






文章目录
1. 前言
前情提要:
《NLP深入学习:结合源码详解 BERT 模型(一)》
《NLP深入学习:结合源码详解 BERT 模型(二)》
之前已经详细说明了 BERT 模型的主要架构和思想,并且讲解了 BERT 源代码对于数据准备的流程,回顾下关键字段的含义:
# 以下是输出到文件的值,也是会作为后续预训练的输入值,重点看!
input_ids:tokens在字典的索引位置,不足max_seq_length(128)则补0
input_mask:初始化为1,不足max_seq_length(128)则补0
segment_ids: 句子A的token和句子B的token,按照0/1排列区分。不足max_seq_length(128)则补0
masked_lm_positions: 被选中 MASK 的token位置索引
masked_lm_ids:被选中 MASK 的token原始值在字典的索引位置
masked_lm_weights:初始化为1
next_sentence_labels:对应is_random_next,1表示随机选择,0表示正常语序
下面我们结合预训练代码详细讲解下 BERT 的预训练流程。
2. 预训练
预训练代码在 run_pretraing.py 文件中,注意我们需要把数据准备的结果作为预训练的输入:
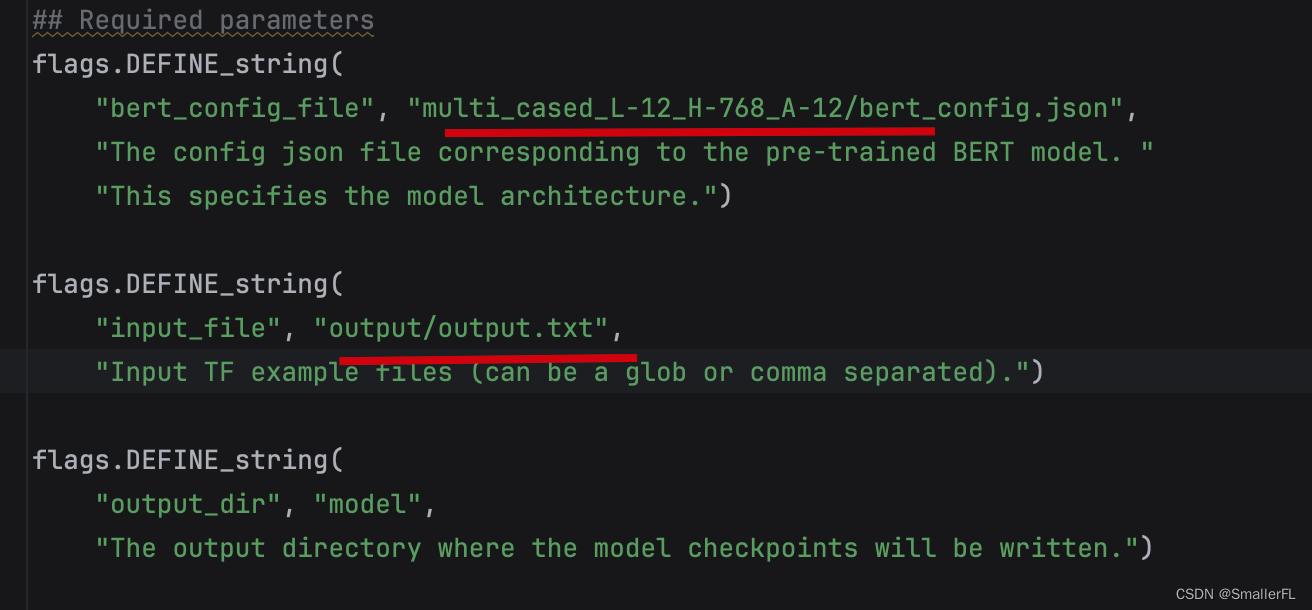
那我们打上断点,继续开启 debug 吧!
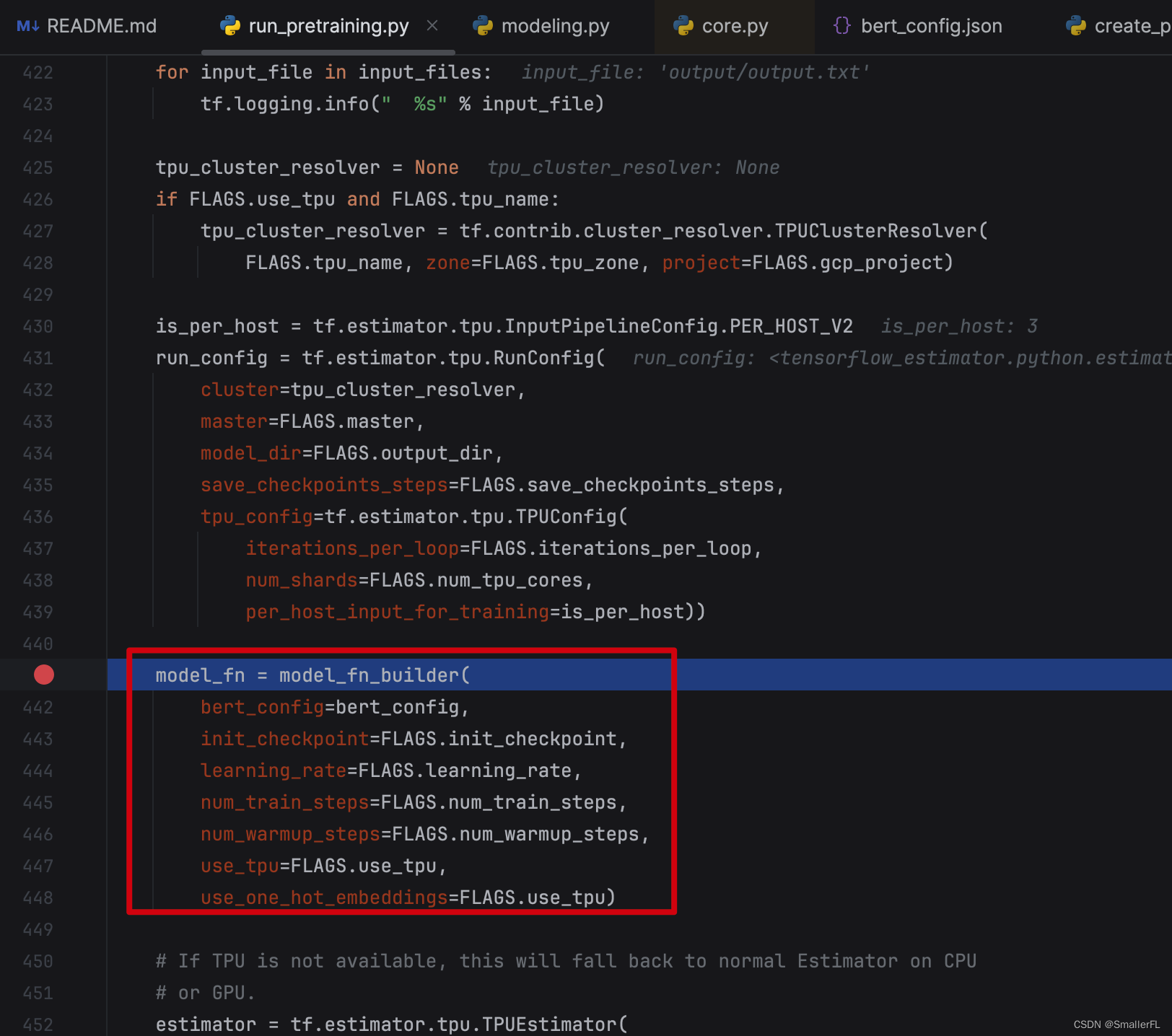
2.1 modeling.BertModel
看预训练代码,大部分的核心代码集中在 modeling.BertModel 这个 class 的 __init__ 代码中:
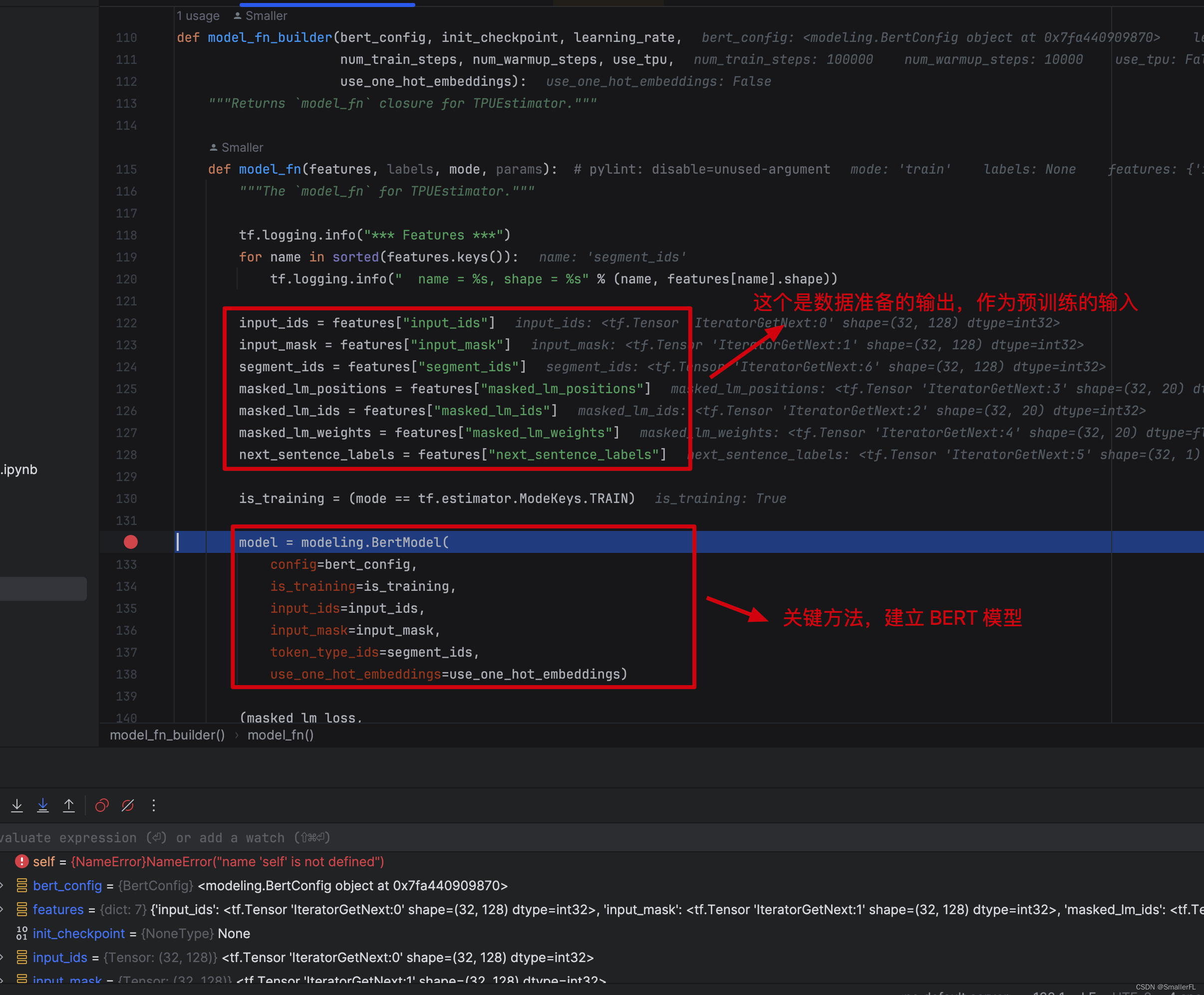
解释下 modeling.BertModel 的参数:
- config: BERT 的配置文件,后续的很多参数都来源于此。我放到路径
./multi_cased_L-12_H-768_A-12/bert_config.json,内容如下:
{
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 119547
