







Attention is all you need
参考文献
1. 总体结构

2. 每一块结构的详细解释
输入编码(Byte Pair Encoding, BPE & Positional Encoding, PE)
BPE不会鉴别单词出现的前后关系,PE的作用就是感应 same words with different positions,使得transformer block可以区别。
输入的表示矩阵 X = BPE+PE ,X_{n*d} = n个单词,d是表示向量的维度
单词的embedding可以有很多种方法获取,BPE其中一种,还可以Word2Vec, Glove.

Transformer Block - Encoder端
输入:输入input层的输出(输入表示矩阵X) 或者 前一层Encoder的输出
X_{n*d} or C --> 编码矩阵 C _{n*d}
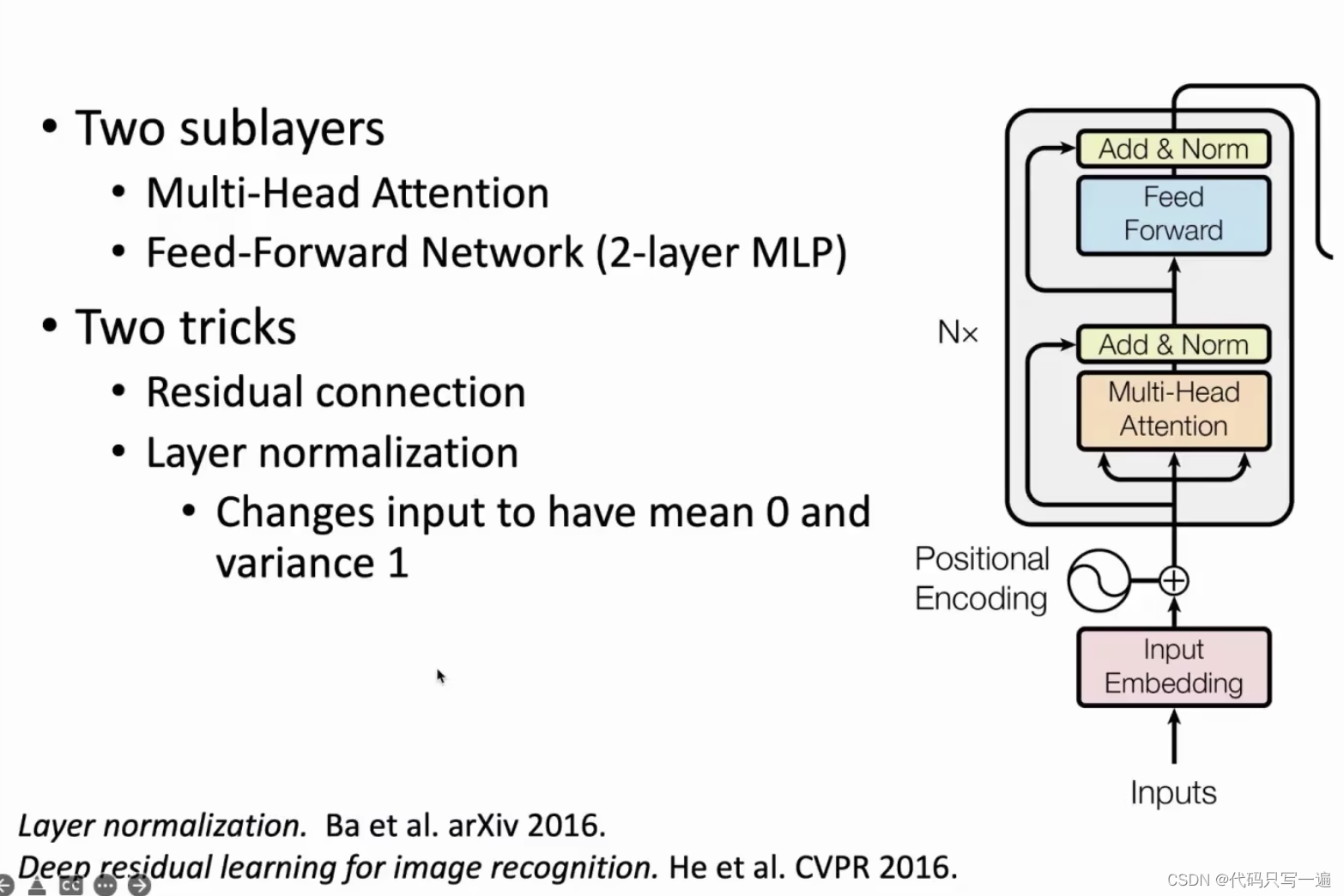
*tricks的作用是针对梯度消失和爆炸的问题。
Multi-Head Attetion 是由多个Self-Attention组成的,其结构如下:

