



想让YOLOv5识别专属物品吗?本文手把手带你实现自定义数据训练。从数据准备到模型部署,清晰流程助你快速解锁目标检测新技能,赋能你的AI项目。
环境说明:
操作系统:win11
显卡:RTX 4060 8G显存
python:3.9.12
yolov5:7.0 下载
cuda:11.8 cuda 11.8安装教材
torch:2.1.0
torchvision:0.16.0
pycharm:2024.3.4
一、安装环境
打开命令提示符(cmd),切换至yolov5-master目录下,执行下列命令。
pip3 install -r requirements.txt如果在后面运行时还缺包,使用pip3安装。
二、划分数据集
1、下载yolov5-master.zip并解压,将其放置在与datasets相同目录下。目录结构关系如下所示。数据的标注教程可参考博文labelImg的安装和使用。
├─datasets
├─images
└─labels
└─yolov5-master
├─.github
├─classify
├─data
├─models
├─runs
├─segment
├─utils
......
2、在yolov5-master目录下创建data_split.py,将以下内容复制到data_split.py文件中。此代码仅将数据集划分为训练集和验证集,如果还需要测试集,可以自行更改代码。
import os
import random
# 设置随机种子
random.seed(42)
# 路径
data_root = "../datasets/"
image_path = data_root + "images/"
train_txt = open(data_root + 'train.txt', 'w')
val_txt = open(data_root + 'val.txt', 'w')
# 训练集占比80%
train_part = 0.8
# 获取所有图片文件名
images = os.listdir(image_path)
# 计算图片数量
nums = len(images)
# 计算训练集图片数量
train_num = round(nums * train_part)
# 将图片顺序打乱
random.shuffle(images)
#划分数据,将图片名放在train.txt和val.txt中
for i, img in enumerate(images):