}
- is_training:True 表示训练,False 表示评估
- input_ids:对应于数据准备的字段
input_ids,形状[batch_size, seq_length],即[32, 128] - input_mask:对应于数据准备的字段
input_mask,形状[batch_size, seq_length],即[32, 128] - token_type_ids:对应于数据准备的字段
segment_ids,形状[batch_size, seq_length],即[32, 128] - use_one_hot_embeddings:词嵌入是否用 one_hot 模式
- scope:变量的scope,用于
tf.variable_scope(scope, default_name="bert")默认是 bert
2.1.1 embedding_lookup
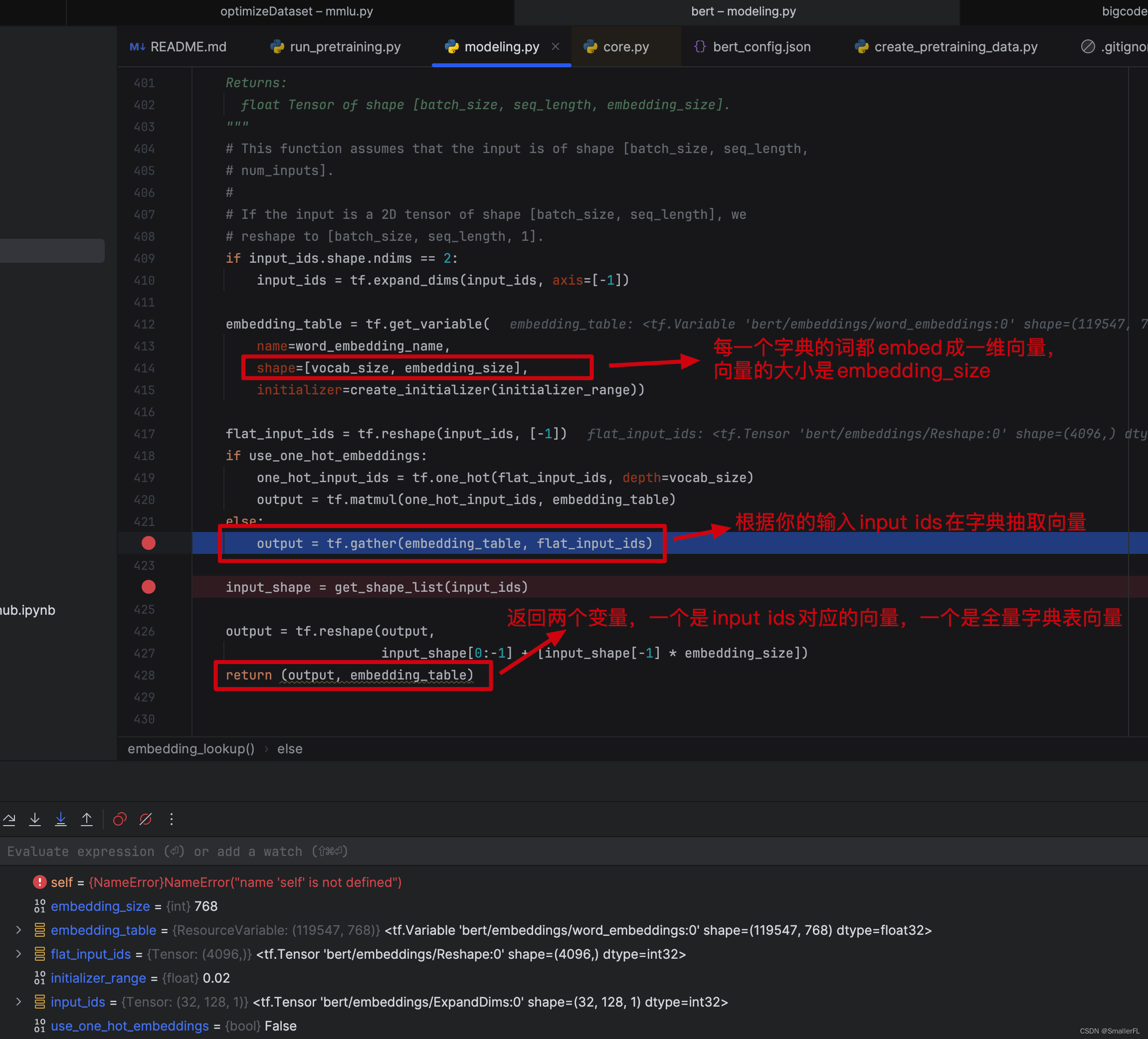
在 modeling.BertModel 的 __init__ 代码中,第一个重要的方法是 embedding_lookup:

我们看下具体的代码,返回值有两个:
out_put是根据输入的input_ids在字典中找到对应的词,并且返回词对应的 embedding 向量,out_put的形状是[batch_size, seq_length, embedding_size]embedding_table是字典每一个词对应的向量,形状是[vocab_size, embedding_size]
ps: 有些同学不清楚字典是什么?字典在项目的 ./multi_cased_L-12_H-768_A-12/vocab.txt 里,每一行对应一个词,里例如id=0则表示字典第一个对应的词[PAD],字典内容如下:
[PAD]
[unused1]
[unused2]
[unused3]
[unused4]
...
[unused99]
[UNK]
[CLS]
[SEP]
[MASK]
<S>
<T>
!
"
#
$
%
...
A
B
C
D
E
F
G
H
2.1.2 embedding_postprocessor
后续的该方法是用于加上位置编码!
