






秋招总结帖
待完善,持续更新
小米(offer)
寒武纪(池子)
荣耀(二面挂)
华为(池子)
茄子科技(hr面后挂)
58 同城(意向)
经纬恒润(天津,n+2w)
海信(青岛,nw)
XX(北京国企,有京户,nw)
神策数据(三面挂)
招银网络科技(一面鸽)
小红书(一面挂)
快手(一面挂)
字节跳动(一面挂)
百度(一面挂)
oppo(一面挂)
龙湖科技(一面挂)
笔试挂或无后续
京东
美团
哔哩哔哩
拼多多
网易
携程
奇安信
虾皮
蔚来
知乎
图森
海量数据处理
- 可以全部放到内存:哈希表统计
- 不可以全部放到内存:哈希(字典树也可用于统计次数),取模,映射到小文件(一个query只会出现在一个文件里)
- TOP K 问题:最小堆(平均 lgK 时间复杂度),归并排序
- bitMap
机器学习算法
-
特征工程基本操作
- 连续特征归一化,类别特征表示
- 特征表示
- 特征选择
- 特征去噪
-
XGboost要点
- 基模型都是回归树
- 一般用 CART,CART 一般是二叉树,所以对于多类别的离散特征,需要编码(one-hot encoding 或者 label encoding)
- 对于多类别离散特征的处理,
- 存在大小关系的按照连续特征处理;
- 不存在大小关系的,特征捆绑(city == beijing || city == shanghai),编码,embedding
-
介绍一下 GBDT
-
XGBoost 常调的参数
-
SVM 为什么进行对偶变化
- 对偶问题容易求解:
- 极小问题变成了极大极小问题
- 自然引入核函数
- 推导步骤
- 最大间隔
- 约束优化问题 -> 拉格朗日函数(极小极大问题) -> 对偶变化,变为极大极小问题
- L(w, b, a)分别对 w, b 求导并令导数为 0,得到 a 和 w, b 的关系,代入L(w, b, a),极大极小问题变成了关于 a 的极小问题,可证明此极小问题与原极大极小问题等价
- 解上述问题,求得 a, 利用 KKT 条件求 w, b
- 得到分类决策函数
- 对偶问题容易求解:
-
贝叶斯概率计算
-
t-SNE 和 PCA
-
样本主成分
- 给定样本矩阵 X X X。样本第一主成分 y 1 = a 1 T x y_1=a_1^T\bold{x} y1=a1Tx 是在 a 1 T a 1 = 1 a_1^Ta_1 = 1 a1Ta1=1 条件下,使得 a 1 T x j ( j = 1 , 2 , . . . , n ) a_1^Tx_j (j=1,2,...,n) a1Txj(j=1,2,...,n) 的样本方差 a 1 T S a 1 a_1^TSa_1 a1TSa1 最大的 x x x 的线性变换;
- 样本第二主成分 y 2 = a 2 T x y_2=a_2^T\bold{x} y2=a2Tx 是在 a 2 T a 2 = 1 a_2^Ta_2 = 1 a2Ta2=1 和 a 2 T x j a_2^Tx_j a2Txj 与 a 1 T x j ( j = 1 , 2 , . . , n ) a_1^Tx_j(j=1,2,..,n) a1Txj(j=1,2,..,n) 的样本协方差 a 1 T S a 2 = 0 a_1^TSa_2 = 0 a1TSa2=0 条件下,使得 a 2 T x j a_2^Tx_j a2Txj 的样本方差 a 2 T S a 2 a_2^TSa_2 a2TSa2 最大的 x x x 的线性变换;
- 一般地,样本第 i 主成分 y i = a i T x y_i=a_i^Tx yi=aiTx 是在 a i T a i = 1 a_i^Ta_i = 1 aiTai=1 和 a i T x j a_i^Tx_j aiTxj 与 a k T x j ( k < i , j = 1 , 2 , . . . , n ) a_k^Tx_j(k < i, j=1,2,...,n) akTxj(k<i,j=1,2,...,n) 的 样本协方差 a k T S a i = 0 a_k^TSa_i=0 akTSai=0 条件下使得 a i T x j a_i^Tx_j aiTxj 的样本方差 a i T S a i a_i^TSa_i aiTSai 最大的 x x x 的线性变换。
-
PCA 推导: 设 x x x 是 m 维随机向量, Σ \Sigma Σ 是 x x x 的协方差矩阵 ( μ = E ( x ) , Σ = E [ ( x − μ ) ( x − μ ) T ] \mu=E(x), \Sigma=E[(x-\mu)(x-\mu)^T] μ=E(x),Σ=E[(x−μ)(x−μ)T]), Σ \Sigma Σ 的特征值分别是 λ 1 ≥ λ 2 ≥ . . . ≥ λ m ≥ 0 \lambda_1 \ge \lambda_2 \ge ... \ge \lambda_m \ge 0 λ1≥λ2≥...≥λm≥0,特征值对应的单位特征向量分别是 α 1 , α 2 , . . . , α m \alpha_1,\alpha_2,...,\alpha_m α1,α2,...,αm,则 x x x 的第 k 主成分是
y k = α k T x = α 1 k x 1 + α 2 k x 2 + . . . + α m k x m , k = 1 , 2 , . . . , m y_k=\alpha_k^Tx=\alpha_{1k}x_1+\alpha_{2k}x_2+...+\alpha_{mk}x_m, \quad k=1,2,...,m yk=αkTx=α1kx1+α2kx2+...+αmkxm,k=1,2,...,m
x x x 第 k 主成分的方差是
v a r ( y k ) = α k T Σ α k = λ k , k = 1 , 2 , . . . , m var(y_k)=\alpha_k^T\Sigma\alpha_k=\lambda_k, \quad k=1,2,...,m var(yk)=αkTΣαk=λk,k=1,2,...,m
即协反差矩阵的第 k 个特征值。 **证明:**采用拉格朗日乘子法求出主成分。
首先求 x x x 的第一主成分 y 1 = α 1 T x y_1=\alpha_1^Tx y1=α1Tx,即求系数向量 α 1 \alpha_1 α1。第一主成分是在 α 1 T α 1 = 1 \alpha_1^T\alpha_1=1 α1Tα1=1 条件下, x x x 的所有线性变换中使方差 v a r ( α 1 T x ) var(\alpha_1^Tx) var(α1Tx) 达到最大的。
求第一主成分就是求解约束最优化问题:
max α 1 α 1 T Σ α 1 s . t . α 1 T α 1 = 1 \max_{\alpha_1}\alpha_1^T\Sigma\alpha_1 \\ s.t. \quad \alpha_1^T\alpha_1=1 α1maxα1TΣα1s.t.α1Tα1=1
定义拉格朗日函数:
L ( α 1 , λ ) = α 1 T Σ α 1 − λ ( α 1 T α 1 − 1 ) L(\alpha_1, \lambda)=\alpha_1^T\Sigma\alpha_1-\lambda(\alpha_1^T\alpha_1-1) L(α1,λ)=α1TΣα1−λ(α1Tα1−1)
其中 λ \lambda λ 是拉格朗日乘子。将拉格朗日函数对 α 1 \alpha_1 α1 求导,并令其为 0,得
Σ α 1 − λ α 1 = 0 \Sigma\alpha_1-\lambda\alpha_1=0 Σα1−λα1=0
因此, λ \lambda λ 是 Σ \Sigma Σ 的特征值, α 1 \alpha_1 α1 是对应的单位特征向量。于是,目标函数
α 1 T Σ α 1 = α 1 T λ α 1 = λ \alpha_1^T\Sigma\alpha_1=\alpha_1^T\lambda\alpha_1=\lambda α1TΣα1=α1Tλα1=λ
假设 α 1 \alpha_1 α1 是 Σ \Sigma Σ 的最大特征值 λ 1 \lambda_1 λ1 对应的单位特征向量,显然 α 1 \alpha_1 α1 与 λ 1 \lambda_1 λ1 是最优化问题的解。所以, α 1 T x \alpha_1^Tx α1Tx 构成第一主成分,其方差是协方差矩阵的最大特征值。 接着求 x x x 的第二主成分 y 2 = α 2 T x y_2=\alpha_2^Tx y2=α2Tx。第二主成分的 α 2 \alpha_2 α2 是在 α 2 T α 2 = 1 \alpha_2^T\alpha_2=1 α2Tα2=1,且 α 2 T x \alpha_2^Tx α2Tx 与 α 1 T x \alpha_1^Tx α1Tx 不相关的条件下, x x x 的所有线性变换使方差 v a r ( α 2 T x ) = α 2 T Σ α 2 var(\alpha_2^Tx)=\alpha_2^T\Sigma\alpha_2 var(α2Tx)=α2TΣα2 达到最大的。
求解第二主成分需要求解约束优化问题
