







【摘要】估计观测数据的因果效应常常面临选择性偏差引起的协变量偏移问题。近期研究尝试利用表示平衡方法来缓解该问题,其目标是从观测数据中提取平衡模式并用于结果预测。其背后的理论基础是:最小化未观测的反事实误差可以通过两个原则实现:(1)降低预测事实结果的风险;(2)减小处理组和对照组样本之间的分布差异。然而,这两个原则之间存在固有的权衡,可能导致对事实结果预测有用的信息丢失,从而恶化因果效应估计。本文提出了一种新的表示平衡模型DIGNet,用于因果效应估计。DIGNet包含两个关键组件PDIG和PPBR,它们通过改进上述原则而不牺牲另一个原则,有效缓解了权衡问题。具体而言,PDIG捕获更有效的平衡模式(原则2),而不影响事实结果预测(原则1);PPBR则增强事实结果预测(原则1),而不影响平衡模式学习(原则2)。消融实验验证了PDIG和PPBR在改进因果效应估计方面的有效性,基准数据集上的实验结果表明,DIGNet在因果效应估计方面优于基线模型。
原文:DIGNet: Learning Decomposed Patterns in Representation Balancing for Treatment Effect Estimation
地址:https://openreview.net/forum?id=Z20FInfWlm
代码:未知
出版:Transactions on Machine Learning Research (06/2024)
机构: 香港理工大学, 香港城市大学
1 研究问题
本文研究的核心问题是: 如何设计表示学习平衡模型,在协变量偏移情况下准确估计个体因果效应。
::: block-1
假设一个医疗场景,有一组病人数据,其中一部分接受了某种新药治疗(处理组),另一部分没有(对照组)。由于伦理和实践限制,医生倾向于为病情较重的人优先用药,导致处理组和对照组在年龄、病情严重程度等协变量上存在系统性差异。这种选择性偏差使得直接比较两组的治疗结果变得不可靠。如果我们想评估新药对每个个体的因果效应,需要某种方法来应对这种协变量偏移问题。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 个体因果效应定义为对同一个体施加处理和不施加处理两种情况下结果的差异,但在现实中每个个体要么接受要么不接受处理,我们无法同时观测到这两个潜在结果。因此个体因果效应本质上依赖于对反事实结果的估计。
- 传统的机器学习模型在存在协变量偏移时,其对反事实结果的估计会出现偏差。因为处理组(对照组)的特征分布与对照组(处理组)不同,违背了训练数据与测试数据独立同分布的假设。
- 表示平衡方法通过学习一个平衡的表示空间来缓解协变量偏移问题。其理论基础是最小化表示空间中事实风险和处理-对照组分布差异,可以减小反事实误差。但过度追求平衡可能损失对事实结果建模有用的信息,引入权衡。
- 在平衡表示学习过程中,如何在缓解协变量偏移的同时,尽可能保留对结果预测有价值的信息?如何在群体距离和个体倾向混淆两个角度分别刻画平衡模式?不同模式如何更好地融合?这些都是有待进一步探索的问题。
针对这些挑战,本文提出了一种基于分解模式的表示平衡新框架"DIGNet":
::: block-1
DIGNet的核心思想是将平衡表示解耦为群体和个体两个层面,融合不同角度的平衡模式,在互补的同时避免负面干扰。首先,通过理论分析,本文证明了除了经典的Wasserstein距离,H散度也可用于界定反事实和因果效应误差的上限,为个体倾向混淆的平衡学习提供了新视角。基于此,DIGNet引入了两个关键模块:PDIG旨在通过最小化群体距离(基于Wasserstein距离)和个体倾向混淆(基于H散度)来捕获互补的平衡模式,而不影响事实结果预测;PPBR旨在通过保留平衡前的原始表示来增强事实结果建模,而不影响平衡模式学习。这种分而治之、相辅相成的策略,犹如两条腿走路,左右互补,稳健高效。最后,DIGNet将PDIG学到的群体和个体平衡表示与PPBR学到的原始表示巧妙融合,形成一个即兼顾平衡、又不失表达能力的联合表示用于因果效应预测。