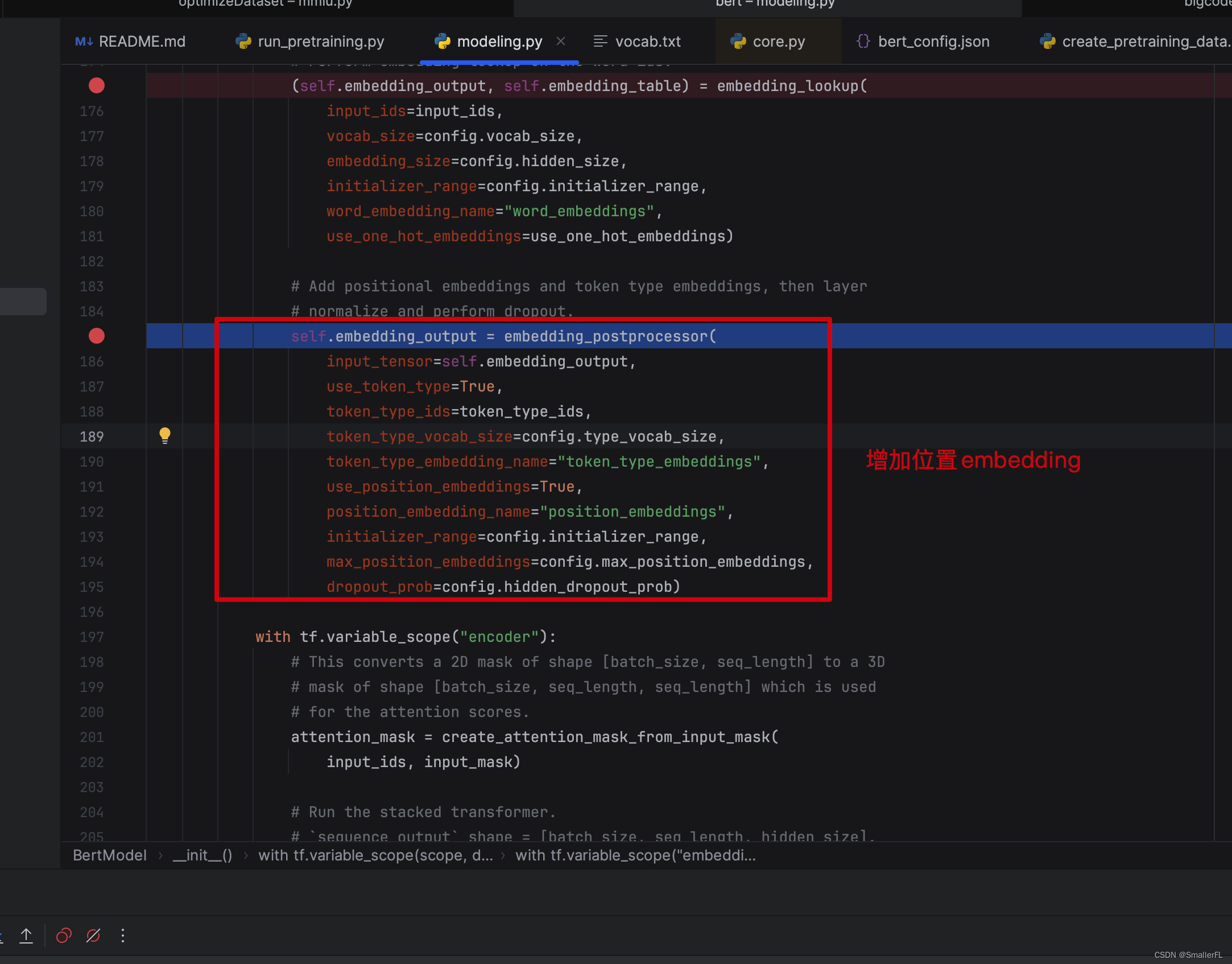
我们进到函数内部查看具体细节:
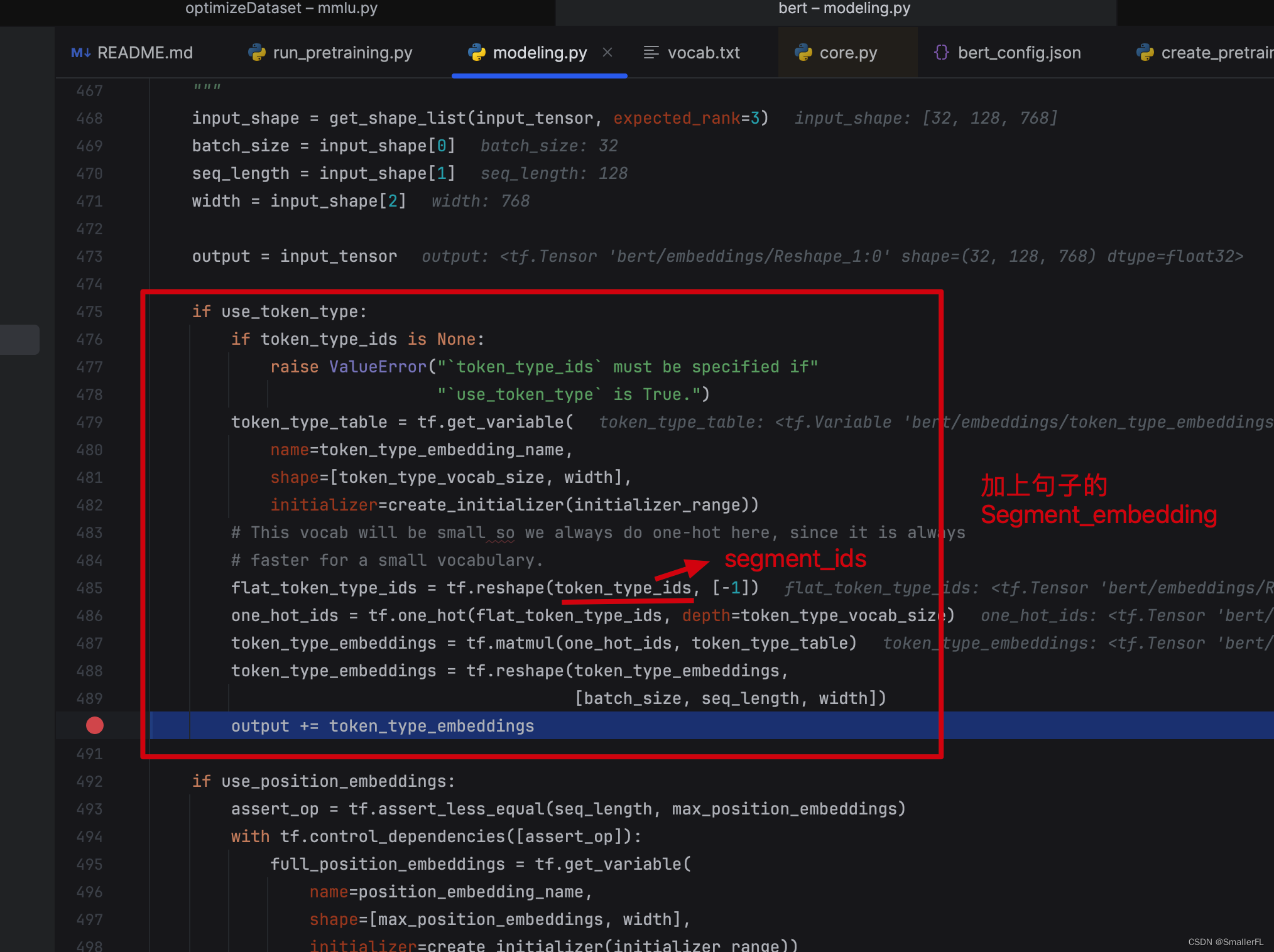
上面代码中,token_type_ids 对应的是 segment_ids,即句子的表示(用0/1来表示),细节见《NLP深入学习:结合源码详解 BERT 模型(二)》 的 2.3章节。token_type_table 和上一节的 embedding_table 是一样的含义,这里就是向量化 segment_ids。由于 segment_ids 只用 0和1来表示,所以token_type_vocab_size=2,并且最终将 out_put 加上了 segment_ids 向量化的结果,就是图中的 TokenEmbeddings + SegmentEmbeddings
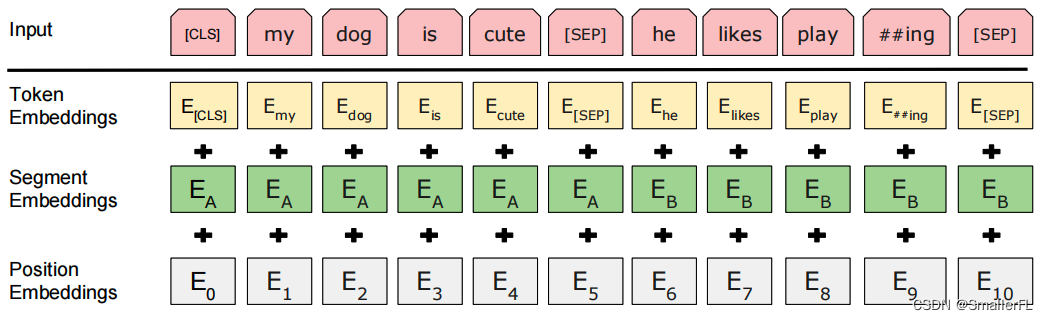
那么显而易见,下一段代码就是再加上 PositionEmbeddings 了!
