






 本文介绍了LayoutLMv3,一种改进的多模态预训练模型,通过统一的文本和图像掩码目标,解决文档AI中不同模态表示学习的差异。模型使用词-块对齐(WPA)目标促进跨模态对齐,实现在多个文档AI任务上的卓越性能,无需依赖CNN或区域注释。
本文介绍了LayoutLMv3,一种改进的多模态预训练模型,通过统一的文本和图像掩码目标,解决文档AI中不同模态表示学习的差异。模型使用词-块对齐(WPA)目标促进跨模态对齐,实现在多个文档AI任务上的卓越性能,无需依赖CNN或区域注释。
摘要
推荐知乎
《多模态预训练模型指北——LayoutLM(二)》 - 知乎
自监督预训练技术在文档AI领域取得了显著发展。大多数多模态预训练模型使用掩码语言建模目标来学习文本模态上的双向表示,但是预训练目标是有所不同的。这种差异增加了多模态表示学习的困难度。在本文中我们提出来LayoutLMv3,用文本和图像掩码来预训练多模态transformers模型用于文档AI。除此以外,LayoutLMv3以word-patch对齐为目标进行预训练,通过预测文本单词对应的图像patch是否被遮挡来学习跨模态对齐。简单统一架构和训练目标使得LayoutLMv3成为一个通用预训练模型,特别对于以文本为中心和以图像为中心的文档AI任务。实验表明,我们提出的模型有着极其优越的性能。
CCS的概念
应用计算->文档分析;计算方法->自然语言处理
介绍
图1所示,预训练的文档人工智能可以对各种文档进行布局解析和提取关键信息,对于工业应用和学术研究非常重要。
由于成功应用了重构预训练目标(个人感觉,从layoutLM以来和bert,很多都是预训练目标做出了修改),自监督预训练技术在表示学习方面取得了快速进展。接着介绍一些历史:
BERT首先提出了"掩码语言模型MLM",通过基于上下文预测随机掩码token的原始词汇来学习双向表示。大多数优秀的多模态文档AI模型使用MLM,但是在图像模态的预训练目标上有所不同。比如图2DocFormer通过CNN解码器学习重建图像像素,倾向于学习有噪声的细节,而不是文档布局等高级结构。selfDoc提出回归掩蔽区域特征,这比在更小的词汇表中分类离散特征噪声更大,更难学习。图像(例如密集的图像像素或连续的区域特征)和文本(离散token)目标进一步增加了跨模态对齐学习的难度。
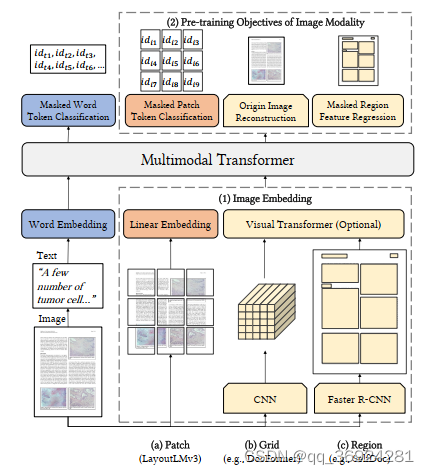
为了克服文本和图像模态预训练目标的差异,促进多模态表示学习,提出了LayoutLMv3,通过统一的文本和图像掩码目标MLM和MIM预训练文档AI的多模态Transformers模型。如图3所示,我们的模型学习重建文本模态掩码词语token,并且重建图像模态的掩码patch token。受DALL-E和BEiT的启发,我们从离散的VAE的潜在代码中获得目标图像token。对于文档,每个词对于一个图像块(patch)。为了学习这种跨模态对齐,我们提出词-贴片对齐(word-patch alignment,WPA)的目标来预测文本单词对应的图像patch是否被masked
受VIT的启发,LayoutLMv3直接利用文档中的原始图像块,而无需其他的预处理步骤,如页面对象检测。它在transformer模型中联合学习图像文本和多模态表示,具备统一的MLM(掩码),MIM和WPA..这使得LayoutLMv3成为第一个不使用CNN做图像嵌入的多模态预训练文档模型,这大大减少了参数并且避免了区域注释。
我们在五个基准实验上测试了它:FUNSD,表单理解;CORD,收据理解;DocVQA,文档视觉问题问答和图像为中心的测试;RVL-CDIP,文档分类;PubLayNet,文档层次布局分析。在这些任务上都有比较好的表现。
贡献
- LayoutLMv3是文档AI中第一个不依赖于预训练的CNN或者Faster R-CNN主干来提取视觉特征,这显著减少了参数并且消除了区域注释。
