






小米商城格式化检测点:
var a = function () {
var x = !0;
return function (a, t) {
var e = x ? function () {
if (t) {
var x = t.apply(a, arguments);
t = null;
return x;
}
} : function () {};
x = !1;
return e;
};
}();
var t = {};
function e(n) {
var r = a(this, function () {
var x = function () {
return "dev";
},
a = function () {
return "window";
};
var t = function () {
var a = new RegExp("\\w+ *\\(\\) *{\\w+ *['|\"].+['|\"];? *}");
return !a.test(x.toString());
};
var e = function () {
var x = new RegExp("(\\\\[x|u](\\w){2,4})+");
return x.test(a.toString());
};
var n = function (x) {
var a = 0;
x.indexOf("i" === a) && r(x);
};
var r = function (x) {
var a = 3;
x.indexOf((!0 + "")[3]) !== a && n(x);
};
t() ? n("indеxOf") : e() ? n("indexOf") : n("indеxOf");
});
r();
}
e(e.s=124)
执行这段代码后,将出现循环调用出现栈溢出。。
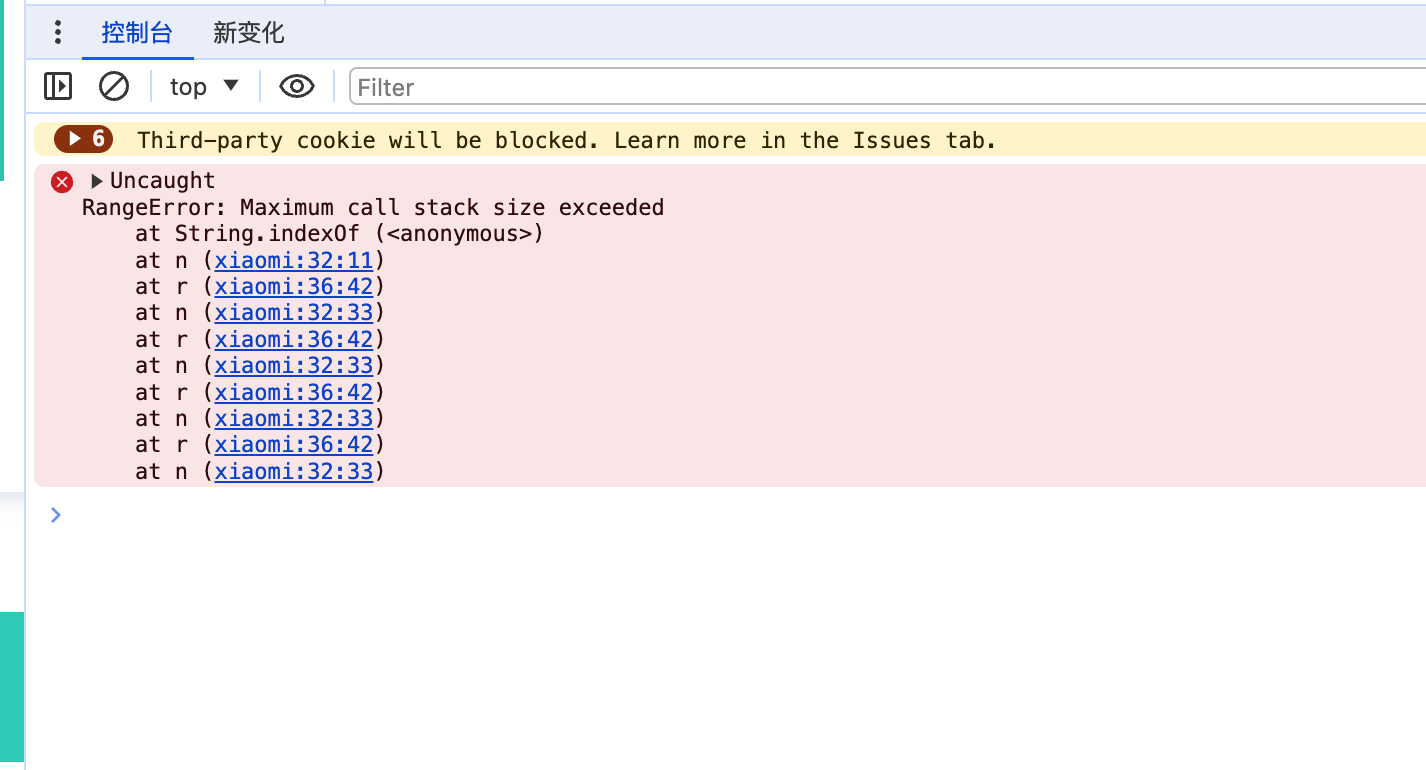
查看栈:

