







Sparse Coding with Variance Regularization
\quad
本文的主题是 sparse coding。这个主题在computer vision中非常常见,因为我们需要提取出图像的 representation,而且尽可能要求是稀疏表示。通常的 sparse coding算法是用
ℓ
1
\ell_1
ℓ1 的惩罚函数(penalty function)来限制字典的稀疏性。在这篇文章中,作者提出了一种全新的框架,在这个框架中我们不再需要对 decoder 使用某种正则函数。
\quad
Abstract
在文中首先提出了一个问题:“ Collapse of the
ℓ
1
\ell_1
ℓ1 norm in the codes”。也就是说
ℓ
1
\ell_1
ℓ1范数崩溃的问题。为什么会造成这个问题呢?首先,现有一个字典为
D
\mathcal{D}
D,重构信号为
y
^
\hat y
y^,那么有
y
=
D
z
=
c
D
⋅
1
c
z
y = \mathcal{D}z = c\mathcal{D} \cdot \frac{1}{c}z
y=Dz=cD⋅c1z
成立,这个意思就是说,当
c
>
1
c>1
c>1时,
1
c
z
\frac{1}{c}z
c1z比原来的
z
z
z会更小,但其实这会有一模一样的重构。此时,如果不对
D
\mathcal{D}
D做限制,
D
\mathcal{D}
D无限大,就会导致
z
z
z无限小,这就是
ℓ
1
\ell_1
ℓ1范数崩溃问题。
传统的方法是利用二范数去规范化字典,但是文中指出这样的规范化是不平凡的,所以本文提出了方差正则化方法,直接对 z z z进行约束,省去了对字典进行约束的步骤。(这里的方差正则化是直接加在损失函数上的)
同时,文中的方差正则化其实就是“Let each latent code component has variance greater than a fixed threshold”。后文会对这里进行详细解释。
另外,文中实验表明,使用了非线性Deocder的带方差正则化的AutoEncoder框架相比于线性decoder的框架具有更高的重构质量。同时,使用了方差正则化的稀疏表示方法在降噪和分类任务也具有很好的效果。
\quad
Sparse AutoEncoder Framework
下图是文中提出的AutoEncoder框架,这个框架其实是比较漂亮的。
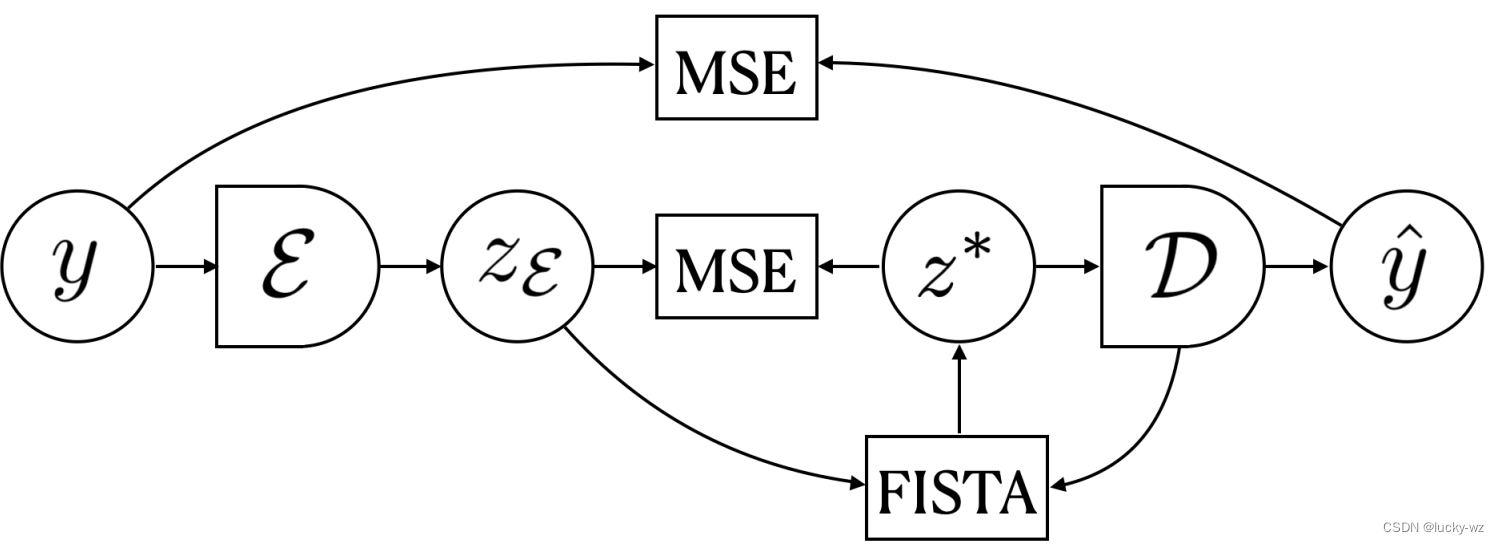
给定一个输入 y y y(图片)和一个固定的decoder D \mathcal{D} D,使用FISTA找到一个sparse code z ∗ z^* z∗可以使用字典 D \mathcal{D} D的元素重构 y y y。
整个框架的输入为图片 y y y。
- 首先,将图片 y y y输入到Encoder里面,得到输出 z ε z_{\varepsilon} zε;
- 其次,将
z
ε
z_{\varepsilon}
zε和
D
\mathcal{D}
D输入到FISTA中,经过若干步迭代,可以得到
z
∗
z^*
z∗。这里的迭代有一个损失函数,可以更新对应的参数。(其实这里的FISTA更像是LISTA)这里的损失函数一共分为三部分:
- 方差正则化
- M S E ( z ε , z ∗ ) MSE(z_\varepsilon, z^*) MSE(zε,z∗)
