_vector_squeezed))
if not target_image_features:
raise ValueError("No target image features were extracted. Cannot proceed.")
print("Finished extracting and storing target image features.")
print(f"Stored {len(known_features_list)} known (path, feature) pairs for generation lookup.")
步骤 0.5:定义训练超参数
理论:为此特定任务调整超参数。可能需要不同的学习率或训练轮数。此处的 block_size 主要与预期的最大提示长度相关。
print("\nStep 0.5: Defining training hyperparameters for text-to-image...")
# Use block_size from loaded config, ensure it's adequate for prompts
max_prompt_len = max(len(d["prompt"]) for d in text_to_image_data)
if block_size < max_prompt_len + 1: # +1 for potential special tokens like <EOS> if used in prompt
print(f"Warning: Loaded block_size ({block_size}) might be small for max prompt length ({max_prompt_len}). Consider increasing block_size if issues arise.")
# Adjust block_size if needed, and recompute PE / causal mask
# block_size = max_prompt_len + 5 # Example adjustment
# print(f"Adjusted block_size to {block_size}")
# Need to recompute PE and causal_mask if block_size changes
# Recreate causal mask just in case block_size was adjusted, or use loaded size
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
print(f"Using block_size: {block_size}")
learning_rate = 1e-4 # Potentially lower LR for fine-tuning
batch_size = 4 # Keep small due to limited data
epochs = 5000 # Number of training iterations
eval_interval = 500
print(f" Training Params: LR={learning_rate}, BatchSize={batch_size}, Epochs={epochs}")
步骤 1:模型适配与初始化
目标:使用加载的权重重建文本 Transformer 组件,并初始化新的输出投影层。
步骤 1.1:初始化文本 Transformer 组件
理论:创建嵌入层、LayerNorms 和 Transformer 块的线性层实例,然后从步骤 0.2 存储的字典中加载预训练权重。
print("\nStep 1.1: Initializing Text Transformer components and loading weights...")
# --- Token Embedding Table ---
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_embedding_dict)
print(f" Loaded Token Embedding Table, shape: {token_embedding_table.weight.shape}")
# --- Transformer Blocks Components ---
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []
for i in range(n_layers):
# LayerNorm 1
ln1 = nn.LayerNorm(d_model).to(device)
ln1.load_state_dict(loaded_ln1_dicts[i])
layer_norms_1.append(ln1)
# MHA QKV Linear (Check bias presence)
qkv_dict = loaded_qkv_dicts[i]
has_bias = 'bias' in qkv_dict
qkv_linear = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)
qkv_linear.load_state_dict(qkv_dict)
mha_qkv_linears.append(qkv_linear)
# MHA Output Linear (Check bias presence)
mha_out_dict = loaded_mha_out_dicts[i]
has_bias = 'bias' in mha_out_dict
output_linear_mha = nn.Linear(d_model, d_model, bias=has_bias).to(device)
output_linear_mha.load_state_dict(mha_out_dict)
mha_output_linears.append(output_linear_mha)
# LayerNorm 2
ln2 = nn.LayerNorm(d_model).to(device)
ln2.load_state_dict(loaded_ln2_dicts[i])
layer_norms_2.append(ln2)
# FFN Linear 1 (Check bias presence)
ffn1_dict = loaded_ffn1_dicts[i]
has_bias = 'bias' in ffn1_dict
lin1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)
lin1.load_state_dict(ffn1_dict)
ffn_linear_1.append(lin1)
# FFN Linear 2 (Check bias presence)
ffn2_dict = loaded_ffn2_dicts[i]
has_bias = 'bias' in ffn2_dict
lin2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)
lin2.load_state_dict(ffn2_dict)
ffn_linear_2.append(lin2)
print(f" Loaded components for {n_layers} Transformer Layers.")
# --- Final LayerNorm ---
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_final_ln_dict)
print(" Loaded Final LayerNorm.")
print("Finished initializing and loading weights for text transformer components.")