max α 2 α 2 T Σ α 2 s . t . α 1 T Σ α 2 = 0 , α 2 T Σ α 1 = 0 α 2 T α 2 = 1 \max_{\alpha_2}\alpha_2^T\Sigma\alpha_2 \\ s.t. \quad \alpha_1^T\Sigma\alpha_2=0, \alpha_2^T\Sigma\alpha_1=0 \\ \quad \alpha_2^T\alpha_2=1 α2maxα2TΣα2s.t.α1TΣα2=0,α2TΣα1=0α2Tα2=1
注意到
α 1 T Σ α 2 = α 2 T Σ α 1 = α 2 T λ 1 α 1 = λ 1 α 2 T α 1 = λ 1 α 1 T α 2 且 α 1 T α 2 = α 2 T α 1 = 0 \alpha_1^T\Sigma\alpha_2=\alpha_2^T\Sigma\alpha_1=\alpha_2^T\lambda_1\alpha_1=\lambda_1\alpha_2^T\alpha_1=\lambda_1\alpha_1^T\alpha_2 \\ 且 \quad \alpha_1^T\alpha_2=\alpha_2^T\alpha_1=0 α1TΣα2=α2TΣα1=α2Tλ1α1=λ1α2Tα1=λ1α1Tα2且α1Tα2=α2Tα1=0
定义拉格朗日函数
α 2 T Σ α 2 − λ ( α 2 T α 2 − 1 ) − ϕ α 2 T α 1 \alpha_2^T\Sigma\alpha_2-\lambda(\alpha_2^T\alpha_2 - 1)-\phi\alpha_2^T\alpha_1 α2TΣα2−λ(α2Tα2−1)−ϕα2Tα1
其中, λ , ϕ \lambda, \phi λ,ϕ 是拉格朗日乘子。对 α 2 \alpha_2 α2 求导,并令其为 0,得
2 Σ α 2 − 2 λ α 2 − ϕ α 1 = 0 2\Sigma\alpha_2 - 2\lambda\alpha_2 - \phi\alpha_1 = 0 2Σα2−2λα2−ϕα1=0
左乘 α 1 T \alpha_1^T α1T ,有
2 α 1 T Σ α 2 − 2 λ α 1 T α 2 − ϕ α 1 T α 1 = 0 2\alpha_1^T\Sigma\alpha_2 - 2\lambda\alpha_1^T\alpha_2 - \phi\alpha_1^T\alpha_1 = 0 2α1TΣα2−2λα1Tα2−ϕα1Tα1=0
由于约束条件,上式前两项是 0,且 α 1 T α 1 = 1 \alpha_1^T\alpha_1=1 α1Tα1=1 ,得出 ϕ = 0 \phi=0 ϕ=0 ,因此
Σ α 2 − λ α 2 = 0 \Sigma\alpha_2-\lambda\alpha_2=0 Σα2−λα2=0
由此, λ \lambda λ 是 Σ \Sigma Σ 的特征值, α 2 \alpha_2 α2 是对应的特征向量。于是,目标函数
α 2 T Σ α 2 = α 2 T λ α 2 = λ α 2 T α 2 = λ \alpha_2^T\Sigma\alpha_2=\alpha_2^T\lambda\alpha_2=\lambda\alpha_2^T\alpha_2=\lambda α2TΣα2=α2Tλα2=λα2Tα2=λ
Σ \Sigma Σ 的第二大特征值 λ 2 \lambda_2 λ2 显然是以上最优化问题的解。于是 α 2 T x \alpha_2^Tx α2Tx 构成第二主成分,其方差等于协方差矩阵的第二大特征值,
v a r ( α 2 T x ) = α 2 T Σ α 2 = λ 2 var(\alpha_2^Tx)=\alpha_2^T\Sigma\alpha_2=\lambda_2 var(α2Tx)=α2TΣα2=λ2
一般地, x x x 的第 k k k 主成分是 α k T x \alpha_k^Tx αkTx,并且 v a r ( α k T x ) = λ k var(\alpha_k^Tx)=\lambda_k var(αkTx)=λk,其中, λ k \lambda_k λk 是 Σ \Sigma Σ 的第 k k k 个特征值, α k \alpha_k αk 是对应的特征向量。总体主成分的性质:
(1) 总体主成分 y y y 的协方差矩阵是对角矩阵: c o v ( y ) = Λ = d i a g ( λ 1 , λ 2 , . . . , λ m ) cov(y) = \Lambda=diag(\lambda_1, \lambda_2,...,\lambda_m) cov(y)=Λ=diag(λ1,λ2,...,λm);
(2) 总体主成分 y y y 的方差之和等于随机变量 x x x 的方差之和;
(3) 第 k 个主成分 y k y_k yk 与变量 x i x_i xi 的相关系数 ρ ( y k , x i ) \rho(y_k, x_i) ρ(yk,xi) 称为因子负荷量(factor loading),它表示第 k 个主成分 y k y_k yk 与变量 x i x_i xi 的相关关系。计算公式是
ρ ( y k , x i ) = c o v ( y k , x i ) v a r ( y k ) v a r ( x i ) = c o v ( α k T x , e i T x ) λ k σ i i c o v ( α k T x , e i T x ) = α k T Σ e i = e i T Σ α k = λ k e i T α k = λ k α i k ρ ( y k , x i ) = λ k α i k λ k σ i i = λ k α i k σ i i \rho(y_k, x_i)=\frac{cov(y_k,x_i)}{\sqrt{var(y_k)var(x_i)}}=\frac{cov(\alpha_k^Tx, e_i^Tx)}{\sqrt{\lambda_k}\sqrt{\sigma_{ii}}} \\ cov(\alpha_k^Tx, e_i^Tx) = \alpha_k^T \Sigma e_i = e_i^T \Sigma \alpha_k = \lambda_k e_i^T \alpha_k = \lambda_k \alpha_{ik} \\ \rho(y_k, x_i) = \frac{\lambda_k\alpha_{ik}}{\sqrt{\lambda_k}\sqrt{\sigma_{ii}}} = \frac{\sqrt{\lambda_k}\alpha_{ik}}{\sqrt{\sigma_{ii}}} ρ(yk,xi)=var(yk)var(xi)cov(yk,xi)=λkσiicov(αkTx,eiTx)cov(αkTx,eiTx)=αkTΣei=eiTΣαk=λkeiTαk=λkαikρ(yk,xi)=λkσiiλkαik=σiiλkαik
(4) 第 k 个主成分 y k y_k yk 与 m 个变量的因子负荷量满足
∑ i = 1 m σ i i ρ 2 ( y k , x i ) = λ k \sum_{i=1}^m\sigma_{ii}\rho^2(y_k, x_i)=\lambda_k i=1∑mσiiρ2(yk,xi)=λk
(5) m 个主成分与第 i 个变量 x i x_i xi 的因子负荷量满足
∑ k = 1 m ρ 2 ( y k , x i ) = 1 \sum_{k=1}^m\rho^2(y_k, x_i) = 1 k=1∑mρ2(yk,xi)=1 -
-
逻辑回归:二项的逻辑回归是如下的条件概率分布:
P ( Y = 1 ∣ x ) = e x p ( w ⋅ x + b ) 1 + e x p ( w ⋅ x + b ) P ( Y = 0 ∣ x ) = 1 1 + e x p ( w ⋅ x + b ) P(Y=1|x) = \frac{exp(w \cdot x + b)}{1+exp(w \cdot x + b)} \\ P(Y=0|x) = \frac{1}{1+exp(w \cdot x + b)} P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)P(Y=0∣x)=1+exp(w⋅x+b)1
一个事件的几率 (odds) 是指该事件的概率与该事件不发生的概率的比值。如果事件发生的概率是 p,那么事件的几率是
p
1
−
p
\frac{p}{1-p}
1−pp ,对于逻辑回归而言,该事件的对数几率是输入
x
x
x 的线性函数表示的模型:
l
o
g
P
(
Y
=
1
∣
x
)
1
−
P
(
Y
=
1
∣
x
)
=
w
⋅
x
log\frac{P(Y=1|x)}{1-P(Y=1|x)}=w \cdot x
log1−P(Y=1∣x)P(Y=1∣x)=w⋅x
参数估计:
设:
P
(
Y
=
1
∣
x
)
=
π
(
x
)
,
P
(
Y
=
0
∣
x
)
=
1
−
π
(
x
)
P(Y=1|x)=\pi(x),P(Y=0|x)=1-\pi(x)
P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x)
似然函数为
∏
i
=
1
N
[
π
(
x
i
)
