







【摘要】预训练的大型语言模型(LLM)在多个领域取得了显着的成功。然而,面向代码的法学硕士的计算复杂度很高,并且与输入的长度呈二次方关系。为了简化法学硕士的输入程序,最先进的方法具有根据法学硕士给出的注意力分数过滤输入代码标记的策略。简化输入的决定不应依赖于法学硕士的注意力模式,因为这些模式受到模型架构和预训练数据集的影响。由于模型和数据集是解决方案域的一部分,而不是输入所属问题域的一部分,因此当模型在不同的数据集上预训练时,结果可能会有所不同。我们提出了 SlimCode,这是一种适用于法学硕士的与模型无关的代码简化解决方案,它取决于输入代码标记的性质。作为对包括 CodeBERT、CodeT5 和 GPT-4 在内的 LLM 针对代码搜索和摘要这两个主要任务的实证研究,我们报告称:1)代码的去除率与训练时间的节省率呈线性关系, 2) 分类标记对代码简化的影响可能有很大差异,3) 分类标记对代码简化的影响是特定于任务的,但与模型无关,4) 上述发现适用于范式提示工程和交互式in-情境学习。实证结果表明,SlimCode 在代码搜索和摘要方面的 MRR 和 BLEU 分数方面可以将最先进的技术提高 9.46% 和 5.15%。此外,SlimCode 比最先进的方法快 133 倍。此外,SlimCode 可以将每个 API 查询调用 GPT-4 的成本降低多达 24%,同时仍然产生与原始代码相当的结果。
原文:Natural Is the Best: Model-Agnostic Code Simplification for Pre-trained Large Language Models
地址:https://arxiv.org/abs/2405.11196
代码:https://github.com/gksajy/slimcode
出版:未知
机构: Central University of Finance and Economics, University of Texas at Dallas解析人:公众号“码农的科研笔记”
1 研究问题
本文研究的核心问题是: 如何设计一个模型无关的代码简化方法,以降低预训练大语言模型在代码相关任务中的计算开销。
假设某软件公司要使用GPT-4来对其代码库进行自动化分析和优化。问题是原始代码往往很长,对GPT-4造成巨大的计算负担。如果能设计一种自动化的、与具体模型无关的代码简化工具,在不损失太多语义信息的前提下最大限度地压缩代码长度,就能大幅降低计算成本,让GPT-4更实用。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
代码简化要在保留关键语义信息和删除冗余细节之间取得平衡。过度简化会导致代码失去原本的功能,而简化不足又无法有效降低计算开销。需要精准把握不同类型代码元素的重要程度。
-
预训练语言模型对代码的理解方式因模型架构和训练数据而异。比如CodeBERT和CodeT5在同一份代码上的关注点可能不同。一个通用的代码简化工具应该尽量不依赖具体模型的注意力模式。
-
简化过程本身要尽量轻量高效。如果为了压缩代码而引入大量的额外计算,就有些舍本逐末了。理想的简化算法应以最低的时空开销找出最优的删除方案。
-
要有一套科学的简化原则,并在下游任务上得到实证支持。如何恰当地定义和度量代码元素的重要性,使之与最终的任务性能良好关联,是简化方案成败的关键。
针对这些挑战,本文提出了一种自下而上的"SlimCode"方法:
SlimCode巧妙地利用代码元素的内在属性,而非模型的注意力模式,来指导简化过程。它将代码简化建模为一个0-1背包优化问题。首先,通过大量实证研究,SlimCode发现不同类别的代码元素(如标识符、符号、方法签名等)对下游任务的影响差异巨大,且这种影响具有显著的跨模型一致性。据此,它为每类元素预设了一个重要性等级。接着,它用一个简单而高效的贪心算法,以最少的时间开销找出满足长度约束的最优删除方案。相比于逐个评估每条语句的重要性,SlimCode的做法无需模型的参与,计算效率大幅提升。实验表明,SlimCode可在不损失性能的前提下,把GPT-4的推理成本降低24%。这一思路为进一步提升大语言模型在软件工程领域的实用性开辟了新的道路。
2 研究方法

为了实现与模型无关的代码简化,论文提出了SlimCode技术。SlimCode的核心思想是根据不同类别tokens对预训练模型下游任务性能的影响程度,对代码tokens进行删减,从而在降低计算开销的同时保持较高的任务性能。
2.1 基于tokens类别的代码简化分析
论文首先在CodeBERT、CodeT5和GPT-4三个预训练模型上,通过随机、词法级别、句法级别和语义级别移除tokens的实验,分析不同类别tokens的重要程度。在随机移除实验中,论文发现移除代码比例与训练时间节省呈线性关系。如在CodeBERT上对50%代码tokens做随机移除,代码搜索和总结任务的训练时间分别减少51.5%和31.76%。
接下来,论文分别在词法、句法和语义三个级别移除6类tokens(标识符、符号、控制结构、方法调用、方法签名、程序依赖图外),考察它们对模型性能的影响。实验表明,不同类别tokens的重要性差异显著。如移除51.38%的符号tokens,CodeBERT在代码搜索任务的性能仅下降2.8%。而移除15.48%的标识符,性能则下降12.52%。此外,论文还发现tokens的重要性排序与任务相关但与模型无关。综合实验结果,论文给出了tokens重要性从高到低的排序:
签名标识符控制结构方法调用符号
该结论为后续SlimCode算法设计提供了依据,即应优先移除重要性低的tokens。
2.2 SlimCode的问题表述与求解
SlimCode将代码简化表述为0-1背包问题。设为包含个代码片段的数据集,每个片段由一系列tokens 组成。表示token 的重要性得分,所有tokens的重量设为1。若简化比例为, 则每个片段需移除tokens数为:
其中为简化前代码的长度。SlimCode采用贪心策略求解上述0-1背包问题,伪代码如Algorithm 1所示。
Algorithm 1 SlimCode: 代码简化算法
输入: 数据集 D, 重要性得分 V, 简化比例 SimplifiedRatio, 代码长度 L
输出: 简化后的数据集 D'
1: 将D复制到D'
2: for j = 1 to m do:
3: 初始化removedTokens存储待移除tokens
4: W ← n_j - (1-SimplifiedRatio) × L
5: currentWeight ← 0
6: while currentWeight < W do
7: 将d'_j中不在removedTokens且v值最大的{index:token}加入removedTokens
8: currentWeight ← size(removedTokens)
9: d_j ← d_j去掉removedTokens中的tokens
10: return D
以如下代码为例,设, :
def sum(a, b):
return a + b
若tokens重要性得分为{def:1, sum:1, (:6, ):6, a:2, b:3, ::6, \n:8, :8, return:4, +:7},则SlimCode简化后结果为:
def sum(a b)
return a b
可见,SlimCode优先移除了括号、空格、换行等符号tokens,而尽可能保留标识符、关键字等重要tokens。
3 实验
3.1 实验场景介绍