:::
2 研究方法
本文提出了一个新的表征平衡模型DIGNet,用于从观测数据中估计个体治疗效应(ITE)。它主要包含两个关键部分:PDIG和PPBR。在详细介绍DIGNet之前,我们先来看一下传统的表征平衡方法。
2.1 传统的表征平衡方法
在因果推断中,我们通常将总体分为两组:接受治疗的个体(treatment group, T = 1 T=1 T=1)和未接受治疗的个体(control group, T = 0 T=0 T=0)。由于非随机的治疗分配机制,这两组个体在协变量 X X X上通常存在分布差异,即 P ( X ∣ T = 1 ) ≠ P ( X ∣ T = 0 ) P(X|T=1) \neq P(X|T=0) P(X∣T=1)=P(X∣T=0) ,这被称为协变量偏移问题。为了缓解这个问题,最近的研究探索了表征平衡方法,旨在从观测数据中提取平衡模式,并利用这些模式来预测结果。这些方法的理论基础是,在表征空间中,最小化反事实误差可以通过两个原则来实现:(I) 最小化预测因果结果的风险;(II) 减少治疗组和对照组的分布差异。我们接下来介绍两个经典的表征平衡模型:GNet和INet。
2.1.1 GNet: 基于群组距离最小化的网络
GNet的目标是通过最小化治疗组和对照组在表征空间中的Wasserstein距离来实现群组距离最小化:
min Φ E , h t L y ( x , t , y ; Φ E , h t ) + α 1 L G ( x , t ; Φ E ) \min_{\Phi_E, h_t} L_y(x,t,y;\Phi_E, h_t) + \alpha_1 L_G(x,t;\Phi_E) ΦE,htminLy(x,t,y;ΦE,ht)+α1LG(x,t;ΦE)
其中 L y L_y Ly表示因果结果的预测损失,对应原则(I); L G L_G LG表示基于Wasserstein距离的群组距离,对应原则(II); Φ E \Phi_E ΦE是特征提取器,将原始协变量 X X X映射到表征空间; h t h_t ht是因果结果的预测器。
直觉上,GNet试图学习一个表征 Φ E ( X ) \Phi_E(X) ΦE(X),使得治疗组 { Φ E ( x i ) } i : t i = 1 \{\Phi_E(x_i)\}_{i:t_i=1} {ΦE(xi)}i:ti=1和对照组 { Φ E ( x i ) } i : t i = 0 \{\Phi_E(x_i)\}_{i:t_i=0} {ΦE(xi)}i:ti=0的Wasserstein距离最小化,同时 Φ E ( X ) \Phi_E(X) ΦE(X)对因果结果 Y Y Y有良好的预测能力。
2.1.2 INet: 基于个体倾向混淆的网络
不同于GNet聚焦于群组层面的距离最小化,INet聚焦于个体层面的倾向混淆。它的目标是学习一个表征 Φ E ( X ) \Phi_E(X) ΦE(X),使得很难根据该表征来判断一个个体接受治疗( T = 1 T=1 T=1)还是未接受治疗( T = 0 T=0 T=0)。INet采用对抗学习的方式来实现这一点:
max π α 2 L I ( x , t ; Φ E , π ) min Φ E , h t L y ( x , t , y ; Φ E , h t ) + α 2 L I ( x , t ; Φ E , π ) \begin{aligned} \max_\pi \quad & \alpha_2 L_I(x,t;\Phi_E,\pi)\\ \min_{\Phi_E, h_t} \quad & L_y(x,t,y;\Phi_E,h_t) + \alpha_2 L_I(x,t;\Phi_E,\pi) \end{aligned} πmaxΦE,htminα2LI(x,t;ΦE,π)Ly(x,t,y;ΦE,ht)+α2LI(x,t;ΦE,π)
