






文章目录
1. 前言
本文主要介绍 BERT 源码预训练的数据准备代码!理清楚几个关键变量的含义:input_ids、input_mask、segment_ids、masked_lm_positions、masked_lm_ids、masked_lm_weights、next_sentence_labels
官方 bert github 源代码 采用的 tensorflow v1 版本,我本地调试采用的是 v2 版本,已上传到我的 bert github ,有需要的自取。bert 的 tensorflow 代码 v1 和 v2 中间有一些兼容性的替换,如下:
import tensorflow as tf -> import tensorflow.compat.v1 as tf如果上面的import不变,也可以把代码的 tf -> tensorflow.compat.v1tf.contrib -> tf.compat.v1.estimatortf.gfile.GFile -> tf.io.gfile.GFiletf.variable_scope -> tf.compat.v1.variable_scope
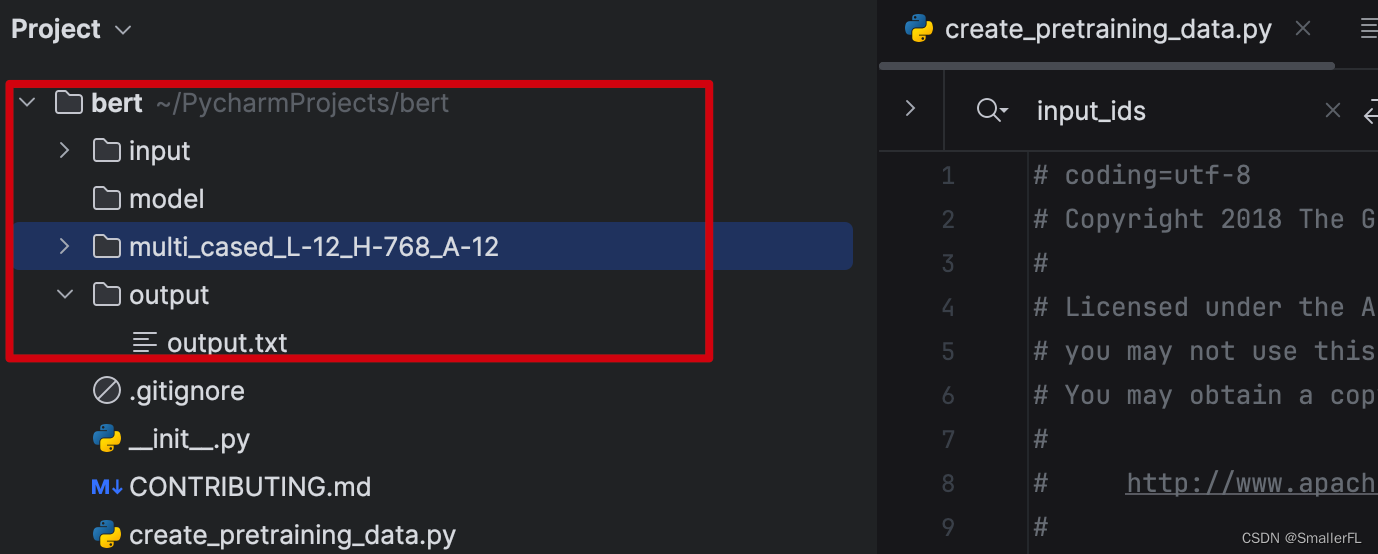
此外,为了跑通 bert 代码,增加了输入输出以及字典文件:
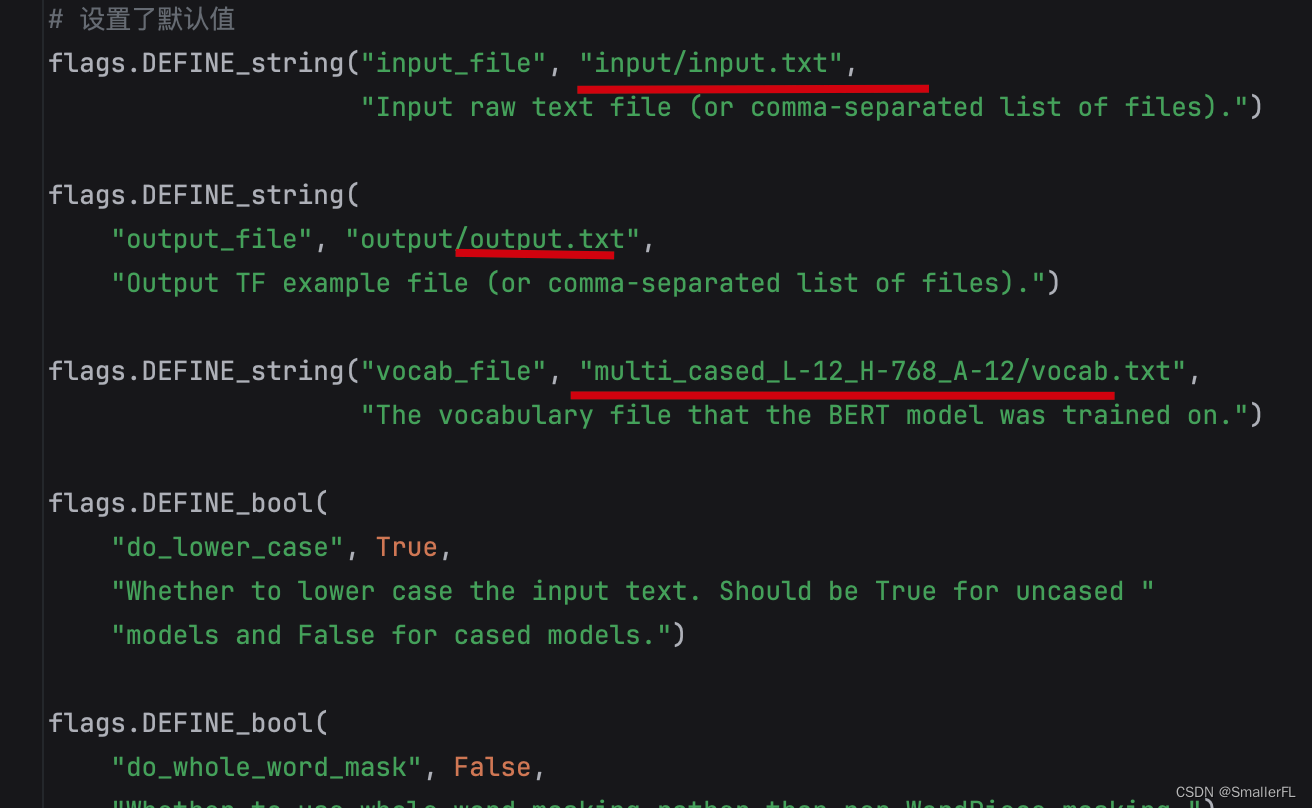
以及增加了 Flag 默认值,例如:
如果不想自己去调整 tensorflow v1 和 v2 版本的差异,建议 fork 或 clone 本人的 bert github 项目,其中已经准备了输入数据,方便调试源代码。
2. 先从数据准备看起
bert 代码中存在一个 python 文件:create_pretraining_data.py,这个文件是用于给预训练准备数据用的。
好,现在跟着我一起去 debug 代码,推荐用 Pycharm(习惯用 vscode 也可以),沉浸式 debug 代码是理解原理的最好方法!