- LayoutLMv3通过统一的离散令牌重构目标MLM和MIM缓解了文本和图像多模态表示学习之间的差异。我们进一步提出来词-块对齐(WPA)目标来促进跨模态对齐学习
- LayoutLMv3是一个通用模型,对于以文本为中心和图像为中心的文档AI任务。第一次,我们展示了文档AI中多模态Transformer对于视觉任务的通用性。
2LayoutLMv3
2.1模型架构
LayoutLMv3应用统一的文本-图像多模态Transformer来学习跨模态表示。Transformer的输入是一个拼接的文本嵌入Y = y1:L和图像嵌入X = x1:M序列, 其中L,M分别为文本和图像的序列长度。通过Transformer,最后一层输出文本和图像的上下文表示。
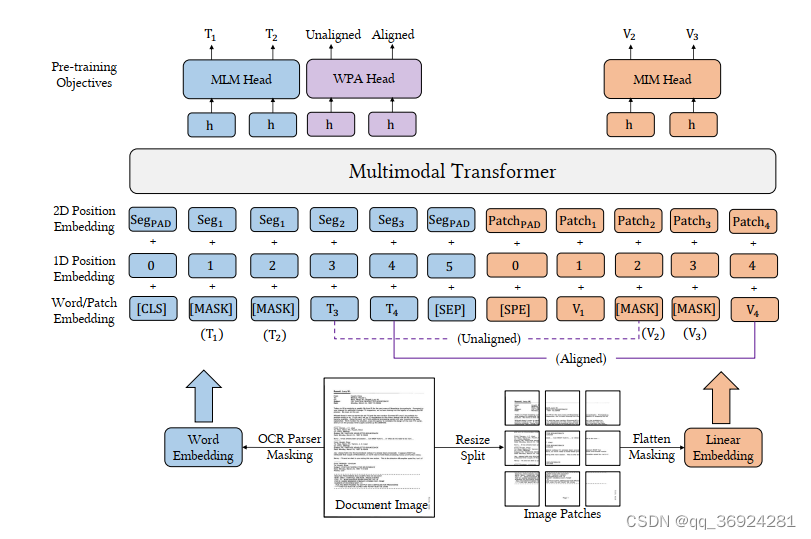
- 文本嵌入,是一个词嵌入和位置嵌入的结合。我们使用OCR对文档预处理得到文本内容和2D布局位置嵌入。我们使用RoBERTa的词嵌入初始化我们的词嵌入参数。位置嵌入=1D位置嵌入+2D位置嵌入,1D位置表示的是文本序列内标记的索引,2D则是文本的边界框位置。
遵循LayoutLM,我们会对坐标进行归一化,用嵌入层分别嵌入x、y轴、宽度和高度特征。LayoutLM和LayoutLMv2采用单词级布局位置, 其中每个单词都有其位置。 相反, 我们采用分段级布局位置, 一个分段中的单词共享相同的2D位置, 因为单词通常表达相同的语义。
- 图像嵌入。文档AI中现有的多模态模型要么依赖于CNN提取网格特征,要么依靠Faster R-CNN提取区域特征进行图像嵌入,这些要不需要大量计算要么需要区域监督。收到ViT的启发,我们用图像块的线性投影特征表示文档图像,然后将它们输入到多模态Transformer。具体来说,我们调整图像大小为H*W,用I∈R^(C× H× W)表示图像,分别是通道大小,高度和宽度。然后分割图像成一系列的P*P的块,线性投影到D维度,并且平展成一系列向量(长度为M=HW/P^2)。然后将可学习的1D位置嵌入添加到每个块(没有观察到2D位置嵌入对效果有改进),就是它的嵌入。

LayoutLMv3是文档人工智能中第一个不依赖cnn提取图像特征的多模态模型,这对于文档人工智能模型减少参数或去除复杂的预处理步骤至关重要。我们在LayoutLMv2[56]的文本和图像模式的自注意网络中插入语义一维相对位置和空间二维相对位置作为偏见项。
2.2预训练目标
使用MLM,MIM和WPA作为目标进行预训练,以自监督学习的方式学习多模态表示。
- 任务1:掩码语言建模MLM。取30%的token,采取跨度遮蔽的办法,跨度长度由泊松分布决定(𝜆 = 3 [21, 27])。预训练目标是最大化正确掩码文本标记yl的对数似然,基于一系列损坏的图像tokenX^M和文本tokenY^L的上下文表示(M,L代表掩码的位置)。我们用𝜃表示Transformer模型的参数并且最小化随后的交叉熵损失函数
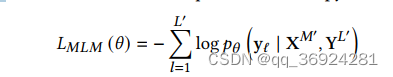
当我们保持布局信息不变时,该目标有利于模型学习布局信息和文本图像上下文之间的对应关系。
- 任务2 掩码图像建模MIM。掩码建模(MIM,MAE)是一种被证明非常有效的自监督训练方法。它通过使用图像的局部信息来生成掩码,并要求模型预测被掩盖的区域。这种方法可以帮助模型学习到更多的视觉特征,提升其表征能力。
- 这是为了推动模型从上下文的文本图像表示中解释视觉内容。MIM目标和MLM目标是对称的,即使用分块掩码(blockwise masking)策略随机遮盖40%的图像token。MIM有交叉熵损失驱动,以在文本和图像token的上下文中重建被掩码的图像标记xm
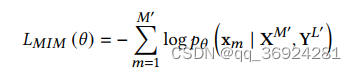