步骤 1.2:初始化新的输出投影层
理论:创建一个新的线性层,将 Transformer 的最终隐藏状态(d_model)映射到图像特征向量的维度(vision_feature_dim)。该层的权重将随机初始化并进行训练。
print("\nStep 1.2: Initializing new output projection layer (Text -> Image Feature)...")
text_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim).to(device)
print(f" Initialized Text-to-Image-Feature Output Layer: {d_model} -> {vision_feature_dim}. Device: {device}")
步骤 2:文本到图像训练的数据准备
目标:对文本提示进行分词和填充,并将其与对应的目标图像特征向量配对。
步骤 2.1:分词和填充提示
理论:使用 char_to_int 将文本提示转换为 token ID 序列。使用 pad_token_id 将每个序列填充到 block_size 长度。同时创建对应的注意力掩码(1 表示真实 token,0 表示填充部分)。
print("\nStep 2.1: Tokenizing and padding text prompts...")
prepared_prompts = []
target_features_ordered = [] # Store target features in the same order
for sample in text_to_image_data:
prompt = sample["prompt"]
image_path = sample["image_path"]
# --- Tokenize Prompt ---
prompt_ids_no_pad = [char_to_int[ch] for ch in prompt]
# --- Padding ---
current_len = len(prompt_ids_no_pad)
pad_len = block_size - current_len
if pad_len < 0:
print(f"Warning: Prompt length ({current_len}) exceeds block_size ({block_size}). Truncating prompt.")
prompt_ids = prompt_ids_no_pad[:block_size]
pad_len = 0
current_len = block_size
else:
prompt_ids = prompt_ids_no_pad + ([pad_token_id] * pad_len)
# --- Create Attention Mask ---
attention_mask = ([1] * current_len) + ([0] * pad_len)
# --- Store Prompt Data ---
prepared_prompts.append({
"input_ids": torch.tensor(prompt_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long)
})
# --- Store Corresponding Target Feature ---
if image_path in target_image_features:
target_features_ordered.append(target_image_features[image_path])
else:
print(f"Error: Target feature not found for {image_path}. Data mismatch?")
# Handle error - maybe skip this sample or raise exception
target_features_ordered.append(torch.zeros(vision_feature_dim, device=device)) # Placeholder
# --- Stack into Tensors ---
all_prompt_input_ids = torch.stack([p['input_ids'] for p in prepared_prompts])
all_prompt_attention_masks = torch.stack([p['attention_mask'] for p in prepared_prompts])
all_target_features = torch.stack(target_features_ordered)
num_sequences_available = all_prompt_input_ids.shape[0]
print(f"Created {num_sequences_available} padded prompt sequences and gathered target features.")
print(f" Prompt Input IDs shape: {all_prompt_input_ids.shape}") # (num_samples, block_size)
print(f" Prompt Attention Mask shape: {all_prompt_attention_masks.shape}") # (num_samples, block_size)
print(f" Target Features shape: {all_target_features.shape}") # (num_samples, vision_feature_dim)
步骤 2.2:批处理策略(随机采样)
理论:设置训练期间的随机批次采样。我们将选择随机索引并获取相应的提示 ID、掩码和目标图像特征。
print("\nStep 2.2: Preparing for batching text-to-image data...")
# Check batch size feasibility
if num_sequences_available < batch_size:
print(f"Warning: Number of sequences ({num_sequences_available}) is less than batch size ({batch_size}). Adjusting batch size.")
batch_size = num_sequences_available
print(f"Data ready for training. Will sample batches of size {batch_size} randomly.")
# In the training loop, we will use random indices to get:
# xb_prompt_ids = all_prompt_input_ids[indices]
# batch_prompt_masks = all_prompt_attention_masks[indices]
# yb_target_features = all_target_features[indices]
步骤 3:文本到图像训练循环(内联)
目标:训练模型将文本提示映射到图像特征向量。
步骤 3.1:定义优化器和损失函数
理论:收集可训练参数(Transformer 组件+新的输出层)。定义优化器(AdamW)。定义损失函数 - 均方误差(MSE)适用于比较预测和目标特征向量。
print("\nStep 3.1: Defining Optimizer and Loss Function for text-to-image...")