if i < train_num: #train
print(image_path + img, file=train_txt, flush=True)
print("train:", img)
else: #test
print(image_path + img, file=val_txt, flush=True)
print("val:", img)
train_txt.close()
val_txt.close()3、打开命令提示符(cmd),切换至yolov5-master目录下,运行data_split.py文件。
python data_split.py
4、运行完成后,打开datasets目录,可以看到多出了两个文件,train.txt和val.txt。
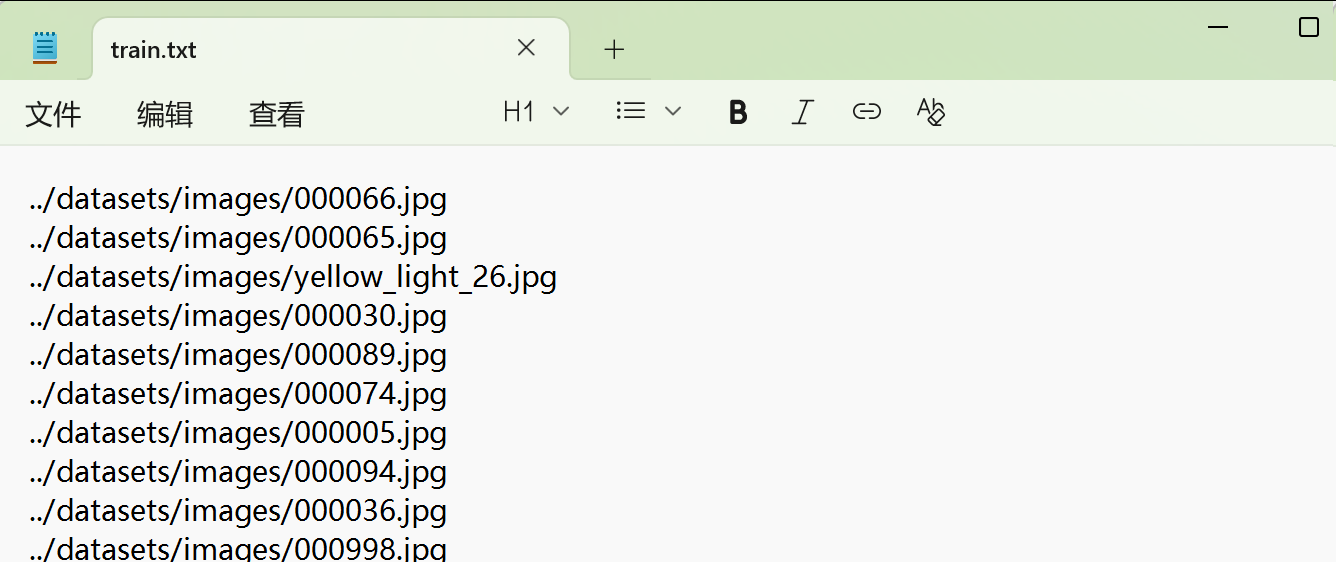
可以打开train.txt查看,文件中保存的是图片的文件名。
三、模型和数据集配置
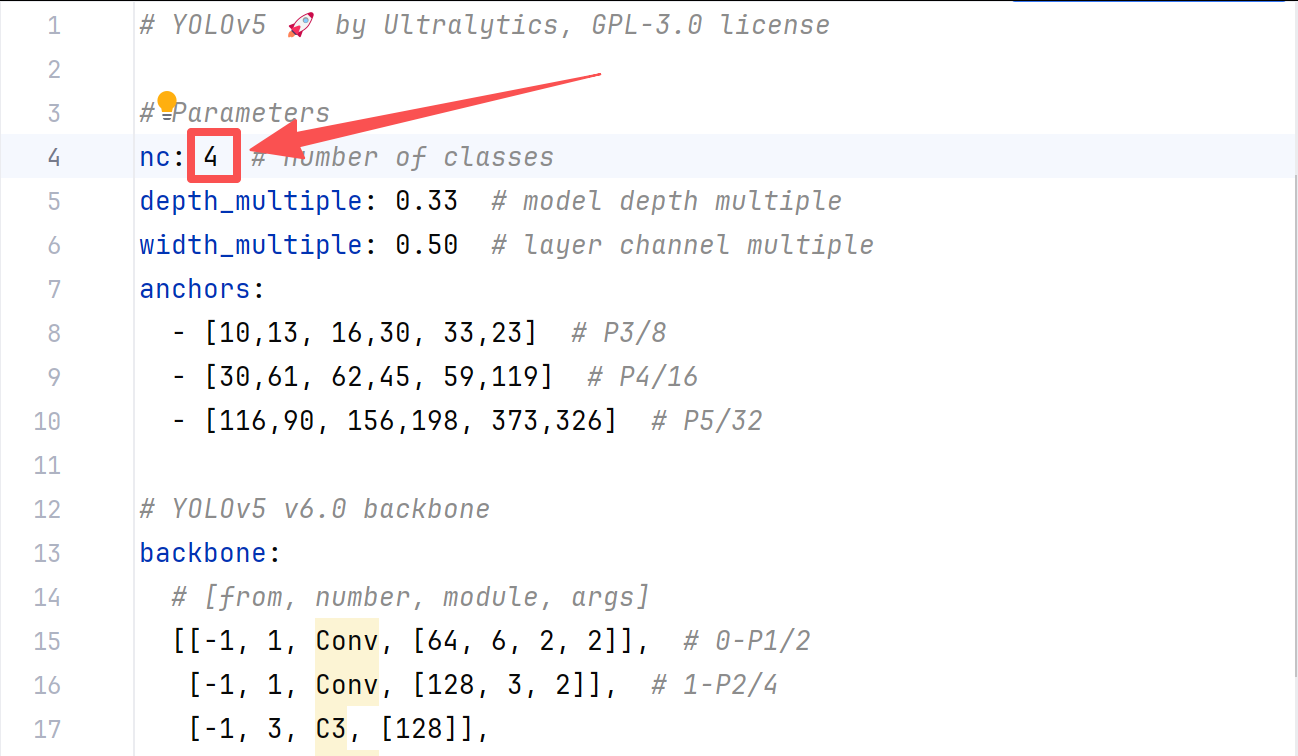
1、配置模型。打开yolov5-master/models/yolov5n.yaml文件,将文件中nc的值改为自己的类别数。我的项目中类别数为4,所以改为了4。可查看datasets/labels/classes.txt中的类别数进行设置。