一看n和r互相调用
快刀斩乱麻:
1.让其中一个不去调用另一个,于是找到n将调用r的代码注释:
var n = function (x) {
var a = 0;
//x.indexOf("i" === a) && r(x);
};
运行看看:
成功执行。
但是知其然,知其所以然,看看它是检测啥?
进入第一个调用的地方:
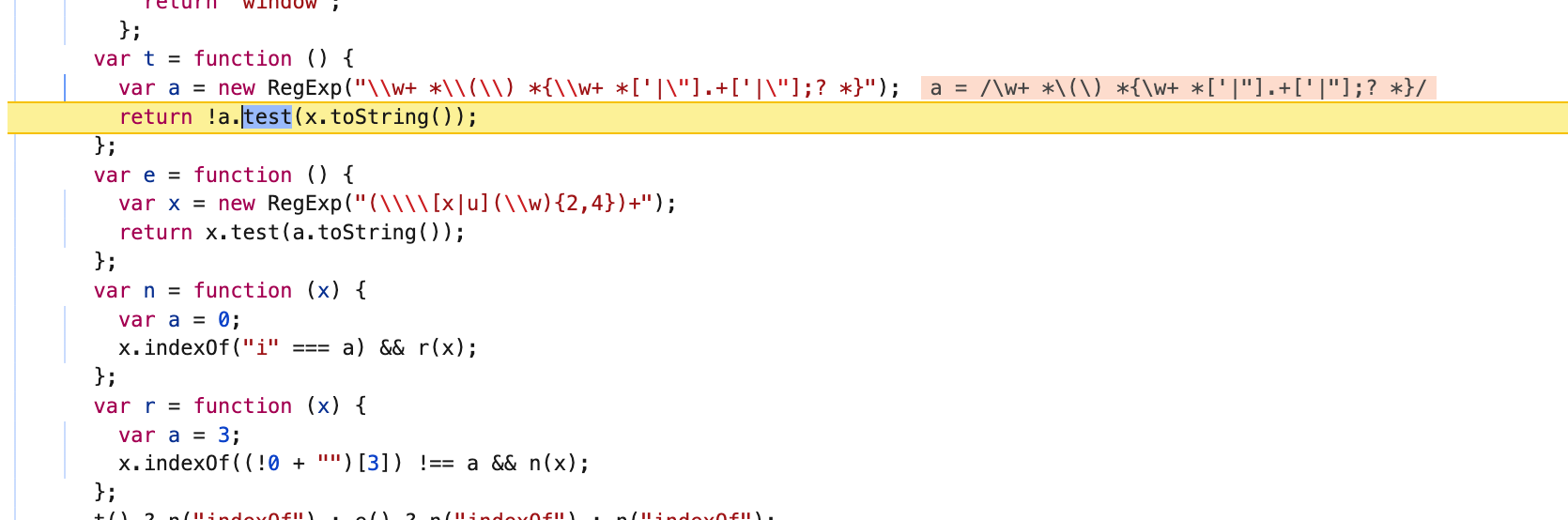

仔细看这个a正则表达式,可以看出,a格式上必须满足没有换行符…
那就把a还原,弄成一行,但是,运行后又进入了e函数:

这个格式就比较鬼畜了,有没有换行符都返回false。
仔细看这:
t() ? n("indеxOf") : e() ? n("indexOf") : n("indеxOf");
t检测为假后,又进入了e的检测,e检测为真还是假,都会调用n(‘indexOf’),进入死循环,
但是t检测为真呢?依然进入n(“indexOf”)进入死循环呀!!!这尼玛什么鬼!突然想到,我勒个去,我这是反混淆后的代码,我们得看看原来的代码才行!
原来的代码:
var _0x2af70d = function() {
return '\x64\x65\x76';
}
, _0x149eed = function() {
return '\x77\x69\x6e\x64\x6f\x77';
};
var _0x1ba3ec = function() {
var _0x326b6c = new RegExp('\x5c\x77\x2b\x20\x2a\x5c\x28\x5c\x29\x20\x2a\x7b\x5c\x77\x2b\x20\x2a\x5b\x27\x7c\x22\x5d\x2e\x2b\x5b\x27\x7c\x22\x5d\x3b\x3f\x20\x2a\x7d');
return !_0x326b6c['\x74\x65\x73\x74'](_0x2af70d['\x74\x6f\x53\x74\x72\x69\x6e\x67']());
};
var _0x567cbd = function() {
var _0x566a50 = new RegExp('\x28\x5c\x5c\x5b\x78\x7c\x75\x5d\x28\x5c\x77\x29\x7b\x32\x2c\x34\x7d\x29\x2b');
return _0x566a50['\x74\x65\x73\x74'](_0x149eed['\x74\x6f\x53\x74\x72\x69\x6e\x67']());
};
var _0x828b58 = function(_0x4770f2) {
var _0x5fe41d = ~-0x1 >> 0x1 + 0xff % 0x0;
if (_0x4770f2['\x69\x6e\x64\x65\x78\x4f\x66']('\x69' === _0x5fe41d)) {
_0x1670cc(_0x4770f2);
}
};
var _0x1670cc = function(_0x413b09) {
var _0x4a50c7 = ~-0x4 >> 0x1 + 0xff % 0x0;
if (_0x413b09['\x69\x6e\x64\x65\x78\x4f\x66']((!![] + '')[0x3]) !== _0x4a50c7) {
_0x828b58(_0x413b09);
}
};
if (!_0x1ba3ec()) {
if (!_0x567cbd()) {
_0x828b58('\x69\x6e\x64\u0435\x78\x4f\x66');
} else {
_0x828b58('\x69\x6e\x64\x65\x78\x4f\x66');
}
} else {
_0x828b58('\x69\x6e\x64\u0435\x78\x4f\x66');
}
});
_0x39ebcf();
_0x828b58('\x69\x6e\x64\u0435\x78\x4f\x66');
我勒个去,这个indexOf是byte形式的字符串,它对e进行索引是找不到e的,所以这里还是检测是否将\x形式\u形式的字符串进行了反混淆
总结:
1.检测是否将字符串的\x \u形式反混淆
2.检测是否换行格式化
综上思路的话,大概明白了他是怎么检测的了。这样的话,也就知道怎么去处理了,反正处理方式很多的,但是呢,一般原则,省时省力,处理的话,最好就是最开始的那种,干掉互相调用链,或者就是找到调用入口直接注释,这里就是:
function e(n) {
var r = a(this, function () {
var x = function () {
return "dev";
},
a = function () {
return "window";
};
var t = function () {
var a = new RegExp("\\w+ *\\(\\) *{\\w+ *['|\"].+['|\"];? *}");
return !a.test(x.toString());
};
var e = function () {
var x = new RegExp("(\\\\[x|u](\\w){2,4})+");
return x.test(a.toString());
};
var n = function (x) {
var a = 0;
x.indexOf("i" === a) && r(x);
};
var r = function (x) {
var a = 3;
x.indexOf((!0 + "")[3]) !== a && n(x);
};
t() ? n("indеxOf") : e() ? n("indexOf") : n("indеxOf");
});
//r();
}
直接把r()调用注释,也就可以不进入这一套判断逻辑。
同样的检测地方还有:
var _0xc3cbb7 = function() {
var _0x2c1eed = {
'data': {
'key': 'cookie',
'value': 'timeout'
},
'setCookie': function(_0x2a4253, _0x4a45c8, _0x5a7b75, _0x142fca) {
_0x142fca = _0x142fca || {};
var _0x47dfad = _0x4a45c8 + '=' + _0x5a7b75;
var _0x456411 = 0x0;
for (var _0x456411 = 0x0, _0x2f51c3 = _0x2a4253['length']; _0x456411 < _0x2f51c3; _0x456411++) {
var _0x2e20cf = _0x2a4253[_0x456411];
_0x47dfad += ';\x20' + _0x2e20cf;
var _0x4743a3 = _0x2a4253[_0x2e20cf];
_0x2a4253['push'](_0x4743a3);
_0x2f51c3 = _0x2a4253['length'];
if (_0x4743a3 !== !![]) {
_0x47dfad += '=' + _0x4743a3;
}
}
_0x142fca['cookie'] = _0x47dfad;
},
'removeCookie': function() {
return 'dev';
},
'getCookie': function(_0x5c79de, _0x5a90fd) {
_0x5c79de = _0x5c79de || function(_0x3f5d05) {
return _0x3f5d05;
}
;
var _0x4a6be9 = _0x5c79de(new RegExp('(?:^|;\x20)' + _0x5a90fd['replace'](/([.$?*|{}()[]\/+^])/g, '$1') + '=([^;]*)'));
var _0x7b7045 = function(_0x1f9b0a, _0x3c3639) {
_0x1f9b0a(++_0x3c3639);
};
_0x7b7045(_0x404828, _0x478507);
return _0x4a6be9 ? decodeURIComponent(_0x4a6be9[0x1]) : undefined;
}
};
var _0x40d28c = function() {
var _0x2e7122 = new RegExp('\x5cw+\x20*\x5c(\x5c)\x20*{\x5cw+\x20*[\x27|\x22].+[\x27|\x22];?\x20*}');
return _0x2e7122['test'](_0x2c1eed['removeCookie']['toString']());
};
_0x2c1eed['updateCookie'] = _0x40d28c;
var _0x452d20 = '';
var _0xc45909 = _0x2c1eed['updateCookie']();
if (!_0xc45909) {
_0x2c1eed['setCookie'](['*'], 'counter', 0x1);
} else if (_0xc45909) {
_0x452d20 = _0x2c1eed['getCookie'](null, 'counter');
} else {
_0x2c1eed['removeCookie']();
}
};
_0xc3cbb7();
这个大家自行观看。\
记得加入我们的学习群:961566389
点击链接加入群聊:https://h5.qun.qq.com/s/62P0xwrCNO
















 7329
7329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