# --- Gather Trainable Parameters ---
# Includes Transformer components and the new output layer
all_trainable_parameters_t2i = list(token_embedding_table.parameters())
for i in range(n_layers):
all_trainable_parameters_t2i.extend(list(layer_norms_1[i].parameters()))
all_trainable_parameters_t2i.extend(list(mha_qkv_linears[i].parameters()))
all_trainable_parameters_t2i.extend(list(mha_output_linears[i].parameters()))
all_trainable_parameters_t2i.extend(list(layer_norms_2[i].parameters()))
all_trainable_parameters_t2i.extend(list(ffn_linear_1[i].parameters()))
all_trainable_parameters_t2i.extend(list(ffn_linear_2[i].parameters()))
all_trainable_parameters_t2i.extend(list(final_layer_norm.parameters()))
all_trainable_parameters_t2i.extend(list(text_to_image_feature_layer.parameters())) # Add the new layer
# --- Define Optimizer ---
optimizer = optim.AdamW(all_trainable_parameters_t2i, lr=learning_rate)
print(f" Optimizer defined: AdamW with lr={learning_rate}")
print(f" Managing {len(all_trainable_parameters_t2i)} parameter groups/tensors.")
# --- Define Loss Function ---
# Theory: MSE loss compares the predicted feature vector to the target feature vector.
criterion = nn.MSELoss()
print(f" Loss function defined: {type(criterion).__name__}")
步骤 3.2:训练循环
理论:迭代 epochs 次。每一步:
- 选择批次(提示 ID、掩码、目标特征)。
- 执行前向传播:嵌入提示,添加位置编码,通过 Transformer 块传递,应用最终层归一化,使用
text_to_image_feature_layer投影到图像特征维度。 - 计算预测和目标特征向量之间的 MSE 损失。
- 反向传播并更新权重。
print("\nStep 3.2: 开始文本到图像训练循环...")
t2i_losses = []
# --- Set Trainable Layers to Training Mode ---
token_embedding_table.train()
for i in range(n_layers):
layer_norms_1[i].train()
mha_qkv_linears[i].train()
mha_output_linears[i].train()
layer_norms_2[i].train()
ffn_linear_1[i].train()
ffn_linear_2[i].train()
final_layer_norm.train()
text_to_image_feature_layer.train() # New layer also needs training mode
# vision_model remains in eval() mode
# --- Training Loop ---
for epoch in range(epochs):
# --- 1. 批次选择 ---
indices = torch.randint(0, num_sequences_available, (batch_size,))
xb_prompt_ids = all_prompt_input_ids[indices].to(device) # (B, T)
batch_prompt_masks = all_prompt_attention_masks[indices].to(device) # (B, T)
yb_target_features = all_target_features[indices].to(device) # (B, vision_feature_dim)
# --- 2. 前向传播 ---
B, T = xb_prompt_ids.shape
C = d_model
# --- 嵌入 + 位置编码 ---
token_embed = token_embedding_table(xb_prompt_ids) # (B, T, C)
pos_enc_slice = positional_encoding[:, :T, :] # (1, T, C)
x = token_embed + pos_enc_slice # (B, T, C)
# --- Transformer块 ---
# 创建注意力掩码(因果掩码+提示的填充掩码)
padding_mask_expanded = batch_prompt_masks.unsqueeze(1).unsqueeze(2) # (B, 1, 1, T)
combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expanded # (B, 1, T, T)
for i in range(n_layers):
x_input_block = x
# Pre-LN MHA
x_ln1 = layer_norms_1[i](x_input_block)
qkv = mha_qkv_linears[i](x_ln1)
qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=-1)
attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)
attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))
attention_weights = F.softmax(attn_scores_masked, dim=-1)