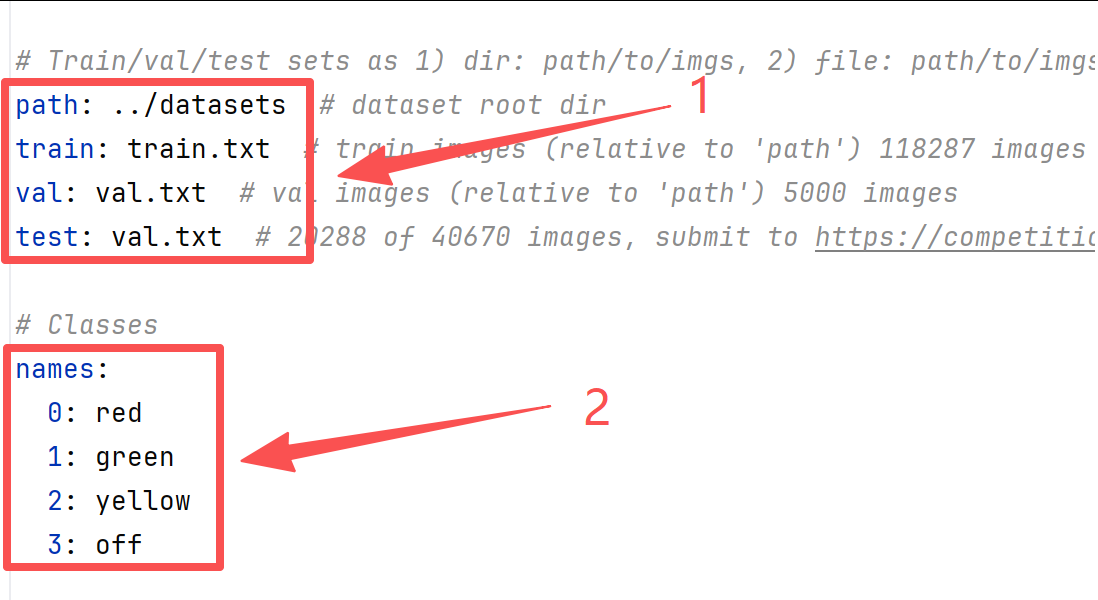
2、配置数据集。打开yolov5-master/data/coco.yaml文件,有两处需要修改,第一处修改数据集如下所示,第二处修改为自己的类名(和datasets/labels/classes.txt类名一致)。
四、模型训练
1、下载预训练模型yolov5n.pt,放置到yolov5-master目录下。
2、启动训练。打开命令提示符(cmd),切换至yolov5-master目录下,执行以下命令。
python train.py --weights=yolov5n.pt --cfg=models/yolov5n.yaml --data=data/coco.yaml --epochs=300 --batch-size=16 --imgsz=640 --device=0 --optimizer=Adam --workers=2
参数说明:
--weights:预训练模型的路径
--cfg:模型配置文件路径
--data:数据集配置文件路径
--epochs:迭代次数
--batch-size:批次大小