- M S E ( y , y ^ ) MSE(y, \hat y) MSE(y,y^)
- 将 z ∗ z^* z∗传入Decoder中,重构信号 y y y。
注意:在FISTA中,输入 z ε z_{\varepsilon} zε其实是作为FISTA迭代的初值,可以减少迭代次数,加快FISTA的收敛。另外,传入 D \mathcal{D} D(参数固定)是为了重构信号 y y y。这就是说,这里想要FISTA得到的 z ∗ z^* z∗同时满足两个条件:(1)和Encoder得到的 z ε z_\varepsilon zε足够接近;(2)要求能较好的重构信号 y y y。
接下来详细讲一讲每部分的细节。
\quad
Background: Sparse Coding and Dictionary Learning
首先来看一下背景知识,知道的略过。
稀疏编码算法就是在给定一个固定的字典
D
∈
R
d
×
l
\mathcal{D}\in\mathbb{R}^{d\times l}
D∈Rd×l和样本
y
∈
R
d
y\in \mathbb{R}^{d}
y∈Rd的基础上,寻求一个潜在的稀疏表示的算法。一般通过最小化能量函数求解:
z
∗
=
arg
min
z
E
(
z
,
y
,
D
)
=
1
2
∥
y
−
D
z
∥
2
2
+
λ
∥
z
∥
1
z^{*}=\arg\min_{z}\mathbf{E}(z, y, \mathcal{D})=\frac{1}{2}\|y-\mathcal{D} z\|_{2}^{2}+\lambda\|z\|_{1}
z∗=argzminE(z,y,D)=21∥y−Dz∥22+λ∥z∥1
其实一般情况下字典也是不知道的,字典
D
\mathcal{D}
D的参数一般利用梯度下降算法最小化均方误差求解得到:
L
D
(
D
,
Z
∗
,
Y
)
=
arg
min
D
1
N
∑
i
=
1
N
∥
y
i
−
D
z
i
∗
∥
2
2
\mathcal{L}_{\mathcal{D}}\left(\mathcal{D}, \mathcal{Z}^{*}, \mathcal{Y}\right)=\arg \min _{\mathcal{D}} \frac{1}{N} \sum_{i=1}^{N}\left\|y_{i}-\mathcal{D} z_{i}^{*}\right\|_{2}^{2}
LD(D,Z∗,Y)=argDminN1i=1∑N∥yi−Dzi∗∥22
方便起见,(1)式重新写为:
z
∗
=
arg
min
z
E
(
z
,
y
,
D
)
=
arg
min
z
f
(
z
)
+
g
(
z
)
z^{*}=\arg \min _{z} \mathbf{E}(z, y, \mathcal{D})=\arg \min _{z} f(z)+g(z)
z∗=argzminE(z,y,D)=argzminf(z)+g(z)
这里先讲一讲ISTA算法 ,一个ISTA迭代可以分为两步:Gradient Step 和 Shrinkage Step。
- Gradient Step
z ~ ( k ) = z ( k − 1 ) − η k ∇ f ( z ( k − 1 ) ) \tilde{z}^{(k)}=z^{(k-1)}-\eta_{k} \nabla f\left(z^{(k-1)}\right) z~(k)=z(k−1)−ηk∇f(z(k−1))
- Shrinkage Step
z
(
k
)
=
τ
λ
η
k
(
z
~
(
k
)
)