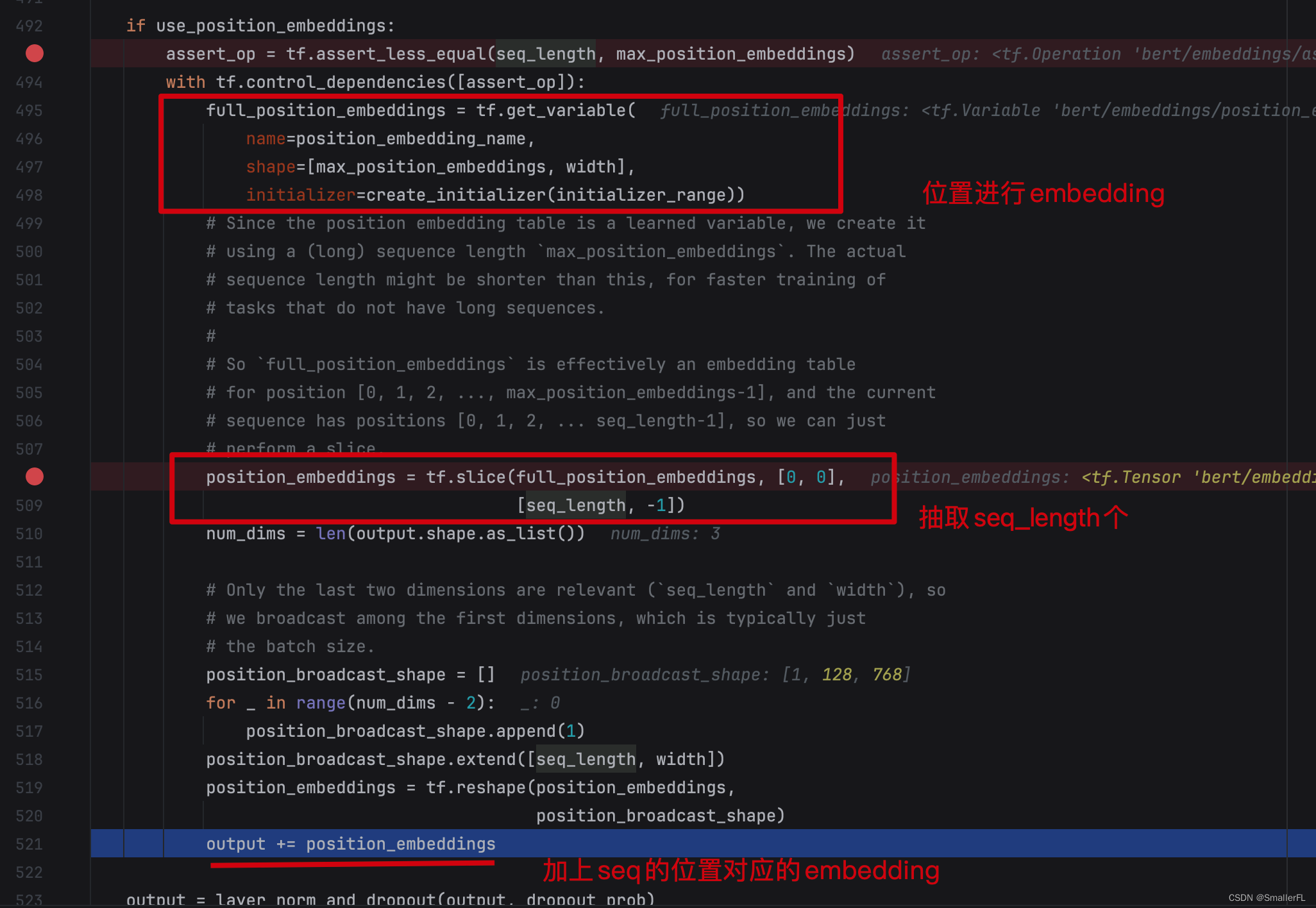
注意,这里的 position_embeddings 实际就是词在句子中的位置对应的 embedding~
最后将输出加上了 layer_norm_and_dropout ,即层归一和dropout。
2.1.3 transformer_model
顺着代码debug下去,在准备好了数据之后,就是经典的 Transformer 模型了:
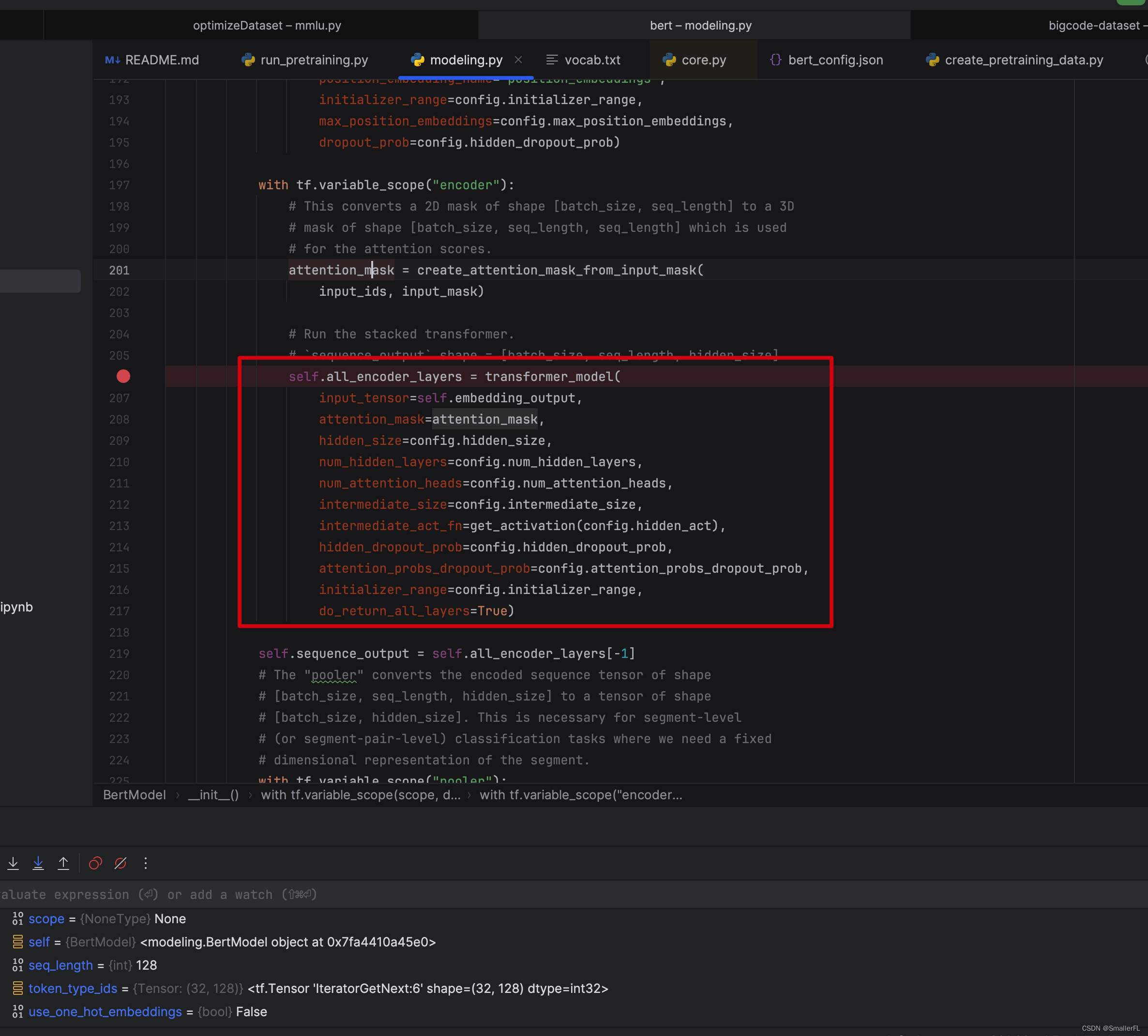
希望深入了解 Transformer 的,建议参考:
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
我们先回忆下 Transformer 的结构,因为下面的代码完全是对论文的编码器实现:
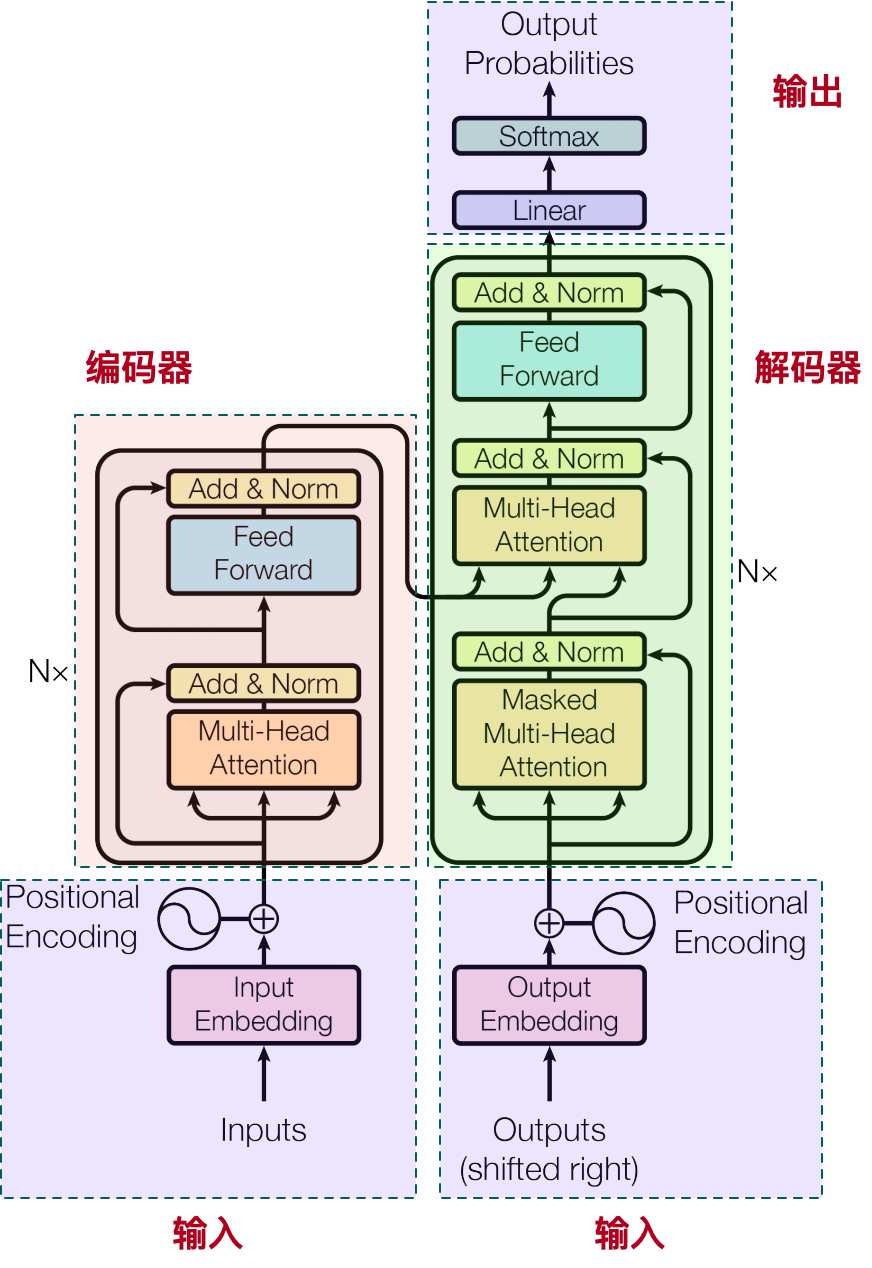
为了方便查看,我把代码的结构和论文的结构对比在一起:
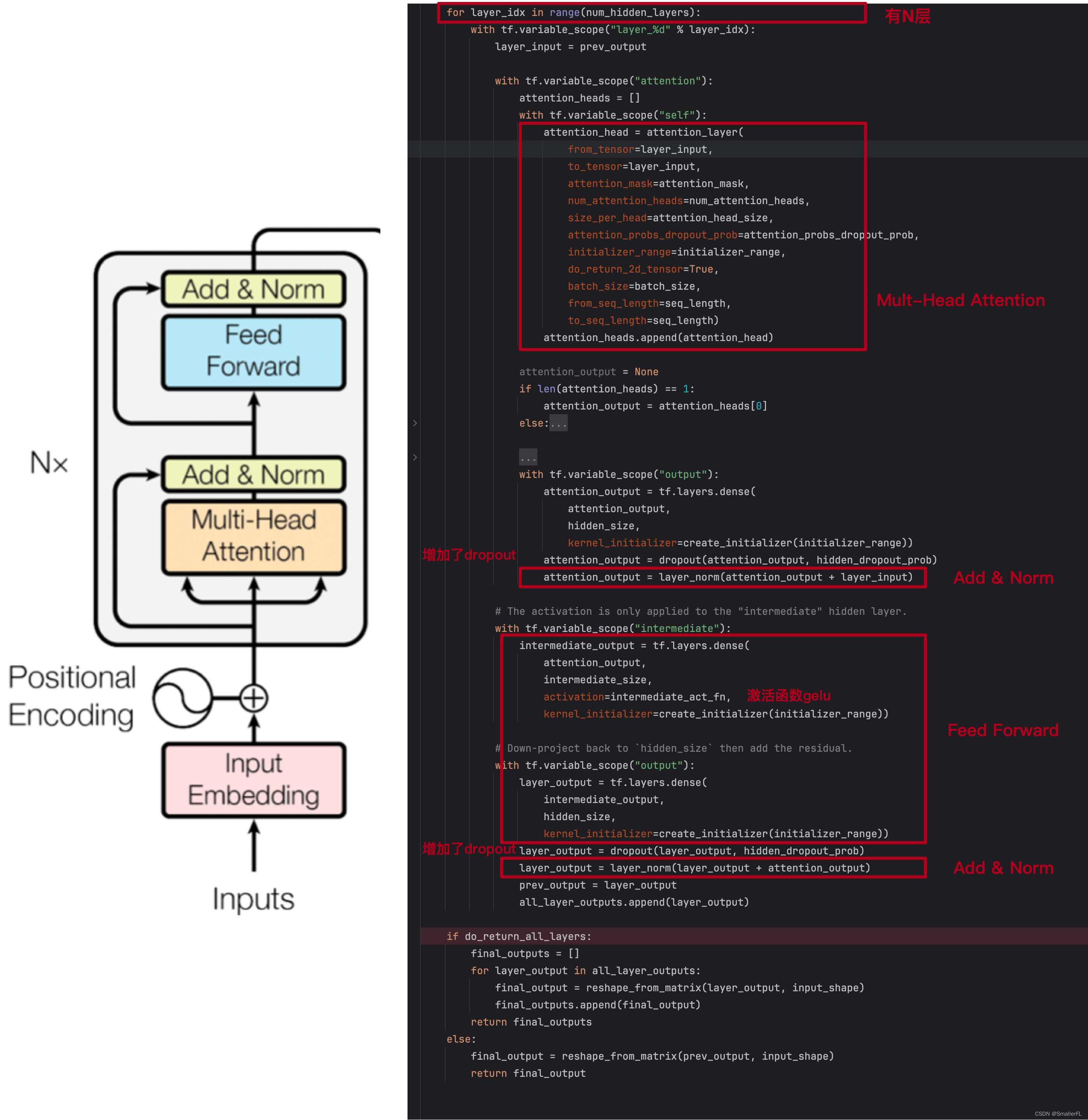
transformer 结构构建完成之后,下面的self.sequence_out 是把最后一层的输出作为 transformer 的 encoding 结果输出。
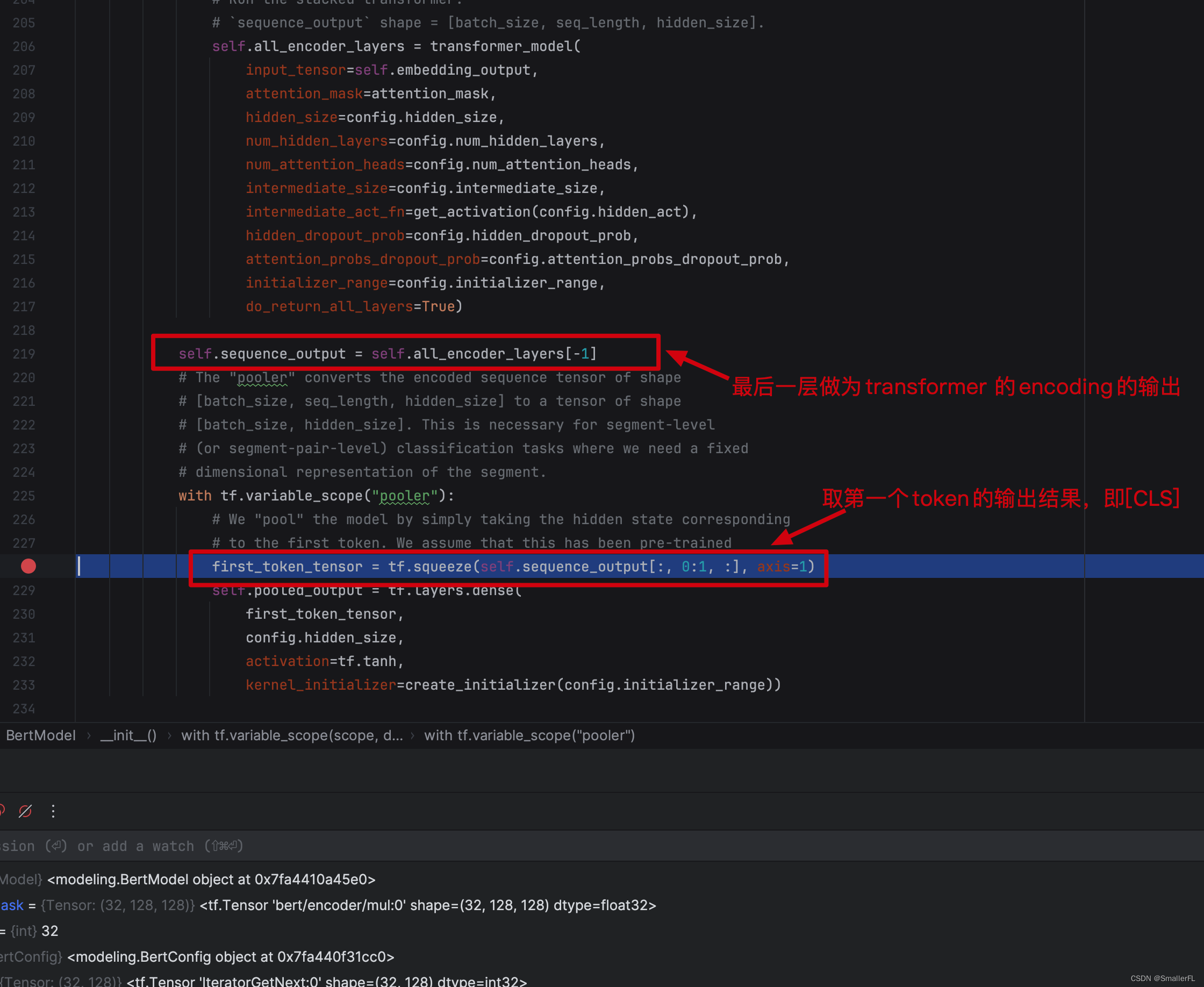
此外,first_token_tensor 是取第一个 token 的输出结果,即 [CLS] 的结果。因为 [CLS] 已经带有上下文信息了,因此对于分类而言,用 [CLS] 的输出即可。这个论文中也有说明:
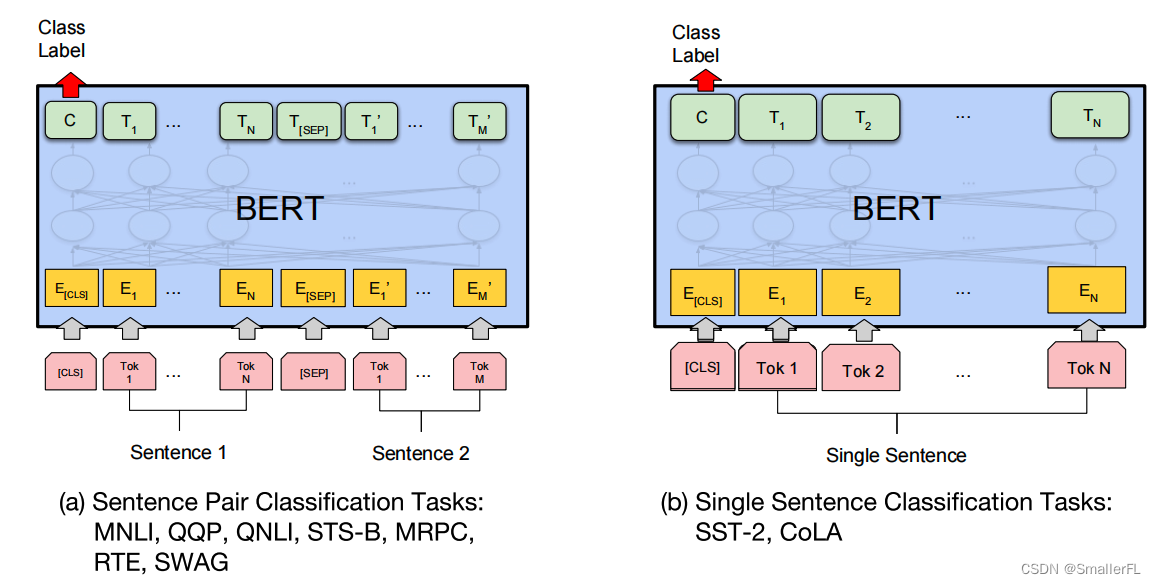
以上就是 BERT 模型的构建整体流程,下面来看 BERT 模型的评估流程,包含 Masked Language Model(MLM)和 Next Sentence Prediction(NSP)。