打上断点,然后开启 debug。
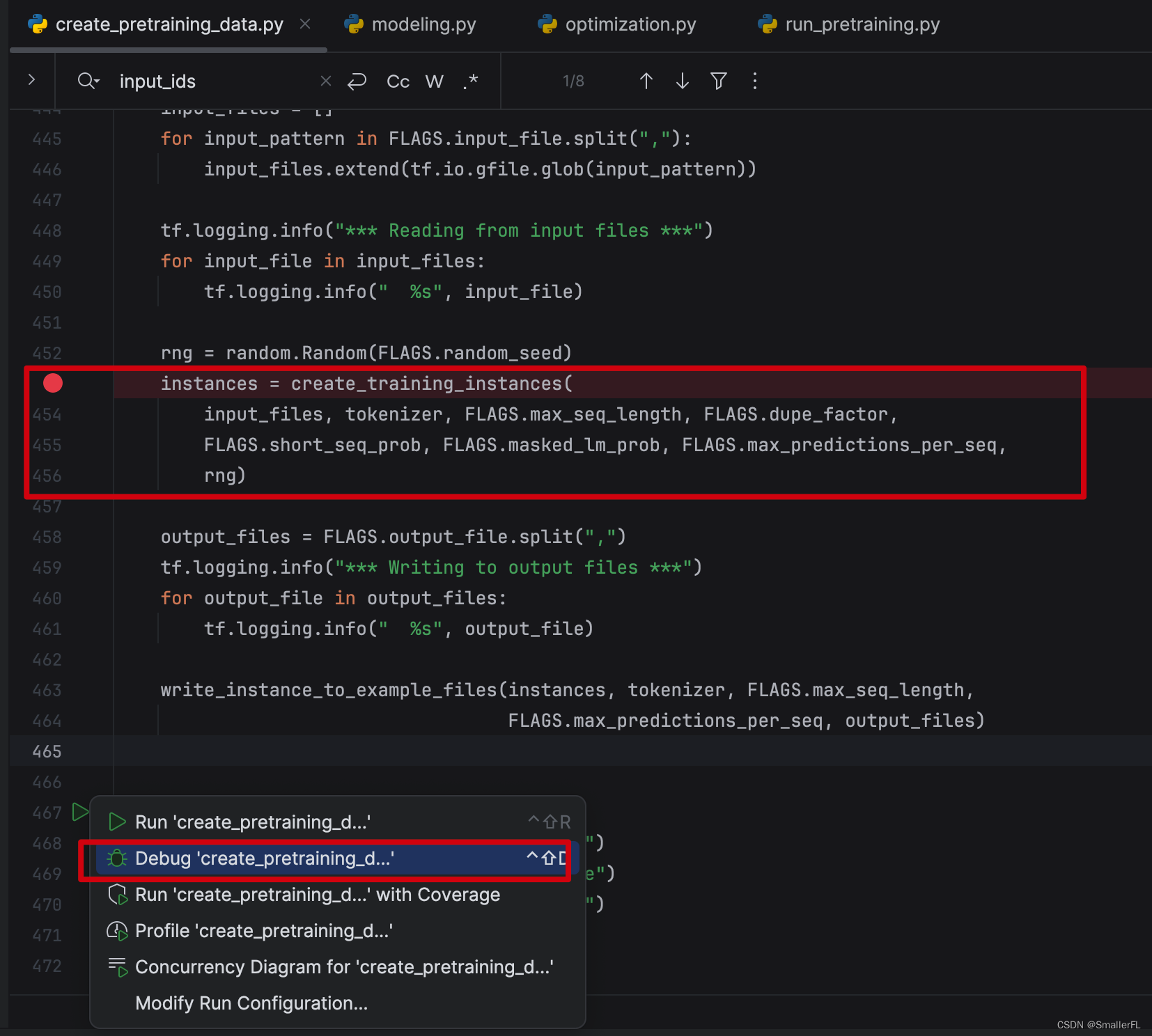
2.1 create_training_instances
进入到第一个方法 create_training_instances。可以看到,input_files 是我准备好的输入语料,
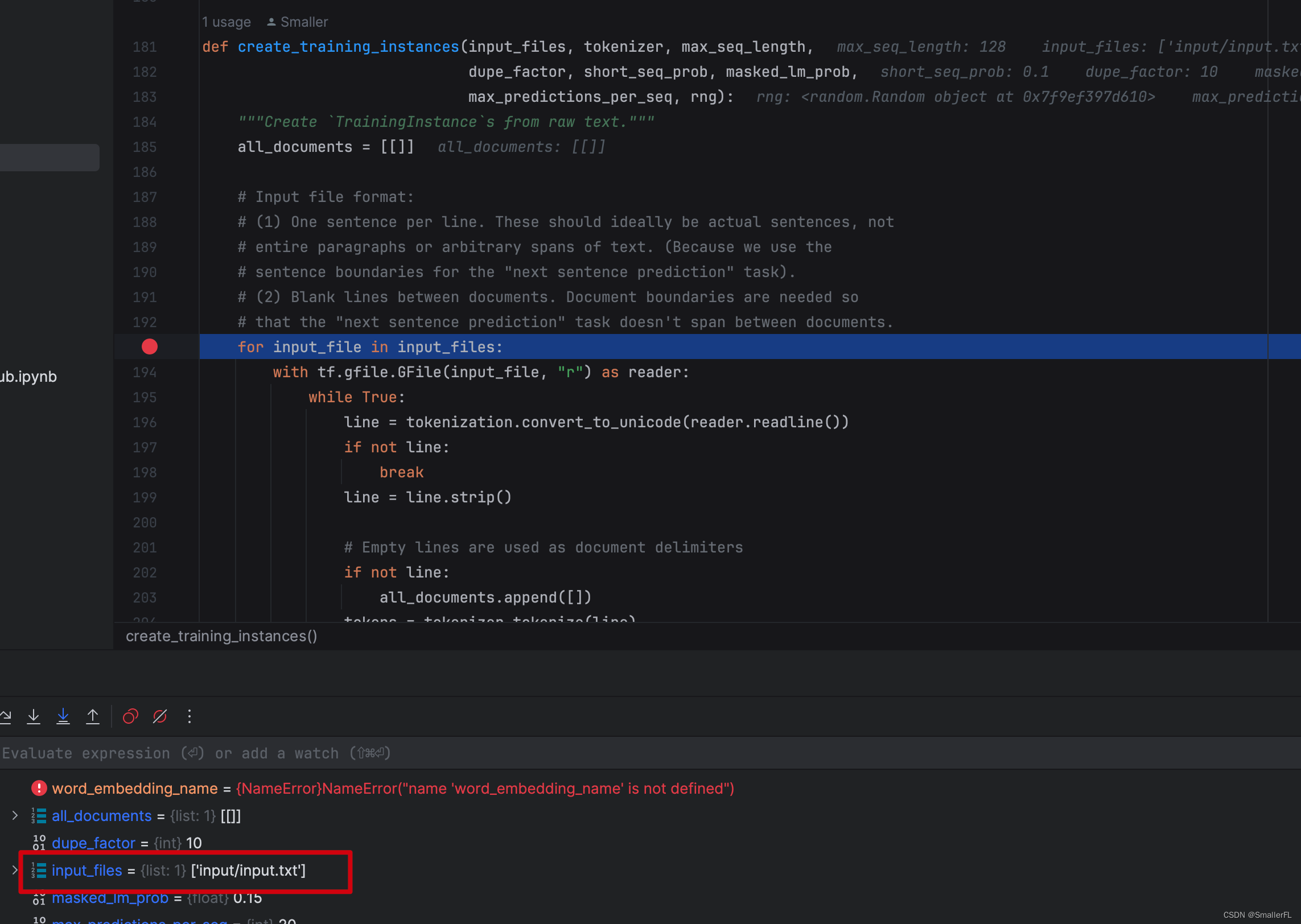
输入的语料在哪呢?我放在了input/input.txt:

那么这段代码很明显,就是把输入数据按照段落加入到 all_documents 列表里,并且打乱段落列表。
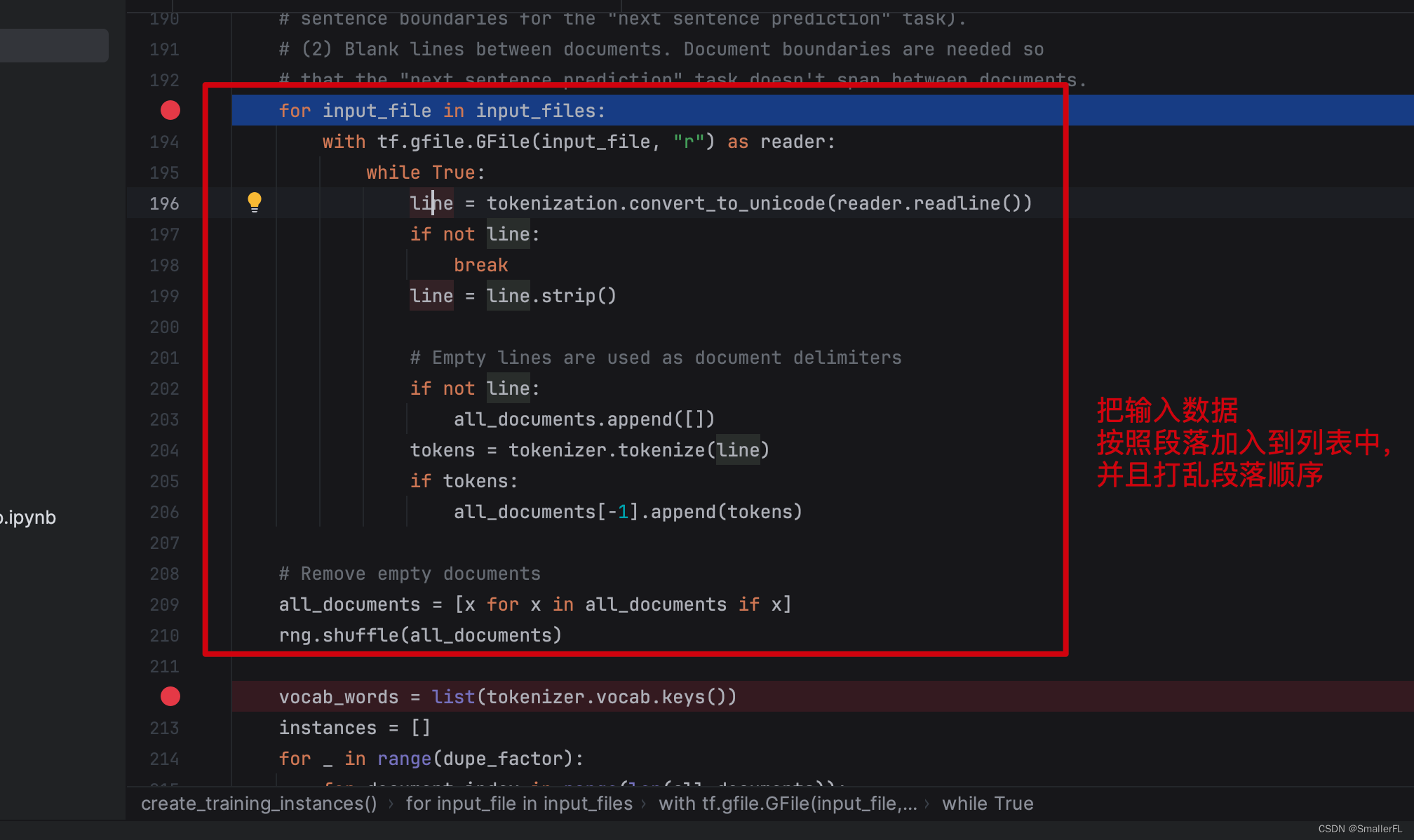
什么是段落(document)?看下面的例子:
BERT is undoubtedly a breakthrough in the use of Machine Learning for Natural Language Processing.