本文研究了代码简化对预训练大语言模型(PLLM)在代码理解和生成任务中的影响。实验重点关注如何通过移除不同类型的token来降低训练和推理的计算开销,同时尽量保持下游任务的性能。实验涉及两大范式:fine-tuning预训练模型(如CodeBERT和CodeT5),以及prompt+predict(如GPT-4)。
3.2 实验设置
Datasets:采用CodeSearchNet数据集,选取Java语言的代码。对代码搜索和代码总结任务分别构建数据集,具体数据规模见表1。从中采样400个样本用于GPT-4实验,见表2。
Baseline:
-
CodeBERT和CodeT5采用默认超参设置,使用Adam优化器。
-
DietCode为已有的代码简化SOTA方法,移除代码中权重低的token。
-
GPT-4采用OpenAI提供的API,设计prompt进行zero-shot预测。
-
Implementation details:
-
采用JavaParser和JAST2DyPDG工具分别提取代码的AST和PDG。
-
基于token在AST和PDG中的位置,将其划分为signature、identifier、symbol、control structure、method invocation等类别,见表3。
-
设计SlimCode算法,基于token的类别和重要性顺序逐步移除。
metric:
-
简化比例(SimplifiedRatio):移除token占原始token的比例。
-
训练时间、时间减少比例:反映计算效率提升。
-
MRR(代码搜索)、BLEU-4(代码总结):评估代码简化对性能的影响。
环境: CPU为2×Intel(R) Xeon(R) Golden 2.40GHz,GPU为2×Nvidia A100。
3.3 实验结果
实验1、随机移除token的影响(RQ1)
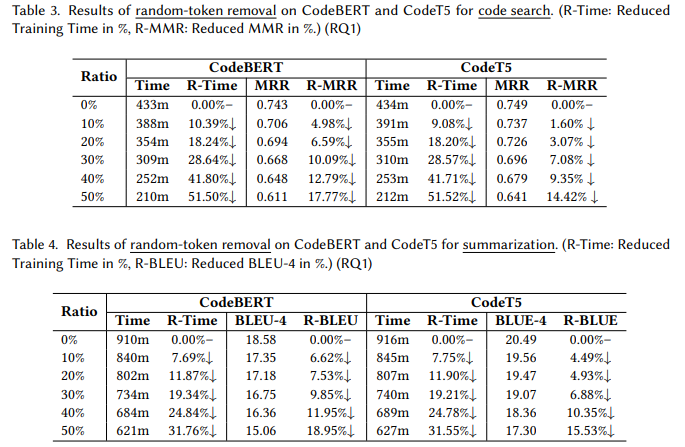
目的:探究随机简化代码对CodeBERT和CodeT5训练时间和性能的影响。
涉及图表:表3、表4
实验细节概述:分别随机移除10%~50%的token,观察训练时间减少率和MRR、BLEU下降情况。
结果:
-
简化比例与训练时间呈近似线性关系,如移除50%token,CodeBERT在代码搜索/总结上训练时间分别减少51.5%/31.76%。
-
CodeT5的结果与CodeBERT类似,但简化后性能略优于CodeBERT。
实验2、移除词法层面token的影响(RQ2)
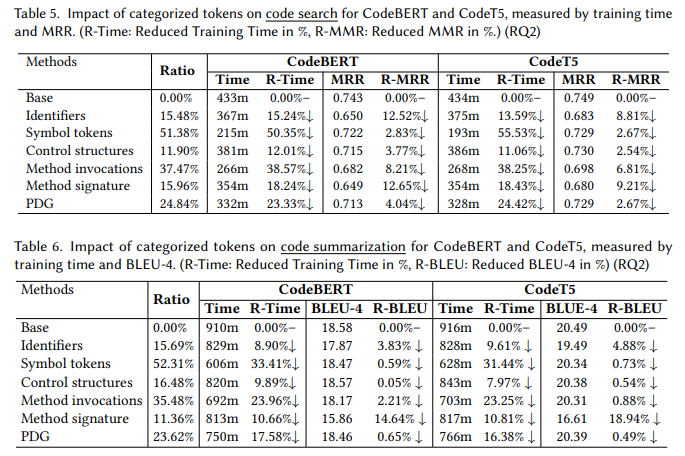
目的:研究移除标识符、符号对CodeBERT和CodeT5的影响。
涉及图表:表5、表6
实验细节概述:利用AST和字符匹配分别定位标识符和符号token,将其全部移除,对比移除前后效果。
结果:
-
移除标识符(占比15%~16%)使MRR下降8%~13%,BLEU下降4%~5%。
-
移除符号(占比51%~52%)仅使MRR下降2%~3%,BLEU下降<1%。
-
标识符蕴含更多语义信息,移除影响更大;符号虽占比高但贡献小,更适合简化。
实验3、移除语法层面token的影响(RQ3)
目的:研究移除控制结构、方法调用、签名token对CodeBERT和CodeT5的影响。
涉及图表:表5、表6
实验细节概述:利用AST定位控制结构、方法调用和签名,分别移除其中token,对比效果。
结果:
-
方法签名的token影响最大,如移除占比11.36%的签名token使CodeT5的BLEU降低18.94%。
-
控制结构、方法调用的token影响适中,高于符号但低于标识符。总体对代码搜索影响更大。
实验4、移除语义非关键token的影响(RQ4)
目的:研究移除不在PDG中token的影响。
涉及图表:表5、表6