]
y
i
[
1
−
π
(
x
i
)
]
1
−
y
i
\prod_{i=1}^N[\pi(x_i)]^{y_i}[1-\pi(x_i)]^{1-y_i}
i=1∏N[π(xi)]yi[1−π(xi)]1−yi
对数似然函数为
KaTeX parse error: No such environment: align at position 16: {align} \begin{̲a̲l̲i̲g̲n̲}̲ L(w)&=\sum_{i=…
对
L
(
w
)
L(w)
L(w) 求极大值,得到
w
w
w 的估计值。对对数似然函数取负转化为极小化问题,利用梯度下降法求解:
−
∂
L
(
w
)
∂
w
=
∑
i
=
1
N
[
−
y
i
x
i
+
x
i
e
x
p
(
w
⋅
x
i
)
1
+
e
x
p
(
w
⋅
x
i
)
]
=
−
∑
i
=
1
N
x
i
[
y
i
−
h
w
(
x
i
)
]
-\frac{\partial L(w)}{\partial w} = \sum_{i=1}^N[-y_ix_i+\frac{x_iexp(w \cdot x_i)}{1+exp(w \cdot x_i)}] = -\sum_{i=1}^N x_i[y_i - h_w(x_i)]
−∂w∂L(w)=i=1∑N[−yixi+1+exp(w⋅xi)xiexp(w⋅xi)]=−i=1∑Nxi[yi−hw(xi)]
梯度更新公式:
w
n
+
1
=
w
n
+
η
⋅
(
∂
L
(
w
)
∂
w
)
=
w
n
+
η
⋅
∑
i
=
1
N
x
i
[
y
i
−
h
w
(
x
i
)
]
w_{n+1} = w_n + \eta \cdot \left( \frac{\partial L(w)}{\partial w} \right) = w_n + \eta \cdot \sum_{i=1}^N x_i[y_i - h_w(x_i)]
wn+1=wn+η⋅(∂w∂L(w))=wn+η⋅i=1∑Nxi[yi−hw(xi)]
其中,
η
\eta
η 是学习率。
-
梯度下降算法求解极大似然过程(更新过程)
-
逻辑回归为什么不使用平方损失
若使用平方损失,损失函数为
L ( w ) = 1 N ∑ i = 1 N [ y i − h w ( x i ) ] 2 L(w)=\frac{1}{N}\sum_{i=1}^N[y_i-h_w(x_i)]^2 L(w)=N1i=1∑N[yi−hw(xi)]2
极小化损失函数,利用梯度下降法求解:
∂
L
(
w
)
∂
w
=
−
2
N
∑
i
=
1
N
x
i
[
y
i
−
h
w
(
x
i
)
]
h
w
′
(
x
i
)
=
−
2
N
∑
i
=
1
N
x
i
[
y
i
−
h
w
(
x
i
)
]
e
x
p
(
w
⋅
x
i
)
[
1
+
e
x
p
(
w
⋅
x
i
)
]
2
\frac{\partial L(w)}{\partial w} = -\frac{2}{N}\sum_{i=1}^N x_i[y_i - h_w(x_i)]h_w'(x_i) = -\frac{2}{N}\sum_{i=1}^N x_i[y_i - h_w(x_i)]\frac{exp(w \cdot x_i)}{[1+exp(w \cdot x_i)]^2}
∂w∂L(w)=−N2i=1∑Nxi[yi−hw(xi)]hw′(xi)=−N2i=1∑Nxi[yi−hw(xi)][1+exp(w⋅xi)]2exp(w⋅xi)
当
w
⋅
x
i
w \cdot x_i
w⋅xi 过大或过小时,
h
w
′
(
x
i
)
h_w'(x_i)
hw′(xi) 都很小,会导致梯度消失的问题。
-
PCA
- 最大化投影方差
-
K-means 和 DBSCAN: Density-Based Spatial Clustering Algorithm with Noise
- k-means
- 聚类效果依赖于簇心的选择
- 会把所有数据点聚类,对离群点不敏感
- 对每个簇来说,所有的方向同等重要,仅适合球形数据簇
- DBSCAN
- 优点:
- 不需要指定簇数
- 适合各种复杂形状的数据点分布
- 可识别出不属于任何簇的离群点
- 缺点:
- 运行速度慢
- 参数调整,
- 对于具有不同密度的簇,效果不好
- 优点:
- k-means
-
聚类算法
- K-Means
- 手肘法,复杂度,优缺点
- 手肘法:SSE(误差平方和和 K 值的曲线,选曲率最大的地方)
- 层次聚类
- DBSCAN
- …
-
GBDT 和 XGBoost
- GBDT 是机器学习算法,XBGoost 是工程实现
- XGBoost 在基分类器显示加入正则化项,控制模型复杂度,有利于防止过拟合,一个是限制树的高度,一个是叶子节点权重的二范数
- XGBoost 同时使用对损失函数做二阶泰勒展开,可以更快更准的降低偏差
- XGBoost 支持多种基分类器
- 支持对数据采样,类似于随机森林(特征采样,样本采样),降低方差
- 处理缺失值,分裂时尝试把空缺值当成一类数据分到左节点或右节点,选增益大的
-
XGBoost 和 lightGBM
- XGBoost 采用预排序,对节点的特征进行预排序并遍历选择最优分割点,数据量大时贪心耗时,lightGBM 使用直方图
- lightGBM 对样本基于梯度采样
- XGBoost 是 level-wise,lightGBM 是 leaf-wise
- 互斥特征捆绑
-
bagging 和 boosting 方法的区别
- bagging 对训练集进行有放回抽样,boosting 对分类错误的样本加权以降低偏差
- bagging 主要关注降低方差,boosting 主要关注降低偏差
- bagging 子模型的训练可以并行进行,boosting 是串行模型,必须串行训练
- bagging 模型的预测结果由各个子模型投票或加权平均得出,boosting 模型的预测结果由各个模型预测结果加起来
- 哪些模型使用了 bagging
- 随机森林
-
说出四个激活函数,以及优缺点
-
XGBoost 过拟合怎么解决
-
SVM 的细节,KKT 条件的意义
- 在线性可分的约束条件下,最大化分类间隔
- 利用拉格朗日乘数,将有约束最优化问题转为无约束最优化问题,由于是不等式约束,转化后是 min-max 优化问题
- 对偶变换,min-max 问题转为 max-min 问题,SVM 中是强对偶关系,原问题和对偶问题解相同
-
求解关于 α \alpha α 的二次规划问题
- 利用 KKT 条件求 w, b
- 得到分类决策函数
-
MSE 为什么不能做分类损失
-
说说 softmax、交叉熵
s o f t m a x ( σ i ) = e x p ( x i ) ∑ j = 1 C e x p ( x j ) , C r o s s E n t r o p y = − ∑ i = 1 C y i l o g ( σ i ) softmax(\sigma_i)=\frac{exp(x_i)}{\sum_{j=1}^Cexp(x_j)}, CrossEntropy = -\sum_{i=1}^Cy_ilog(\sigma_i) softmax(σi)=∑j=1Cexp(xj)exp(xi),CrossEntropy=−i=1∑Cyilog(σi)
- 相对熵 / KL散度
K L ( P ∣ ∣ Q ) = ∑ P ( x ) l o g P ( x ) Q ( x ) o r ∫ P ( x ) l o g P ( x ) Q ( x ) d x KL(P||Q)=\sum P(x)log\frac{P(x)}{Q(x)} \quad or \quad \int P(x)log\frac{P(x)}{Q(x)}dx KL(P∣∣Q)=∑P(x)logQ(x)P(x)or∫P(x)logQ(x)P(x)dx
- 互信息
I ( X ; Y ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g p ( x , y ) p ( x ) p ( y ) I(X;Y)=\sum_{x \in X}\sum_{y \in Y}p(x, y)log\frac{p(x, y)}{p(x)p(y)} I(X;Y)=x∈X∑y∈Y∑p(x,y)logp(x)p(y)p(x,y)
- 条件熵
H ( X ∣ Y ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g p ( x ∣ y ) H(X|Y)=-\sum_{x \in X}\sum_{y \in Y}p(x,y)logp(x|y) H(X∣Y)=−x∈X∑y∈Y∑p(x,y)logp(x∣y)
- JS 散度
J S ( P ∣ ∣ Q ) = 1 2 K L ( P ∣ ∣ P + Q 2 ) + 1 2 K L ( Q ∣ ∣ P + Q 2 ) JS(P||Q)=\frac{1}{2}KL(P||\frac{P+Q}{2})+\frac{1}{2}KL(Q||\frac{P+Q}{2}) JS(P∣∣Q)=21KL(P∣∣2P+Q)+21KL(Q∣∣2P+Q)
-
为什么使用 softmax?