Training the language model in BERT is done by predicting 15% of the tokens in the input, that were randomly picked.
If we used [MASK] 100% of the time the model wouldn’t necessarily produce good token representations for non-masked words.
If we used [MASK] 90% of the time and random words 10% of the time.
If we used [MASK] 90% of the time and kept the same word 10% of the time, then the model could just trivially copy the non-contextual embedding.
这里一共有3个段落,因为英文的段落之间是用空行划分开的。
2.2 vocab_words = list(tokenizer.vocab.keys())
顺着代码接下来看 vocab_words = list(tokenizer.vocab.keys()) 方法,这里是把字典的单词导出成 list
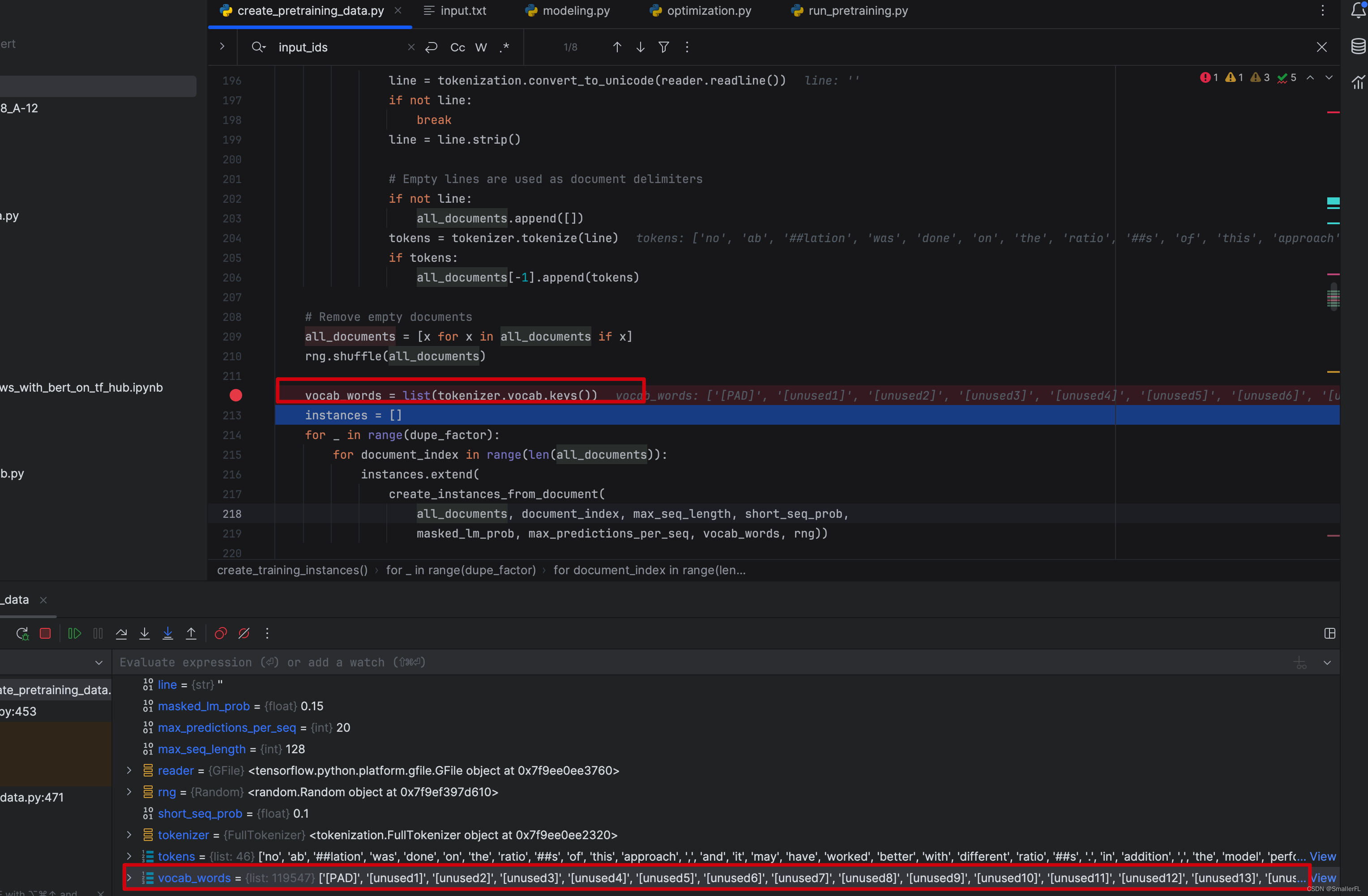