实验细节概述:提取PDG,移除代码中不在PDG内的token,分析效果变化。
结果:
-
不在PDG中的token影响较小,虽然占比23%~24%,但MRR和BLEU降低仅4%左右。
-
相比控制结构和调用token影响更小,但高于符号token。
实验5、SlimCode在代码简化中的效果(RQ5)
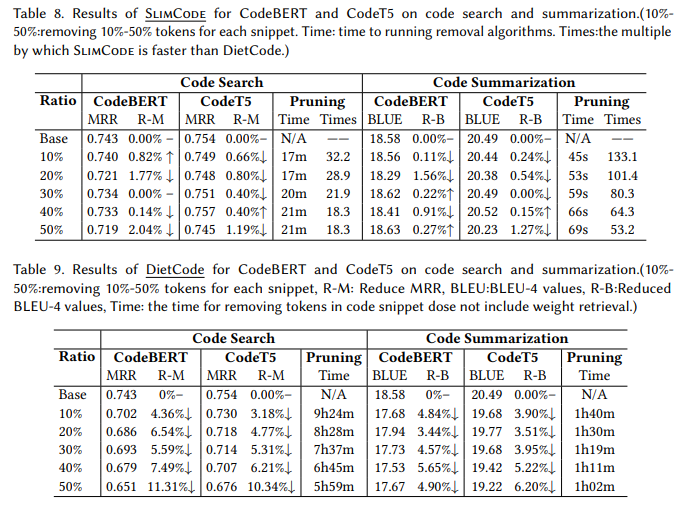
目的:评估SlimCode在简化代码以提升CodeBERT和CodeT5效率方面的表现。
涉及图表:表8、表9、图1
实验细节概述:基于前面实验得出的token重要性,设计SlimCode算法逐步移除token,并与DietCode对比。
结果:
-
SlimCode平均使CodeBERT和CodeT5在代码搜索/总结任务上的MRR/BLEU提升9.46%/5.15%。
-
SlimCode运行速度是DietCode的133倍,因为不需要微调模型来获取token权重。
-
SlimCode移除的95%以上是符号和无关token,而DietCode移除了大量标识符等高价值token。
实验6、SlimCode在GPT-4 zero-shot学习中的效果(RQ6)
目的:验证之前的实验结果是否适用于prompt范式下的GPT-4,并分析SlimCode的效果。
涉及图表:表10、表11
实验细节概述:将不同简化方法用于GPT-4,设计合适的prompt进行zero-shot预测,分析token数、准确率和BLEU。
结果:
-
随着简化比例提高,GPT-4生成的token数和性能整体下降,但变化趋势与CodeBERT/T5略有不同。
-
SlimCode的简化代码在准确率和BLEU上平均超过DietCode 26%和10%,有时甚至优于原始代码。
-
以50%简化比例为例,SlimCode使GPT-4的token数减少27%,API调用费用降低24%,同时准确率提升2.35%。
4 总结后记
本论文针对预训练大语言模型(Pre-trained Large Language Models, PLLM)在代码相关任务中的高计算复杂度问题,提出了一种基于代码token特性的模型无关的代码简化方法SlimCode。通过系统分析不同类型token对模型性能的影响,根据token的重要性对其进行简化,在减少训练和推理时间的同时保持较高的性能。实验结果表明,SlimCode相比现有方法在代码搜索和代码摘要任务上取得了更好的效果,速度也提高了133倍。此外,SlimCode还能降低24%的GPT-4 API调用成本。
疑惑和想法:
-
SlimCode目前只考虑了token级别的简化,能否设计语句级别或更高层次的简化方法?
-
除了文中提到的6种token类型,是否还有其他类型的token值得考虑?如何自动化地挖掘重要的token类型?
-
SlimCode在其他代码相关任务(如代码补全、代码生成等)上的效果如何?能否进一步提升?
-
如何将SlimCode与模型压缩技术相结合,进一步减小模型规模和推理开销?
可借鉴的方法点:
-
基于token特性而非注意力分布进行简化的思想可以推广到其他序列数据上,如自然语言处理中的文本简化任务。
-
将代码简化问题建模为0-1背包问题,并采用贪心算法求解的方法可以应用于其他需要在效果和效率间权衡的场景。
-
考虑不同范式(如"pre-train and fine-tune"和"pre-train, prompt and predict")下方法的适用性,增强方法的泛化性。
-
代码简化可以作为PLLM应用于软件工程领域的一个重要前处理步骤,与其他任务相结合提升整体性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