与RNN的attention一样,但增加了一项key K. 其中,Q和K是互不干扰的,可以并行计算。
Q,K,V就是一个矩阵乘以输入向量X,从文本得到。

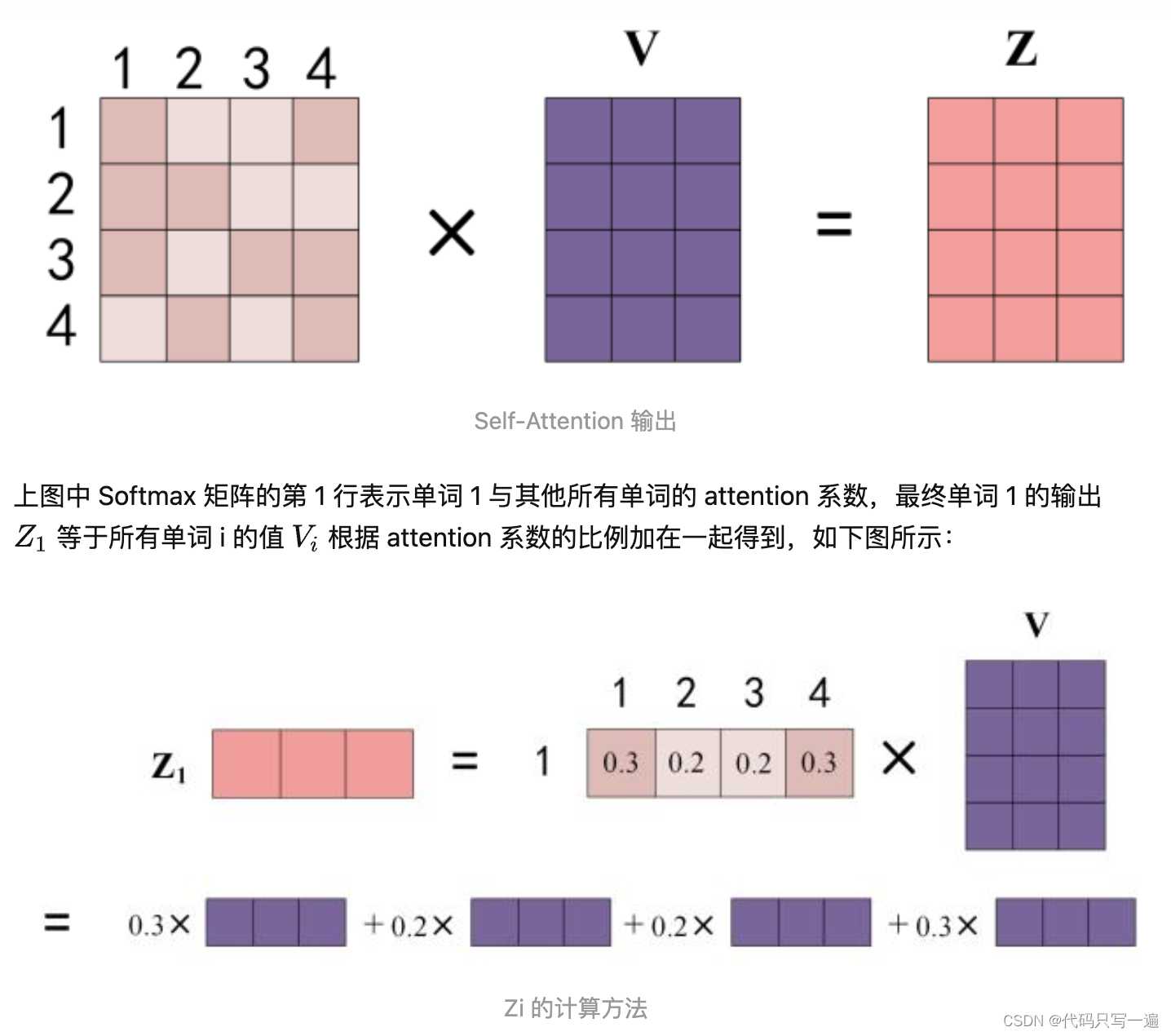
Attention distribution matrix 的每一行 表示 单词1 与其他所有单词的attention系数。