字典从哪来呢?实际源码是没有的,这里是我从官方下载后加入的,放在了 multi_cased_L-12_H-768_A-12/vocab.txt:
2.3 create_instances_from_document
那么顺着代码看,后续最关键的方法就是 create_instances_from_document 了
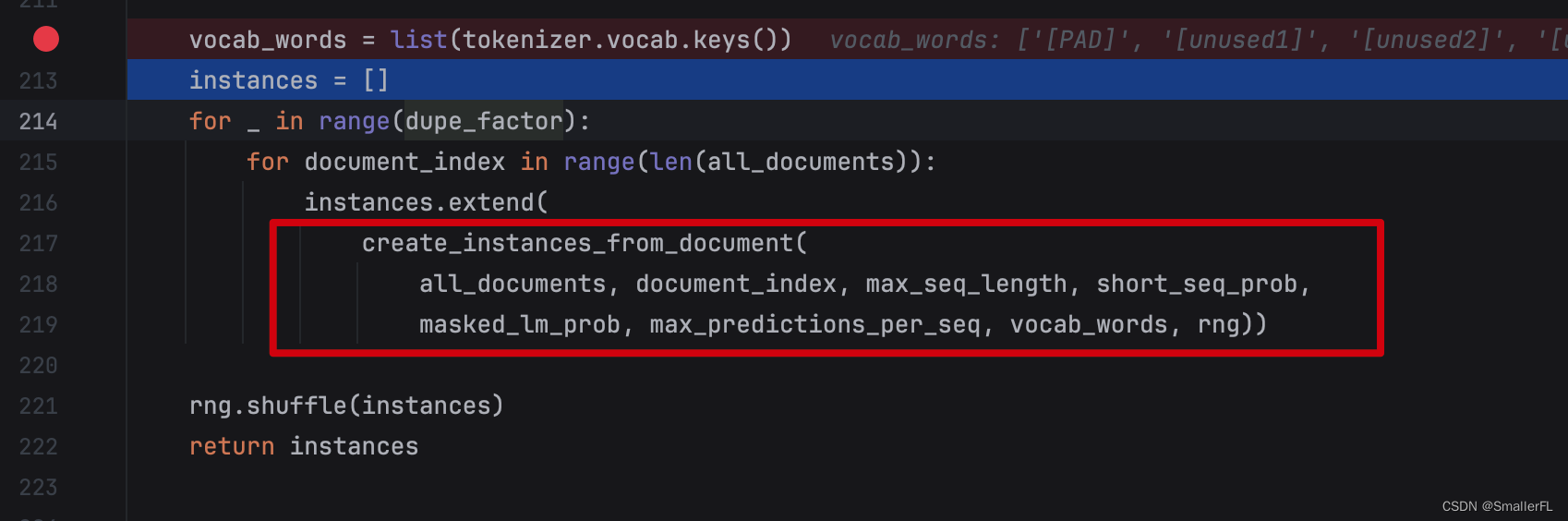
我们进到 create_instances_from_document 函数:
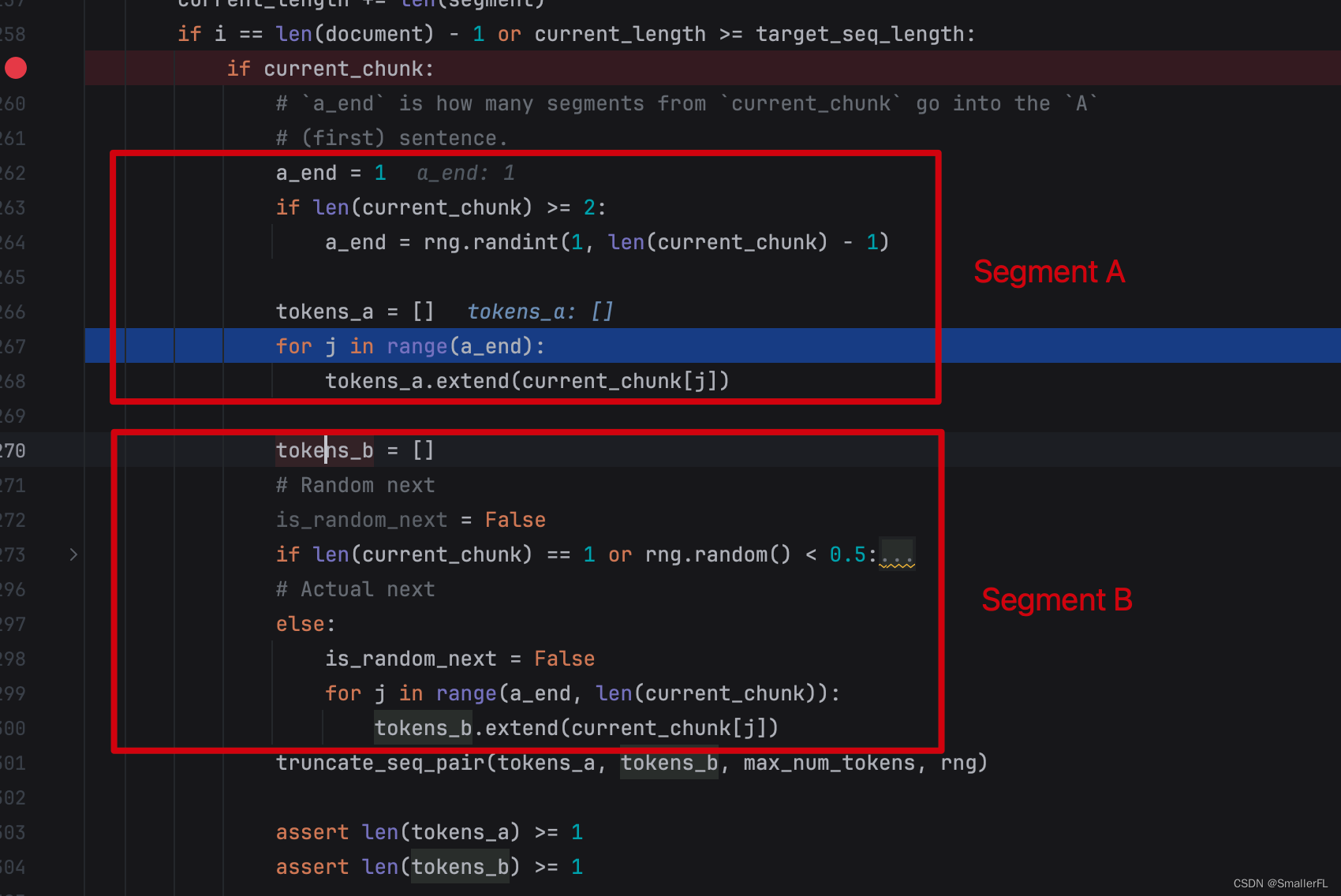
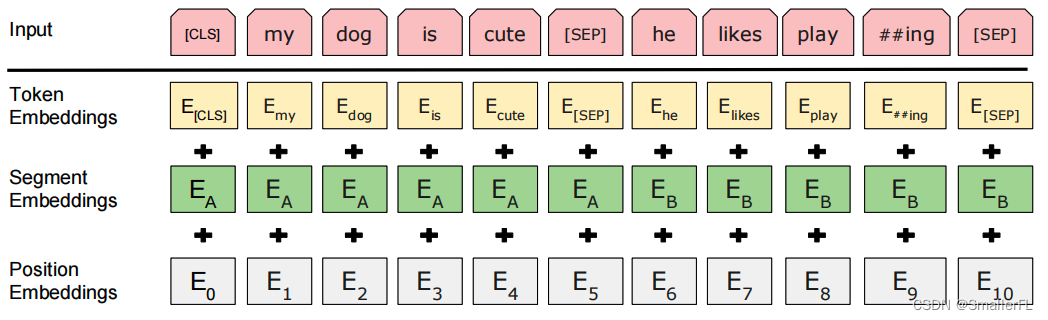
为了理解上述代码的含义,我们先看论文里的 Input 的组成,其中包含有一个 Segment Embedding:
Segment Embedding 的组成是
E
A
E_A
EA 和
E
B
E_B
EB (Segment A 和 Segment B)。其中
E
B
E_B
EB 50% 概率保持顺序不变,即仍然是 A 句子之后的句子 B;50% 概率从其他段落随机抽取一个句子,拼接到 A 句子后。
这个就是论文的 Next Sentence Prediction (NSP)所描述的任务,具体细节可以查看《NLP深入学习:结合源码详解 BERT 模型(一)》 2.2.2 章节。
