







文章目录
where子句的and,or操作符
需要更强的过滤控制,之前都是用的单一条件,即只用一个where子句,现在用多个where子句组合更多的条件。组合方式有两只在种:and子句的方式,或者or子句的方式

and, or就是逻辑操作符

and逻辑操作符

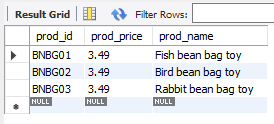
select prod_id, prod_price, prod_name
from products
where vend_id = 'DLL01' AND prod_price <=4;
可以有更多条件
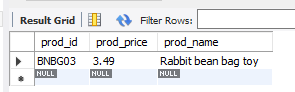
select prod_id, prod_price, prod_name
from products
where vend_id = 'DLL01' AND prod_price <=4 and prod_id='BNBG03';
or逻辑操作符

有的实现里,有短路性质,有的没有,比如mysql就没有

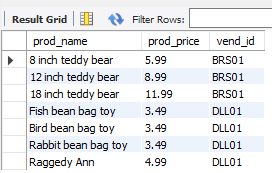
select prod_name, prod_price,vend_id
from products
where vend_id = 'DLL01' OR vend_id = 'BRS01';
从这里的实际输出来看,并没有短路,第一个条件和第二个条件都执行了的
求值顺序:and 和 or相遇,用圆括号对操作符明确分组
主要是涉及到优先级,and的优先级比or高,所以要用括号,括号的优先级比and更高
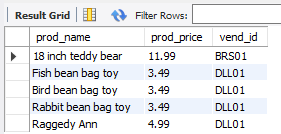
select prod_name, prod_price, vend_id
from products
where vend_id = 'DLL01' OR vend_id = 'BRS01'
AND prod_price >= 10;
看来,最后一个and条件只作用于了vend_id = 'BRS01’条件。


select prod_name, prod_price, vend_id
from products
where (vend_id = 'DLL01' OR vend_id = 'BRS01')
AND prod_price >= 10;
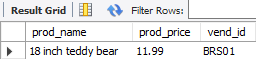

IN 操作符:指定条件范围,和OR功能一样

select prod_name, prod_price, vend_id
from products
where vend_id in ('DLL01', 'BRS01')
ORDER BY prod_name;
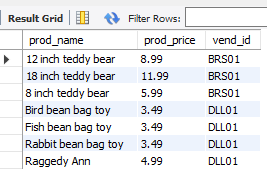
其实in的功能和or一样,但是代码更短
select prod_name, prod_price, vend_id
from products
where vend_id ='DLL01' or vend_id = 'BRS01'
ORDER BY prod_name;

not操作符:复杂子句中非常有用

select prod_name, vend_id
from products
where not vend_id = 'DLL01'
ORDER BY prod_price;
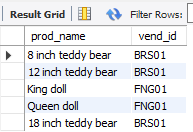
和下面的两段代码功能一样
select prod_name, vend_id
from products
where vend_id != 'DLL01'
ORDER BY prod_price;
select prod_name, vend_id
from products
where vend_id <> 'DLL01'
ORDER BY prod_price;

总结
- 注意用圆括号管理求值顺序
- 用and,or操作符组合where子句
- 用in和not操作符筛选条件















 2515
2515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









