







本文中利用步长为1,卷积核大小为1的卷积代替多层感知机。
def build(self, input_shape):
self.channel = input_shape[-1] #[B,H,W,C]去除通道数
self.MLP1 = layers.Conv2D(filters=self.channel//self.chanel, kernel_size=1, strides=1, activation="relu")
self.MLP2 = layers.Conv2D(filters=self.channel, activation="sigmoid", kernel_size=1, strides=1)
Squeeze(压缩):通过全局平均池化操作(全局最大池化也行)将输入特征图压缩成一个向量。这个向量具有和输入特征图相同的通道数,但每个通道只有一个值,这个值可以看作是对应通道的特征图的全局平均描述。
x = layers.GlobalAveragePooling2D()(inputs)
x = layers.Reshape((1, 1, self.channel))(x)
Excitation(激励):使用一个或多个全连接层(通常是瓶颈结构,即先降维再升维)对这个压缩后的向量进行处理,以生成一个和输入特征图通道数相同的权重向量。这个权重向量中的每个元素表示对应通道的注意力权重,值越大表示该通道越重要。
x = self.MLP1(x)
x = self.MLP2(x)
Scale(缩放):将激励步骤得到的权重向量与原始输入特征图进行逐通道相乘,实现对原始特征图的重新加权。这样,网络就能够更加关注重要的特征通道,而忽略不重要的通道。
x = inputs*x完整代码:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras import layers, Sequential
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape((-1, 28, 28, 1)) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
class Se_Block(layers.Layer):
def __init__(self, reduction=16, way="Max"):
super(Se_Block,self).__init__()
self.reduction = reduction
self.channel = None
self.MLP1 = None
self.MLP2 = None
self.way = way
def build(self, input_shape):
self.channel = input_shape[-1] #[B,H,W,C]去除通道数
self.MLP1 = layers.Conv2D(filters=self.channel//self.channel, kernel_size=1, strides=1, activation="relu")
self.MLP2 = layers.Conv2D(filters=self.channel, activation="sigmoid", kernel_size=1, strides=1)
def call(self, inputs, *args, **kwargs):
if self.way == "Average":
x = layers.GlobalAveragePooling2D()(inputs)#压缩
x = layers.Reshape((1, 1, self.channel))(x)
x = self.MLP1(x)#降维
x = self.MLP2(x)#升维
if self.way == "Max":
x = layers.GlobalMaxPool2D()(inputs)