- 指数让大的更大,小的更小
- 可微
-
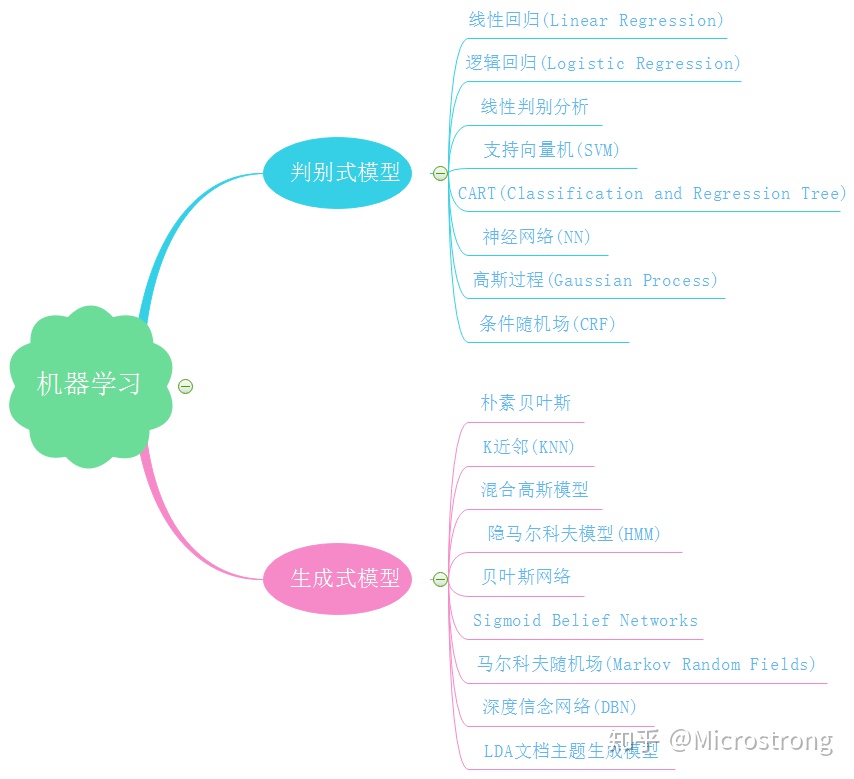
生成式模型、判别式模型
-
集成学习
- 集成学习的核心是得到不一样且有一定准确率的基分类器,然后表决(从降低方差的角度)
- boosting:有放回均匀采样
- 主要关注降低偏差,所以应当尽量不让基学习器容量很大
- stacking, boosting, bagging 随机森林
- bagging,随机森林都是为了得到不同的基学习器
- 随机森林:基学习器是决策树的 bagging + 属性扰动
- 集成策略
- 平均法
- 简单平均
- 加权平均(一般个体学习器性能差异较大时才采用)
- 投票法
- 绝对多数投票法
- 某标记得票超过半数,则预测,否则拒绝预测
- 相对多数投票法
- 预测为得票最多的标记
- 加权投票法
- 绝对多数投票法
- 学习法
- stacking
- 平均法
-
熟悉DNN、CNN、RNN、LSTM等经典模型,对 Transformer、Attention 等熟悉者有加分
-
梯度消失、梯度爆炸
出现原因:
- 链式法则,梯度累乘效应导致梯度指数级增长或减小;梯度饱和(GAN,sigmoid,tanh)
解决方案:
- pre-training + fine-tunning
- 梯度剪切:对梯度设定阈值,主要针对梯度爆炸
- 权重正则化
- 选择 relu 系的激活函数,梯度大部分是常数(1)
- BN:把数据从饱和区拉到非饱和区
- 残差网络系:resnet,densenet
-
神经网络基础知识
- 权重共享、dropout
- CNN 卷积计算尺寸
- RNN
- 你没有训练序列模型和强化学习模型的经历
- 课题的时候花点时间
- 强化学习 demo 跑一个
-
为什么分类问题损失函数不用 MSE 而用交叉熵
- 由于使用 sigmoid (softmax),MSE 求导的结果中包含 f(x)(1-f(x)),y=0,f(x)=1时,会有梯度消失问题;
- MSE 是非凸的,有许多局部极小值点
-
softmax 上溢下溢
- 其实没有下溢,只有上溢(指数过大时:z = z - max(Z))
-
交叉熵,极大似然估计, KL散度
-
常用损失函数
-
指数损失:对异常点敏感
-
对数似然
-
交叉熵
-
均方误差 (MSE)
- 在模型输出与真实值的误差服从高斯分布的假设下,最小化均方差损失函数与极大似然估计本质上是一致的
-
绝对误差 (MAE)
-
MSE 比 MAE 更快收敛,MAE 比 MSE 更 robust,更不易受异常点(outlier)影响
-
MAE 在 ∣ y i − y i ^ ∣ |y_i-\hat{y_i}| ∣yi−yi^∣ 很小时梯度同样为 1,不利于模型收敛
-
MAE 假设误差服从拉普拉斯分布,MSE 假设误差服从高斯分布,出现 outlier 拉普拉斯分布相比高斯分布受到的影响小得多
-
MSE 假设模型预测值和真实值之间的误差服从标准高斯分布 ( μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1),则给定一个 x i x_i xi ,模型输出真实值 y i y_i yi 的概率为
p ( y i ∣ x i ) = 1 2 π e x p ( − ( y i − y i ^ ) 2 2 ) p(y_i|x_i)=\frac{1}{\sqrt{2\pi}}exp(-\frac{(y_i-\hat{y_i})^2}{2}) p(yi∣xi)=2π1exp(−2(yi−yi^)2)
进一步地,假设数据集中 N 个样本点之间相互独立,则给定所有 x x x 输出所有真实值的概率,即似然 Likelihood,为所有 p ( y i ∣ x i ) p(y_i|x_i) p(yi∣xi) 的累乘
L ( x , y ) = ∏ i = 1 N 1 2 π e x p ( − ( y i − y i ^ ) 2 2 ) L(x,y)=\prod_{i=1}^{N}\frac{1}{\sqrt{2\pi}}exp(-\frac{(y_i-\hat{y_i})^2}{2}) L(x,y)=i=1∏N2π1exp(−2(yi−yi^)2)
极小化负对数似然函数,并去掉无关项:
N L L ( x , y ) = − l o g ( L ( x , y ) ) = N 2 l o g 2 π + 1 2 ∑ i = 1 N ( y i − y i ^ ) 2 N L L ( x , y ) = 1 2 ∑ i = 1 N ( y i − y i ^ ) 2 NLL(x,y)=-log(L(x,y))=\frac{N}{2}log2\pi+\frac{1}{2}\sum_{i=1}^N(y_i-\hat{y_i})^2 \\ NLL(x,y)=\frac{1}{2}\sum_{i=1}^N(y_i-\hat{y_i})^2 NLL(x,y)=−log(L(x,y))=2Nlog2π+21i=1∑N(yi−yi^)2NLL(x,y)=21i=1∑N(yi−yi^)2 -
-
-
Huber Loss: y i y_i yi 与 y i ^ \hat{y_i} yi^ 差别大时 使用 MAE,降低 outlier 的影响;误差接近 0 时使用 MSE,使损失函数可到并且梯度更加稳定
-
激活函数优缺点
- sigmoid,softmax,tanh,reLU,leakyReLU
-
梯度下降
- 一阶梯度下降
-
优化器
-
SGD,mini-batch,动量,RMSprop,adam
-
学习率自动调整
- 学习率衰减、预热、周期调整
- AdaGrad:首先计算梯度平方的累加值,学习率逐渐衰减
- Δ θ t = − α G t + ϵ ⊙ g t \Delta\theta_t = -\frac{\alpha}{\sqrt{G_t+\epsilon}}\odot g_t Δθt=−Gt+ϵα⊙gt, G t = ∑ τ = 1 t g τ ⊙ g τ G_t = \sum_{\tau=1}^t g_{\tau} \odot g_{\tau} Gt=∑τ=1tgτ⊙gτ
- RMSprop:把 AdaGrad 的梯度平方累积变为指数衰减移动平均
-
梯度估计修正
- 动量法:在第𝑡 次迭代时,计算负梯度的“加权移动平均”作为参数的更新方向
- Adam:一方面计算梯度平方 g𝑡2 的指数加权平均(和 RMSprop 算法类似),另一方面计算梯度g𝑡 的指数加权平均(和动量法类似)
Adam
计算梯度平方 g t 2 g_t^2 gt2 的指数加权平均(RMSprop): G t = β 2 G t − 1 + ( 1 − β 2 ) g t ⊙ g t G_t=\beta_2G_{t-1} + (1 - \beta_2)g_t \odot g_t Gt=β2Gt−1+(1−β2)gt⊙gt