2.2 get_masked_lm_output
先来看 Masked Language Model(MLM)的评估,对应代码中的 get_masked_lm_out ,见下图:
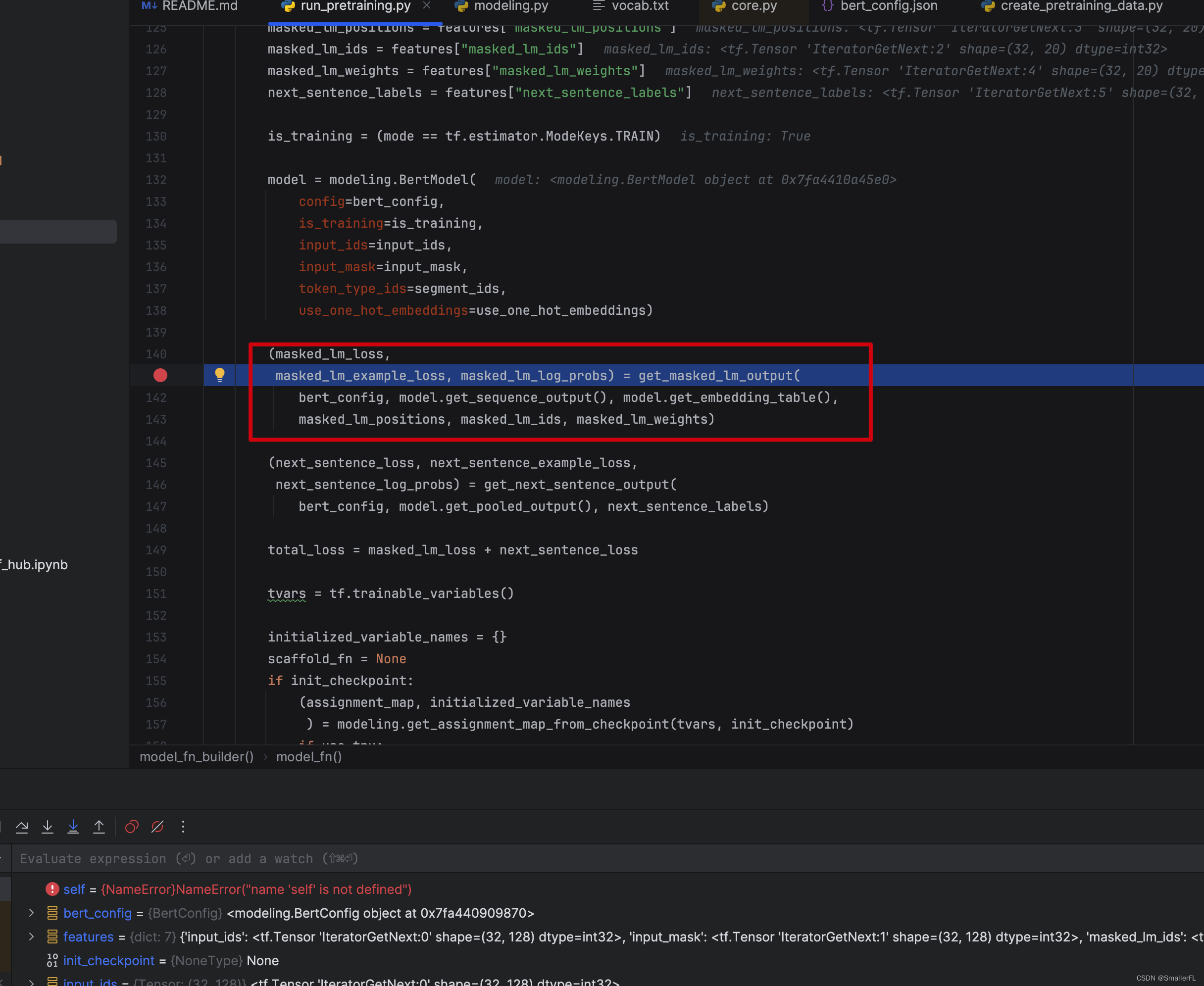
首先看下 get_masked_lm_out 的输入参数:
bert_config: BERT 的配置文件,对应我的路径./multi_cased_L-12_H-768_A-12/bert_config.jsoninput_tensor:BERT 模型的输出,即上文的self.sequence_outoutput_weights:对应上文embedding_lookup的第二个输出,即字典每一个词对应的向量,形状是[vocab_size, embedding_size]positions:对应features["masked_lm_positions"],即被选中 MASK 的 token 位置索引label_ids:对应features["masked_lm_ids"],即被选中 MASK 的 token 原始值在字典的索引位置label_weights:对应features["masked_lm_weights"]
下面是整体的代码,代码有些地方需要细细品味:
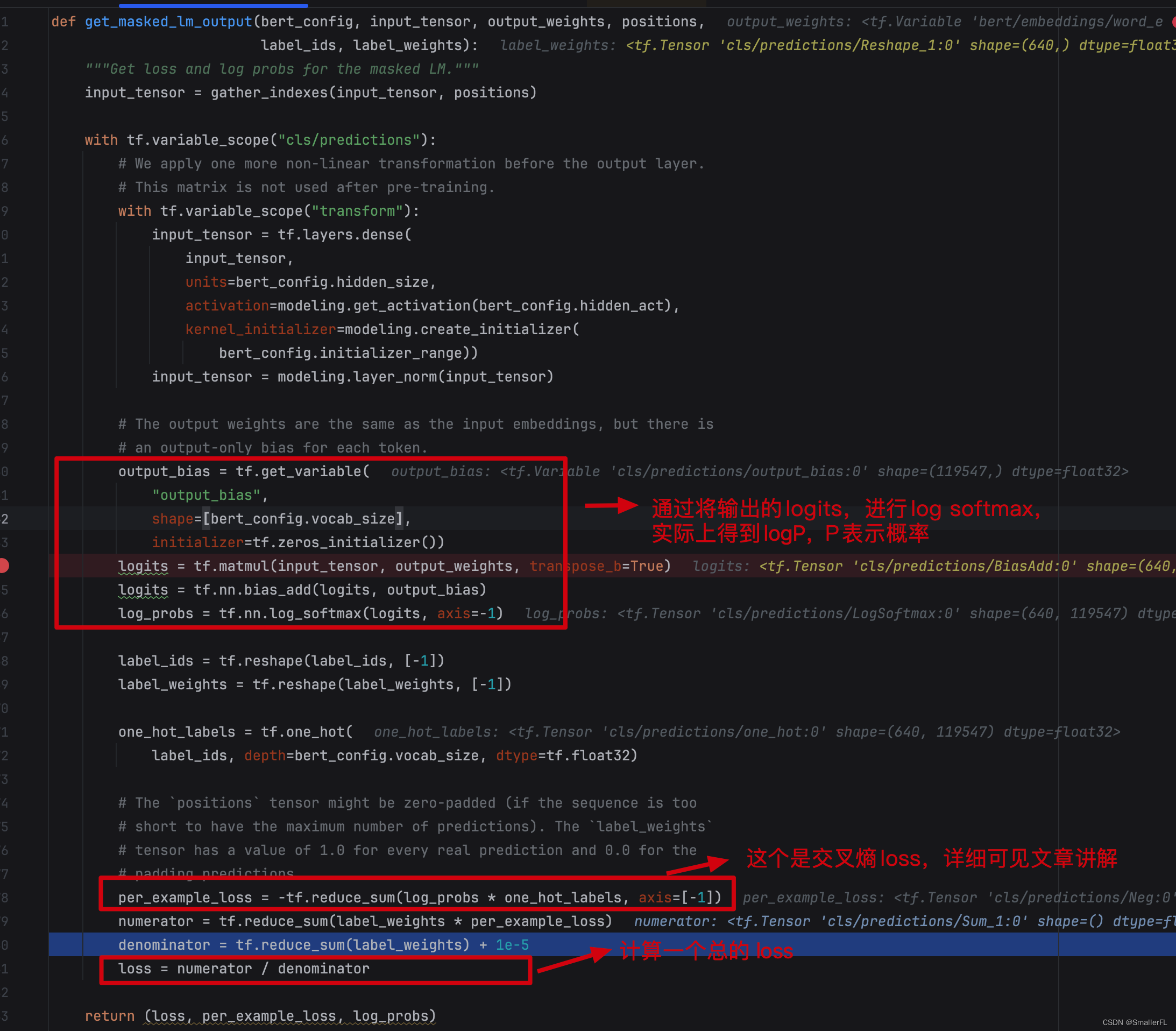
要看懂这里的代码,首先我们要知道 BERT 在 Masked Language Model(MLM)上要干啥。BERT 首先给句子的词打上了 [MASK] ,后续就要对 [MASK] 的词进行预测。预测,就是在词典中出现的词给出一个概率,看属于哪个词,本质上就是多分类问题。那么对于多分类问题,通常的做法是计算交叉熵。