x = layers.Reshape((1, 1, self.channel))(x)
x = self.MLP1(x)#降维
x = self.MLP2(x)#升维
if self.way =="combination":
x1 = layers.GlobalMaxPool2D()(inputs)
x2 = layers.GlobalAveragePooling2D()(inputs) # 压缩
x1 = layers.Reshape((1, 1, self.channel))(x1)
x2 = layers.Reshape((1, 1, self.channel))(x2)
x1 = self.MLP1(x1)#降维
x1 = self.MLP2(x1)#升维
x2 = self.MLP1(x2)#降维
x2 = self.MLP2(x2)#升维
x = x1+x2
x = inputs*x #scale
return x
model = Sequential([
layers.Conv2D(filters=16, kernel_size=3, strides=2, activation='relu', input_shape=(28, 28, 1)),
Se_Block(way="combination"),
layers.Flatten(),
layers.Dense(10, activation="softmax")
])
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=32)
SE模块即插即用,可以随意放置。本文只是简单的实现了一下,所以只用了一层卷积。
各个版本se测试,最终可以看出组合版的其实要好一点点。 但是手写数字这个数据集太简单,看不出太大差距。
最大池化:
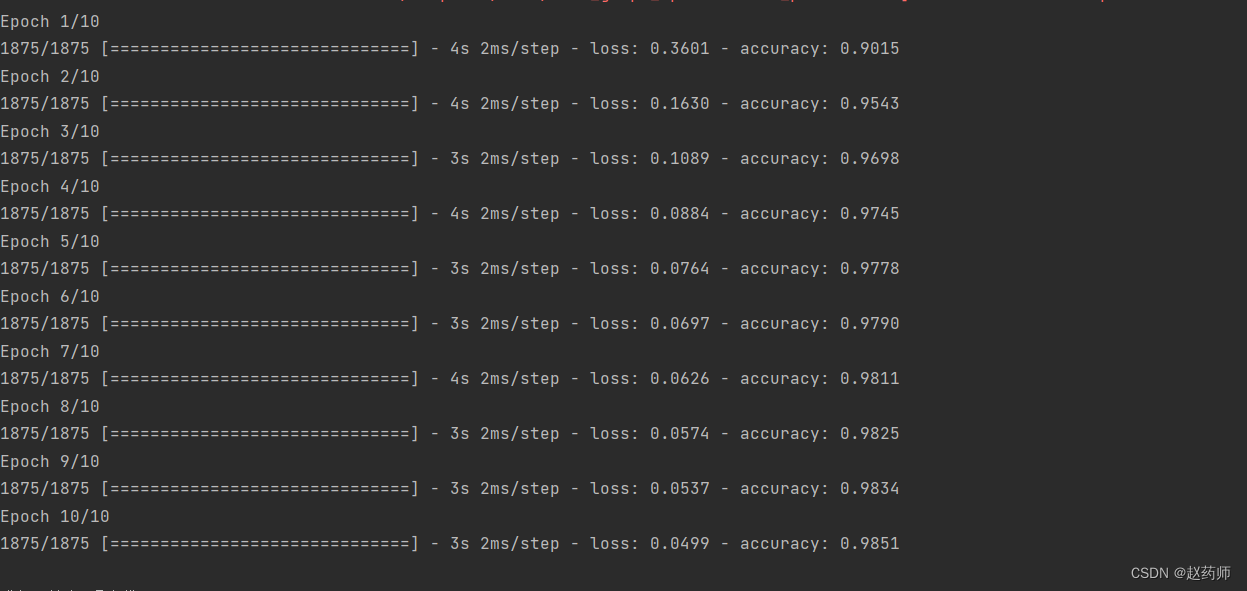
平均池化:
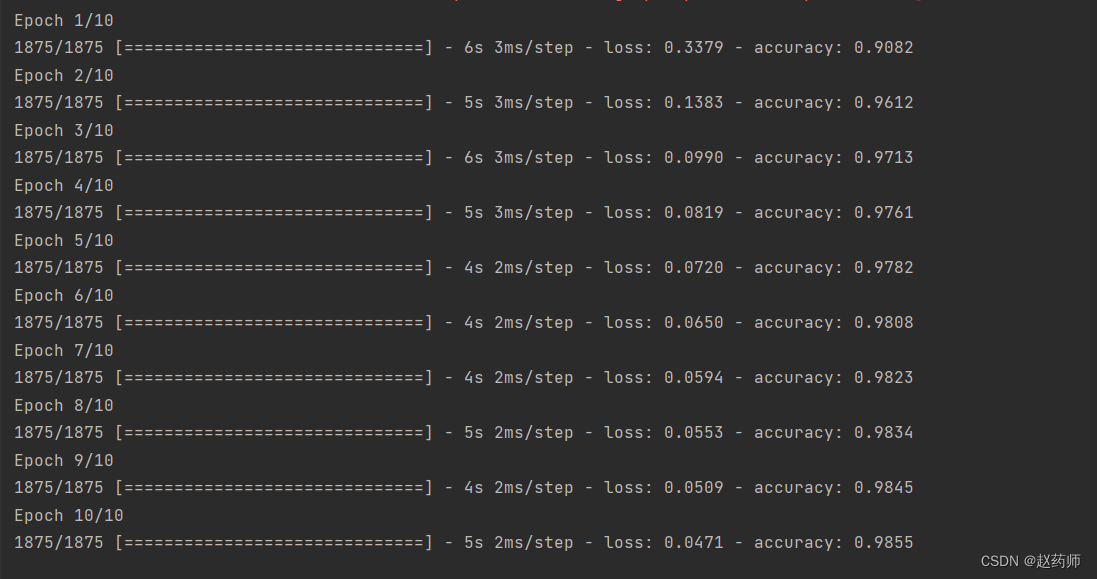
组合版:

加上空间注意力机制
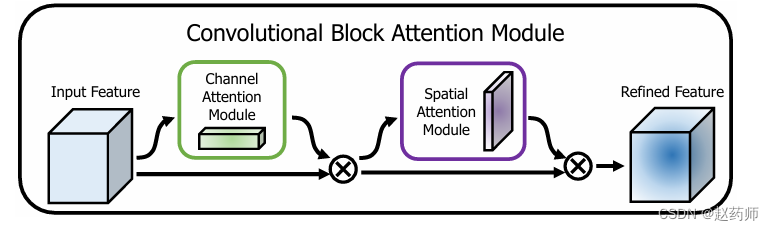
有2种实现方式,直接卷积,或着沿着通道维度池化后再卷积。
实现第二种方式,第一种太简单了就不实现了。
代码:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras import layers, Sequential
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape((-1, 28, 28, 1)) / 255.0
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
class Se_Block(layers.Layer):
def __init__(self, reduction=16, way="Max"):
super(Se_Block,self).__init__()
self.reduction = reduction
self.channel = None
self.MLP1 = None
self.MLP2 = None
self.way = way
def build(self, input_shape):
self.channel = input_shape[-1] #[B,H,W,C]去除通道数
self.MLP1 = layers.Conv2D(filters=self.channel//self.channel, kernel_size=1, strides=1, activation="relu")
self.MLP2 = layers.Conv2D(filters=self.channel, activation="sigmoid", kernel_size=1, strides=1)