其中 L I L_I LI表示个体倾向的交叉熵损失; π \pi π是个体倾向的判别器,它试图最大化将个体正确分类为treatment或control的概率;而特征提取器 Φ E \Phi_E ΦE试图愚弄判别器 π \pi π。最终,平衡的表征使得判别器难以判断个体的倾向,我们称这个过程为个体倾向混淆。
举个例子,假设有一种疫苗可以预防某种疾病。我们将协变量定义为 X X X,接种疫苗( T = 1 T=1 T=1)定义为treatment,未接种( T = 0 T=0 T=0)定义为control,特定抗体水平定义为outcome Y Y Y。如果个体接种了疫苗,我们假设抗体水平为 y = exp ( x ) y=\exp(x) y=exp(x),否则为 y = 0 y=0 y=0。在观测数据中,接种与否( T T T)是根据个体的协变量 X X X来决定的。如下图所示, X X X在treatment组和control组的分布是不同的。在这种情况下,INet试图学习一个表征 Φ E ( X ) \Phi_E(X) ΦE(X),使得仅根据 Φ E ( X ) \Phi_E(X) ΦE(X)很难判断一个个体是接种还是未接种疫苗,即实现个体倾向混淆。
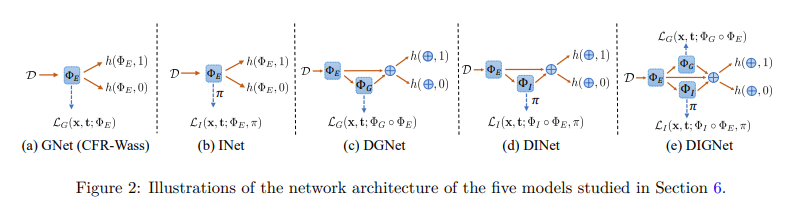
2.2 引入分解模式的表征平衡方法
尽管GNet和INet在表征平衡方面取得了进展,但它们仍然面临因果结果预测和表征平衡之间的权衡问题。强制模型只关注平衡可能会损害因果结果预测的能力。为了缓解这个问题,本文提出了两个关键的方法:PDIG和PPBR。
2.2.1 PDIG: 平衡模式的分解
PDIG的目的是在不影响因果结果预测的情况下,捕获更有效的平衡模式。它将平衡模式分解为两个不同的部分:群组距离最小化(通过Wasserstein距离实现)和个体倾向混淆(通过H-divergence实现)。具体来说:
min Φ G L G ( x , t ; Φ G ∘ Φ E ) min Φ I max π L I ( x , t ; Φ I ∘ Φ E , π ) \begin{aligned} \min_{\Phi_G} \quad & L_G(x,t;\Phi_G \circ \Phi_E)\\ \min_{\Phi_I} \max_\pi \quad & L_I(x,t;\Phi_I \circ \Phi_E,\pi) \end{aligned} ΦGminΦIminπmaxLG(x,t;ΦG∘ΦE)LI(x,t;ΦI∘ΦE,π)
其中 Φ G \Phi_G ΦG用于群组距离最小化, Φ I \Phi_I ΦI用于个体倾向混淆。
直觉上,PDIG试图学习分解的平衡模式 Φ G ( Φ E ( X ) ) \Phi_G(\Phi_E(X)) ΦG(ΦE(X))和 Φ I ( Φ E ( X ) ) \Phi_I(\Phi_E(X)) ΦI(ΦE(X))。群组距离最小化和个体倾向混淆聚焦于平衡的不同方面,它们共同协作产生更有效的平衡表征,而不影响因果结果的预测。
2.2.2 PPBR: 平衡前模式的保留
PPBR的目的是在不影响学习平衡模式的情况下,增强因果结果的预测。这是通过将表征分解为平衡前模式 Φ E ( X ) \Phi_E(X) ΦE(X)和平衡模式 Φ G ( Φ E ( X ) ) , Φ I ( Φ E ( X ) ) \Phi_G(\Phi_E(X)), \Phi_I(\Phi_E(X)) ΦG(ΦE(X)),ΦI(ΦE(X))来实现的。在预测因果结果时,PPBR将平衡前模式和平衡模式进行拼接:
min Φ E , Φ I , Φ G , h t L y ( x , t , y ; Φ E ⊕ ( Φ I ∘ Φ E ) ⊕ ( Φ G ∘ Φ E ) , h t ) \min_{\Phi_E,\Phi_I,\Phi_G,h_t} L_y(x,t,y;\Phi_E \oplus (\Phi_I \circ \Phi_E) \oplus (\Phi_G \circ \Phi_E), h_t) ΦE,ΦI,ΦG,htminLy(x,t,y;ΦE⊕(ΦI∘ΦE)⊕(ΦG∘ΦE),ht)
其中 ⊕ \oplus ⊕表示拼接操作。
这就好比在做蛋糕时,我们将鸡蛋(原始特征)分离成蛋清和蛋黄(平衡前模式和平衡模式)。蛋清主要用于制作蛋白霜(学习平衡表征),而全蛋(平衡前模式+平衡模式)用于制作蛋糕胚(预测因果结果)。鸡蛋的分离使得我们可以分别优化蛋白霜和蛋糕胚,PPBR也是类似的思想。
回到前面疫苗接种的例子。如果我们对 X X X进行不当的平衡,就可能丢失与outcome相关的信息。PPBR试图通过保留一部分平衡前的信息 Φ E ( X ) \Phi_E(X) ΦE(X)来缓解这个问题,使模型能更好地预测因果结果。
2.3 本文提出的DIGNet模型
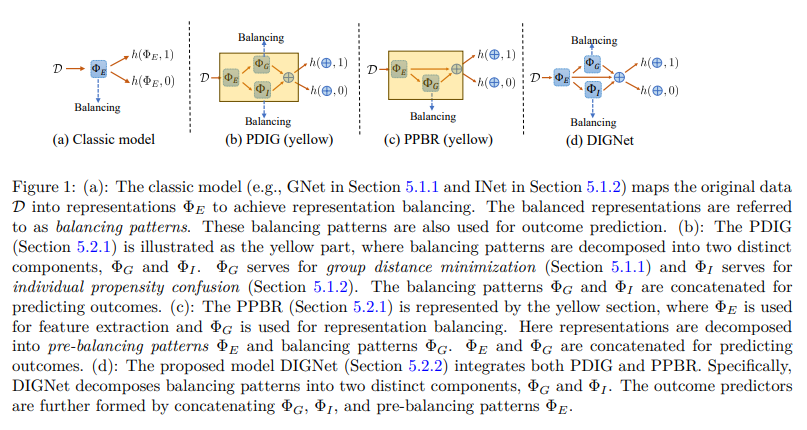
基于PDIG和PPBR,本文提出了DIGNet模型用于估计个体治疗效应。DIGNet的目标函数如下:
min Φ G α 1 L G ( x , t ; Φ G ∘ Φ E ) max π α 2 L I ( x , t ; Φ I ∘ Φ E , π ) min Φ I α 2 L I ( x , t ; Φ I ∘ Φ E , π ) min Φ E , Φ I , Φ G , h t L y ( x , t , y ; Φ E ⊕ ( Φ I ∘ Φ E ) ⊕ ( Φ G ∘ Φ E ) , h t ) \begin{aligned} \min_{\Phi_G} \quad & \alpha_1 L_G(x,t;\Phi_G \circ \Phi_E)\\ \max_\pi \quad & \alpha_2 L_I(x,t;\Phi_I \circ \Phi_E,\pi)\\ \min_{\Phi_I} \quad & \alpha_2 L_I(x,t;\Phi_I \circ \Phi_E,\pi)\\ \min_{\Phi_E,\Phi_I,\Phi_G,h_t} \quad & L_y(x,t,y;\Phi_E \oplus (\Phi_I \circ \Phi_E) \oplus (\Phi_G \circ \Phi_E), h_t) \end{aligned} ΦGminπmaxΦIminΦE,ΦI,ΦG,htminα1LG(x,t;ΦG∘ΦE)α2LI(x,t;ΦI∘ΦE,π)α2LI(x,t;ΦI∘ΦE,π)Ly(x,t,y;ΦE⊕(ΦI∘ΦE)⊕(ΦG∘ΦE),ht)
在每次迭代中,DIGNet通过最小化Wasserstein距离(第一项)来实现群组距离最小化,通过最小最大化H-divergence(第二项和第三项)来实现个体倾向混淆。在预测因果结果时,DIGNet拼接平衡前模式 Φ E ( X ) \Phi_E(X) ΦE(X)和分解的平衡模式 Φ I ( Φ E ( X ) ) \Phi_I(\Phi_E(X)) ΦI(ΦE(X))、 Φ G ( Φ E ( X ) ) \Phi_G(\Phi_E(X)) ΦG(ΦE(X))。
总的来说,DIGNet巧妙地结合了PDIG和PPBR。PDIG负责学习分解的、更有效的平衡模式,而PPBR负责在此过程中保留预测因果结果的信息。它们相互配合,共同提升了个体治疗效应的估计性能。
3 实验
3.1 实验场景介绍
在非随机观测数据中,由于缺乏反事实信息,真实的处理效应无法获得。因此论文使用模拟数据和半合成基准数据来测试所提出方法和其他基线模型的性能。实验主要探究三个问题:
- PDIG是否有助于通过路径一(Path I,即学习更有效的平衡模式而不影响因果结果预测)来改善ITE估计?