好了, NSP 的数据准备对应的代码如下:
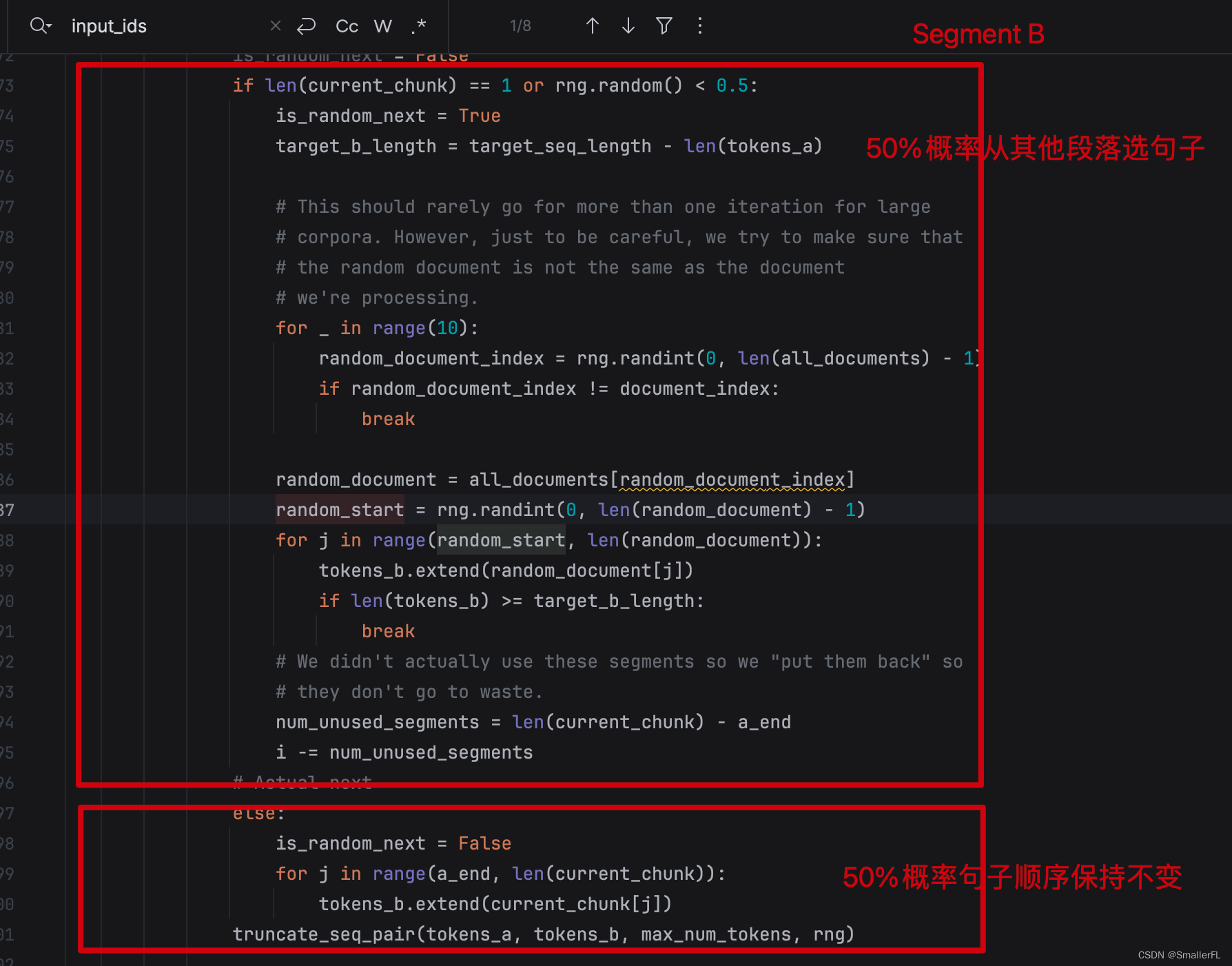
我们接着往下看,代码里出现了 "[CLS]"、"[SEP]" 这个标识,以及 segment_ids.append(0),segment_ids.append(1) 方法
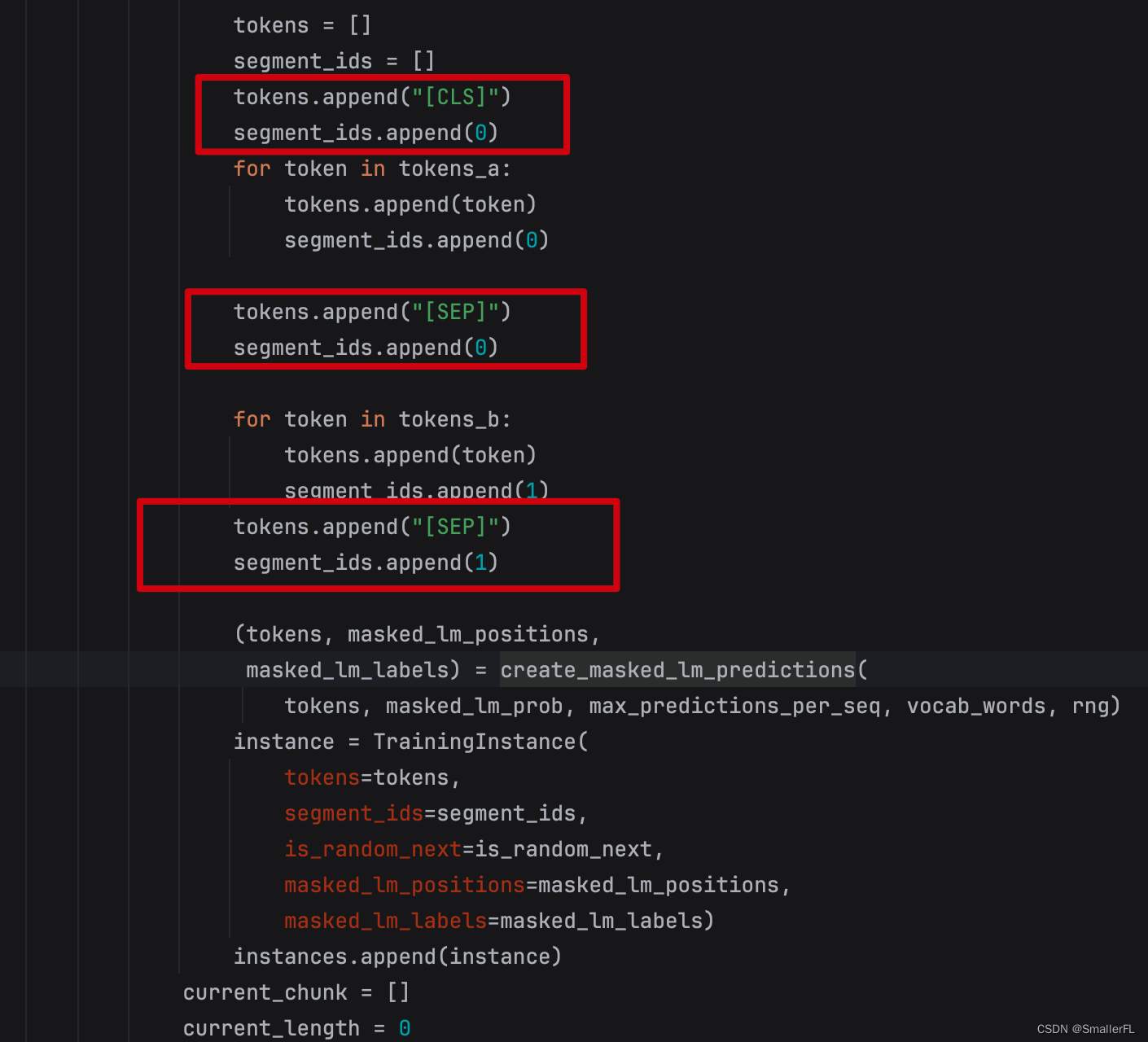
上面的代码已经相当明显了。为了方便理解,我们假如:
句子 A 由以下 token 组成:
[token_a1, token_a2]
句子 B 由以下 token 组成:
[token_b1, token_b2]
那么,代码里最终的 tokens 会组装成这样:
[[CLS],token_a1,token_a2,[SEP],token_b1,token_b2,[SEP]]。
而代码中的 segment_ids,会得到如下结果:
[0,0,0,0,1,1,1]
而 segment_ids 就是 Segment Embedding 的组成:
E
A
E_A
EA +
E
B
E_B
EB
2.4 create_masked_lm_predictions
到目前为止,我们组装了 NSP 所需要的数据。顺着往下看,最重要的函数就是 create_masked_lm_predictions ,而这个函数就是 BERT 所谓的 MASK 的关键数据准备步骤!