这里就不详细阐述交叉熵的来龙去脉了,直接说明交叉熵如何计算。我们假设真实分布为 y,而模型输出分布为
y
^
\widehat{y}
y
,总的类别数为 n,交叉熵损失函数的计算方法为:
l
o
s
s
=
∑
i
=
1
n
[
−
y
l
o
g
y
^
i
−
(
1
−
y
)
l
o
g
(
1
−
y
^
i
)
]
loss = \sum_{i=1}^{n}[-ylog\widehat{y}_i-(1-y)log(1-\widehat{y}_i)]
loss=i=1∑n[−ylogy
i−(1−y)log(1−y
i)]
好,我们来看代码中关键的几个步骤:
-
log_probs = tf.nn.log_softmax(logits, axis=-1),这个方法实际上计算的是:
l o g _ p r o b s = [ l o g y ^ 1 , l o g y ^ 2 , . . . , l o g y ^ n ] log\_probs = [log\widehat{y}_1, log\widehat{y}_2,...,log\widehat{y}_n] log_probs=[logy 1,logy 2,...,logy n]
其中 l o g y ^ i log\widehat{y}_i logy i 表达的是属于词典第 i 个词的概率的对数值。 -
one_hot_labels = tf.one_hot(label_ids, depth=bert_config.vocab_size, dtype=tf.float32),计算每个词的在字典的 one_hot 结果,形状是[batch_size*seq_len, vocab_size]。例如,“animal” 在字典第18883位置,那么"animal"对应的 one_hot 就是 [0,0,…0,1,0,…,0],其中向量长度就是字典的大小,1排在向量的18883个。 -