- PPBR是否有助于通过路径二(Path II,即在不影响学习平衡模式的情况下改善因果结果预测)来改善ITE估计?
- 在基准数据集上,所提出的DIGNet模型能否优于其他基线模型?
3.2 实验设置
- Datasets:
- Simulation data: 通过改变数据生成策略中的γ参数模拟不同程度的选择偏差
- Semi-synthetic data: 使用IHDP基准数据集,该数据集展现了由于非白人母亲的子群体在治疗组中被排除而导致的协变量偏移
- Baseline: GNet, INet, DGNet, DINet
- Implementation details:
- 在消融研究中,为确保公平比较,所有模型的超参数在所有数据集上保持一致
- 所有模型都采用了提前停止(early stopping)规则
- metric: 常用指标
- 环境: Dell 7920服务器,1个16核Intel Xeon Gold 6250 3.90GHz CPU和3个NVIDIA Quadro RTX 6000 GPU
3.3 实验结果
实验一、模拟数据上不同模型性能随选择偏差程度的变化
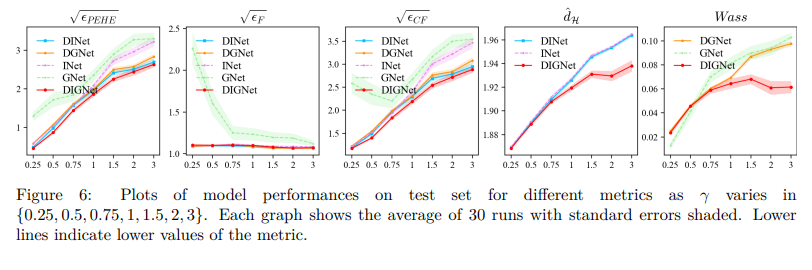
目的: 观察选择偏差程度γ的变化对GNet、INet、DGNet、DINet和DIGNet性能的影响
涉及图表: 图6
实验细节概述:
- 遍历γ ∈ {0.25, 0.5, 0.75, 1, 1.5, 2, 3}生成具有不同选择偏差程度的数据集
- 对每个γ重复生成30个不同的数据集,按56%/24%/20%的比例划分为训练/验证/测试集
- 在测试集上评估不同模型的√ϵPEHE、√ϵCF、√ϵF、Wass和ˆdH指标
结果:
- DIGNet在所有数据集上的√ϵPEHE最低,GNet性能最差
- DINet和DGNet在√ϵCF和√ϵPEHE上优于INet和GNet
- INet、DINet和DGNet在因果结果估计(√ϵF)上与DIGNet性能相当,但在反事实估计(√ϵCF)或ITE估计(√ϵPEHE)上不如DIGNet
- 当选择偏差严重时(γ>1),DIGNet相比DINet和INet(或DGNet和GNet)取得了更小的ˆdH(或Wass)
实验二、消融实验:研究PDIG和PPBR对ITE估计的改进
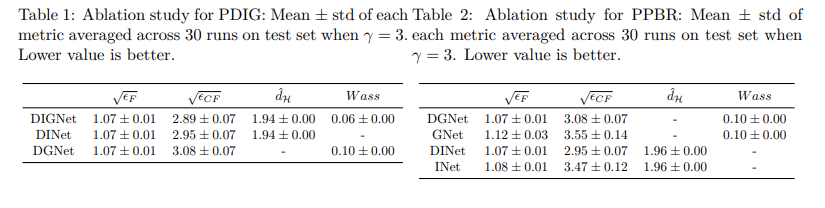
目的: 探究PDIG和PPBR分别通过Path I和Path II提升ITE估计的机制
涉及图表: 表1,表2,表3
实验细节概述:
- 针对高选择偏差的情况(γ=3),在测试集上比较不同模型的性能指标(表1,2)
- 记录30次训练和测试中的平均性能指标(表3)
- 对比GNet vs. DGNet、INet vs. DINet、DGNet vs. DIGNet、DINet vs. DIGNet的性能提升显著性(表5)
结果:
- PDIG: 在不影响因果结果预测的情况下,学习到更有效的平衡模式。相比DINet和DGNet,DIGNet在学习平衡模式上(ˆdH或Wass)和估计反事实结果(√ϵCF)及处理效应(√ϵPEHE、ϵAT E)上表现更优