图像token的标签来自于图像标记器,它可以通过一个视觉词汇把密集的图像像素转换为离散的token。因此MIM有利于学习高层布局而不是嘈杂的低层细节。
- 任务3 词-块patch 对齐(WPA)
在多模态任务中,必然会有一个任务是可以将文本与图像产生联系的。
对于文档,每个text对应一个图像块。当我们分别用MLM和MIM时,文本和图像模态之间没有明显的关联学习。因此我们需要一个WPA来学习文本单词和图像补丁之间的颗粒度对齐。WPA的目的是预测一个text所对应的图像块是否被掩盖。具体来说,当对应的图像标记没有被掩码时,我们将对齐标签分配给未掩码的文本标记,否则分配一个未对齐的标签。在计算WPA损失时,我们排除了掩码文本令牌,以防止模型学习掩码文本单词和图像块之间的对应关系。。我们使用一个两层的MLP头,它输入上下文文本和图像,输出具有二进制交叉熵损失的二进制对齐|非对齐标签:
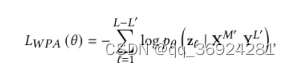
其中L-L’是为掩码文本标记的数量,zt是位于t位置的语言标签的二进制标签。
3实验
3.1模型配置
LayoutLMv3的网络架构遵循v1和v2的网络架构。BASE版本采用12层transformer编码器具有12个头,隐藏层大小D=768,3072中间大小的前馈网络。而LARGE则是16头大小为1024的隐藏层,4096中间大小的前馈网络,24层的transformer编码器。我们使用最大序列长度L=512的字节对编码(BPE)tokenize文本序列。在每个文本序列的开始和结束添加一个【CLS】[SEP】token。当文本序列的长度小于L,我们将【PAD】token追加到其中。这些特殊标记的边界框坐标都是0。图像嵌入的参数是C*H*W=3*224*224,p=16,M=196.
我们使用分布式和混合精度训练以减少内存成本和加快训练。我们也使用梯度累积机制 将一批样本分割为几个小批量。我们还使用梯度检查点技术进行文档布局分析以降低内存成本。为了稳定训练,我们计算attention时,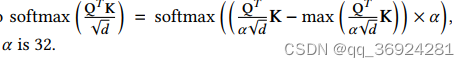
3.2预训练
为了学习各种文档的通用表示,我们在一个大型IIT-CDIP数据集上面预训练LayoutLMv3.这个测试集是一个大规模扫描文档图像数据集。对于多模态transformer编码器和文本嵌入层,使用RoBERTa的预训练权值初始化。而图像标记层则用DiT的预训练图像标记器初始化(这个一个自监督预训练文档图像Transformer模型)。图像token的词汇量为8192。我们随机初始化了剩余的模型参数。使用Adam优化器对模型进行了预训练,进行了50万步,批大小为2048。
权值衰减为1E-2,(𝛽1, 𝛽2) = (0.9,0.98)。BASE的学习率为1E-4,在前4.8%的step对学习率使用线性预热。对于LARGE,学习率和预热率分别为5E-5和10%。
(warmup是针对学习率learning rate优化的一种策略,主要过程是,在预热期间,学习率从0线性(也可非线性)增加到优化器中的初始预设lr,之后使其学习率从优化器中的初始lr线性降低到0。)
3.3多模态任务上的微调
从模型的特征信息:文本(T)、Layout(L)、图像(I),以及图像的特征提取器 Faster R-CNN(R)、CNN Grid(G)、Linear Patch(P)。
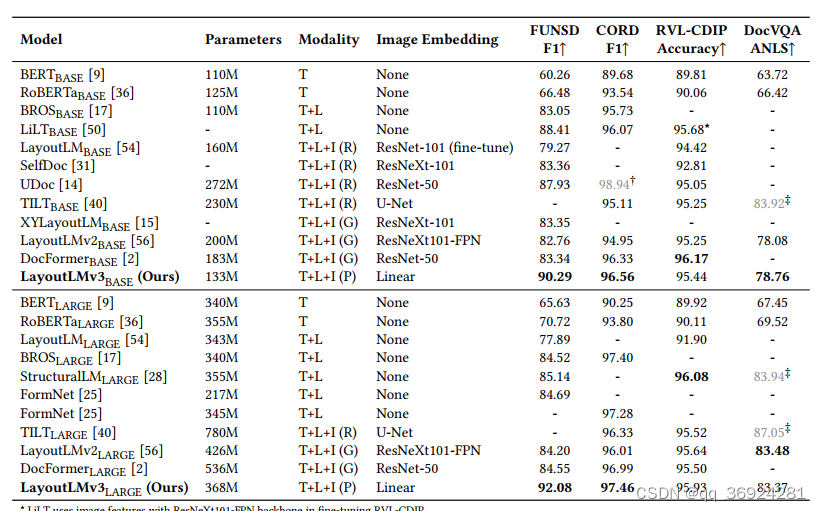
总结
v3 版本,采用了更简单的图像特征输入方式(直接线性投影),并且结合新的图像特征的输入方式设计了一种新的任务用于构建文本与图像之间信息的融合与交互。

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









