







最近因为项目的需要,目前学了两个星期的强化学习,为了验证自己的学习成果,特此进行输出,以检验自己的学习情况。
文章目录
1. 环境安装
首先利用Anaconda创建虚拟环境,然后安装下面两个库。至于细节,自行进行百度进行安装,这里不进行详细讲解。
2. 强化学习基础知识
2.1 什么是强化学习(RL)
广泛地讲,强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。强化学习用**智能体(agent)**这个概念来表示做决策的机器。
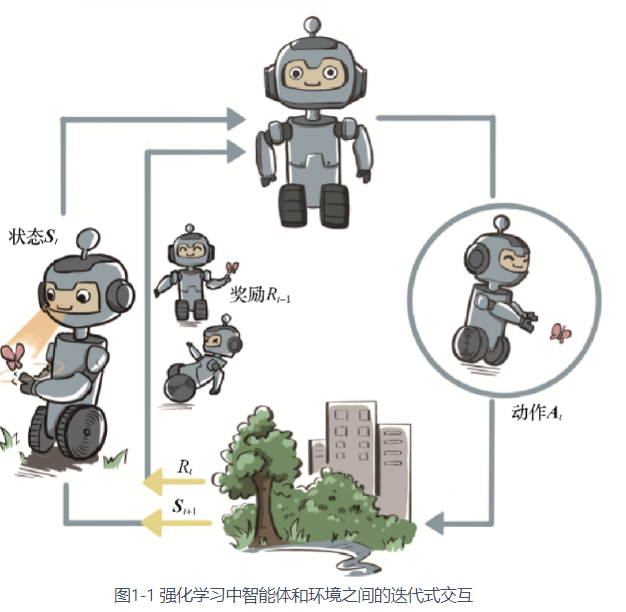
2.2 强化学习的核心
2.2.1 贝尔曼方程
强化学习的灵魂是贝尔曼期望方程以及贝尔曼最优方程。
首先,我们想评价一个策略是否是好的,我们只需要看从状态S到终止状态时,其所有的奖励是否够大。公式如下:
G t = R t + γ R t + 1 + γ 2 R t + 2 + . . . = ∑ k = 0 ∞ γ k R t + k G_t=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+...= \sum_{k=0}^\infty\gamma^kR_{t+k} Gt=Rt+γRt+1+γ2Rt+2+...=k=0∑∞γkRt+k
其中 R t R_t Rt表示智能体在时刻 t t t下的奖励, γ \gamma γ表示衰减因子,这个变量的作用是用来平衡长期奖励以及短期奖励。
上面公式中我们只是给出了从状态 S S S出发,某一情况下的奖励,众所周知,从状态S出发,其可能性是多种多样的,因此,我们需要采用概率论中的期望概念。同时为了能够得到所有状态的价值,采用 V ( s ) V(s) V(s)来表示,定义如下:
V ( s ) = E [ G t ∣ S t = s ] = E [ R t + γ R t + 1 + γ 2 R t + 2 + … ∣ S t = s ] = E [ R t + γ ( R t + 1 + γ R t + 2 + … ) ∣ S t = s ] = E [ R t + γ G t + 1 ∣ S t = s ] = E [ R t + γ V ( S t + 1 ) ∣ S t = s ] \begin{aligned} V(s)& =\mathbb{E}[G_{t}|S_{t}=s] \\ &=\mathbb{E}[R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\ldots|S_t=s] \\ &=\mathbb{E}[R_t+\gamma(R_{t+1}+\gamma R_{t+2}+\ldots)|S_t=s] \\ &=\mathbb{E}[R_t+\gamma G_{t+1}|S_t=s] \\ &=\mathbb{E}[R_t+\gamma V(S_{t+1})|S_t=s] \end{aligned} V(s)=E[Gt∣St=s]=E[Rt+γRt+1+γ2Rt+2+…∣St=s]=E[Rt+γ(Rt+1+γRt+2+…)∣St=s]=E[Rt+γGt+1∣St=s]=E[Rt+γV(St+1)∣St=s]
其中,令 E [ R t ∣ S t = s ] = r ( s ) E[R_t|S_t=s] =r(s) E[Rt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3447
3447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