attention_weights = torch.nan_to_num(attention_weights)
attn_output = attention_weights @ v
attn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C)
mha_result = mha_output_linears[i](attn_output)
x = x_input_block + mha_result # Residual 1
# Pre-LN FFN
x_input_ffn = x
x_ln2 = layer_norms_2[i](x_input_ffn)
ffn_hidden = ffn_linear_1[i](x_ln2)
ffn_activated = F.relu(ffn_hidden)
ffn_output = ffn_linear_2[i](ffn_activated)
x = x_input_ffn + ffn_output # Residual 2
# --- Final LayerNorm ---
final_norm_output = final_layer_norm(x) # (B, T, C)
# --- 选择用于预测的隐藏状态 ---
# 理论:我们需要每个序列一个向量来预测图像特征向量。
# 我们可以取*最后一个非填充*标记的隐藏状态。
# 找到批次中每个序列的最后一个非填充标记的索引。
# batch_prompt_masks的形状为(B, T),值为1表示非填充,0表示填充。
# `torch.sum(mask, 1) - 1`给出了最后一个'1'的索引。
last_token_indices = torch.sum(batch_prompt_masks, 1) - 1 # Shape: (B,)
# 确保索引在边界内(处理全部是填充的情况,虽然不太可能)
last_token_indices = torch.clamp(last_token_indices, min=0)
# 收集对应于这些最后标记的隐藏状态。
# 我们需要索引final_norm_output[batch_index, token_index, :]
batch_indices = torch.arange(B, device=device)
last_token_hidden_states = final_norm_output[batch_indices, last_token_indices, :] # (B, C)
# --- 投影到图像特征维度 ---
# 理论:使用新的输出层预测图像特征向量。
predicted_image_features = text_to_image_feature_layer(last_token_hidden_states) # (B, vision_feature_dim)
# --- 3. 计算损失 ---
# 理论:计算预测特征和目标特征之间的MSE。
loss = criterion(predicted_image_features, yb_target_features)
# --- 4. Zero Gradients ---
optimizer.zero_grad()
# --- 5. Backward Pass ---
if not torch.isnan(loss) and not torch.isinf(loss):
loss.backward()
# Optional: Gradient Clipping
# torch.nn.utils.clip_grad_norm_(all_trainable_parameters_t2i, max_norm=1.0)
# --- 6. Update Parameters ---
optimizer.step()
else:
print(f"Warning: Invalid loss detected (NaN or Inf) at epoch {epoch+1}. Skipping optimizer step.")
loss = None
# --- Logging ---
if loss is not None:
current_loss = loss.item()
t2i_losses.append(current_loss)
if epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" Epoch {epoch+1}/{epochs}, MSE Loss: {current_loss:.6f}")
elif epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" Epoch {epoch+1}/{epochs}, Loss: Invalid (NaN/Inf)")
print("--- Text-to-Image Training Loop Completed ---\n")
# Optional: Plot losses
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(t2i_losses)
plt.title("Text-to-Image Training Loss (MSE)")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.grid(True)
plt.show()
步骤 4:文本到图像生成(内联实现)
目标:使用训练好的模型从文本提示生成图像特征向量,并找到最接近的已知图像。
步骤 4.1:准备输入提示
理论:定义新的文本提示,进行分词处理,并填充到 block_size 长度。
print("\nStep 4.1: Preparing input prompt for generation...")
# --- Input Prompt ---
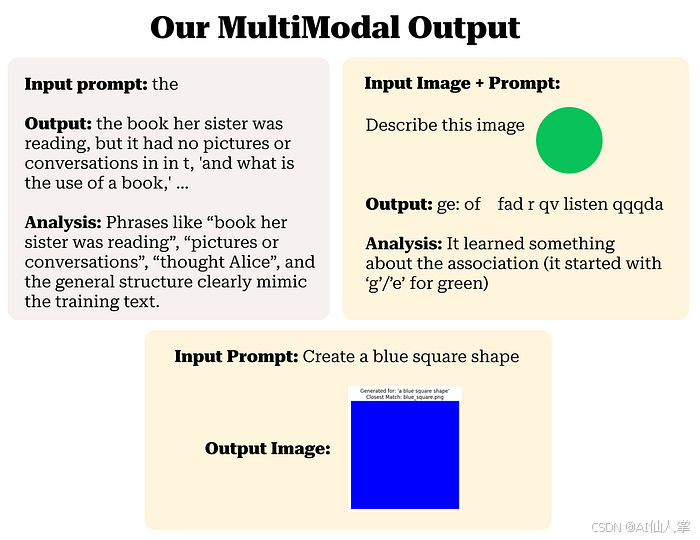
generation_prompt_text = "a blue square shape"
print(f"Input Prompt: '{generation_prompt_text}'")
# --- Tokenize and Pad ---
gen_prompt_ids_no_pad = [char_to_int.get(ch, pad_token_id) for ch in generation_prompt_text] # Use get with default for safety
gen_current_len = len(gen_prompt_ids_no_pad)
gen_pad_len = block_size - gen_current_len
if gen_pad_len < 0:
print(f"Warning: Generation prompt length ({gen_current_len}) exceeds block_size ({block_size}). Truncating.")