计算梯度梯度的指数加权平均(动量法): M t = β 1 M t − 1 + ( 1 − β 1 ) g t M_t = \beta_1M_{t-1} + (1-\beta_1)g_t Mt=β1Mt−1+(1−β1)gt
假设 M 0 = 0 , G 0 = 0 M_0 = 0,G_0 = 0 M0=0,G0=0,那么在迭代初期 M t M_t Mt 和 G t G_t Gt 得知会比真实的均值和方差要小,特别是当 β 1 , β 2 \beta_1,\beta_2 β1,β2 都接近 1 时,偏差会很大。因此,对偏差进行修正:
M t ^ = M t 1 − β 1 t G t ^ = G t 1 − β 2 t \hat{M_t}=\frac{M_t}{1-\beta_1^t} \\ \hat{G_t}=\frac{G_t}{1-\beta_2^t} Mt^=1−β1tMtGt^=1−β2tGt
参数更新: Δ θ t = − α G t ^ + ϵ M t ^ \Delta\theta_t=-\frac{\alpha}{\sqrt{\hat{G_t} + \epsilon}}\hat{M_t} Δθt=−Gt^+ϵαMt^- 梯度截断(梯度爆炸)
-
- 二阶梯度下降
- 牛顿法
- 拟牛顿法
- BFGS…
- 一阶梯度下降
-
分类评价标准
准确率:左右样本被分类正确的比例。
召回率:真实为正类的样本中,被判断为正类的占比。
精准率:判断为正类的样本中,真实为正类的占比。
f1分数:2召回率精准率/(召回率+精准率)
假正率:负类中被分类为正类的占比。
真正率:正类中被分类为正类的占比。(就是召回率)
ROC、AUC等。
ROC是指横坐标为假正率、纵坐标为真正率的曲线。真正率越高的同时,假正率低,就说明这个ROC曲线越好,曲线越陡。无视样本不平衡,因为无论正负样本比例如何变化,ROC都不会变。为了评估ROC的好坏,可能需要尝试不同的阈值(概率大于多少被判定为正类)。
AUC(area under curve)是ROC曲线下的面积。
-
回归问题评价指标
- MSE
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum_{i=1}^n(y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
- RMSE
R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^n(y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
- MAE (平均绝对误差)
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n}\sum_{i=1}^n|y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
- MAPE (平均百分比误差): 分母为 0 时不可用
M A P E = 100 % n ∑ i = 1 n ∣ y i − y ^ i y i ∣ MAPE = \frac{100\%}{n}\sum_{i=1}^n \left| \frac{y_i - \hat{y}_i}{y_i} \right| MAPE=n100%i=1∑n∣∣∣∣yiyi−y^i∣∣∣∣
- SMAPE (Symmetric Mean Absolute Percentage Error): 分母为 0 时不可用
S M A P E = 100 % n ∑ i = 1 n ∣ y i − y ^ i ∣ ( ∣ y i ∣ + ∣ y ^ i ∣ ) / 2 SMAPE = \frac{100\%}{n}\sum_{i=1}^n \frac{|y_i - \hat{y}_i|}{(|y_i| + |\hat{y}_i|)/2} SMAPE=n100%i=1∑n(∣yi∣+∣y^i∣)/2∣yi−y^i∣
- R 2 R^2 R2
R 2 = 1 − S S E S S T = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ i ) 2 R^2 = 1-\frac{SSE}{SST} = 1-\frac{\sum_{i=1}^n(y_i - \hat{y}_i)^2}{\sum_{i=1}^n(y_i - \bar{y}_i)^2} R2=1−SSTSSE=1−∑i=1n(yi−yˉi)2∑i=1n(yi−y^i)2
- Adjusted R-square: 调整 R 方,n:数据点个数,k:特征个数
A d j u s t e d R 2 = 1 − ( 1 − R 2 ) ( n − 1 ) ( n − k − 1 ) Adjusted \space R^2 = 1-\frac{(1 - R^2)(n-1)}{(n - k - 1)} Adjusted R2=1−(n−k−1)(1−R2)(n−1)
-
多重共线性
- 出现原因
多重共线性就是指一个解释变量的变化引起另一个解释变量的变化。
原本自变量应该是各自独立,根据回归分析结果,能得知哪些因素对因变量 Y 有显著影响。
如果各个自变量 x 之间有很强的线性关系,就无法固定其他变量,也就找不到 x 和 y 之间的真实关系了。
此外,多重共线性的原因还可能包括:
- 数据不足,某些情况下,收集更多数据可以解决共线性问题;
- 错误使用虚拟变量。比如,同时将男、女两个虚拟变量都放入模型,此时必定出现共线性,称为完全共线性
- 共线性判别指标
- VIF
-
FM、FFM、DeepFM
- 机器学习特征工程
- 数据预处理
- 无量纲化
- 标准化
- 区间缩放
- 标准化和归一化
- 定量特征二值化
- 定性特征哑编码
- 缺失值计算
- 填充
- 常量填充
- 插值填充
- 已有数据训练模型预测缺失值
- XGBoost
- 删除
- 填充
- 数据变换
- 无量纲化
- 特征选择
- Filter 过滤法
- 方差选择法,选择方差大(设定阈值)的特征
- 相关系数法,计算特征对目标值的相关系数和P值
- 卡方检验
- 互信息
- Wapper 包装法
- 通过消除特征获得不同特征集训练模型
- Embedded 集成法(学习器自动选择特征)
- 基于惩罚项
- 基于树模型
- 组合特征
- FM
- 决策树
- 先验知识
- Filter 过滤法
- 降维
- 主成分分析
- 线性判别分析
- 自编码器
- 数据预处理
SVM
线性不可分的线性支持向量机(软间隔最大化)的学习问题变成如下凸二次规划问题(convex quadratic programming)问题(原始问题)
min
w
,
b
,
ξ
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
y
i
(
w
⋅
x
i
+
b
)
≥
1
−
ξ
i
,
i
=
1
,
2
,
.