z^{(k)}=\tau_{\lambda \eta_{k}}\left(\tilde{z}^{(k)}\right)
z(k)=τληk(z~(k))
其中,
τ
α
(
x
)
j
=
sign
(
x
j
)
(
∣
x
j
∣
−
α
)
+
\tau_{\alpha}(x)_{j}=\operatorname{sign}\left(x_{j}\right)\left(\left|x_{j}\right|-\alpha\right)_{+}
τα(x)j=sign(xj)(∣xj∣−α)+。ISTA详细步骤可以看之前写的文章:Iterative Shrinkage Thresholding Algorithm
FISTA比较简单,它其实就是在ISTA的基础上加了一个动量项,进行了加速。Gradient Step式中的
z
k
−
1
z^{k-1}
zk−1被替换为:
x
(
k
)
=
z
(
k
−
1
)
+
t
k
−
1
−
1
t
k
(
z
(
k
−
1
)
−
z
(
k
−
2
)
)
x^{(k)}=z^{(k-1)}+\frac{t_{k-1}-1}{t_{k}}\left(z^{(k-1)}-z^{(k-2)}\right)
x(k)=z(k−1)+tktk−1−1(z(k−1)−z(k−2))
令
t
1
=
1
t_1=1
t1=1,对于
k
≥
2
k\geq 2
k≥2有:
t
k
=
1
+
1
+
4
t
k
−
1
2
2
t_{k}=\frac{1+\sqrt{1+4 t_{k-1}^{2}}}{2}
tk=21+1+4tk−12
因此,FISTA的 Gradient Step变为了:
z
~
(
k
)
=
x
(
k
)
−
η
k
∇
f
(
x
(
k
)
)
\tilde{z}^{(k)}=x^{(k)}-\eta_{k} \nabla f\left(x^{(k)}\right)
z~(k)=x(k)−ηk∇f(x(k))
Shrinkage Step和ISTA一样。
\quad
(F)ISTA with Variance Regularization
为了防止
ℓ
1
\ell_1
ℓ1范数的崩溃,在原来的优化问题上加入方差正则化:
f
~
(
z
)
=
∑
i
=
1
n
1
2
∥
y
i
−
D
z
⋅
i
∥
2
2
⏟
reconstruction terms
+
∑
j
=
1
l
β
[
(
T
−
Var
(
z
j
⋅
)
)
+
]
2
⏟
squared hinge terms
\tilde{f}(\mathbf{z})=\underbrace{\sum_{i=1}^{n} \frac{1}{2}\left\|y_{i}-\mathcal{D} \mathbf{z}_{\cdot i}\right\|_{2}^{2}}_{\text{reconstruction terms}} + \underbrace{\sum_{j=1}^{l} \beta\left[\left(T-\sqrt{\operatorname{Var}\left(\mathbf{z}_{j\cdot}\right) }\right)_{+}\right]^{2}}_{\text{squared hinge terms}}
f~(z)=reconstruction terms
i=1∑n21∥yi−Dz⋅i∥22+squared hinge terms
j=1∑lβ[(T−Var(zj⋅))+]2
其中,
Var
(
z
j
.