首先看这里的代码,还记得论文里说在所有的 tokens 里选择15%的比例用来 MASK 吗,就是这行代码的描述:
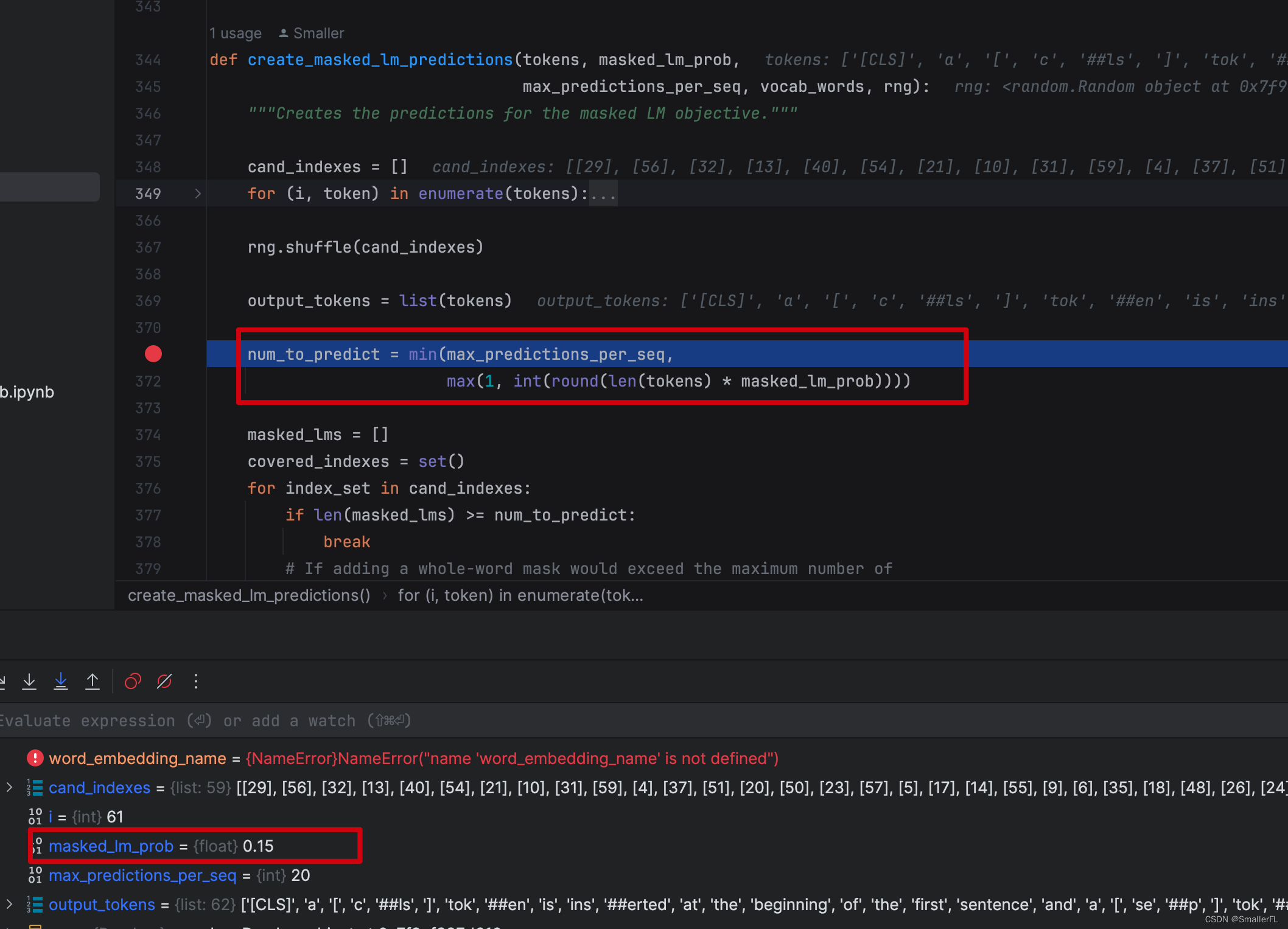
只不过这里的 num_to_predict 有一个最大限度,为 max_predictions_per_seq 即 20,这是设置的默认值!
如果忽略这个值,那么 len(tokens) * masked_lm_prob = len(tokens) * 15% 这就是选择 15% 的比例用来 MASK!
我们接着看 MASK 是如何替换的,看下面代码就非常清楚了!
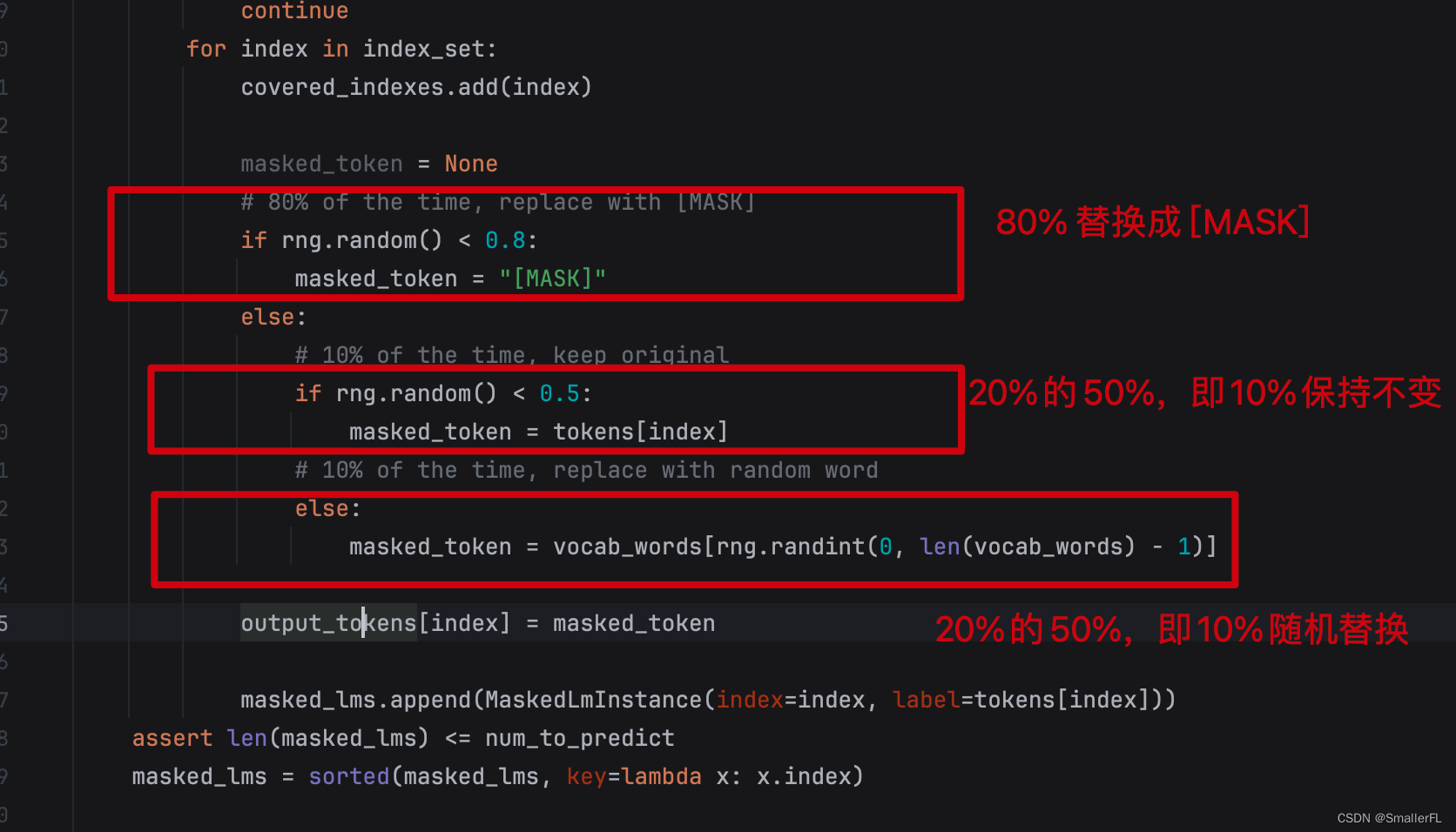
那么这个函数返回的值是啥?返回值有三个(output_tokens, masked_lm_positions, masked_lm_labels),描述如下:
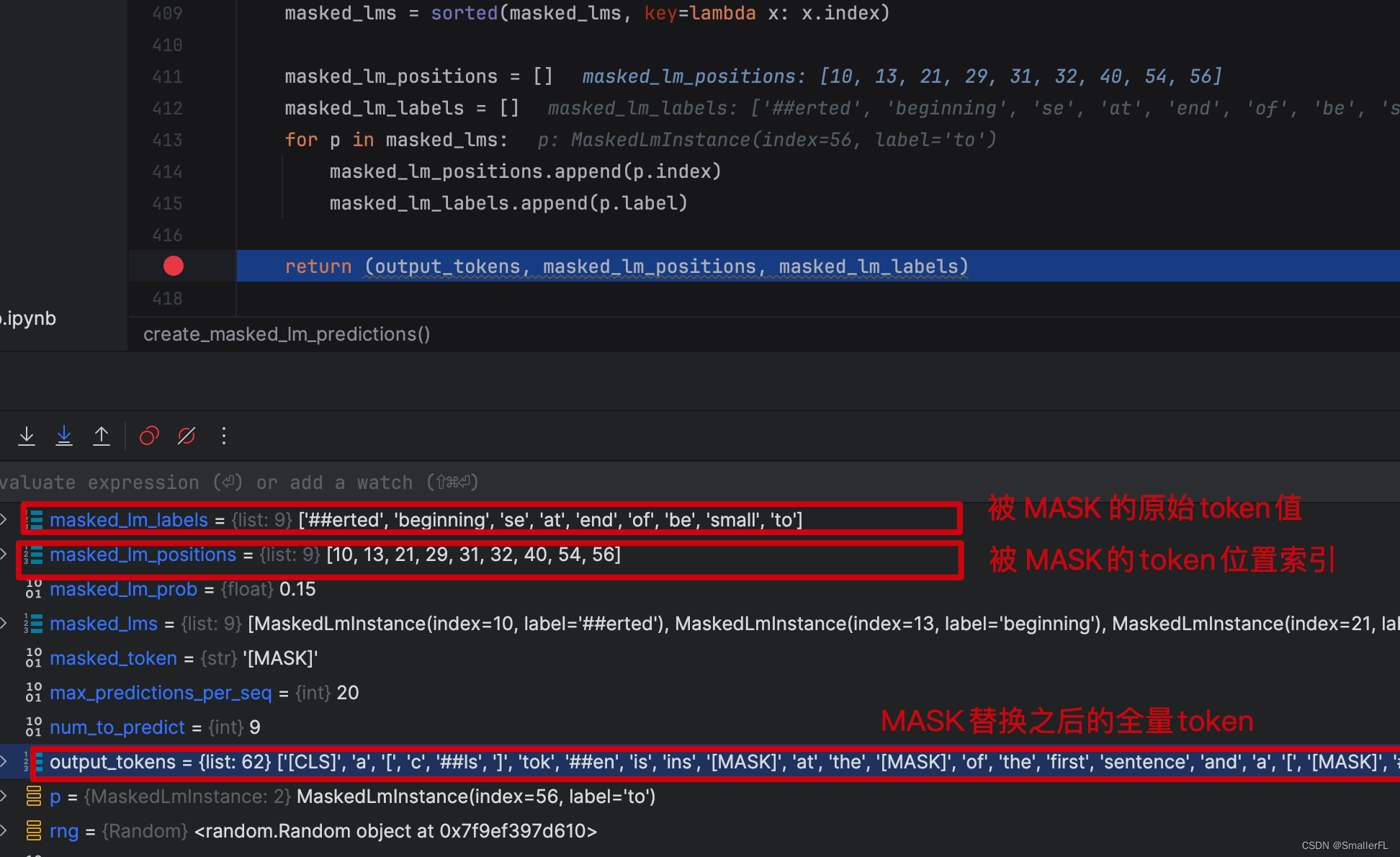
ok,到这里基本上就清楚了整体的数据准备的逻辑!
2.5 几个关键变量
我们大致跟着程序 debug 过了一遍数据准备的整体逻辑!下面总结一下输出的几个关键变量,这里面的变量有些会写入到文件里,必须深入理解其含义!
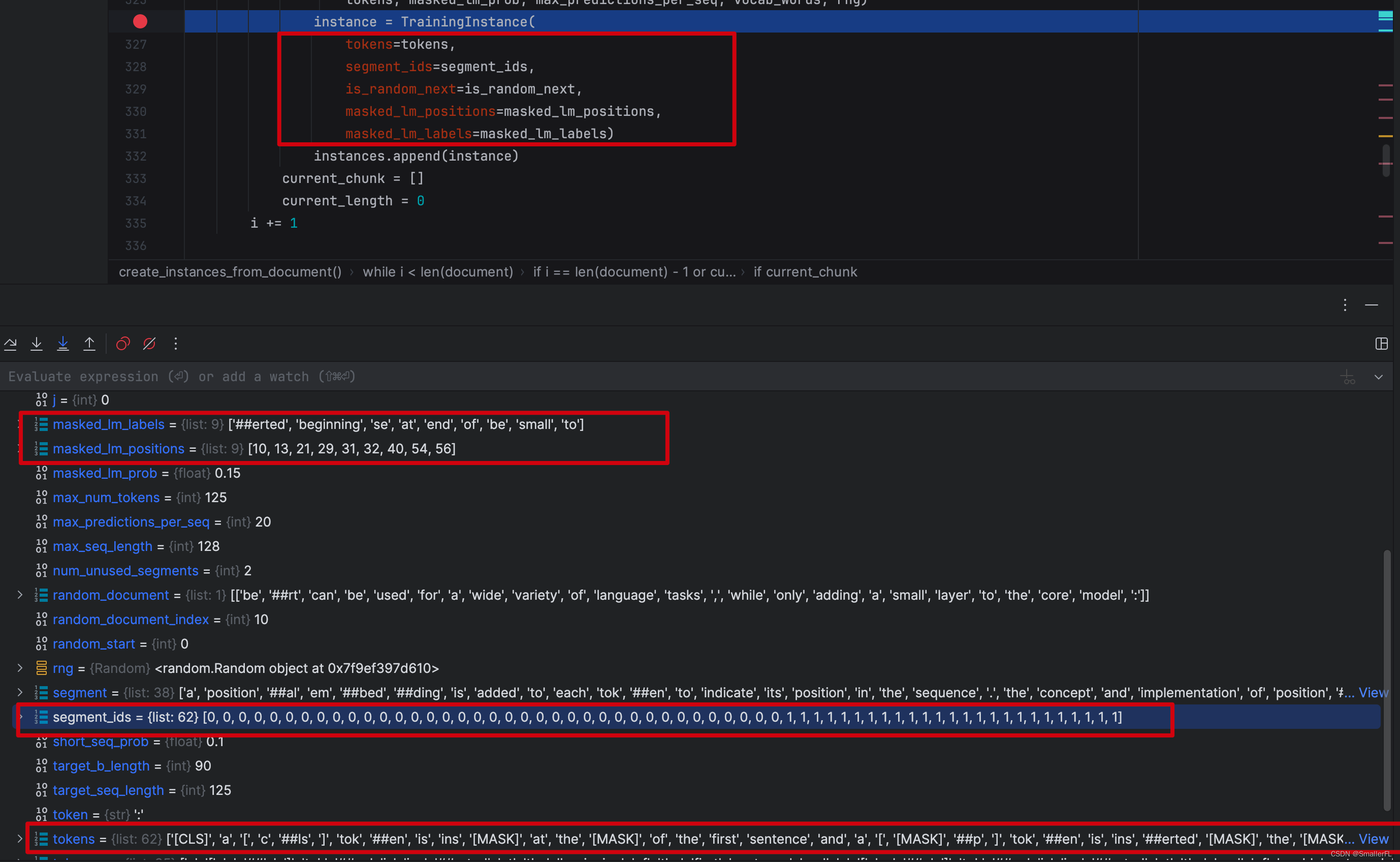
tokens: 带有[CLS]、[SEP],并且某些token已经被[MASK]的tokens列表
segment_ids: 句子A的token和句子B的token,按照0/1排列区分
is_random_next: 下一句是否随机选择的
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_labels: 被选中 MASK 的token原始值
