







文章目录
1. 前言
近年来,大语言模型(LLM)在通用人工智能(AGI)领域的进展令人瞩目,但如何有效提升模型的复杂推理能力仍是核心挑战。传统方法多依赖监督微调(SFT)或人工标注数据,而 DeepSeek 团队在《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》一文中提出了一种全新的技术路径——基于纯强化学习(RL)的推理。
本文提出的 DeepSeek-R1 系列模型包含两个核心版本:
- DeepSeek-R1-Zero:完全通过大规模 RL 训练(无SFT阶段)直接优化基座模型,自主涌现出反思、验证等推理行为;
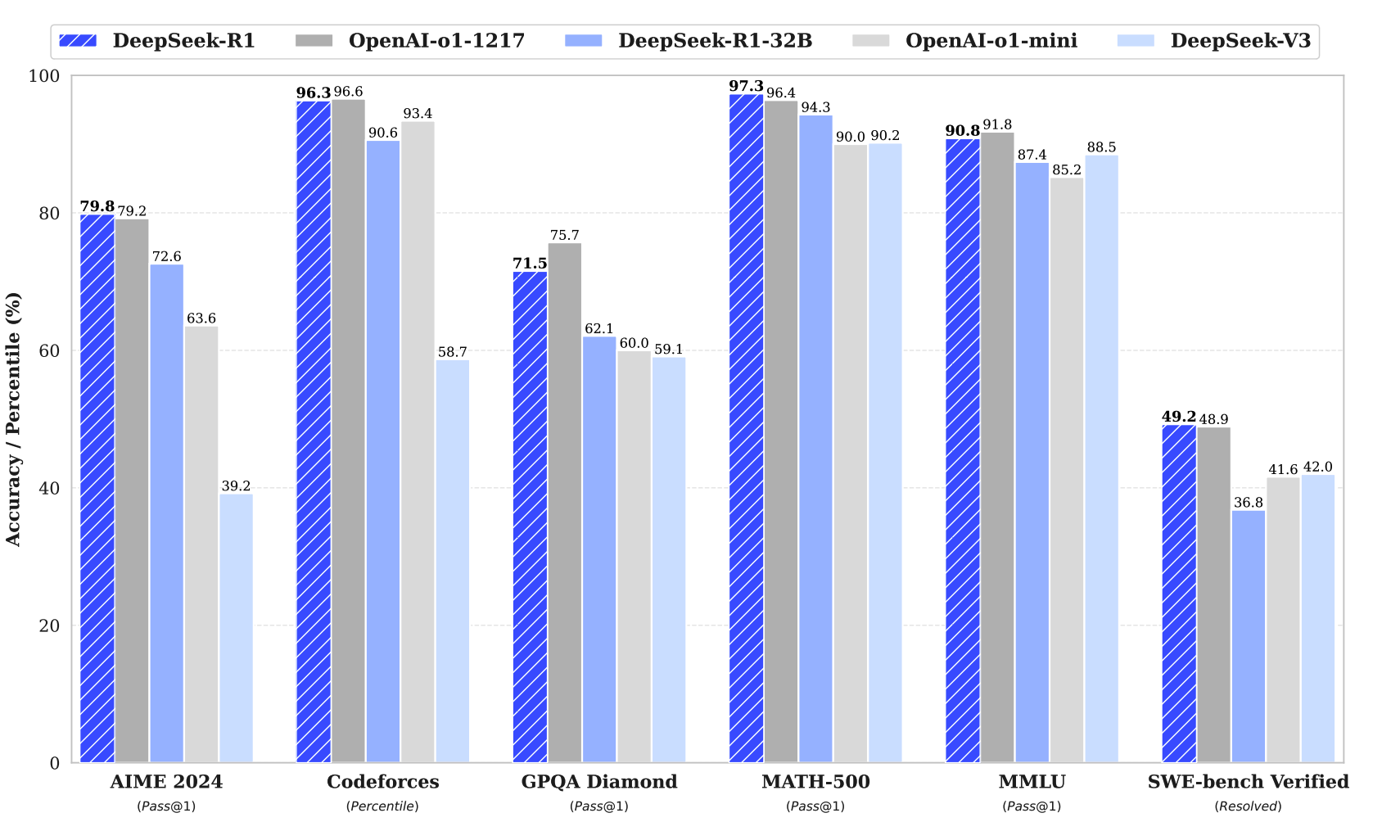
- DeepSeek-R1:在冷启动数据基础上结合多阶段训练,显著提升可读性与推理性能,最终达到与 OpenAI-o1-1217 匹敌的水平。
2. 核心流程
2.1 DeepSeek-R1-Zero:纯强化学习驱动的自进化
DeepSeek-R1-Zero 以 DeepSeek-V3-Base 为基座,采用 GRPO(Group Relative Policy Optimization)算法进行训练,其核心创新在于完全摒弃监督微调阶段,仅通过 RL 激励模型自主探索推理路径。
2.1.1 关键设计
(1)奖励系统
- 准确性奖励(Rule-based):通过规则验证数学答案正确性或代码编译结果;
- 格式奖励:强制模型在
<think>和<answer>标签内输出推理过程与答案。
(2)训练模板
- 为了训练 DeepSeek-R1-Zero,设计了一个简单的模板。首先产生一个推理过程,然后是最后的答案。
<think>推理过程</think><answer>答案</answer>
(3)自进化现象
- 随着 RL 步数增加,模型逐步涌现出反思(Re-evaluation)、**长链推理(Long CoT)**等行为;
- 在 AIME 2024 上,Pass@1 从15.6%提升至71.0%,多数投票(cons@64)可达86.7%。

2.1.2 核心算法:GRPO(Group Relative Policy Optimization)
以下内容细节可仔细研究原始论文:
- 论文:《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》
- 地址:https://arxiv.org/abs/2402.03300
GRPO 通过分组策略优化降低训练成本,省去传统 PPO 中的 Critic(评论家) 模型。其目标函数为:
J GRPO ( θ ) = E q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) [ 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ϵ , 1 + ϵ ) A i ) − β D KL ( π θ ∣ ∣ π ref ) ) ] J^{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}^G_{i=1} \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \min \left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip}\left(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon\right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right) \right] JGRPO(θ)=Eq∼P(Q),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











