







写在前面:
第三堂课是关于Agent的构建,可能是之前的博文学习llama3时进行过agent的能力体验,感觉这堂课还是比较轻松。
也借助这个机会,重温了一遍agent,也翻阅了一些文章,了解了下ReAct,碰巧最近本地部署了qwen-7b-int4的模型,所以本博文就记录下将教程中的大模型替换成qwen的输出样貌以及其他前面博文没提到的内容。
依旧是先放上课程链接:
React的论文链接:
一位大佬的Agent解读:
1、ReAct介绍
ReAct(Reasoning and Acting,推理+行为),一种用于语言模型的新方法,专注于将推理和行动融合在一起。(其实也是一种提示词工程)
推理部分有助于模型进行归纳、跟踪和更新行动计划,并处理异常情况;而行动部分则使模型能够与外部信息源(知识和环境)进行交互,以收集所需信息。
为什么使用:
- 一步步操作(相当于做数学题给出详细的做题步骤),提高了模型的可解释性和可信度。
- 提升大模型处理复杂问题的能力。
- 一定程度上解决的大模型的幻觉问题(模型在处理输入时可能会产生一些看似合理但实际上是错误的输出),
- 在与思维链(CoT)结合使用时,可以帮助解决推理错误,减少推理错误传播。(CoT是一种提示词工程,对于复杂的推理问题,细化分解为一系列小的简单的问题)
- 通用且灵活。ReAct适用于具有不同动作空间和推理需求的多种任务。
- 高性能且稳健。对新任务展现出强大的泛化能力。
- 符合直觉,易于设计。
(既然大家都用这个图,我也附上这个)

原理:
通常Agent与环境交互解决问题时,在时间步时,Agent对当前的环境的观察结果为
,然后遵循策略
执行动作
,其中
,即历史环境的观察及动作。当历史上下文与动作的映射很不清晰时,学习一个策略是较难的。
而ReAct在Agent的动作空间添加语言空间进行扩充,
,新动作
在语言空间中,也被称为思想或者推理痕迹,它不会影响外部环境。ReAct结合新动作和上下文信息进行推理来支持接下来的动作。
纯个人理解:
ReAct说白了就是走一步看一步,可以类比成以下场景:
- 一个侦探,直接得到真相太难,但可以在案发现场不断地发现线索,并带着线索(大模型的上下文)一步步换原案件的原貌,找到凶手。
- 一个动态规划过程,如熟知爬楼梯,每次只能上一个或者两个台阶,那么上到第三个台阶的方案可以是在第一个台阶上两步或者第二个台阶上一步。(后一个的输入需要前一个的计算结果,有点像RNN)
- 一个分治过程,同时做多个不相干不交叉的事情,最后把这些事情的结果梳理整合返回,如发动机、车架等零部件生产互不相关,最后由工人(大模型)拼装成完整的汽车。
2、Agent 与 LLM
再次看Agent,就主要说说关于LLM和Agent新的认识吧:
Agent主要是为了弥补下LLM的一些缺点:
- 会产生幻觉
- 结果不一定可靠真实
- 对时事了解有限或者是未知
- 处理复杂问题较难
Agent可以借助工具、利用外部知识库、长短期记忆来应对LLM的不足。
此外,LLM主要是依靠prompt与用户进行交互,prompt的清晰程度会影响LLM的回答程度效果;二Agent仅需要给一个目标,并通过多方配合,进行思考并给出行为结果。
3、结合课程的Agent实战
在魔搭社区逛模型时候,看到了Qwen7b-chat-int4模型,就本地部署了下。
主体程序感觉还算简单,打开课程链接看相关的Tiny-agent代码应该很容易懂,这里主要想要记录的是程序中的关于ReAct的提示:
# 工具的描述
TOOL_DESC = """{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters} Format the arguments as a JSON object."""
# ReAct的提示词
REACT_PROMPT = """Answer the following questions as best you can. You have access to the following tools:
{tool_descs}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
"""DataWhale的课程中使用的是谷歌的搜索工具,但是我不管怎样都没能注册上,所以逛了逛百度的开发者平台,用了个IP城市查询的接口工具代替(有白嫖的次数),同时需要正则表达式来提取ip。
def baidu_ip_search(self, ip_search: str):
url = 'http://gwgp-gskkegngtuu.n.bdcloudapi.com/ip/city/query'
mat = r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"
ip = re.search(mat, ip_search)
params = {}
if ip is None:
return ""
params['ip'] = ip.group()
# print(params)
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'X-Bce-Signature': 'AppCode/百度的AppCode'
}
response = requests.request("GET", url, params=params, headers=headers)
# print("res", json.loads(response.content))
res = json.loads(response.content)
return res["data"]["result"]["prov"] + res["data"]["result"]["city"]当不问相关需要调用工具的问题时,比如问及“北京的景点有哪些”,还是会调用工具:
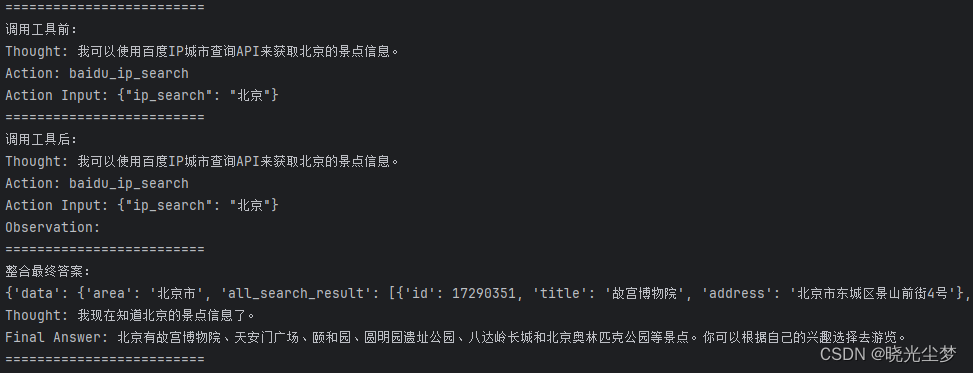
当问及相关问题(随便写个ip),但是把工具屏蔽时,调用返回的是结果是:

当问及相关问题(随便写个ip),启用IP城市查询的工具,调用的返回是:
















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