- PPBR: 在不影响学习平衡模式的情况下,改善因果结果预测。相比INet(或GNet),DINet(或DGNet)在估计因果结果(√ϵF)、反事实结果(√ϵCF)及处理效应(√ϵPEHE、ϵAT E)上表现更优
- 显著性分析发现GNet vs. DGNet、INet vs. DINet、DGNet vs. DIGNet的差异具有统计学意义
实验三、IHDP基准数据集上的比较
目的: 评估DIGNet在IHDP基准数据集上相比其他因果推断模型的性能
涉及图表: 表4,表6
实验细节概述:
- 在1-100个IHDP数据集上进行消融实验,比较各模型的√ϵPEHE和ϵAT E(表4)
- 在1-1000个IHDP数据集上,将DIGNet与其他因果模型进行比较(表6)
结果:
- 消融实验表明,PDIG和PPBR都有利于处理效应估计,与之前的发现一致
- 与其他模型相比,DIGNet在测试样本的√ϵPEHE和ϵAT E上分别降低了21%和7.7%的误差,展现出稳健的优势
4 总结后记
本论文针对观察数据中存在的协变量偏移(covariate shift)问题,提出了一种表征平衡模型DIGNet用于个性化治疗效应估计。DIGNet通过两个关键组件PDIG和PPBR,在不牺牲对结果预测的情况下学习更有效的平衡模式,同时在不影响学习平衡模式的情况下提高了对事实结果的预测。消融实验验证了PDIG和PPBR在改善治疗效应估计方面的有效性,基准数据集上的实验结果表明,DIGNet在治疗效应估计方面优于基线模型。
::: block-2
疑惑和想法:
- 除了Wasserstein距离和H-divergence,是否存在其他形式的表征平衡度量指标?不同指标在理论性质和实践效果上有何区别?
- 本文主要关注二值治疗(binary treatment)场景,如何将所提出的方法推广到多值治疗(multi-value treatment)或连续治疗(continuous treatment)场景?
- 能否将表征学习与其他因果推断方法(如双稳健估计double robust estimation)相结合,进一步提升个性化治疗效应估计的性能?
:::
::: block-2
可借鉴的方法点: - 利用分解表征(decomposed representation)的思想来优化表征学习目标,可以推广到其他因果推断或者域自适应场景。
- 在对比学习损失中同时考虑个体水平(individual-level)和群体水平(group-level)的平衡,这一思路可用于指导表征学习。 (推荐)
- 巧妙融合预平衡表征(pre-balancing representation)和平衡表征(balancing representation)来改善下游任务的想法值得借鉴,可以应用于多视图表征学习等。
:::
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