gen_prompt_ids = gen_prompt_ids_no_pad[:block_size]
gen_pad_len = 0
gen_current_len = block_size
else:
gen_prompt_ids = gen_prompt_ids_no_pad + ([pad_token_id] * gen_pad_len)
# --- Create Attention Mask ---
gen_attention_mask = ([1] * gen_current_len) + ([0] * gen_pad_len)
# --- Convert to Tensor ---
xb_gen_prompt_ids = torch.tensor([gen_prompt_ids], dtype=torch.long, device=device) # Add batch dim B=1
batch_gen_prompt_masks = torch.tensor([gen_attention_mask], dtype=torch.long, device=device) # Add batch dim B=1
print(f"Prepared prompt tensor shape: {xb_gen_prompt_ids.shape}")
print(f"Prepared mask tensor shape: {batch_gen_prompt_masks.shape}")
步骤 4.2:生成图像特征向量
理论:使用训练好的模型(在评估模式下)对输入提示进行前向传播,获取预测的图像特征向量。
print("\nStep 4.2: Generating image feature vector...")
# --- Set Model to Evaluation Mode ---
token_embedding_table.eval()
for i in range(n_layers):
layer_norms_1[i].eval()
mha_qkv_linears[i].eval()
mha_output_linears[i].eval()
layer_norms_2[i].eval()
ffn_linear_1[i].eval()
ffn_linear_2[i].eval()
final_layer_norm.eval()
text_to_image_feature_layer.eval()
# --- Forward Pass ---
with torch.no_grad():
B_gen, T_gen = xb_gen_prompt_ids.shape
C_gen = d_model
# Embeddings + PE
token_embed_gen = token_embedding_table(xb_gen_prompt_ids)
pos_enc_slice_gen = positional_encoding[:, :T_gen, :]
x_gen = token_embed_gen + pos_enc_slice_gen
# Transformer Blocks
padding_mask_expanded_gen = batch_gen_prompt_masks.unsqueeze(1).unsqueeze(2)
combined_attn_mask_gen = causal_mask[:,:,:T_gen,:T_gen] * padding_mask_expanded_gen
for i in range(n_layers):
x_input_block_gen = x_gen
# Pre-LN MHA
x_ln1_gen = layer_norms_1[i](x_input_block_gen)
qkv_gen = mha_qkv_linears[i](x_ln1_gen)
qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)
q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)
attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)
attn_scores_masked_gen = attn_scores_gen.masked_fill(combined_attn_mask_gen == 0, float('-inf'))
attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)
attention_weights_gen = torch.nan_to_num(attention_weights_gen)
attn_output_gen = attention_weights_gen @ v_gen
attn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)
mha_result_gen = mha_output_linears[i](attn_output_gen)
x_gen = x_input_block_gen + mha_result_gen # Residual 1
# Pre-LN FFN
x_input_ffn_gen = x_gen
x_ln2_gen = layer_norms_2[i](x_input_ffn_gen)
ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)
ffn_activated_gen = F.relu(ffn_hidden_gen)
ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)
x_gen = x_input_ffn_gen + ffn_output_gen # Residual 2
# Final LayerNorm
final_norm_output_gen = final_layer_norm(x_gen)
# Select Hidden State (use last non-padding token's state)
last_token_indices_gen = torch.sum(batch_gen_prompt_masks, 1) - 1
last_token_indices_gen = torch.clamp(last_token_indices_gen, min=0)
batch_indices_gen = torch.arange(B_gen, device=device)
last_token_hidden_states_gen = final_norm_output_gen[batch_indices_gen, last_token_indices_gen, :]
# Project to Image Feature Dimension
predicted_feature_vector = text_to_image_feature_layer(last_token_hidden_states_gen)
print(f"Generated predicted feature vector with shape: {predicted_feature_vector.shape}") # Should be (1, vision_feature_dim)
步骤 4.3:查找最接近的已知图像(简化重建)
理论:将预测的特征向量与我们已知训练图像的预计算特征向量(known_features_list)进行比较。找到特征向量与预测向量距离最小(如欧几里得距离或余弦距离)的已知图像,并显示该图像。
print("\n步骤4.3:寻找最接近的已知图像...")
