









概述
层次聚类是一种无监督学习方法,它通过构建一个层次的嵌套簇来组织数据。这种方法可以生成数据的树状图(Dendrogram),从而揭示数据内在的层次结构和相似性关系。层次聚类主要有两种策略:凝聚层次聚类(Agglomerative Hierarchical Clustering)和分裂层次聚类(Divisive Hierarchical Clustering)。
凝聚层次聚类
凝聚层次聚类是一种自底向上的方法,它开始时将每个数据点视为一个单独的簇,然后在算法的每一步中找出距离最近的两个簇进行合并,直到达到预设的簇数量或某个终止条件。
实现过程
1、计算节点之间的距离(将每个数据点作为一个节点)
2、初始化父节点
3、遍历节点集合(距离小于阈值的合并,添加到父节点的节点列表中)
4、更新父节点(相似度计算时,计算每个剩余节点与父节点的相似度,父节点集合中每个点赋予一个相似度权重)
5、递归聚合(对于具有多个子节点的父节点,重复步骤3和4,直到所有节点的聚类关系确定。这确保了树形结构可以不断地在聚合的过程中建立起来)
6、修建树结构(根据实际需求,对生成的父子节点树进行修剪。例如,可以设定一个最大深度或者基于距离阈值进行修剪,将超过最大深度或者距离阈值的树枝剪掉。)
7、得到聚类结果,可以获得不同层次下的聚类结果,树结构中同层的类别表示同一层次的聚类结果。
例子
MATLAB自带数据集例子
1、层次聚类树
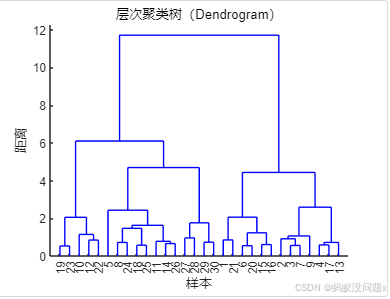
上图中的层次聚类树是iris数据集,它包含了鸢尾花的各种特征。我们使用该数据集进行聚类分析,得到如上图所示的层次聚类树。
层次聚类树是一种图形化展示数据聚类过程的方式,反映了数据点或簇的逐步合并过程。它呈现了每一轮合并的相似度或距离。
坐标系的含义:
-
横坐标:表示聚类合并的“距离”或“相似度”。这个坐标值反映了两个簇或数据点之间合并的距离。距离值越大,表示这两个簇之间的相似度较低,合并发生的“困难”越大;反之,距离小则表示这些数据点或簇之间的相似度较高,合并过程较为“容易”。
在层次聚类树中,横坐标的数值越大,代表两个簇的合并发生时,它们之间的差异(或距离)越大,反之亦然。
-
纵坐标:纵坐标表示数据点或簇的索引。它展示了聚类过程中的层级关系,即哪些数据点在最初阶段是单独的簇,哪些数据点后来被合并到其他簇中。纵坐标并不代表物理上的空间位置,而是用来表示数据点和簇之间的层次关系。
图中各个信息的解释:
-
叶子节点(最底部的点):每个叶子节点通常代表原始数据集中的一个单独的数据点。聚类过程开始时,每个数据点都被认为是一个独立的簇。
-
分支(树干):表示两个簇合并的过程。合并的高度(横坐标的值)表示两个簇之间的相似度或距离。高度越低,合并的簇之间越相似。
-
簇合并的顺序:树状图显示了聚类的顺序,越往上,簇的合并顺序越接近整体数据集的“最终”聚类结果。树状图可以用来推断数据点之间的相似度结构。
延申解释:
-
如果你观察到两个数据点在树状图中几乎没有合并(合并高度非常大),那么这两个数据点在特征空间中的差异很大,它们在聚类过程中很久才会合并成一个簇。
-
如果某两个数据点的合并高度较低,表示它们的相似度较高,因此在聚类中会很早被合并成一个簇。
2、层次聚类结果散点图
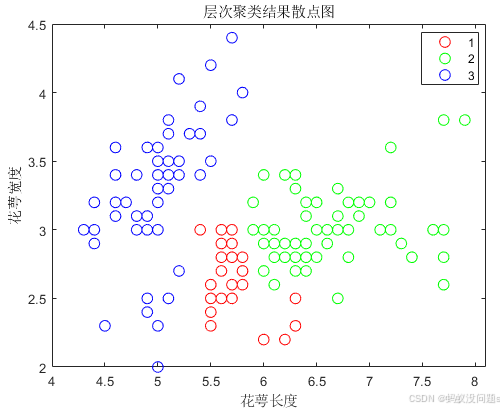
层次聚类结果散点图通常用于展示聚类结果在二维空间中的分布情况。它通过将数据点投影到二维平面上并使用不同的颜色或形状表示不同的簇,来直观地观察聚类的结果。
坐标系的含义:
-
横坐标和纵坐标:散点图的横坐标和纵坐标通常表示数据点在两个特征维度上的值(例如,
Feature 1和Feature 2)。这些特征是从原始数据中提取出来的。不同的维度值决定了数据点在平面中的位置。 -
点的颜色或形状:散点图中不同颜色或形状的点代表不同的簇。聚类算法(例如层次聚类)将数据点分配到不同的簇中,散点图通过颜色或形状的区分来显示每个数据点所属的簇。
图中的信息:
-
