







背景
泛化指,模型不仅在训练集表现良好,在未知数据(测试集)也表现良好,即具有良好的泛化能力。(模型会出现过拟合overfitting或者欠拟合underfitting的问题)。正则化,目的是要同时让经验风险和模型复杂度都较小,是对模型的一种规则约束。
显示正则化
1. 提前终止模型训练
2. 多个模型集成融合(Dropout:有n个节点的神经网络,可以看做是2**n个模型的集成;Dropout connect是随机去掉链接,可以看做2**边数量 模型的集成;等)
3. K折验证

参数正则化
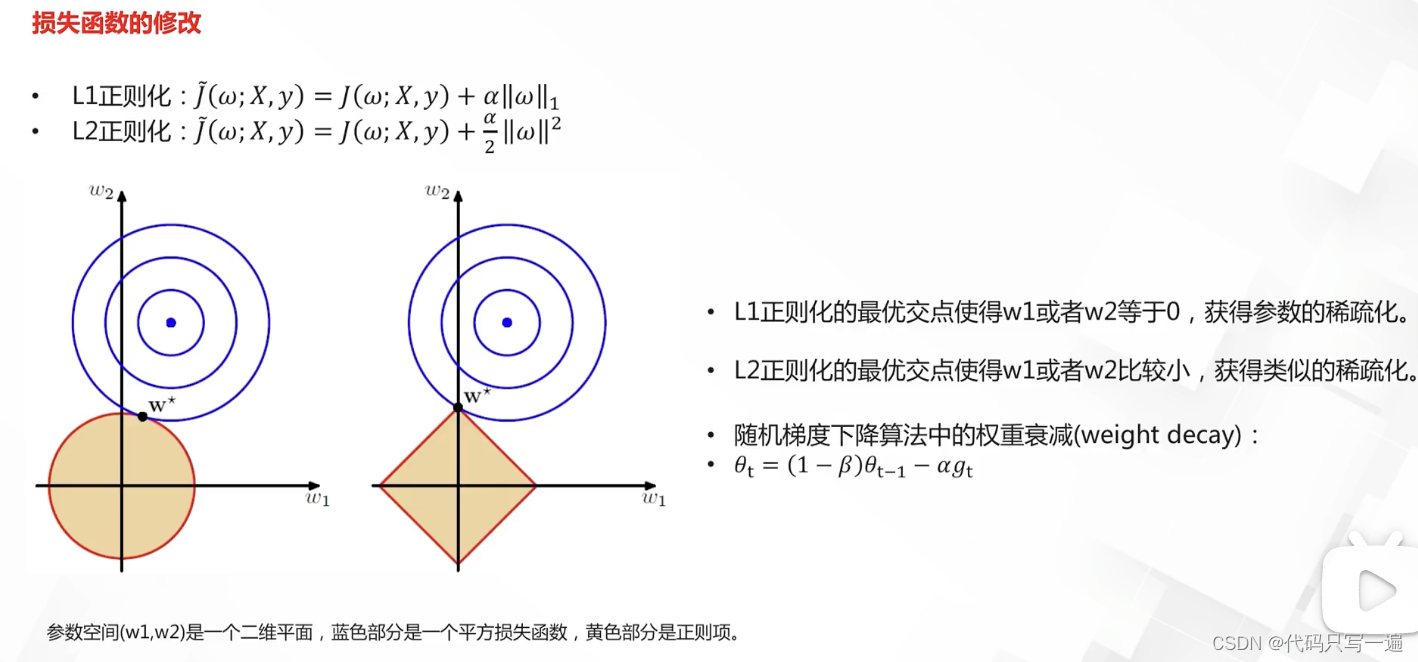
(L1 参数系数等于更稀疏, L2 得到类似的稀疏化 参数数值较小)
权重衰减和L2在某些情况下很类似,但在某些优化器(特别是那些不基于梯度下降的优化器,如Adam)的上下文中,权重衰减和L2正则化的实现略有不同:
-
权重衰减:
- 在某些现代优化器中,权重衰减是直接在权重更新步骤中应用的。它是一个独立的步骤,与计算梯度和应用梯度更新(如动量项)分开。
- 这种方法的好处是,它保留了优化器的其它属性,如动量项不受正则化的影响。
-
L2正则化:
- L2正则化通常在计算梯度时被考虑进去。梯度计算会包括损失函数对权重的导数,加上正则化项对权重的导数。
- 在这种情况下,正则化项直接影响梯度的计算,可能会影响优化器的其他属性(如动量)。
隐式正则化
没有直接对模型进行正则化,但间接对模型获得泛化能力
1. 数据标准化;(标准化和归一化不太相同,标准化是与数据同分布)



2. 数据增强,扩大数据集规模
3. 随机梯度下降算法,不同优化过程获得不同结果
4. 标签噪声 















 2983
2983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