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1]),这个方法是用于交叉熵的。因为我们知道真实的分布情况,就是one_hot_labels对应的结果,那么对于某一个具体的词,其交叉熵的计算就是 − y l o g y ^ i − ( 1 − y ) l o g ( 1 − y ^ i ) -ylog\widehat{y}_i-(1-y)log(1-\widehat{y}_i) −ylogy i−(1−y)log(1−y i),将 y=1(即事先知道一定属于某个词)代入,即交叉熵为 − l o g y ^ i -log\widehat{y}_i −logy i。所以事先计算了log_probs,per_example_loss可以直接得到每个词的交叉熵的结果。 -
loss将per_example_loss得到的结果赋予权重进行加权平均,得到一个最终的 loss,实际上就相当于 l o s s = ∑ i = 1 n w i [ − y l o g y ^ i − ( 1 − y ) l o g ( 1 − y ^ i ) ] loss = \sum_{i=1}^{n}w_i[-ylog\widehat{y}_i-(1-y)log(1-\widehat{y}_i)] loss=∑i=1nwi[−ylogy i−(1−y)log(1−y i)]
2.3 get_next_sentence_output
再来看 Next Sentence Prediction(NSP)评估,预测句子的下一句:
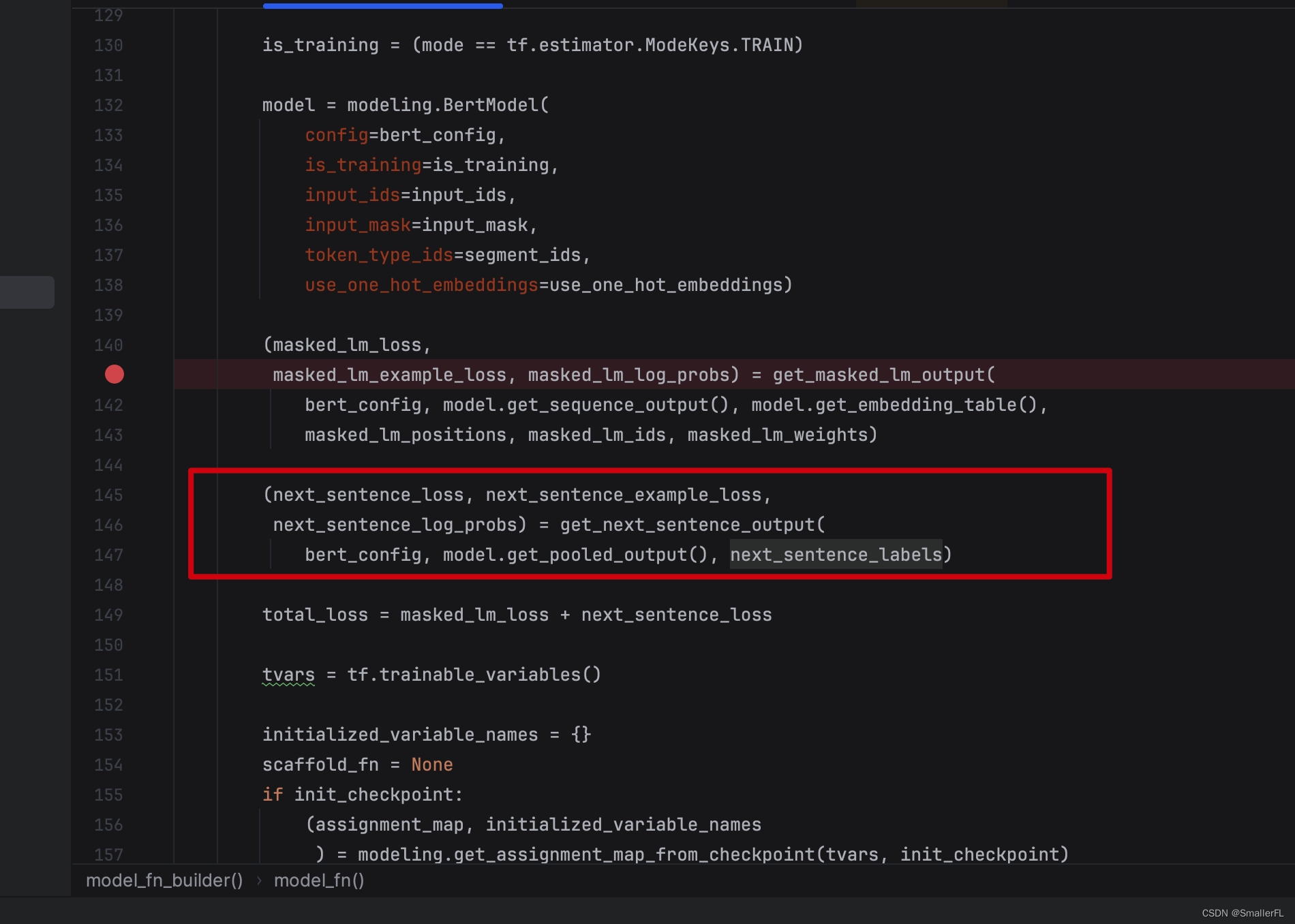
首先看下 get_next_sentence_output 的输入参数:
bert_config: BERT 的配置文件,对应我的路径./multi_cased_L-12_H-768_A-12/bert_config.jsoninput_tensor:[CLS]的输出线性变换后的结果,简单理解为[CLS]的输出作为当前函数的输入labels:对应features["next_sentence_labels"],1表示下一个句子是随机选择的,0表示正常语序
由于下一个句子只有两种选择,要么是随机的,要么是原先正常的句子,所以其实就是一个二分类问题:
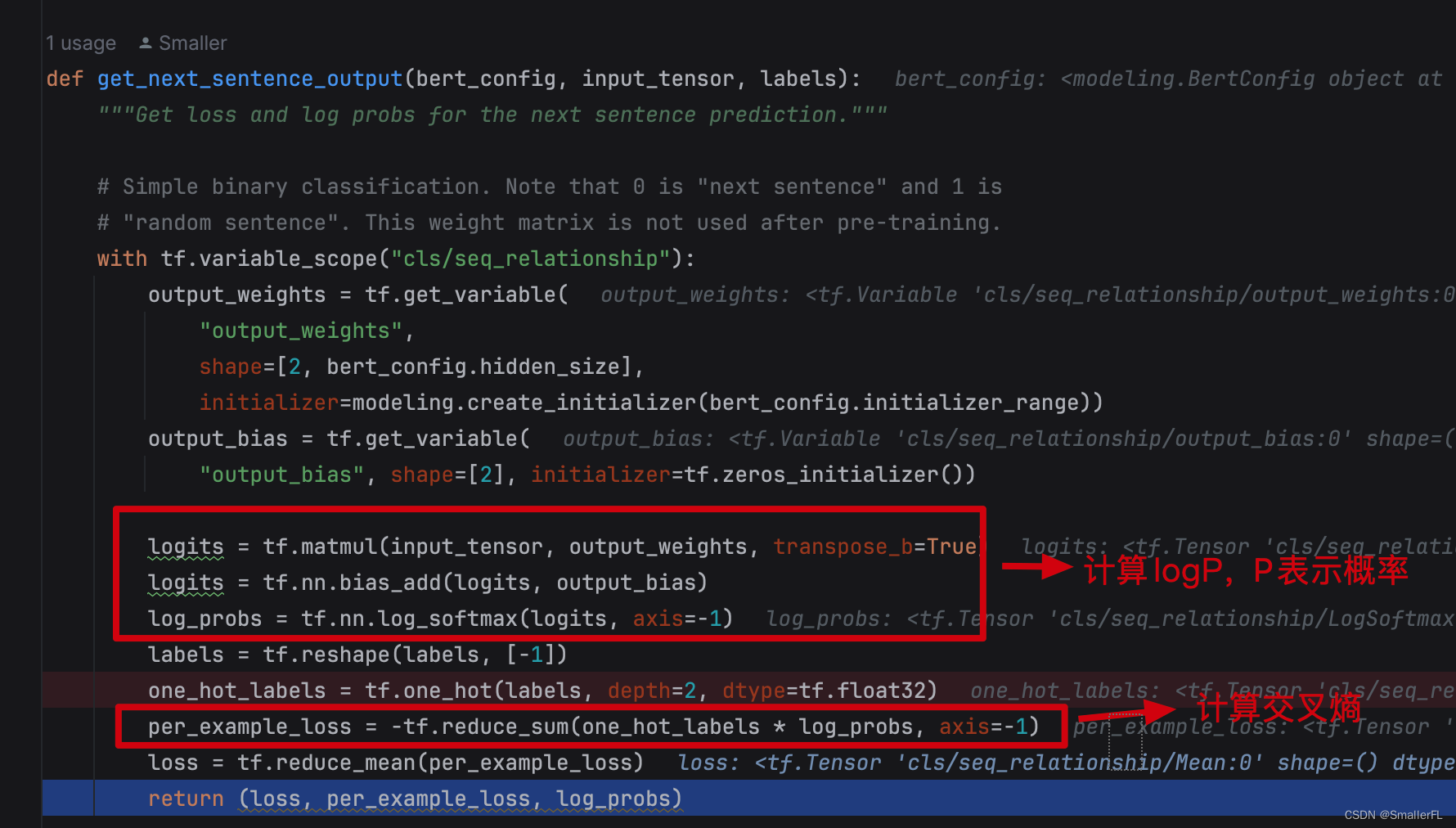
二分类的交叉熵:
l
o
s
s
=
∑
i
=
1
n
−
y
l
o
g
y
^
i
loss = \sum_{i=1}^{n}-ylog\widehat{y}_i
loss=i=1∑n−ylogy
i
上面的核心逻辑跟 get_masked_lm_output 一模一样。只不过这里的 loss 用的是平均值,没有用加权平均
2.4 训练
计算了 masked_lm_loss 以及 next_sentence_loss 之后,将两种 loss 相加,即是总的 loss
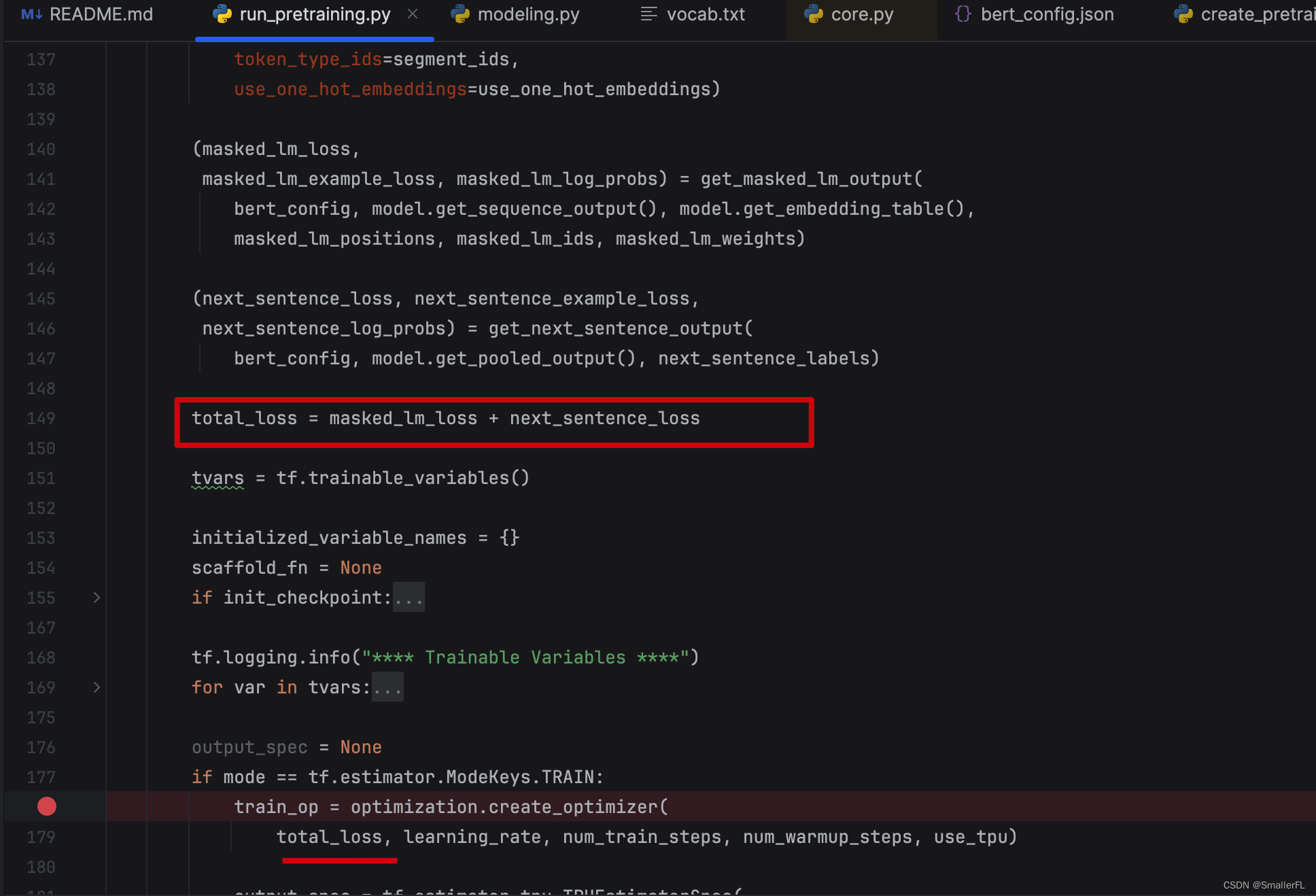
后续就训练模型降低 loss
3. 参考
《NLP深入学习:结合源码详解 BERT 模型(一)》
《NLP深入学习:结合源码详解 BERT 模型(二)》
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎:SmallerFL;
也欢迎关注我的wx公众号:一个比特定乾坤
















 7843
7843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