)
=
1
n
−
1
∑
i
=
1
n
(
z
j
i
−
μ
j
)
2
\operatorname{Var}\left(\mathbf{z}_{j .}\right)=\frac{1}{n-1} \sum\limits_{i=1}^{n}\left(\mathbf{z}_{j i}-\mu_{j}\right)^{2}
Var(zj.)=n−11i=1∑n(zji−μj)2。
在此基础上,加入
ℓ
1
\ell_1
ℓ1正则化项,可以得到修正后的能量函数:
E
~
(
z
,
Y
,
D
)
=
∑
i
=
1
n
1
2
∥
y
i
−
D
z
⋅
i
∥
2
2
+
∑
j
=
1
l
β
[
(
T
−
Var
(
z
j
⋅
)
)
+
]
2
+
∑
i
=
1
n
λ
∥
z
⋅
i
∥
1
\tilde{\mathbf{E}}(\mathbf{z}, Y, \mathcal{D})=\sum_{i=1}^{n} \frac{1}{2}\left\|y_{i}-\mathcal{D} \mathbf{z}_{\cdot i}\right\|_{2}^{2}+\sum_{j=1}^{l} \beta\left[\left(T-\sqrt{\operatorname{Var}\left(\mathbf{z}_{j\cdot}\right) }\right)_{+}\right]^{2}+\sum_{i=1}^{n} \lambda\left\|\mathbf{z}_{\cdot i}\right\|_{1}
E~(z,Y,D)=i=1∑n21∥yi−Dz⋅i∥22+j=1∑lβ[(T−Var(zj⋅))+]2+i=1∑nλ∥z⋅i∥1
不知道大家对这个方差正则化是否理解,我来谈谈自己的一点想法:关注hinge term这一项,我们最小化 E ~ ( z , Y , D ) \tilde{\mathbf{E}}(\mathbf{z}, Y, \mathcal{D}) E~(z,Y,D)时,由于平方的存在,理想情况下是想hinge term这一项越小越好,里面的 ( T − Var ( z j ⋅ ) ) \left(T-\sqrt{\operatorname{Var}\left(\mathbf{z}_{j\cdot}\right) }\right) (T−Var(zj⋅))这部分本身就非负(简单的理解,其实 ( ) + ()_+ ()+就是ReLU),所以这部分越小越小,其实就是让 z z z的方差大于一个固定的阈值 T \sqrt{T} T。
与上面的ISTA类似,分别讨论 Gradient Step 和 Shrinkage Step:
-
Gradient Step:
z ~ ⋅ t ( k ) = z ⋅ t ( k − 1 ) − η k ∇ z ⋅ t ( k − 1 ) f ~ ( z ) \tilde{\mathbf{z}}_{\cdot t}^{(k)}=\mathbf{z}_{\cdot t}^{(k-1)}-\eta_{k} \nabla_{\mathbf{z}_{\cdot t}^{(k-1)}} \tilde{f}(\mathbf{z}) z~⋅t(k)=z⋅t(k−1)−ηk∇z⋅t(k−1)f~(z)- reconstruction terms
∂ ∂ z s t ∑ i = 1 n 1 2 ∥ y i − D z ⋅ ∥ 2 2 = D s T ( D z ⋅ t − y t ) \frac{\partial}{\partial \mathbf{z}_{s t}} \sum_{i=1}^{n} \frac{1}{2}\left\|y_{i}-\mathcal{D} \mathbf{z}_{\cdot}\right\|_{2}^{2}=\mathcal{D}_{s}^{T}\left(\mathcal{D} \mathbf{z}_{\cdot t}-y_{t}\right) ∂zst∂i=1∑n21∥yi−Dz⋅∥22=DsT(Dz⋅t−yt) - hinge terms
∂ ∂ z s t ∑ j = 1 l β [ ( T − Var ( z j . ) ) + ] 2 = { − 2 β n − 1 T − Var ( z s . ) Var ( z s . ) ( z s t − μ s ) , if Var ( z s . ) < T 0 otherwise \frac{\partial}{\partial \mathbf{z}_{s t}} \sum_{j=1}^{l} \beta\left[\left(T-\sqrt{\operatorname{Var}\left(\mathbf{z}_{j .}\right)}\right)_{+}\right]^{2}= \begin{cases}-\frac{2 \beta}{n-1} \frac{T-\sqrt{\operatorname{Var}\left(\mathbf{z}_{s .}\right)}}{\sqrt{\operatorname{Var}\left(\mathbf{z}_{s .)}\right.}}\left(\mathbf{z}_{s t}-\mu_{s}\right), & \text { if } \sqrt{\operatorname{Var}\left(\mathbf{z}_{s .}\right)}<T \\ 0 & \text { otherwise }\end{cases} ∂zst∂j=1∑lβ[(T−Var(zj.))+]2=⎩⎨⎧−n−12βVar(zs.)T−Var(zs.)(zst−μs),0 if Var(zs.)<T otherwise
- reconstruction terms
-
Shrinkage Step:与ISTA一样。
AutoEncoder Architectures
Encoder
Encoder的架构如下:

这里的Encoder的架构采用的2010年发表的LISTA的架构。要注意的是,Encoder的输出层也作用了ReLU,也就是说,Encoder的输出是非负的,同时也是较为稀疏。
\quad
Decoder
Decoder其实就相当于字典的存在,也就是说:
y
=
D
x
y=\mathcal{D}x
y=Dx
可以
D
\mathcal{D}
D看作一个映射,把
z
∗
→
y
^
z^*\rightarrow\hat y
z∗→y^。自然地,这个映射有线性的,也有非线性的。在论文中,作者使用了两种Decoder,分别为:
- Linear Decoder: A simple linear transformation W ∈ R d × l W\in \mathbb{R}^{d\times l} W∈Rd×l.