# --- 计算距离 ---
# 理论:计算预测向量与每个已知向量之间的距离。
# 我们使用余弦距离:1 - 余弦相似度。距离越小越好。
predicted_vec = predicted_feature_vector.squeeze(0).cpu().numpy() # 移至CPU并转换为numpy供scipy使用
min_distance = float('inf')
closest_image_path = None
for known_path, known_vec_tensor in known_features_list:
known_vec = known_vec_tensor.cpu().numpy()
# 计算余弦距离
# dist = scipy_distance.cosine(predicted_vec, known_vec)
# 或者计算欧几里得距离(L2范数)
dist = scipy_distance.euclidean(predicted_vec, known_vec)
# print(f" 到 {os.path.basename(known_path)} 的距离: {dist:.4f}") # 可选:打印距离
if dist < min_distance:
min_distance = dist
closest_image_path = known_path
# --- 显示结果 ---
if closest_image_path:
print(f"Closest match found: '{os.path.basename(closest_image_path)}' with distance {min_distance:.4f}")
# 使用PIL或matplotlib显示图像
try:
matched_img = Image.open(closest_image_path)
print("Displaying the closest matching image:")
# 在notebook环境中,简单地显示对象通常就可以工作:
# matched_img
# 或者使用matplotlib:
import matplotlib.pyplot as plt
plt.imshow(matched_img)
plt.title(f"Generated for: '{generation_prompt_text}'\nClosest Match: {os.path.basename(closest_image_path)}")
plt.axis('off')
plt.show()
except FileNotFoundError:
print(f"Error: Could not load the matched image file at {closest_image_path}")
except Exception as e:
print(f"Error displaying image: {e}")
else:
print("Could not determine the closest image.")
步骤 5:保存模型状态(可选)
要保存我们的文本到图像生成模型,您需要创建一个包含所有模型组件和配置的字典,然后使用 torch.save()。具体方法如下:
import os
# 如果目录不存在则创建
save_dir = 'saved_models'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, 'text_to_image_model.pt')
# 创建包含所有相关组件和配置的字典
text_to_image_state_dict = {
# 配置
'config': {
'vocab_size': vocab_size,
'd_model': d_model,
'n_heads': n_heads,
'n_layers': n_layers,
'd_ff': d_ff,
'block_size': block_size,
'vision_feature_dim': vision_feature_dim
},
# 分词器
'tokenizer': {
'char_to_int': char_to_int,
'int_to_char': int_to_char
},
# 模型权重(可训练部分)
'token_embedding_table': token_embedding_table.state_dict(),
'positional_encoding': positional_encoding, # 未训练,但重建时需要
'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],
'mha_qkv_linears': [l.state_dict() for l in mha_qkv_linears],
'mha_output_linears': [l.state_dict() for l in mha_output_linears],
'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],
'ffn_linear_1': [l.state_dict() for l in ffn_linear_1],
'ffn_linear_2': [l.state_dict() for l in ffn_linear_2],
'final_layer_norm': final_layer_norm.state_dict(),
'text_to_image_feature_layer': text_to_image_feature_layer.state_dict() # 新的输出层
# 注意:我们不在这里保存冻结的vision_model权重,
# 因为我们假设它在使用时会从torchvision单独加载。
}
# 保存到文件
torch.save(text_to_image_state_dict, save_path)
print(f"文本到图像模型已保存到 {save_path}")
加载保存的文本到图像模型
要加载模型,您需要逆转保存过程:
# 加载保存的文本到图像模型
# 加载保存的状态字典
load_path = 'saved_models/text_to_image_model.pt'
if os.path.exists(load_path):
loaded_t2i_state = torch.load(load_path, map_location=device)