def call(self, inputs, *args, **kwargs):
if self.way == "Average":
x = layers.GlobalAveragePooling2D()(inputs)#压缩
x = layers.Reshape((1, 1, self.channel))(x)
x = self.MLP1(x)#降维
x = self.MLP2(x)#升维
if self.way == "Max":
x = layers.GlobalMaxPool2D()(inputs)
x = layers.Reshape((1, 1, self.channel))(x)
x = self.MLP1(x)#降维
x = self.MLP2(x)#升维
if self.way =="combination":
x1 = layers.GlobalMaxPool2D()(inputs)
x2 = layers.GlobalAveragePooling2D()(inputs) # 压缩
x1 = layers.Reshape((1, 1, self.channel))(x1)
x2 = layers.Reshape((1, 1, self.channel))(x2)
x1 = self.MLP1(x1)#降维
x1 = self.MLP2(x1)#升维
x2 = self.MLP1(x2)#降维
x2 = self.MLP2(x2)#升维
x = x1+x2
x = inputs*x #scale
return x
class SpatialAttention(layers.Layer):
def __init__(self):
super(SpatialAttention, self).__init__()
self.conv2d = layers.Conv2D(filters=1, strides=1, kernel_size=3, padding="same", activation="sigmoid")
def call(self, inputs, *args, **kwargs):
MAX = tf.reduce_max(inputs, axis=-1)#[B,w,h,channel],沿着最后一个维度:通道,取最大值,得到的维度为【B,w,h】
MAX = tf.expand_dims(MAX, axis=-1)#增加通道维度,[B,h,w,1]
average = tf.reduce_mean(inputs, axis=-1)#同上述一样
average = tf.expand_dims(average, axis=-1)
combine = tf.concat([MAX, average], axis=-1)#[B,h,w,2]
x = self.conv2d(combine)#[B,h,w,1]
return inputs*x
model = Sequential([
layers.Conv2D(filters=16, kernel_size=3, strides=2, activation='relu', input_shape=(28, 28, 1)),
Se_Block(way="Average"),
SpatialAttention(),
layers.Flatten(),
layers.Dense(10, activation="softmax")
])
model.summary()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=32)
空间注意力机制与通道注意力机制的三种版本组合就不演示了。
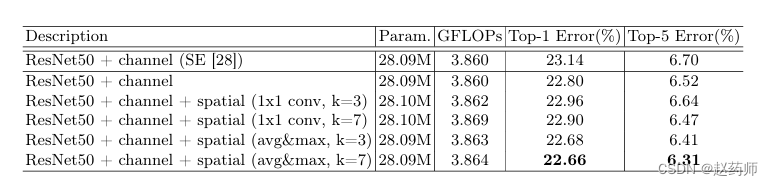

















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