.
.
,
N
ξ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\min_{w,b,\xi}\frac{1}{2}||w||^2 + C\sum_{i=1}^N\xi_i \\ s.t. \quad y_i(w \cdot x_i + b) \ge 1 - \xi_i,i=1,2,...,N \\ \xi_i \ge 0, i=1,2,...,N
w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξis.t.yi(w⋅xi+b)≥1−ξi,i=1,2,...,Nξi≥0,i=1,2,...,N
上述原始最优化问题的拉格朗日函数是:
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
−
∑
i
=
1
N
α
i
[
y
i
(
w
⋅
x
i
+
b
)
−
1
+
ξ
i
]
−
∑
i
=
1
N
μ
i
ξ
i
其
中
,
α
i
≥
0
,
μ
i
≥
0
L(w,b,\xi,\alpha,\mu) = \frac{1}{2}||w||^2 + C\sum_{i=1}^N\xi_i - \sum_{i=1}^N\alpha_i[y_i(w \cdot x_i + b) - 1 + \xi_i] - \sum_{i=1}^N\mu_i\xi_i \\ 其中,\alpha_i \ge 0, \mu_i \ge 0
L(w,b,ξ,α,μ)=21∣∣w∣∣2+Ci=1∑Nξi−i=1∑Nαi[yi(w⋅xi+b)−1+ξi]−i=1∑Nμiξi其中,αi≥0,μi≥0
对偶问题是拉格朗日函数的极大极小问题。
max
α
,
μ
min
w
,
b
,
ξ
L
(
w
,
b
,
ξ
,
α
,
μ
)
s
.
t
.
α
i
≥
0
,
μ
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\max_{\alpha,\mu}\min_{w,b,\xi}L(w,b,\xi,\alpha,\mu) \\ s.t. \quad \alpha_i \ge 0, \mu_i \ge 0, i=1,2,...,N
α,μmaxw,b,ξminL(w,b,ξ,α,μ)s.t.αi≥0,μi≥0,i=1,2,...,N
首先求
L
(
w
,
b
,
ξ
,
α
,
μ
)
L(w,b,\xi,\alpha,\mu)
L(w,b,ξ,α,μ) 对
w
,
b
,
ξ
w,b,\xi
w,b,ξ 的极小,由
∇
w
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
w
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
∇
b
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
−
∑
i
=
1
N
α
i
y
i
=
0
∇
ξ
i
L
(
w
,
b
,
ξ
,
α
,
μ
)
=
C
−
α
i
−
μ
i
=
0
\nabla_wL(w,b,\xi,\alpha,\mu) = w - \sum_{i=1}^N\alpha_iy_ix_i = 0 \\ \nabla_bL(w,b,\xi,\alpha,\mu) = -\sum_{i=1}^N\alpha_iy_i = 0 \\ \nabla_{\xi_i}L(w,b,\xi,\alpha,\mu) = C - \alpha_i - \mu_i = 0
∇wL(w,b,ξ,α,μ)=w−i=1∑Nαiyixi=0∇bL(w,b,ξ,α,μ)=−i=1∑Nαiyi=0∇ξiL(w,b,ξ,α,μ)=C−αi−μi=0
得
w
=
∑
i
=
1
N
α
i
y
i
x
i
∑
i
=
1
N
α
i
y
i
=
0
C
−
α
i
−
μ
i
=
0
w = \sum_{i=1}^N\alpha_iy_ix_i \\ \sum_{i=1}^N\alpha_iy_i = 0 \\ C - \alpha_i - \mu_i = 0
w=i=1∑Nαiyixii=1∑Nαiyi=0C−αi−μi=0
代入拉格朗日函数得:
KaTeX parse error: No such environment: align at position 175: …pha_i \\ \begin{̲a̲l̲i̲g̲n̲}̲ s.t. \quad &\s…
将对偶最优化问题:利用等式约束
C
−
α
i
−
μ
i
=
0
C - \alpha_i - \mu_i = 0
C−αi−μi=0 消去
μ
i
\mu_i
μi,并将约束写成:
0
≤
α
i
≤
C
0 \le \alpha_i \le C
0≤αi≤C
将极大问题转化为极小问题,得到:
KaTeX parse error: No such environment: align at position 119: …pha_i \\ \begin{̲a̲l̲i̲g̲n̲}̲ s.t. \quad &\s…
定理 7.3 设
α
∗
=
(
α
1
∗
,
α
2
∗
,
.
.
.
,
α
N
∗
)
T
\alpha^* = (\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T
α∗=(α1∗,α2∗,...,αN∗)T 是对偶问题的解,若存在
α
∗
\alpha^*
α∗ 的一个分量
α
j
∗
\alpha_j^*
αj∗ ,满足
0
<
α
j
∗
<
C
0<\alpha_j^*<C
0<αj∗<C,则原始问题的解
w
∗
,
b
∗
w^*,b^*
w∗,b∗ 可按下式求得:
w
∗
=
∑
i
=
1
N
α
i
∗
y
i
x
i
b
∗
=
y
j
−
∑
i
=
1
N
y
i
α
i
∗
(
x
i
⋅
x
j
)
w^*=\sum_{i=1}^N\alpha_i^*y_ix_i \\ b^*=y_j - \sum_{i=1}^Ny_i\alpha_i^*(x_i \cdot x_j)
w∗=i=1∑Nαi∗yixib∗=yj−i=1∑Nyiαi∗(xi⋅xj)
证明: 原始问题是凸二次规划问题,解满足 KKT 条件,即
∇
w
L
(
w
∗
,
b
∗
,
ξ
∗
,
α
∗
,
μ
∗
)
=
w
∗
−
∑
i
=
1
N
α
i
∗
y
i
x
i
=
0
∇
b
L
(
w
∗
,
b
∗
,
ξ
∗
,
α
∗
,
μ
∗
)
=
−
∑
i
=
1
N
α
i
∗
y
i
=
0
∇
ξ
i
L
(
w
∗
,
b
∗
,
ξ
∗
,
α
∗
,
μ
∗
)
=
C
−
α
i
∗
−
μ
i
∗
=
0
α
i
∗
[
y
i
(
w
∗
⋅
x
i
+
b
∗
)
−
1
+
ξ
i
∗
]
=
0
μ
i
∗
ξ
i
∗
=
0
y
i
(
w
∗
⋅
x
i
+
b
∗
)
−
1
+
ξ
i
∗
≥
0
ξ
i
∗
≥
0
α
i
∗
≥
0
μ
i
∗
≥
0
,
i
=
1
,
2
,
.
.
.