print(f"从'{load_path}'加载状态字典。")
# 提取配置和分词器
config = loaded_t2i_state['config']
vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
block_size = config['block_size']
vision_feature_dim = config['vision_feature_dim']
d_k = d_model // n_heads
char_to_int = loaded_t2i_state['tokenizer']['char_to_int']
int_to_char = loaded_t2i_state['tokenizer']['int_to_char']
# 重新创建因果掩码
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
# 重建并加载模型组件
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_t2i_state['token_embedding_table'])
positional_encoding = loaded_t2i_state['positional_encoding'].to(device)
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []
for i in range(n_layers):
# Load Layer Norm 1
ln1 = nn.LayerNorm(d_model).to(device)
ln1.load_state_dict(loaded_t2i_state['layer_norms_1'][i])
layer_norms_1.append(ln1)
# Load MHA QKV Linear
qkv_dict = loaded_t2i_state['mha_qkv_linears'][i]
has_bias = 'bias' in qkv_dict
qkv = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)
qkv.load_state_dict(qkv_dict)
mha_qkv_linears.append(qkv)
# Load MHA Output Linear
mha_out_dict = loaded_t2i_state['mha_output_linears'][i]
has_bias = 'bias' in mha_out_dict
mha_out = nn.Linear(d_model, d_model, bias=has_bias).to(device)
mha_out.load_state_dict(mha_out_dict)
mha_output_linears.append(mha_out)
# Load Layer Norm 2
ln2 = nn.LayerNorm(d_model).to(device)
ln2.load_state_dict(loaded_t2i_state['layer_norms_2'][i])
layer_norms_2.append(ln2)
# Load FFN Linear 1
ffn1_dict = loaded_t2i_state['ffn_linear_1'][i]
has_bias = 'bias' in ffn1_dict
ff1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)
ff1.load_state_dict(ffn1_dict)
ffn_linear_1.append(ff1)
# Load FFN Linear 2
ffn2_dict = loaded_t2i_state['ffn_linear_2'][i]
has_bias = 'bias' in ffn2_dict
ff2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)
ff2.load_state_dict(ffn2_dict)
ffn_linear_2.append(ff2)
# Load Final LayerNorm
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_t2i_state['final_layer_norm'])
# Load Text-to-Image Feature Layer
t2i_out_dict = loaded_t2i_state['text_to_image_feature_layer']
has_bias = 'bias' in t2i_out_dict
text_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim, bias=has_bias).to(device)
text_to_image_feature_layer.load_state_dict(t2i_out_dict)
print("文本到图像模型组件加载成功。")
else:
print(f"在{load_path}未找到模型文件。无法加载模型。")
第六步:总结
关键步骤包括:
- 加载:重用之前多模态模型中的文本 Transformer 组件和 ResNet 特征提取器。
- 数据:定义与目标图像配对的文本提示,并使用冻结的 ResNet 预提取目标图像特征向量。
- 架构调整:将 Transformer 的最终输出层替换为新的线性层,将隐藏状态投影到图像特征维度。
- 训练:训练 Transformer 组件和新输出层,以最小化给定文本提示的预测图像特征向量与目标图像特征向量之间的均方误差(MSE)。
- 生成与简化重建:使用训练好的模型从新的文本提示中预测特征向量,然后找到实际特征向量与预测向量最接近的训练图像(使用欧几里得距离)并显示该图像。
该方法展示了在保持内联实现约束的同时,使用 Transformer 进行跨模态生成(文本到视觉表示)的概念。它避免了直接像素生成(GANs、扩散模型)的显著复杂性,但通过在已知图像的特征空间中进行最近邻搜索,提供了一个有形的基础视觉输出。现实中的文本到图像模型要复杂得多,通常结合不同的架构并在海量数据集上进行训练。



















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











