







1. 概览
ALBERT,来源于2020年论文 《ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》,提出了 ALBERT(A Lite BERT),一种用于自监督学习的语言表示模型。ALBERT 通过两种参数减少技术降低了 BERT 模型的内存消耗并提高了训练速度,同时引入了句子顺序预测(SOP)的自监督损失,专注于建模句子间的连贯性。
论文:https://openreview.net/pdf?id=H1eA7AEtvS
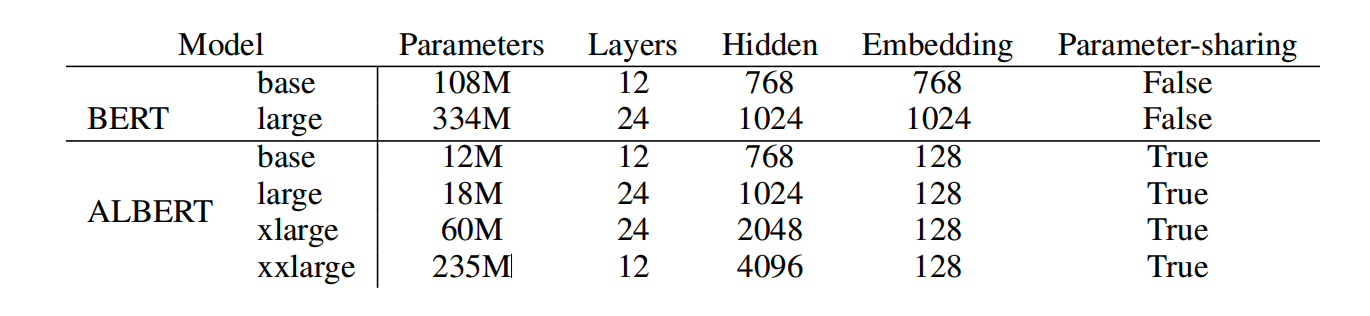
参数对比:
BERT 详细介绍看这里:
《NLP深入学习:结合源码详解 BERT 模型(一)》
《NLP深入学习:结合源码详解 BERT 模型(二)》
《NLP深入学习:结合源码详解 BERT 模型(三)》
下面介绍改进点。
2. 因子化嵌入参数化
因子化嵌入参数化(Factorized Embedding Parameterization)。
在 BERT 模型中,词汇嵌入(WordPiece embeddings)的大小与隐藏层(hidden layer)的大小是相等的,即
E
≡
H
E \equiv H
E≡H。这种设计在建模和实际应用中存在一些局限性:
-
建模角度: 词汇嵌入旨在学习上下文无关的表示,而隐藏层嵌入旨在学习上下文相关的表示。BERT 的强大之处在于利用上下文信息来学习这些上下文相关的表示。因此,将词汇嵌入大小 E E E 与隐藏层大小 H H H 分离,可以更高效地利用模型参数,因为通常 H H H 远大于 E E E。
-
实际应用角度: 自然语言处理通常需要较大的词汇表。如果 E ≡ H E \equiv H E≡H,那么增加 H H H 会增加嵌入矩阵的大小,从而导致模型参数数量急剧增加,这在训练时会导致内存消耗过大。
为了解决这些问题,ALBERT 采用了因子化嵌入参数化技术:
- 将嵌入参数分解为两个较小的矩阵。ALBERT 不是直接将 one-hot 向量投影到大小为 H H H 的隐藏空间,而是首先将它们投影到一个较低维度的嵌入空间(大小为 E E E),然后再投影到隐藏空间。
- 通过这种分解,嵌入参数从 O ( V × H ) O(V \times H) O(V×H) 减少到 O ( V × E + E × H ) O(V \times E + E \times H) O(V×E+E×H),当 H H H 远大于 E E E 时,这种参数减少是显著的。
3. 跨层参数共享
在 ALBERT 模型中,为了进一步提高参数效率并减少模型大小,采用了跨层参数共享(Cross-Layer Parameter Sharing) 技术。这种技术的核心思想是在模型的所有层之间共享相同的参数集,而不是为每一层独立学习一组参数。具体来说,ALBERT 在所有层之间共享以下参数:
-
自注意力层(Self-Attention Layers):在所有层之间共享自注意力机制的参数,包括 q(query)、k(key)、v(value)矩阵以及注意力输出的线性变换矩阵。
-
前馈网络(Feed-Forward Networks, FFN):在所有层之间共享前馈网络的权重矩阵和偏置项。这意味着每一层的前馈网络使用相同的参数集。
这种跨层参数共享策略有几个优势:
-
减少参数数量:通过在所有层之间共享参数,ALBERT 显著减少了模型的总参数数量。一个具有24层的 ALBERT-large 模型,其参数数量远少于具有相同层数的 BERT-large 模型。
-
提高训练效率:由于参数数量的减少, ALBERT 在训练时需要更新的参数更少,这不仅减少了内存占用,还加快了训练速度。
-
稳定训练过程:跨层参数共享作为一种正则化形式,有助于稳定训练过程,因为它减少了过拟合的风险。此外,参数的共享使得模型在不同层之间保持了一致性,这有助于模型更好地泛化。
-
保持表示质量:尽管参数数量减少,但 ALBERT 通过跨层参数共享仍然能够学习到高质量的表示。实验结果表明,ALBERT在多个下游任务上取得了与BERT相当甚至更好的性能。
在 ALBERT 中,跨层参数共享的实现方式是将每一层的参数设置为相同,并在整个网络中重复使用这些参数。这种设计允许模型在保持参数数量可控的同时,捕获不同层次的特征表示,从而在各种自然语言理解任务中取得了优异的性能。
4. 句子顺序预测
在 ALBERT 模型中,除了传统的遮蔽语言模型(Masked Language Modeling, MLM)损失外,还引入了一种新的自监督损失,即句子顺序预测(Sentence Order Prediction, SOP) 损失。这种损失专注于建模句子间的连贯性,与 BERT 中的下一个句子预测(Next Sentence Prediction, NSP)损失相比,SOP 损失更专注于句子间的逻辑和语义连贯性。
-
改进句子间关系的理解:在许多自然语言处理任务中,理解句子间的逻辑和语义关系至关重要。SOP 损失通过预测两个连续文本片段的顺序,迫使模型学习句子间的连贯性。
-
解决 NSP 的局限性:BERT 中的 NSP 损失旨在预测两个句子是否在原始文本中连续出现。然而,后续研究表明 NSP 的预测效果不稳定,且其任务难度相对较低。SOP 损失通过专注于句子间的连贯性,提高了任务的难度和实用性。
SOP 损失的实现方式如下:
-
正例:使用与 BERT 相同的技巧,即从训练语料中选取连续的两个文本片段作为正例。
-
负例:将这两个连续的文本片段顺序颠倒,作为负例。这种设计迫使模型学习区分不同顺序下的文本片段,从而更好地捕捉句子间的连贯性。
-
损失计算:模型需要预测给定的两个文本片段的原始顺序。这可以通过一个二分类任务来实现,其中模型需要判断两个文本片段的顺序是否正确。
参考
[1] https://openreview.net/pdf?id=H1eA7AEtvS
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤



















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