--imgsz:图片大小
--device:GPU编号
--optimizer:优化器
--workers:CPU核心数(线程数)
当显示如下内容时,模型就开始训练了。
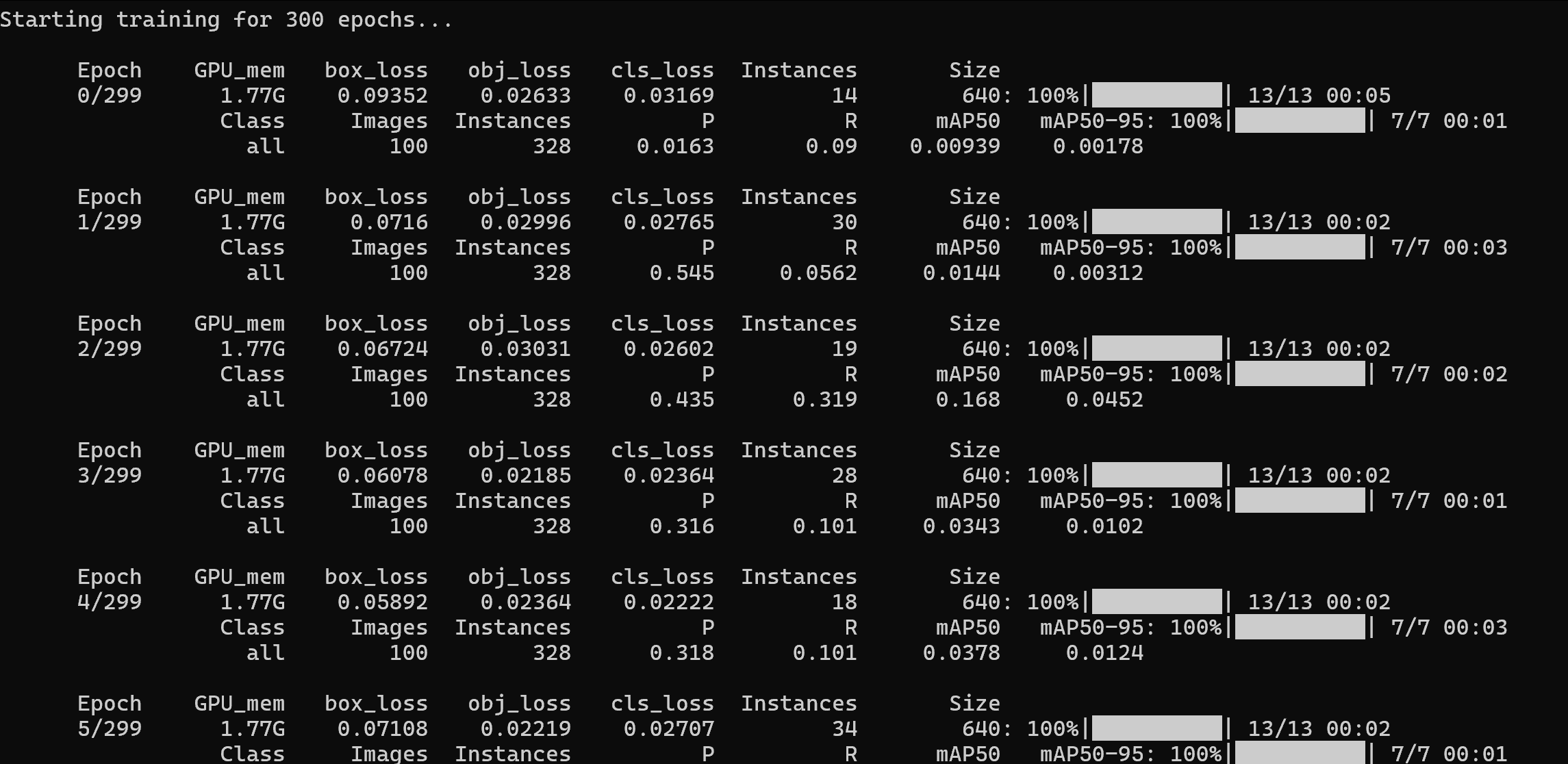
训练结束后,可在yolov5-master\runs\train\exp目录下查看训练过程。每次训练exp序号依次增加,第2次训练目录为exp2。文件夹中保存了训练过程文件results.csv,PR曲线PR_curve.png等数据。
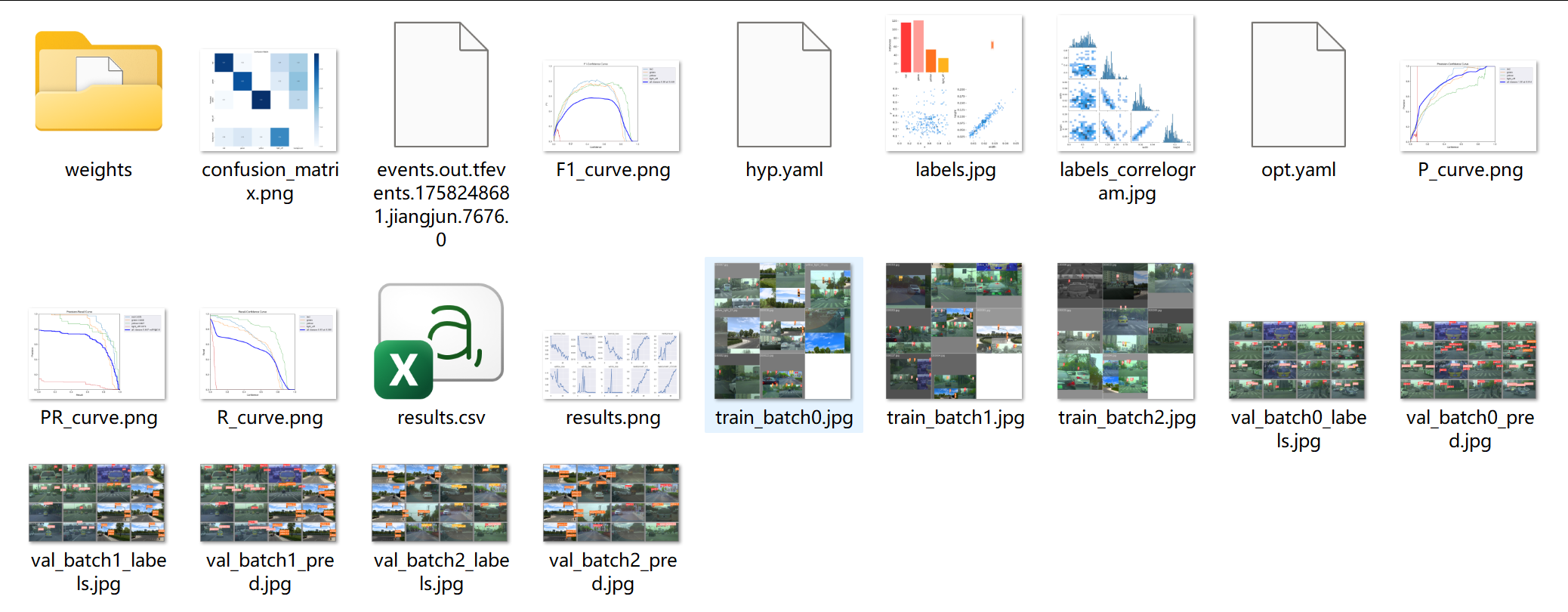
训练好的模型保存至weights目录中,best.pt为训练最好的模型,last.pt为最后一个epoch训练的参数。

四、模型测试
1、继续在命令提示符(cmd)中执行以下命令。
python val.py --weights=runs/train/exp/weights/best.pt --data=data/coco.yaml --batch-size=8 --imgsz=640 --device=0 --workers=2
执行完成后,可以看到如下信息,这些时模型的评价指标。