Multi-head Attention
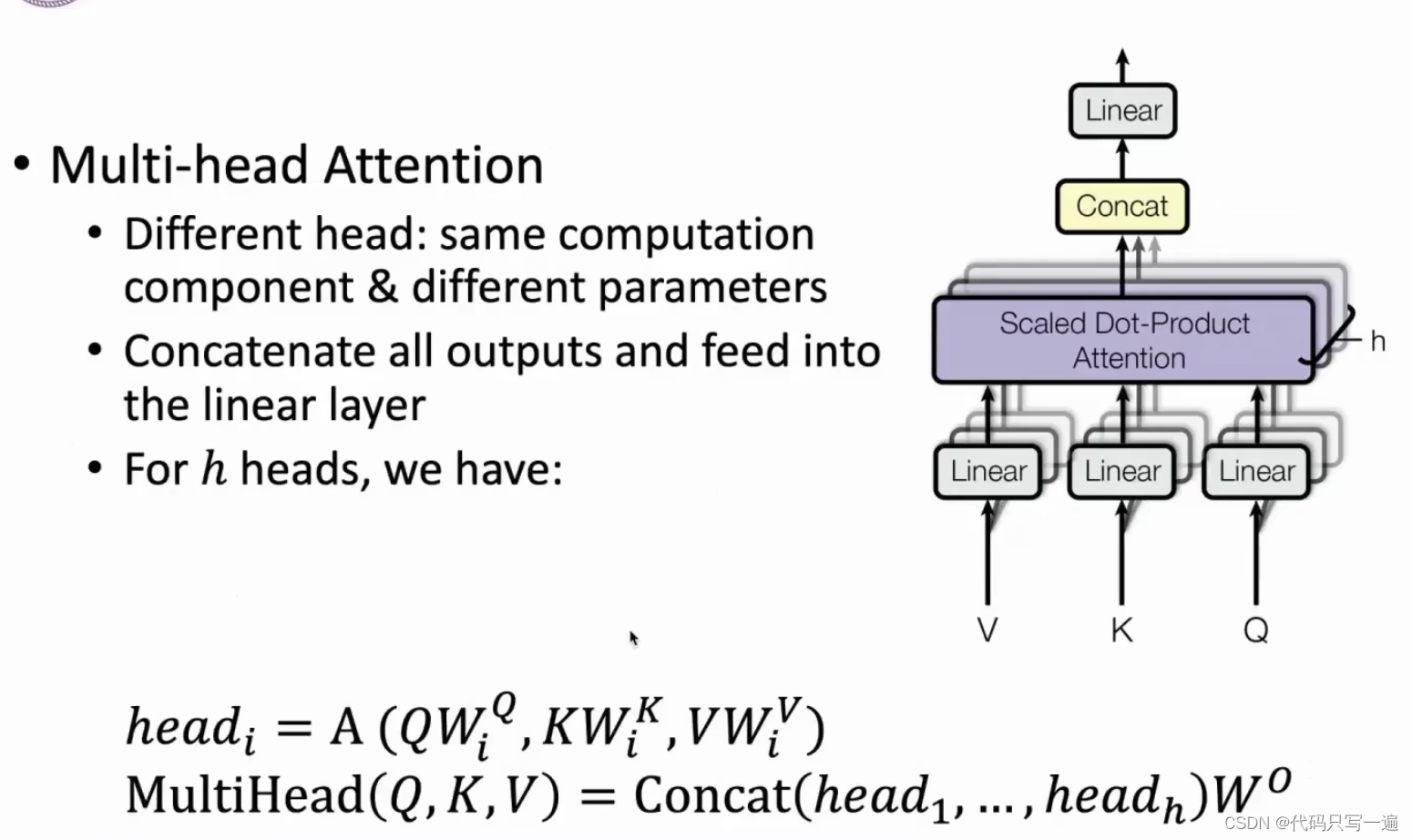
concat(head1, .., head h) * W = head.shape,可以看到multi-head attention输出的矩阵Z与其输入矩阵X的维度是一样的。
Transformer Block - Decoder 端
接收encoder的编码矩阵C_{n*d},然后首先输入一个翻译开始符"<begin>",预测第一个单词“I”;然后输入翻译开始符"<begin>"和单词“I”,预测单词“have”,以此类推。
与Encoder block类似,但存在一些区别:
- 包含两个multi-head attention层;
- 第一层multi-head采用了masked的操作;
- 第二层K,V矩阵使用encoder的编码矩阵C计算,而Q使用上一个Decoder block的输出计算;
- 最后有一个softmax层计算下一个翻译单词的概率。

Mask 上三角部分变为负无穷,softmax后概率变为0,就是不关注后面的words,只看前面的。

3. 使用Tricks

4. 优缺点
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









