






PAPER:Autonomous Driving Strategies at Intersections: Scenarios, State-of-the-Art, and Future Outlooks
Abstract
由于交叉口场景的复杂性和动态性,交叉口自动驾驶策略一直是近年来智能交通系统研究的难点和热点。本文对目前最先进的交叉口自动驾驶策略进行了简要总结。首先列举并分析了常见的交集场景类型、对应的仿真平台以及相关数据集。其次,通过回顾前人的研究,总结了现有自动驾驶策略的特点,并将其划分为几个类别。最后,指出了现有自动驾驶策略存在的问题,并提出了一些有价值的研究展望。
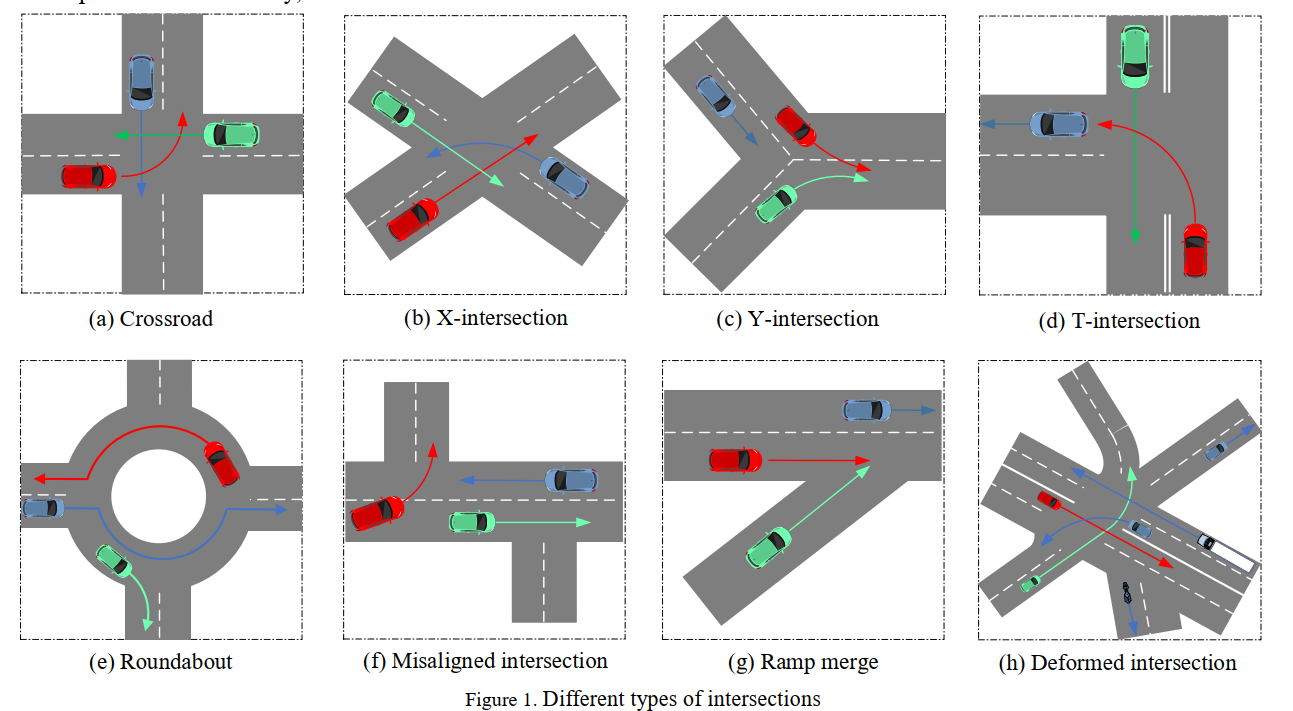
常见检查口总结
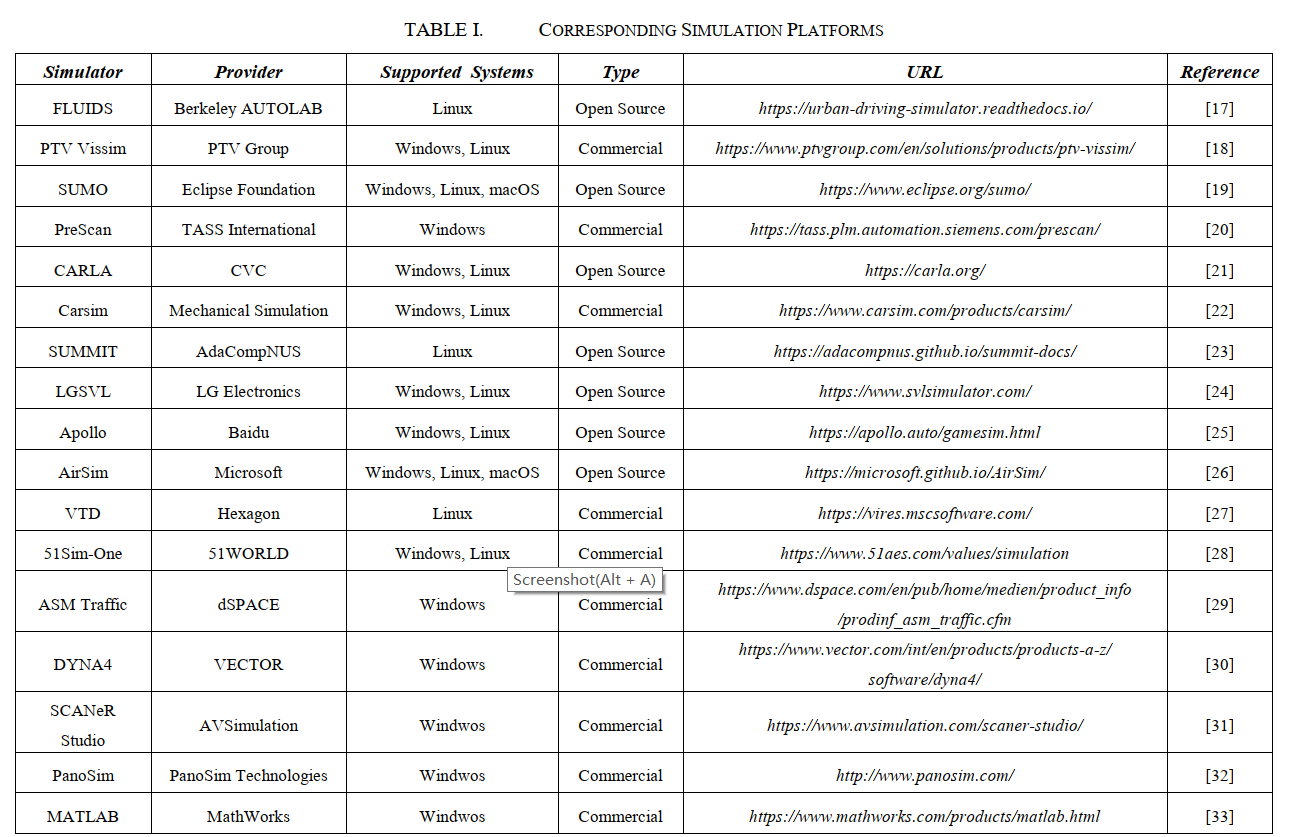
常用平台
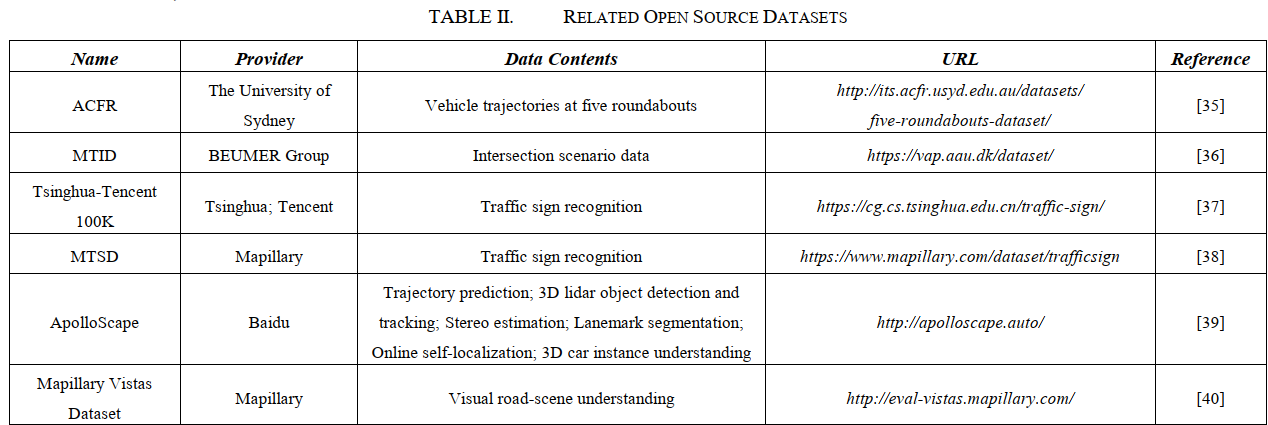
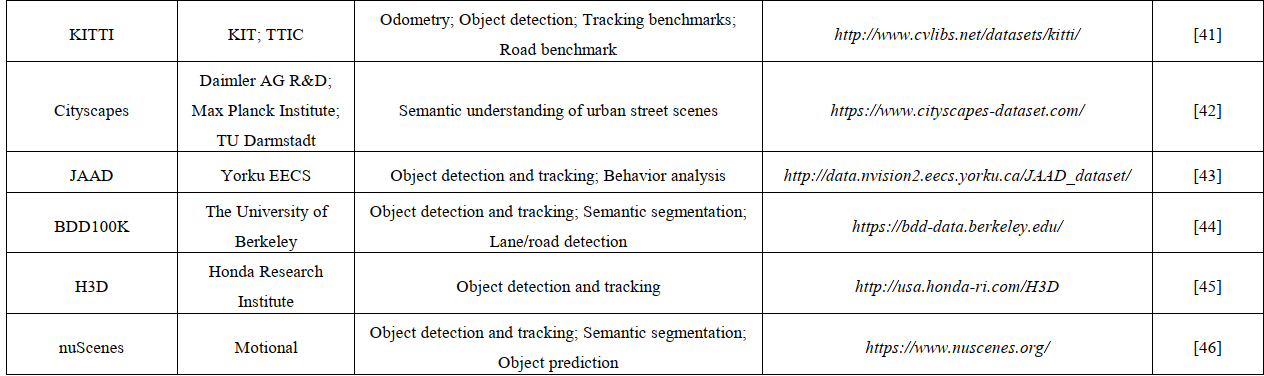
常用数据集
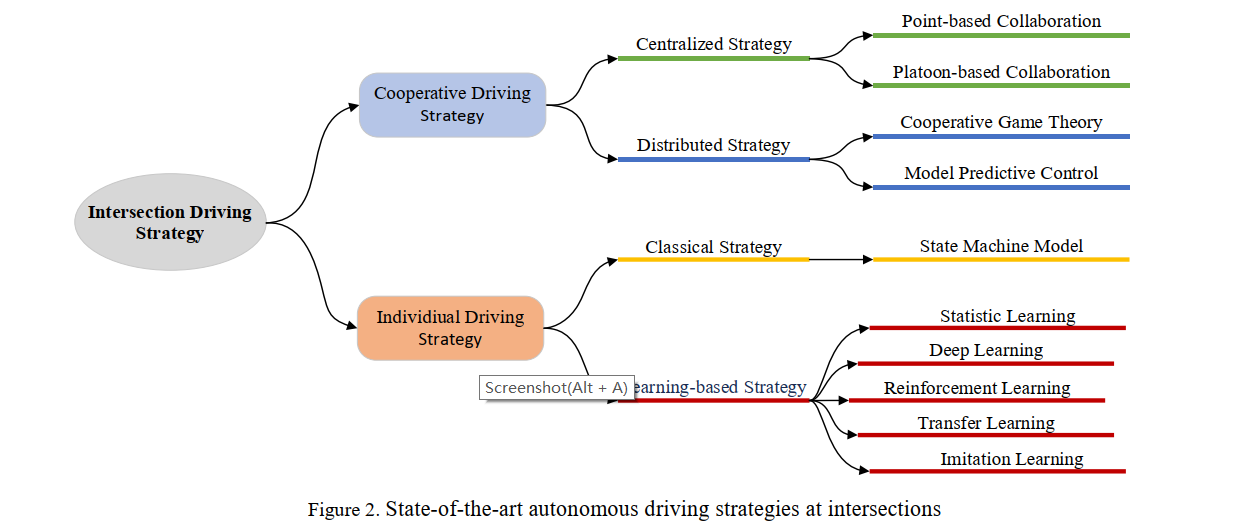
交叉口策略
首先,将自动驾驶策略分为合作驾驶策略和个体驾驶策略。合作驾驶策略可分为集中式驾驶策略和分布式驾驶策略,个体驾驶策略可分为经典驾驶策略和学习型驾驶策略。每个策略包括许多特定的方法,如图所示。
参考:https://zhuanlan.zhihu.com/p/393906132















 6620
6620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