,
N
\nabla_wL(w^*,b^*,\xi^*,\alpha^*,\mu^*) = w^* - \sum_{i=1}^N\alpha_i^*y_ix_i = 0 \\ \nabla_bL(w^*,b^*,\xi^*,\alpha^*,\mu^*) = -\sum_{i=1}^N\alpha_i^*y_i = 0 \\ \nabla_{\xi_i}L(w^*,b^*,\xi^*,\alpha^*,\mu^*) = C - \alpha_i^* - \mu_i^* = 0 \\ \alpha_i^*[y_i(w^* \cdot x_i + b^*) - 1 + \xi_i^*] = 0 \\ \mu_i^*\xi_i^*=0 \\ y_i(w^* \cdot x_i + b^*) - 1 + \xi_i^* \ge 0 \\ \xi_i^* \ge 0 \\ \alpha_i^* \ge 0 \\ \mu_i^* \ge 0, \quad i=1,2,...,N
∇wL(w∗,b∗,ξ∗,α∗,μ∗)=w∗−i=1∑Nαi∗yixi=0∇bL(w∗,b∗,ξ∗,α∗,μ∗)=−i=1∑Nαi∗yi=0∇ξiL(w∗,b∗,ξ∗,α∗,μ∗)=C−αi∗−μi∗=0αi∗[yi(w∗⋅xi+b∗)−1+ξi∗]=0μi∗ξi∗=0yi(w∗⋅xi+b∗)−1+ξi∗≥0ξi∗≥0αi∗≥0μi∗≥0,i=1,2,...,N
若存在
α
j
∗
\alpha_j^*
αj∗ ,满足
0
<
α
j
∗
<
C
0<\alpha_j^*<C
0<αj∗<C,则
y
i
(
w
∗
⋅
x
i
+
b
∗
)
−
1
=
0
y_i(w^* \cdot x_i + b^*) - 1 = 0
yi(w∗⋅xi+b∗)−1=0,得证。
分类超平面可写成
∑
i
=
1
N
α
i
∗
y
i
(
x
⋅
x
i
)
+
b
∗
=
0
\sum_{i=1}^N \alpha_i^*y_i(x \cdot x_i) + b^* = 0
i=1∑Nαi∗yi(x⋅xi)+b∗=0
分类决策函数可以写成
f
(
x
)
=
s
i
g
n
(
∑
i
=
1
N
α
i
∗
y
i
(
x
⋅
x
i
)
+
b
∗
)
f(x) = sign\left( \sum_{i=1}^N \alpha_i^*y_i(x \cdot x_i) + b^* \right)
f(x)=sign(i=1∑Nαi∗yi(x⋅xi)+b∗)
求解过程不写,基本就是解凸二次规划得到
α
∗
\alpha^*
α∗ 利用 KKT 条件算
w
∗
,
b
∗
w^*,b^*
w∗,b∗,从而得到分类超平面及分类决策函数。
拉格朗日对偶性
-
原始问题
假设 f ( x ) , c i ( x ) , h j ( x ) f(x),c_i(x),h_j(x) f(x),ci(x),hj(x)是定义在 R n R^n Rn上的连续可微函数,考虑约束最优化问题
min x ∈ R n f ( x ) s . t . c i ( x ) ≤ 0 , i = 1 , 2 , . . . , k h j ( x ) = 0 , j = 1 , 2 , . . . , l \min_{x \in R^n}f(x) \\ s.t. \quad c_i(x) \le 0, \quad i=1,2,...,k \\ \quad h_j(x)=0, \quad j=1,2,...,l x∈Rnminf(x)s.t.ci(x)≤0,i=1,2,...,khj(x)=0,j=1,2,...,l
称此约束最优化问题为原始最优化问题或原始问题。
引进广义拉格朗日函数
L
(
x
,
α
,
β
)
=
f
(
x
)
+
∑
i
=
1
k
α
i
c
i
(
x
)
+
∑
j
=
1
l
β
j
h
j
(
x
)
L(x, \alpha, \beta)=f(x)+\sum_{i=1}^k\alpha_ic_i(x)+\sum_{j=1}^l\beta_jh_j(x)
L(x,α,β)=f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)
这里,
α
i
≥
0
,
β
j
\alpha_i \ge 0,\beta_j
αi≥0,βj 是拉格朗日乘子,考虑
x
x
x 的函数:
θ
P
(
x
)
=
max
α
,
β
;
α
i
≥
0
L
(
x
,
α
,
β
)
\theta_P(x)=\max_{\alpha,\beta;\alpha_i \ge 0}L(x, \alpha, \beta)
θP(x)=α,β;αi≥0maxL(x,α,β)
P 表示原始问题。
假设给定某个
x
x
x 如果违反原始问题的约束条件,即存在某个 i 使得
c
i
(
x
)
>
0
c_i(x)>0
ci(x)>0 或者存在某个 j 使得
h
j
(
x
)
h_j(x)
hj(x),那么就有
θ
P
(
x
)
=
max
α
,
β
;
α
i
≥
0
[
f
(
x
)
+
∑
i
=
1
k
α
i
c
i
(
x
)
+
∑
j
=
1
l
β
j
h
j
(
x
)
]
=
+
∞
\theta_P(x)=\max_{\alpha,\beta;\alpha_i \ge 0} \left[ f(x)+\sum_{i=1}^k\alpha_ic_i(x)+\sum_{j=1}^l\beta_jh_j(x) \right] = +\infin
θP(x)=α,β;αi≥0max[f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)]=+∞
因为若某个 i 使得
c
i
(
x
)
>
0
c_i(x) > 0
ci(x)>0,则可令
α
i
→
+
∞
\alpha_i \rightarrow +\infin
αi→+∞,若某个 j 使得
h
j
(
x
)
≠
0
h_j(x) \neq 0
hj(x)=0,则可令
β
j
h
j
(
x
)
→
+
∞
\beta_jh_j(x) \rightarrow +\infin
βjhj(x)→+∞,而将其余
α
,
β
\alpha,\beta
α,β 取 0.
相反地,如果
x
x
x 满足约束条件时,有约束条件可知
θ
P
(
x
)
=
f
(
x
)
\theta_P(x)=f(x)
θP(x)=f(x) 。因此,
θ
P
(
x
)
=
{
f
(
x
)
,
x
满
足
原
始
问
题
约
束
+
∞
,
其
他
\theta_P(x) = \left\{ \begin{aligned} f(x), && x 满足原始问题约束\\ +\infin, && 其他 \end{aligned} \right.
θP(x)={f(x),+∞,x满足原始问题约束其他
所以考虑极小化问题
min
x
θ
P
(
x
)
=
min
x
max
α
,
β
;
α
i
≥
0
L
(
x
,
α
,
β
)
\min_x\theta_P(x)=\min_x \max_{\alpha,\beta;\alpha_i \ge 0}L(x, \alpha, \beta)
xminθP(x)=xminα,β;αi≥0maxL(x,α,β)
它与原始优化问题有相同的解,被称为广义拉格朗日函数的极大极小问题。定义原始问题的最优值
p
∗
=
min
x
θ
P
(
x
)
p^*=\min_x\theta_P(x)
p∗=xminθP(x)
-
对偶问题
定义:
θ D ( α , β ) = min x L ( x , α , β ) \theta_D(\alpha,\beta)=\min_xL(x,\alpha,\beta) θD(α,β)=xminL(x,α,β)
再考虑极大化
θ
D
(
α
,
β
)
\theta_D(\alpha,\beta)
θD(α,β) ,即
max
α
,
β
;
α
i
≥
0
θ
D
(
α
,
β
)
=
max
α
,
β
;
α
i
≥
0
min
x
L
(
x
,
α
,
β
)
\max_{\alpha,\beta;\alpha_i \ge 0}\theta_D(\alpha,\beta) = \max_{\alpha,\beta;\alpha_i \ge 0} \min_xL(x, \alpha, \beta)
α,β;αi≥0maxθD(α,β)=α,β;αi≥0maxxminL(x,α,β)
上述问题称为广义拉格朗日函数的极大极小问题,可以将广义拉格朗日函数的极大极小问题表示为约束优化问题:
max
α
,
β
θ
D
(
α
,
β
)
=
max
α
,
β
min
x
L
(
x
,
α
,
β
)
s
.
t
.