为了方便理解还是举例:
句子 A 由以下 token 组成:
[token_a1, token_a2],并且 token_a2 选中 MASK,并且变成 [MASK]
句子 B 由以下 token 组成:
[token_b1, token_b2],并且 token_b2 选中 MASK,但是保持不变
且 B 是随机选择的,那么输出变量如下:
tokens:[[CLS],token_a1,[MASK],[SEP],token_b1,token_b2,[SEP]
segment_ids:[0,0,0,0,1,1,1]
is_random_next: True
masked_lm_positions:[2,5]
masked_lm_labels: [token_a2,token_b2]
2.6 write_instance_to_example_files
最后一步是输出到外部的文件中,这就要看 write_instance_to_example_files 函数了:
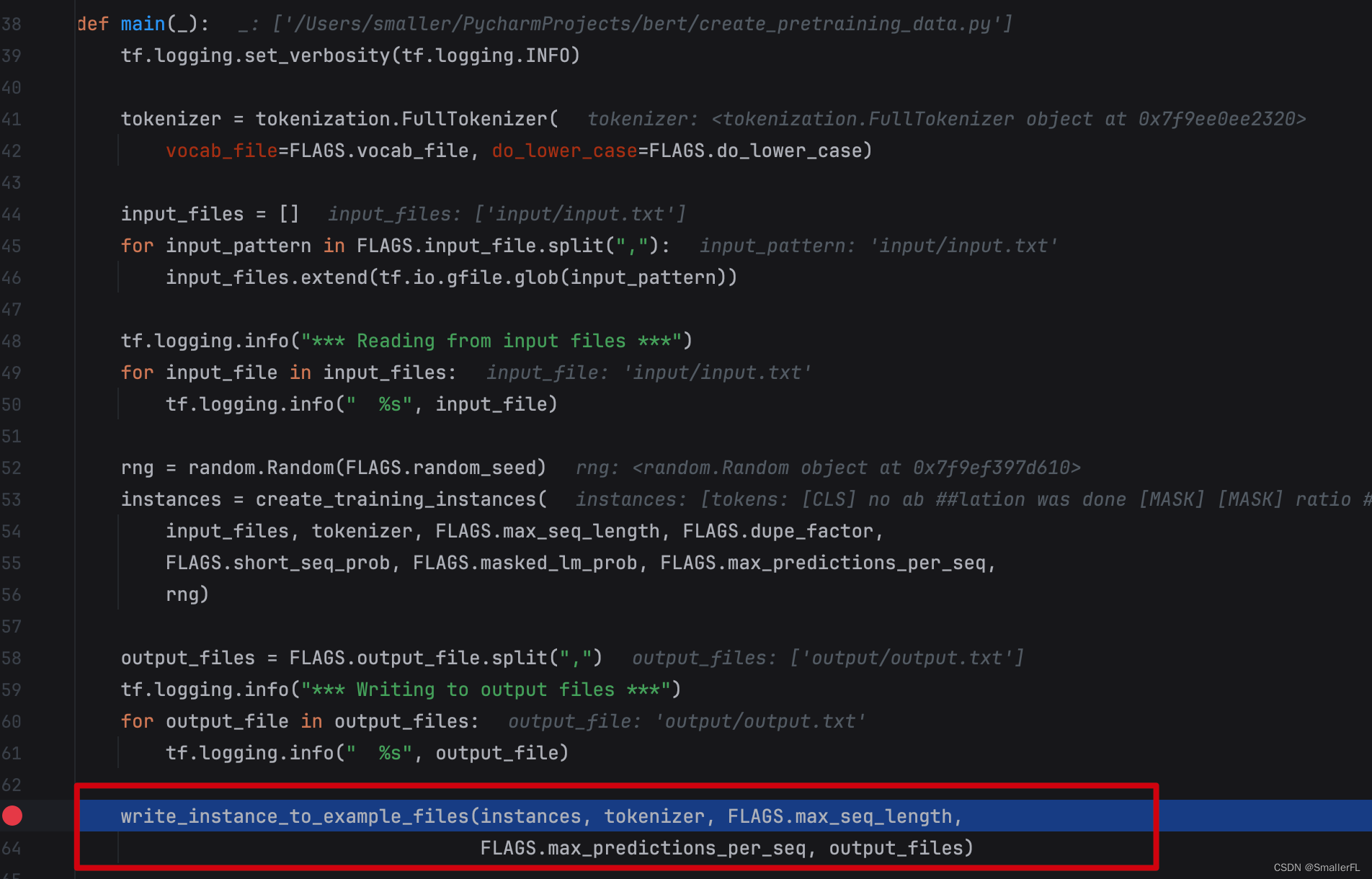
进入到其中,关键写入文件的几个变量input_ids、input_mask、segment_ids、masked_lm_positions、masked_lm_ids、masked_lm_weights、next_sentence_labels,这是后续预训练的输入参数,非常重要!
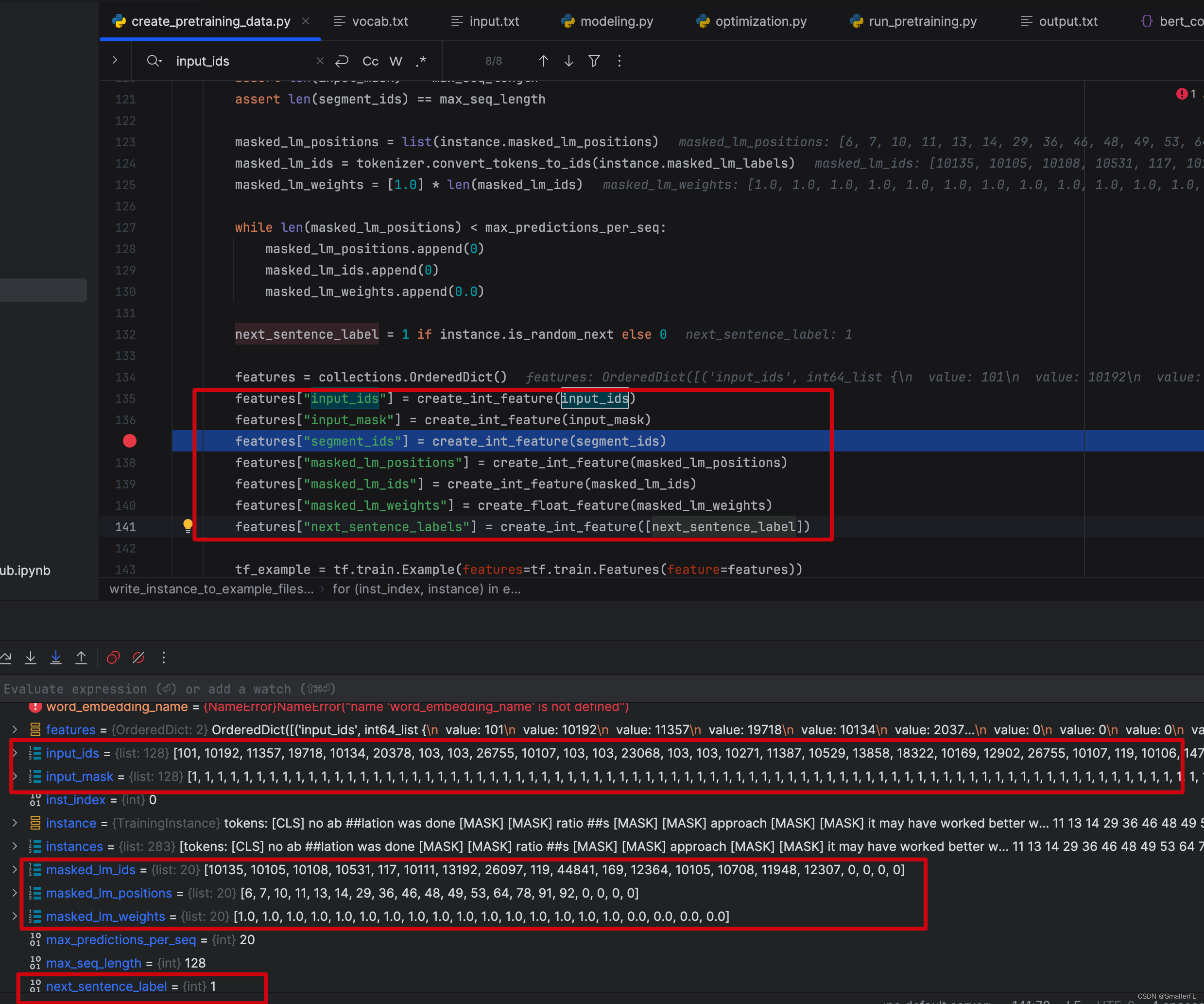
其中segment_ids、masked_lm_positions、masked_lm_ids 上文已经介绍过了。
# 以下是上一节描述的值,需要转换成输出到文件的值,贴在这里是方便对照
tokens: 带有[CLS]、[SEP],并且某些token已经被[MASK]的tokens列表
segment_ids: 句子A的token和句子B的token,按照0/1排列区分
is_random_next: 下一句是否随机选择的
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_labels: 被选中 MASK 的token原始值
# 以下是输出到文件的值,也是会作为后续预训练的输入值,重点看!
input_ids:tokens在字典的索引位置,不足max_seq_length(128)则补0
input_mask:初始化为1,不足max_seq_length(128)则补0
segment_ids: 句子A的token和句子B的token,按照0/1排列区分。不足max_seq_length(128)则补0
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_ids:被选中 MASK 的token原始值在字典的索引位置
masked_lm_weights:初始化为1
next_sentence_labels:对应is_random_next,1表示随机选择,0表示正常语序
3. 参考
《NLP深入学习:结合源码详解 BERT 模型(一)》
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
未完待续,后文将结合源码介绍 BERT 的训练过程!
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎:SmallerFL;
也欢迎关注我的wx公众号:一个比特定乾坤
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