数据点的位置:每个数据点的位置由其特征值(例如,X轴和Y轴的值)决定。散点图的目的是展示这些数据点如何分布在二维空间中。
-
聚类结果:通过不同的颜色或形状,散点图清楚地展示了每个数据点属于哪个簇。例如,簇1的所有数据点可能用红色表示,簇2用蓝色表示,簇3用绿色表示等等。这样,您可以通过观察这些数据点在二维空间中的分布来判断簇的形状和相对位置。
延申解释:
-
如果观察到某些簇的数据点在图中聚集在一起,且这些簇之间的边界明显分开,那么说明聚类算法很好地捕捉到了这些数据点之间的相似性。
-
如果簇之间没有明显的分离,或者某些数据点被错误地分类到不同的簇中,可能意味着数据中的噪声或不良的聚类效果。
总结:
-
层次聚类树(Dendrogram)是一种展示聚类过程的树状图,显示了数据点或簇在聚类过程中逐步合并的顺序。横坐标表示合并的距离或相似度,纵坐标表示数据点的层级关系。
-
层次聚类结果散点图展示了最终聚类的空间分布,横纵坐标对应于数据点的特征值,数据点通过颜色或形状区分不同的簇。
注意点
凝聚聚类对噪声和离群点敏感。
合并簇后,不能撤销合并,这可能导致不理想的聚类结果。
计算复杂度较高,尤其是在数据量大时。
实际应用
生物信息学:基因表达数据聚类。
市场分析:客户细分。
图像处理:图像分割。
分裂层次聚类
分裂层次聚类是一种自顶向下的方法,它开始时将所有数据点视为一个簇,然后在每一步中选择最合适的簇进行分裂,直到每个数据点都是一个单独的簇或达到预设的簇数量。
实现过程
1. 初始化:所有数据点为一个簇。
2. 选择簇:选择一个簇进行分裂。
3. 分裂:基于某些标准(如最大方差)将选择的簇分裂为两个子簇。
4. 重复步骤2-3,直到达到所需的簇数量或终止条件。
例子
假设有一组数据点,分裂聚类的过程可能如下:
1. 所有点开始时在一个簇中。
2. 选择一个包含多个类的簇进行分裂。
3. 根据某种分裂准则(如最大方差)将该簇分裂为两个更小的簇。
4. 继续选择并分裂簇,直到达到所需的簇数量。
注意点
分裂聚类的初始簇选择对结果有很大影响。
分裂策略需要精心设计,以确保有效的聚类结果。
与凝聚聚类相比,分裂聚类可能更难以处理大型数据集。
实际应用
社交网络分析:识别社区结构。
文本分类:文档聚类。
推荐系统:用户兴趣建模。
层次聚类算法的选择和应用需要根据具体问题和数据特性来决定。通过理解和应用不同的层次聚类算法,可以有效地从大规模数据中提取有价值的信息,为决策提供数据支持。
% 1. 加载数据集(使用MATLAB自带的iris数据集)
load fisheriris
% iris数据集包含150个样本和4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
% 2. 选择数据的前两列作为示例特征进行聚类
X = meas(:, 1:2); % 选择前两列特征,即花萼的长度和宽度
% 3. 计算欧几里得距离矩阵
distances = pdist(X, 'euclidean'); % pdist计算样本间的距离
% 4. 使用linkage函数执行层次聚类
Z = linkage(distances, 'ward'); % 'ward'方法是聚合方式的一种
% 5. 可视化层次聚类树(树状图)
figure;
dendrogram(Z);
title('层次聚类树(Dendrogram)');
xlabel('样本');
ylabel('距离');
% 进行聚类并获得簇的标签
T = cluster(Z, 'maxclust', 3); % 假设我们要分成3个簇
% 绘制散点图,使用不同颜色表示不同簇
figure;
gscatter(X(:,1), X(:,2), T, 'rgb', 'o', 8);
title('层次聚类结果散点图');
xlabel('花萼长度');
ylabel('花萼宽度');


















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