α
i
≥
0
,
i
=
1
,
2
,
.
.
.
,
k
\max_{\alpha,\beta}\theta_D(\alpha,\beta) = \max_{\alpha,\beta} \min_xL(x, \alpha, \beta) \\ s.t. \quad \alpha_i \ge 0, i=1,2,...,k
α,βmaxθD(α,β)=α,βmaxxminL(x,α,β)s.t.αi≥0,i=1,2,...,k
上述问题称为原始问题的对偶问题,定义对偶问题的最优值:
d
∗
=
max
α
,
β
;
α
i
≥
0
θ
D
(
α
,
β
)
d^*=\max_{\alpha,\beta;\alpha_i \ge 0}\theta_D(\alpha,\beta)
d∗=α,β;αi≥0maxθD(α,β)
-
原始问题和对偶问题的关系
定理 1 若原始问题和对偶问题都有最优值,则
d
∗
=
max
α
,
β
;
α
i
≥
0
min
x
L
(
x
,
α
,
β
)
≤
min
x
max
α
,
β
;
α
i
≥
0
L
(
x
,
α
,
β
)
=
p
∗
d^*=\max_{\alpha,\beta;\alpha_i \ge 0} \min_xL(x, \alpha, \beta) \le \min_x \max_{\alpha,\beta;\alpha_i \ge 0} L(x, \alpha, \beta)=p^*
d∗=α,β;αi≥0maxxminL(x,α,β)≤xminα,β;αi≥0maxL(x,α,β)=p∗
证明:对任意的
α
,
β
,
x
\alpha,\beta,x
α,β,x 有
θ
D
(
α
,
β
)
=
min
x
L
(
x
,
α
,
β
)
≤
L
(
x
,
α
,
β
)
≤
max
α
,
β
;
α
i
≥
0
L
(
x
,
α
,
β
)
≤
θ
P
(
x
)
\theta_D(\alpha,\beta)=\min_xL(x, \alpha, \beta) \le L(x, \alpha, \beta) \le \max_{\alpha,\beta;\alpha_i \ge 0} L(x, \alpha, \beta) \le \theta_P(x)
θD(α,β)=xminL(x,α,β)≤L(x,α,β)≤α,β;αi≥0maxL(x,α,β)≤θP(x)
即:
θ
D
(
α
,
β
)
≤
θ
P
(
x
)
\theta_D(\alpha,\beta) \le \theta_P(x)
θD(α,β)≤θP(x),由于原始问题和对偶问题均有解,所以
max
α
,
β
;
α
i
≥
0
θ
D
(
α
,
β
)
≤
min
x
θ
P
(
x
)
\max_{\alpha,\beta;\alpha_i \ge 0} \theta_D(\alpha,\beta) \le \min_x\theta_P(x)
α,β;αi≥0maxθD(α,β)≤xminθP(x)
即:
d
∗
=
max
α
,
β
;
α
i
≥
0
min
x
L
(
x
,
α
,
β
)
≤
min
x
max
α
,
β
;
α
i
≥
0
L
(
x
,
α
,
β
)
=
p
∗
d^*=\max_{\alpha,\beta;\alpha_i \ge 0} \min_xL(x, \alpha, \beta) \le \min_x \max_{\alpha,\beta;\alpha_i \ge 0} L(x, \alpha, \beta)=p^*
d∗=α,β;αi≥0maxxminL(x,α,β)≤xminα,β;αi≥0maxL(x,α,β)=p∗
**推论 1 **设
x
∗
x^*
x∗ 和
α
∗
,
β
∗
\alpha^*,\beta^*
α∗,β∗ 分别是原始问题和对偶问题的解,并且
d
∗
=
p
∗
d^*=p^*
d∗=p∗ 。则
x
∗
x^*
x∗ 和
α
∗
,
β
∗
\alpha^*,\beta^*
α∗,β∗ 分别是原始问题和对偶问题的最优解。
在某些条件下,原始问题和对偶问题的最优值相等,这时可以用解对偶问题替代解原始问题。下面以定理的形式叙述有关的重要结论而不予证明。
定理 2 考虑原始问题和对偶问题,假设
- 函数 f ( x ) f(x) f(x) 和 c i ( x ) c_i(x) ci(x) 是凸函数;
- h j ( x ) h_j(x) hj(x) 是仿射函数;
- 不等式约束是严格可行的,即存在 x x x,对所有 i i i,有 c i ( x ) < 0 c_i(x)<0 ci(x)<0;
则存在
x
∗
,
α
∗
,
β
∗
x^*, \alpha^*, \beta^*
x∗,α∗,β∗ ,使
x
∗
x^*
x∗ 是原始问题的解,
α
∗
,
β
∗
\alpha^*, \beta^*
α∗,β∗ 是对偶问题的解,并且
d
∗
=
p
∗
=
L
(
x
∗
,
α
∗
,
β
∗
)
d^*=p^*=L(x^*, \alpha^*, \beta^*)
d∗=p∗=L(x∗,α∗,β∗)
定理 3 若原始问题和对偶问题满足 定理 2 的条件,则
x
∗
x^*
x∗ 和
α
∗
,
β
∗
\alpha^*,\beta^*
α∗,β∗ 分别是原始问题和对偶问题的解的充分必要条件是
x
∗
,
α
∗
,
β
∗
x^*, \alpha^*,\beta^*
x∗,α∗,β∗ 满足下列 Karush-Kuhn-Tucker (KKT) 条件:
∇
x
L
(
x
∗
,
α
∗
,
β
∗
)
=
0
α
i
∗
c
i
(
x
∗
)
=
0
,
i
=
1
,
2
,
.
.
.
,
k
c
i
(
x
∗
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
k
α
i
∗
≥
0
,
i
=
1
,
2
,
.
.
.
,
k
h
j
(
x
∗
)
=
0
,
j
=
1
,
2
,
.
.
.
,
l
\nabla_xL(x^*,\alpha^*,\beta^*)=0 \\ \alpha_i^*c_i(x^*)=0, \quad i=1,2,...,k \\ c_i(x^*) \le 0, \quad i=1,2,...,k \\ \alpha_i^* \ge 0, \quad i=1,2,...,k \\ h_j(x^*) = 0, \quad j=1,2,...,l
∇xL(x∗,α∗,β∗)=0αi∗ci(x∗)=0,i=1,2,...,kci(x∗)≤0,i=1,2,...,kαi∗≥0,i=1,2,...,khj(x∗)=0,j=1,2,...,l
上面第二个条件称为 KKT 的对偶互补条件(此条件的意思是,若
x
∗
,
α
∗
,
β
∗
x^*, \alpha^*,\beta^*
x∗,α∗,β∗ 是最优解,则原始问题中的拉格朗日余项等于 0.)。由此条件可知:若
α
i
∗
>
0
\alpha_i^*>0
αi∗>0,则
c
i
(
x
∗
)
=
0
c_i(x^*)=0
ci(x∗)=0.
SVM:逐句话、逐个公式的推导
LR 原理推导,损失函数,求解方法
决策树细节
编程题:
不熟悉的:
- 股票买卖
- 链表、二叉树的指针操作,哨兵,边界条件处理
- 优先队列
- 单调栈
- 堆排序
- 字符串理解
- 二分法(旋转数组),边界条件
- 单例模式
- 多线程
- 子序列和子串
面试遇到的:
- 字节:字符串编辑距离
- 百度:最长公共子序列
- 茄子:有序数组生成二叉平衡搜索树
- 寒武纪:排序怎么多核心并行,卷积感受野计算公式,计算一组数的全排列
- 华为:后序遍历中序遍历构造二叉树,搬货物
- 小米:层序遍历二叉树,链表翻转















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









