







Streamlit框架的定制化
最近做了一个关于streamlit框架的项目,颇有感触,所以在这里记录一下。
什么是streamlit?
Streamlit 是一个python的WEB UI库,它做了高度的封装以便于不懂后前端开发的人员也能轻松构建画面。你可以从官网进行详细的了解:https://docs.streamlit.io/library/api-reference 。
我的第一感受是,画面美观,很方便可以集成调用python的模块,不用像以前通过 ajax+web服务器的方式,省了很多麻烦。但是同时也会有一些问题,比如,定制化完成画面的布局等等,就会非常需要考验人的想象力了。
看完本文你能够了解到什么?
我将从实际遇到的问题入手,去探究如何去使用Streamlit 完成一些定制化的需求。
- Streamlit 的执行原理和流程
- Streamlit 如何自定义CSS
- Streamlit 如何嵌入执行js
- Streamlit 静态资源
- Streamlit 布局问题
- Streamlit 录音组件
- Streamlit 事件如何处理
Streamlit 的执行原理和流程
用我不太专业的说法来讲就是,不论画面做了任何动作,streamlit都会从头到尾执行一次。
是的,这就代表当画面交互变得复杂,你需要很强的逻辑能力才能够驾驭,不然你可能会遇到各种问题。
Streamlit 如何自定义CSS
这部分其实官方有提到,参考以下代码即可实现:
global_css = open("bfs/global.css", encoding="utf-8").read()
st.markdown(f"""<style>{global_css}</style>""", unsafe_allow_html=True)
建议紧跟在 st.set_page_config 语句之后,因为代码总是自上而下执行,可以确保后续布局渲染时可以立即应用上css, 不然可能会出现 先出现布局后,位置再发生变化的情况。
另外,顺带分享一个两个选择器——索引选择器(官方可能不这么说)和属性选择器。
Section[data-testid='stSidebar'] div[data-testid='stVerticalBlock'] > div:nth-of-type(1){
position: absolute;
top: -80px;
width: 130px;
height: 35px
}
Section[data-testid='stSidebar'] 用于选中session元素属性 data-testid=‘stSidebar’ 的元素,div:nth-of-type(n) 用于选中 第 n 个div元素,注意这里的 n 从 1 开始。
这两个选择器基本上能够满足 streamlit 的布局需求。
如何嵌入执行js
官方也提到过,请参考以下代码:
global_js = open("bfs/global.js", encoding="utf-8").read()
st.components.v1.html(f"""<script >{global_js}</script>""", height=0, width=0)
这部分需要特别注意,使用这种方式实际上会在画面中 追加一个iframe 去执行我们的js代码。
但是 iframe 是完全独立的环境,这会导致你js获取dom元素会找不到,所以需要使用以下的代码跳出 iframe。
let _document = window.parent.document;
在文件开头加入这句话,然后后续就可以使用 _document 愉快的使用js操作画面啦。
Streamlit 静态资源
这部分可以在自动 streamlit app时加入 --server.enableStaticServing=true 参数。
streamlit run frontend/app.py --browser.gatherUsageStats=False --server.enableStaticServing=true
它会将相对位置的 static 目录挂在为静态资源目录。这里的目录会指定为 frontend/static。
请确保该文件夹存在。
项目启动成功以后,你就可以通过 http://xxx.xxx.xxx.xxx:xxxx/app/static/ 去访问该静态资源了。
这为我们布局提供了一些便利性,为什么这么说?
当我们需要向画面中添加一些图片的icon时,我个人在streamlit 有种解决方案:
1、通过 streamlit 的图片组件将图片放到画面上,然后通过 css 去调整布局。
# 全局css
global_css = open("bfs/global.css", encoding="utf-8").read()
st.markdown(f"""<style>{global_css}</style>""", unsafe_allow_html=True)
# 添加图片
st.image(Image.open("static/img/record.png"))
这种方式经实践是可行的,但是存在一些问题,画面加载时会有先展示原布局,然后才会被应用上css,另外st.image 生成的布局嵌套比较深,对于css定位不说麻烦,但是相对比较繁琐。最后偶尔会出现css应用不上去的情况,原因不明。
2、开启静态资源服务,由js完成图片icon的添加(推荐)
相对于第一种方式,我们需要开启静态资源服务,也就是本章节开始的部分。
然后后你可以定位到你需要的元素,去追加 img 元素,同时 可以指定 class,用于定位。
例:
let is_assistant = st_msg.querySelector("div[data-testid='stChatMessageContent']");
if (is_assistant) {
if (is_assistant.getAttribute("aria-label").indexOf("from assistant") !== -1) {
let img_ele = _document.createElement("img");
img_ele.src = src;
img_ele.width = 35;
img_ele.height = 35;
img_ele.classList.add("copy");
img_ele.addEventListener("click", function() {
img_ele.classList.add("hidden");
const textarea = _document.createElement('textarea');
_document.body.appendChild(textarea);
textarea.textContent = img_ele.parentElement.innerText;
textarea.select();
if (_document.execCommand('copy')) {
_document.execCommand('copy');
// alert("copy success!")
_document.body.removeChild(textarea);
display_copied(img_ele);
}
});
st_msg.append(img_ele);
上述代码是定位到 div[data-testid='stChatMessageContent'] 元素并追加图片的示例,同时设定了class并且添加了点击事件。
这种方式经实践比较稳定,已投入使用,未出现方式一中提到的问题。敬请参考。
Streamlit 布局问题
如何用Streamlit 实现我们想要的布局是一个问题,官方有一些组件可以使用。
https://docs.streamlit.io/library/api-reference/layout
其中 st.sidebar、st.columns、st.container 这三个基本上就可以完成我们需要的布局。
需要注意的点是,默认使用 st.* 是会加到整体的画面上的,我们以使用 with 关键字,这种情况下,会被加到 with 所在的容器当中。
例:
with st.sidebar:
# 2023/11/20 張 Add Start
st.image(Image.open(f"{static_dir}/img/logo.jpg"))
上述代码中的 logo.jpg 就会被加到 侧边栏当中。
或者 在使用 container 等容器时,你可以先实例化一个 container,然后添加到容器。
例:
msg_container = st.container()
msg_container.image(Image.open(f"{static_dir}/img/logo.jpg"))
这样 logo.jpg 就会被加到 msg_container 中。
建议将需要的组件都分类装到各自的container中,这样会省不少事儿。
Streamlit 录音组件
这个部分,也有一些坑。这里就推荐一下吧~
1、 audio-recorder-streamlit
https://pypi.org/project/audio-recorder-streamlit/
示例代码:
import streamlit as st
from audio_recorder_streamlit import audio_recorder
audio_bytes = audio_recorder()
if audio_bytes:
st.audio(audio_bytes, format="audio/wav")
效果:

2、streamlit-audiorecorder
https://pypi.org/project/streamlit-audiorecorder/
示例代码:
import streamlit as st
from audiorecorder import audiorecorder
st.title("Audio Recorder")
audio = audiorecorder("Click to record", "Click to stop recording")
if len(audio) > 0:
# To play audio in frontend:
st.audio(audio.export().read())
效果:

3、streamlit-audiorec
https://pypi.org/project/streamlit-audiorec/
示例代码:
import streamlit as st
from st_audiorec import st_audiorec
wav_audio_data = st_audiorec()
if wav_audio_data is not None:
st.audio(wav_audio_data, format='audio/wav')
效果:
这种方式虽然很炫酷~ 但是经测试,整合到项目之后非常慢,不知道原因。
目前笔者使用的是 第二种方式。
Streamlit 事件如何处理
这么说吧~ 我觉得Streamlit 没有所谓的事件处理,它所有的动作都会触发整个apps重新加载。
由于这一机制,你只能保存状态,通过flag去做处理。
例:
import streamlit as st
from audio_recorder_streamlit import audio_recorder
audio_bytes = audio_recorder()
if audio_bytes:
text = "识别后的文字"
st.write(text)
st.button("TEST")
上述是一段代码,模拟用户语音输入后识别文字,然后显示在文本框中。
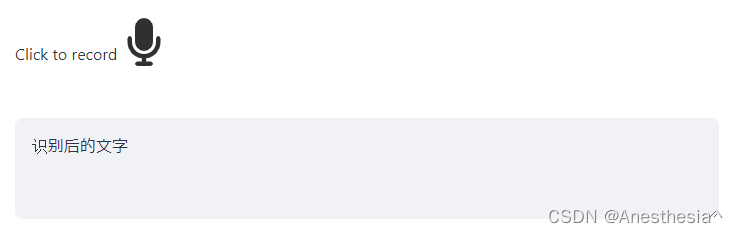
然而,当我清空文本框之后,它又会出现。
细心地小伙伴会发现是 if audio_bytes: 这个判断条件的问题,清空文本框后 录音内容并未被清空,所以当它被重新加载时又会出现。
清空不就好了?很遗憾,目前我无法做到,当然有经验的小伙伴可以共有一下。
这里采用迂回使用flag配合js的方式来实现。

如上图所示,追加了一个录音按钮和录音图标,由 录音图标 去控制开始结束录音,完成录音时同时点击录音按钮 完成flag的设定。
当然录音图标的 追加与点击逻辑 由js实现,这部分我就不细说了。
最后判断 需要的识别条件就可以设置成该flag。
示例代码:
import streamlit as st
from audio_recorder_streamlit import audio_recorder
if "record_flag" not in st.session_state:
st.session_state["record_flag"] = False
if "text" not in st.session_state:
st.session_state["text"] = ""
audio_bytes = audio_recorder()
if st.session_state["record_flag"]:
st.session_state["text"] = "识别后的文字"
st.session_state["record_flag"] = False
st.text_area(label="", key="text")
def record():
st.session_state["record_flag"] = True
st.button("Record", on_click=record)
用这种思路可以实现相对于比较复杂的逻辑。
另外,由于 streamlit 的刷新机制,某些情况下是部分刷新,这部分,我没太明白,导致某些情况下达不到我们预期的效果;比如笔者遇到的问题,需要给 chatgpt 回答的内容添加点击事件,但是用户发消息时并未触发 js的运行,导致事件没绑定上。
这种情况,可以使用js的 观察者对象,监听Dom元素的变化。
示例代码:
const msg_observer = new MutationObserver((mutationsList, observer) => {
add_copy_icon();
});
// 配置观察选项
const msg_config = { attributes: false, childList: true, subtree: true };
let msg_container = _document.querySelector('section.main .block-container');
msg_observer.observe(msg_container, msg_config);
这样做了之后,一旦 msg_container 元素发生变化就会执行 add_copy_icon 方法,以刷新监听事件。
以上就是本次关于 Streamlit 的使用心得,基本上能够应对 Streamlit 各种复杂的需求 ,当然你可以选择使用 Streamlit 的自定义组件去解决该问题,不在本次的讨论范畴。
欢迎大家留言探讨!


















 5995
5995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











