







写在前面
这是该系列最后一堂课,主要是对比评测模型的好坏程度,给模型进行打分。
对于大模型来说,输出结果纷杂,也会导致评测的指标也有众多选择。本文也主要学习下相关的评测指标,先不将评测作为现阶段学习的重点。等自认为大模型的学习有一定成果后再进一步研究。
依旧是先放上课程链接:
一、相关评测指标
说到评测指标,最先想到的就是AUC、F1、威尔科克森符号秩检验,也是之前写小论文以及毕设时用到的,借此机会又了解到一些其他指标,就一并放上来整理下。
1、AUC
说到AUC,就不得不提到混淆矩阵(一切罪恶的起源)。
| 标记为正 | 标记为负 | |
| 实际为正 | 真正例(TP) | 假反例(FN) |
| 实际为负 | 假正例(FP) | 真负例(TN) |
| TPR(真正例率)= TP /(TP+FN),也叫召回率、查全率(Recall) FPR(假正例率)= FP/(FP+TN) ACC(准确率) = (TP + TN)/(TP + FN + FP + TN) Precision(精准率)= TP/(TP + FP) |
||
然后,以FPR为横坐标,TPR为纵坐标,就可以绘制ROC曲线(接受者操作特征曲线)。
那么如何根据FPR和TPR绘制曲线呢?
对于二分类问题,假设有100个评测目标,借助模型,可以得到这100个目标的评测分数。依次以这100个评测分数作为阈值进行二分类,那么就有了100次的分类判断结果(也就是有100对FPR和TPR的计算结果,即100个点),将这100个点进行绘制,就得到ROC。
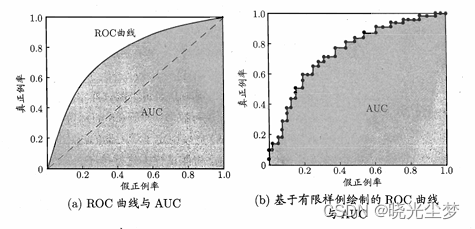
图片来自西瓜书
而AUC就是ROC曲线下的面积。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