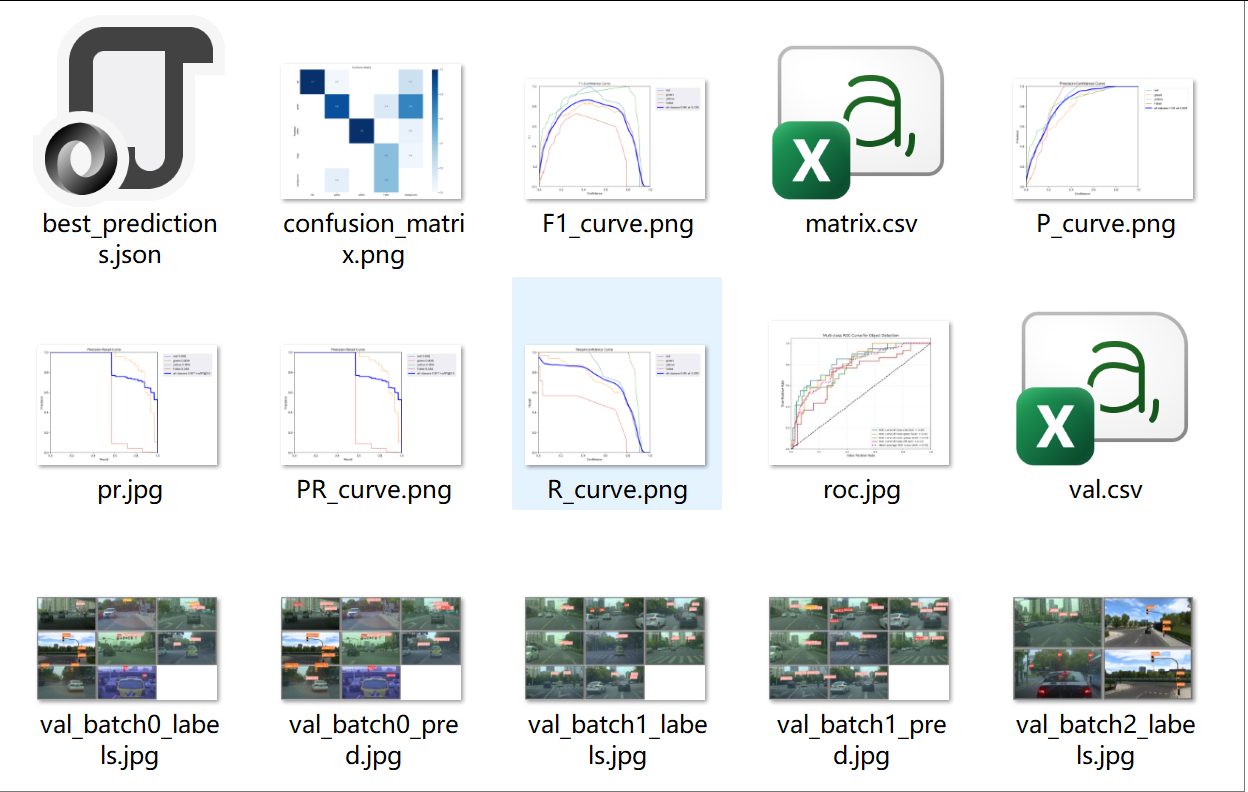
2、关于测试生成的相关文件,存储在yolov5-master\runs\val\exp目录下,包括f1、pr曲线等。
五、将模型转换为onnx格式。
1、在命令提示符(cmd)中执行下列命令。
python export.py --weights=runs/train/exp/weights/best.pt --include=onnx
2、执行完成后,onnx模型保存在yolov5-master\runs\train\exp\weights目录中。

六、模型推理
在命令提示符(cmd)中执行下列命令,即可推理图片或视频。这里需要说明一下--source参数,它的值可以是一张图片、一个装有图片的文件夹、或一个视频文件。
python detect.py --weights=runs/train/exp/weights/best.pt --source=视频.mp4 --data=coco.yaml --device=0



















 2626
2626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