- Non-Linear Decoder: Networks with one hidden layer. (parameters: W 1 ∈ R m × l W_1\in\mathbb{R}^{m\times l} W1∈Rm×l, b 1 ∈ R m b_1\in\mathbb{R}^{m} b1∈Rm, W 2 ∈ R d × m W_2\in\mathbb{R}^{d\times m} W2∈Rd×m)
并且,论文中的实验说明了非线性的Decoder的效果比线性的Decoder效果更好。
\quad
Training
一些训练的细节:
- 利用Encoder得到的结果当作FISTA的初值,减少迭代次数;
- 限制 z z z为非负,简化Shrinkage为ReLU;
- λ \lambda λ的值取决于稀疏程度;
- 四组算法:SDL、SDL-NL、VDL、VDL-NL
- SDL:standard dictionary learning.
- SDL-NL: SDL with non-linear decoder.
- VDL:variance-regularized dictionary learning.
- VDL-NL:VDL with non-linear decoder.
- 数据集:MNIST VS Natural Image Patches.
- 评估: PSNR
提到PSNR,这里简单说一下PSNR的计算公式。给定一个大小为
m
×
n
m\times n
m×n的干净图像
I
I
I和噪声图像
K
K
K,均方误差(
M
S
E
MSE
MSE)定义为:
M
S
E
=
1
m
n
∑
i
=
0
m
−
1
∑
j
=
0
n
−
1
[
I
(
i
,
j
)
−
K
(
i
,
j
)
]
2
M S E=\frac{1}{m n} \sum_{i=0}^{m-1} \sum_{j=0}^{n-1}[I(i, j)-K(i, j)]^{2}
MSE=mn1i=0∑m−1j=0∑n−1[I(i,j)−K(i,j)]2
在此基础上,PSNR(dB)被定义为:
P
S
N
R
=
10
⋅
log
10
(
M
A
X
I
2
M
S
E
)
P S N R=10 \cdot \log _{10}\left(\frac{M A X_{I}^{2}}{M S E}\right)
PSNR=10⋅log10(MSEMAXI2)
其中 M A X I 2 MAX_I^2 MAXI2为图片可能的最大像素值。如果每个像素都由 8 位二进制来表示,那么就为 255。通常,如果像素值由 B B B位二进制来表示,那么 M A X I = 2 B − 1 MAX_I=2^B-1 MAXI=2B−1。一般地,针对 uint8 数据,最大像素值为 255;针对浮点型数据,最大像素值为 1。
峰值信噪比PSNR衡量图像失真或是噪声水平的客观标准。
2个图像之间PSNR值越大,则越相似。普遍基准为30dB,30dB以下的图像劣化较为明显。
\quad
参考
- Evtimova K, LeCun Y. Sparse Coding with Multi-Layer Decoders using Variance Regularization[J]. arXiv preprint arXiv:2112.09214, 2021.















 3396
3396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











